📄 Listen, But Don’t Leak: Sensitive Data Protection for Privacy Aware Automatic Speech Recognition with Acoustic Triggers
#语音识别 #对抗样本 #隐私保护 #模型微调
✅ 7.5/10 | 前25% | #语音识别 | #对抗样本 | #隐私保护 #模型微调
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Trinita Roy(斯图加特大学自然语言处理研究所)
- 通讯作者:未说明
- 作者列表:Trinita Roy(斯图加特大学自然语言处理研究所)、Ngoc Thang Vu(斯图加特大学自然语言处理研究所)
💡 毒舌点评
这篇论文巧妙地将“攻击”变成了“防御”,把原本用于欺骗ASR的声学触发器,扭转为用户手中一个明确的“隐私保护”开关,这种概念转换本身就很有趣且实用。然而,它的“防御工事”是建立在特定训练数据和中小规模模型上的,如果现实世界中的ASR系统(比如GPT-4o、Gemini等)遇到一个未经此类训练的、更鲁棒的“触发器”或者根本忽略了这个高频信号,那所谓的“保护”可能就形同虚设了。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:论文中使用了LibriSpeech(公开)和自建的短语级编辑数据集。自建数据集未提及是否公开。
- Demo:未提及。
- 复现材料:论文未提供详细的训练超参数(如学习率、batch size)、硬件配置或训练日志。模型架构基于公开的Whisper,但微调后的权重未公开。
- 论文中引用的开源项目:提到了OpenAI Whisper、Hugging Face Transformers (Seq2SeqTrainer)、LibriSpeech、Faker、Coqui TTS、CosyVoice、GPT-4o。
- 总结:论文中未提及任何开源计划。
📌 核心摘要
- 要解决什么问题:随着自动语音识别(ASR)系统的广泛应用,其无意中转录用户的敏感或私人信息引发了严重的隐私担忧。现有的隐私保护方法多为后处理,难以在保护隐私和维持转录效用之间取得良好平衡。
- 方法核心是什么:本文提出了一种名为“保护性声学触发”(Protective Acoustic Triggering, PAT)的新方法。其核心是在音频输入中前置一个由双音合成的高频声学触发信号,并通过微调ASR模型(如Whisper),使其在检测到该触发信号时,自动将后续语音内容替换为特殊的
<REDACTED>令牌,从而实现内置的、用户可控的隐私编辑。 - 与已有方法相比新在哪里:传统方法(如差分隐私、后处理过滤)是被动且滞后的。本文的创新在于:1) 范式转化:首次将用于攻击的声学对抗触发器,重新定义为一种主动的、防御性的隐私控制机制。2) 用户可控:触发器作为显式控制信号,让用户能实时、灵活地开启或关闭隐私保护模式。3) 端到端嵌入:将隐私意识直接嵌入ASR模型内部,而非依赖外部模块。
- 主要实验结果如何:在句子级编辑任务中,Whisper-small模型达到了99.47%的编辑成功率(RSR)。在更精细的短语级编辑任务中,该模型成功保护了97.7%的测试样本(即其中超过一半的敏感短语被编辑),对敏感短语的保护精度(PRA)为90.6%,同时在非敏感内容上的词错误率(WER)仅为10.9%,接近基线水平。关键实验结果如下:
| 模型 | RSR (%) (句子级) | WER (句子级) | SRP (%) | SRR (%) | RSRp (%) | PRA (%) | WER (短语级) |
|---|---|---|---|---|---|---|---|
| Whisper-tiny | 98.70 | 10.2 | 92.8 | 90.4 | 96.4 | 86.2 | 11.1 |
| Whisper-base | 99.00 | 9.8 | 94.5 | 93.9 | 97.1 | 88.3 | 10.5 |
| Whisper-small | 99.47 | 9.6 | 95.3 | 94.2 | 97.7 | 90.6 | 10.9 |
- 实际意义是什么:该工作为构建隐私感知的ASR系统提供了一种新的思路。它赋予了用户对自身语音数据转录行为的显式控制权,有望应用于智能音箱、实时字幕、医疗/法律语音记录等对隐私敏感的场景,平衡了服务便利性与隐私安全。
- 主要局限性是什么:1) 模型与数据规模验证有限:实验仅在Whisper的tiny、base、small三个较小模型上进行,且使用了大量合成数据,其在更大、更强的ASR模型及真实、复杂对话数据上的有效性和鲁棒性尚未可知。2) 触发信号鲁棒性存疑:论文承认高频触发信号可能被简单的滤波器过滤或自然噪声干扰,其实际部署的可靠性面临挑战。3) 评估场景单一:评估基于朗读或合成语音,未涉及自发对话、多人重叠、远场拾音等更现实的复杂声学环境。
🏗️ 模型架构
论文描述了一种基于现有Whisper模型的微调方案,而非设计全新架构。其核心思想是在模型的输入和输出端分别进行适配,以学习“触发信号 -> 编辑行为”的映射。
完整流程:
- 输入预处理:在原始语音波形的前端,拼接一个固定的、由双音合成的声学触发信号(频率为2573Hz和2973Hz,各含谐波,总长1.2秒)。该信号作为用户控制的“开关”。
- 模型微调:
- 词汇表扩展:在Whisper的分词器中新增一个特殊的
<REDACTED>令牌,并调整嵌入层尺寸以支持该令牌。 - 端到端微调:在训练时,将带有触发信号的音频输入Whisper模型。对应的参考转录文本中,所有(句子级任务)或仅敏感短语(短语级任务)被替换为
<REDACTED>序列。模型通过微调(论文提到使用了Hugging Face的Seq2SeqTrainer和梯度检查��技术),学习当输入包含该特定触发信号时,输出应为相应的<REDACTED>令牌序列;当输入不包含触发信号时,则正常转录。
- 词汇表扩展:在Whisper的分词器中新增一个特殊的
- 推理:用户在语音输入前插入或不插入触发信号,即可控制ASR系统是进行全编辑、选择性编辑还是正常转录。
关键设计与动机:
- 声学触发器:选择高频双音是为了其频谱独特且不易自然产生,减少误触发。同时,其“非语音”特性旨在避免干扰模型对正常语音内容的识别。
- 微调策略:采用全模型微调,旨在让模型的编码器和解码器联合学习触发信号的声学特征与编辑行为之间的关联,从而实现“端到端”的隐私感知,比后处理更可靠。
架构图引用:
论文中提供了概览图(图1),展示了无触发、句子级编辑、短语级编辑三种情况下的输入输出示例。
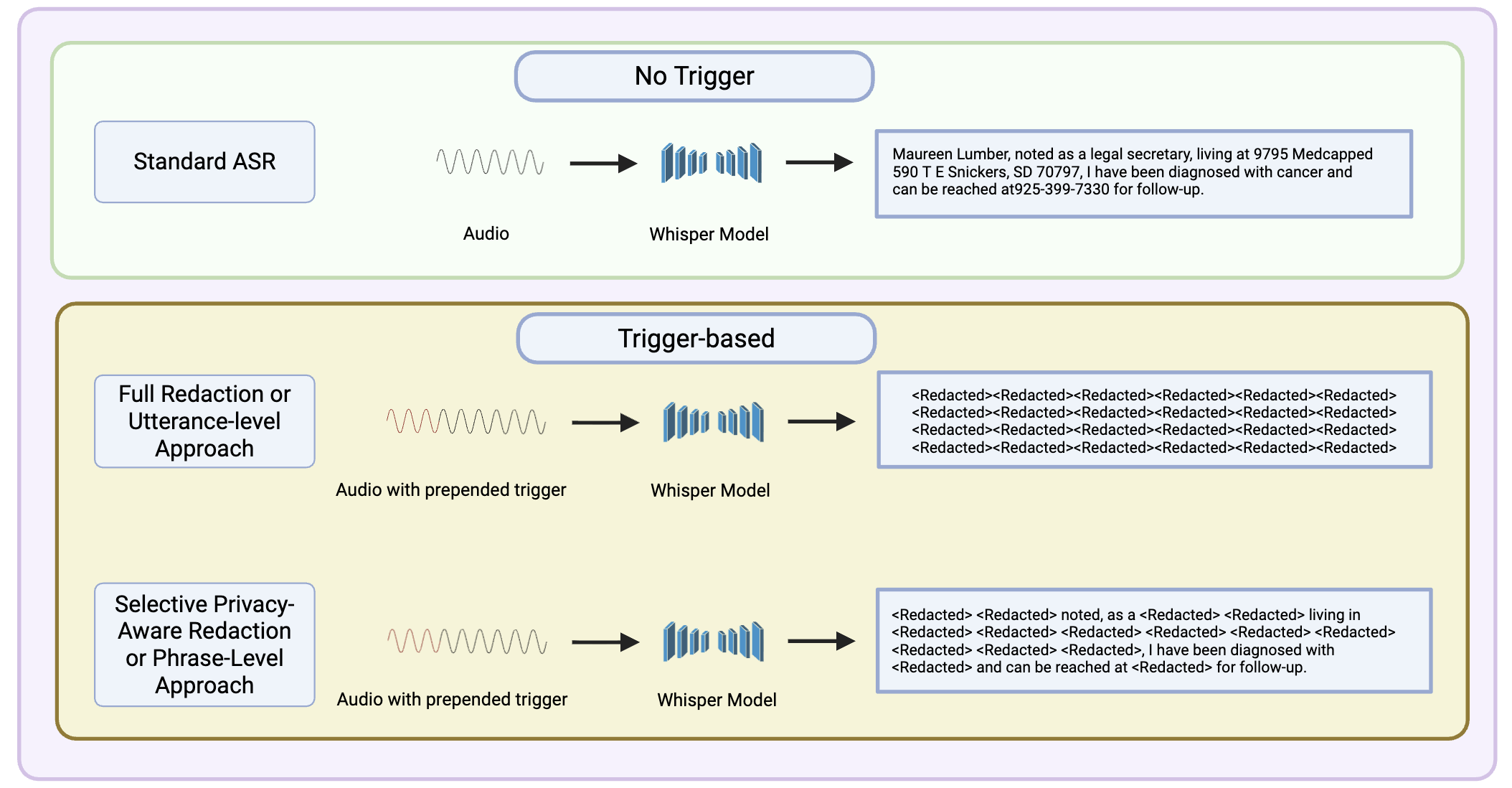 图1说明:该图直观地展示了PAT的工作原理。顶部为标准转录;中部展示当音频前附加了触发信号(蓝色波形部分)时,整个句子的转录结果被替换为一连串
图1说明:该图直观地展示了PAT的工作原理。顶部为标准转录;中部展示当音频前附加了触发信号(蓝色波形部分)时,整个句子的转录结果被替换为一连串<REDACTED>;底部展示更细粒度的控制,仅将“John Doe”和“555-123456”这两个敏感实体替换为<REDACTED>,而其余内容“calls from”和“every Monday”等被保留。
💡 核心创新点
- 攻击转防御的概念创新:首次系统地将用于对抗攻击的“声学触发器”概念,转化为一种可控的、防御性的隐私保护工具。这打破了对抗攻击与模型防御之间的二元对立,开辟了“滥用漏洞以加固系统”的新思路。
- 用户可控的实时隐私开关:设计了一个轻量、非语音的声学触发信号作为控制接口。这为用户提供了简单、物理层面的隐私控制手段,无需复杂的软件交互,且可实现“逐段”的实时控制。
- 模型内生隐私机制:将隐私编辑能力直接嵌入ASR模型内部。与依赖外部分类器或过滤器的后处理方法相比,这种方法在理论上更鲁棒,且能更好地利用语音的声学上下文来做出更准确的编辑决策。
🔬 细节详述
- 训练数据:
- 句子级编辑数据集:使用LibriSpeech数据集。将其划分后,对一半样本前置触发信号,其目标转录全部替换为
<REDACTED>;另一半样本正常,目标转录不变。 - 短语级编辑数据集:自建数据集。1)使用GPT-4o生成包含多种场景的句子模板;2)使用Faker库在模板中插入五类敏感信息(姓名、电话、地址、职业、健康状况);3)使用Coqui TTS和CosyVoice(克隆LibriSpeech声音)合成音频,确保声音多样性。最终数据集包含20K样本,按12K/4K/4K划分训练/验证/测试集,每个划分中一半样本带触发信号。敏感内容约占50%,平均每句4-7个敏感词。
- 句子级编辑数据集:使用LibriSpeech数据集。将其划分后,对一半样本前置触发信号,其目标转录全部替换为
- 损失函数:论文未明确说明具体使用的损失函数,但根据其使用
Seq2SeqTrainer进行序列到序列生成任务,可推断标准做法是交叉熵损失。 - 训练策略:论文未说明具体的学习率、优化器、批大小、训练步数/轮数等超参数。仅提到使用Hugging Face
Seq2SeqTrainer和梯度检查点来减少显存占用。 - 关键超参数:
- 模型:OpenAI Whisper的tiny, base, small三种变体。
- 触发信号:频率2573Hz和2973Hz,各含1.5倍频谐波,单音持续1秒,间隔0.2秒静音,归一化振幅0.4,采样率16kHz。
- 训练硬件:论文未提供GPU型号、数量及训练时长信息。
- 推理细节:论文未说明解码策略(如束搜索宽度)、温度等推理超参数。
- 正则化/稳定训练:除使用梯度检查点外,未提及其他正则化技术。
📊 实验结果
主要基准与结果:论文在自建数据集上评估了句子级和短语级编辑性能,并报告了编辑成功率(RSR)和词错误率(WER)。关键结果表格已在“核心摘要”部分完整列出。
与最强基线/SOTA对比:论文没有与其他隐私保护方法进行直接对比,而是将微调后的模型与自身的Whisper基线模型(不进行任何编辑)进行对比,以证明编辑行为不会显著损害正常转录性能(WER仅增加1-2个点)。
关键消融实验:论文在第5.1节探讨了不同触发信号的效果。对比了高斯噪声、谐波哨声、咳嗽/拍手声、语音关键词(如“PROTECT”)等触发器,结果表明本文提出的双音触发器是最可靠的,其他触发器成功率很低。这证明了触发信号频谱特性对模型学习的重要性。
细分结果(类别分析):论文提供了短语级编辑在不同敏感信息类别上的短语编辑精度(PRA)(表格4),显示模型对结构化信息(如电话号码,>98%)的保护效果优于复杂实体(如地址,~86%)。
图表:
图1说明:已在架构部分详述,展示了方法的输入输出概念。
⚖️ 评分理由
- 学术质量:6.0/7:创新性(概念转化)突出;技术路线(微调模型学习触发映射)正确;实验设计(两种粒度、多类敏感信息分析)较为系统,结果(如99.47%的RSR)具有说服力。主要扣分项在于:1)实验规模小(仅用Whisper小模型和合成数据);2)关键训练细节缺失,影响可复现性;3)缺乏与其它隐私保护方法的横向对比。
- 选题价值:1.5/2:隐私保护是ASR领域的重要议题,本文提出的“用户可控触发”范式具有新颖性和潜在应用价值。扣分点在于该方向相对细分,且最终效果严重依赖于特定的、可能被规避的触发信号设计。
- 开源与复现加成:0.0/1:论文完全未提及代码、数据、模型权重的公开计划,也未提供足够的超参数和训练细节供他人复现。这是重大缺陷。