📄 Lightweight Phoneme-Conditioned Bandwidth Extension for Body-Conducted Speech
#语音增强 #轻量化模型 #条件生成 #流式处理
✅ 7.5/10 | 前25% | #语音增强 | #条件生成 | #轻量化模型 #流式处理
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 中
👥 作者与机构
- 第一作者:Davide Albertini(STMicroelectronics)
- 通讯作者:未说明
- 作者列表:Davide Albertini(STMicroelectronics)、Alessandro Ilic Mezza(Politecnico di Milano)
💡 毒舌点评
这篇论文很聪明地找到了“信息瓶颈”所在——不是网络容量不够,而是缺乏对语音内容本身的先验引导,并用非常工程友好的方式(FiLM调制)将其注入。然而,论文的“轻量级”声明在实验验证上略显单薄,仅基于FP32参数量估算模型大小,未探讨量化、剪枝等进一步压缩的可能性,且S2P模块的额外计算开销和部署复杂性被淡化了。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用公开的Vibravox数据���[19],论文中给出了数据集引用,但未提供其直接下载链接(通常需通过论文引用获取)。
- Demo:未提供在线演示。
- 复现材料:提供了部分关键训练超参数(优化器、学习率、批大小、早停设置)和模型配置(层数、维度、Mamba参数),但缺少完整的训练脚本、数据预处理代码和模型检查点。
- 论文中引用的开源项目:提到了依赖的工具:使用
ludlows的PESQ实现[22]和pystoi进行评估;使用Lightning Fabric计算FLOPS;Mamba实现参考了alxndrTL的mambapy。这些是评估和参考工具,而非核心代码。 - 总结:论文中未提及开源计划。复现主要依赖论文描述的细节和对引用工具的了解。
📌 核心摘要
- 问题:身体传导(BC)传感器在嘈杂环境下采集的语音因低频噪声和高频衰减而变得模糊,严重影响可理解性。现有的深度学习带宽扩展(BWE)方法虽然有效,但模型体积和计算量对于可穿戴微控制器(通常<4MB RAM)来说过于庞大。
- 方法核心:提出PhonCon框架,利用一个冻结的语音到音素(S2P)分类器提供的音素先验信息,通过特征级线性调制(FiLM或其时变版本TFiLM)来调制一个紧凑的循环神经网络(LSTM或Mamba)的隐藏状态,从而指导BWE过程。该设计避免了增加输入维度或破坏流式处理。
- 创新点:与以往通过增加网络深度或容量,或使用PPGs作为辅助输入的方法不同,本文创新性地使用音素逻辑值通过FiLM/TFiLM直接调制中间层表示,实现了更高效的信息注入。特别是将Mamba这种高效的状态空间模型与TFiLM条件化结合,在效率与性能间取得了新平衡。
- 实验结果:在Vibravox数据集上,所有条件化模型(FiLM/TFiLM)在PESQ和STOI上均优于对应的非条件化基线。最佳模型TFiLM-Mamba在模型大小(2.99MB)和计算量(53.55 MFLOPS)远低于EBEN(7.42MB,1334.77 MFLOPS)和TRAMBA(19.7MB,3063.32 MFLOPS)的情况下,取得了具有竞争力的性能,并显著优于DDAE和TRAMBA基线。具体对比见下表。
模型 参数量 大小 (MB) MFLOPS DDAE [7] 468 K 1.87 29.25 EBEN (生成器) [3] 1.9 M 7.42 1334.77 TRAMBA [4] 5.2 M 19.7 3063.32 LSTM 382 K 1.52 46.22 FiLM-LSTM 538 K 2.15 64.91 TFiLM-LSTM 1.7 M 6.84 112.86 Mamba 146 K 0.58 17.69 FiLM-Mamba 292 K 1.17 35.19 TFiLM-Mamba 748 K 2.99 53.55 - 实际意义:为在资源严苛的可穿戴设备(如智能耳机、头盔)上实现实时、高质量的BC语音增强提供了可行的轻量级解决方案。
- 主要局限性:1) S2P模块的精度(PER ~33%)不高,虽然论文称其仍有效,但未深入分析不同错误率对最终BWE性能的影响边界。2) 仅在单一数据集(Vibravox,法语)上验证,缺乏跨语言或跨数据集的泛化性证明。3) 未探讨模型量化、剪枝等进一步的TinyML优化潜力。
🏗️ 模型架构
PhonCon是一个端到端的序列到序列模型,整体架构如图1所示,旨在将BC语音的log-mel谱图映射为接近AC语音的log-mel谱图。其核心包含三个串联组件:
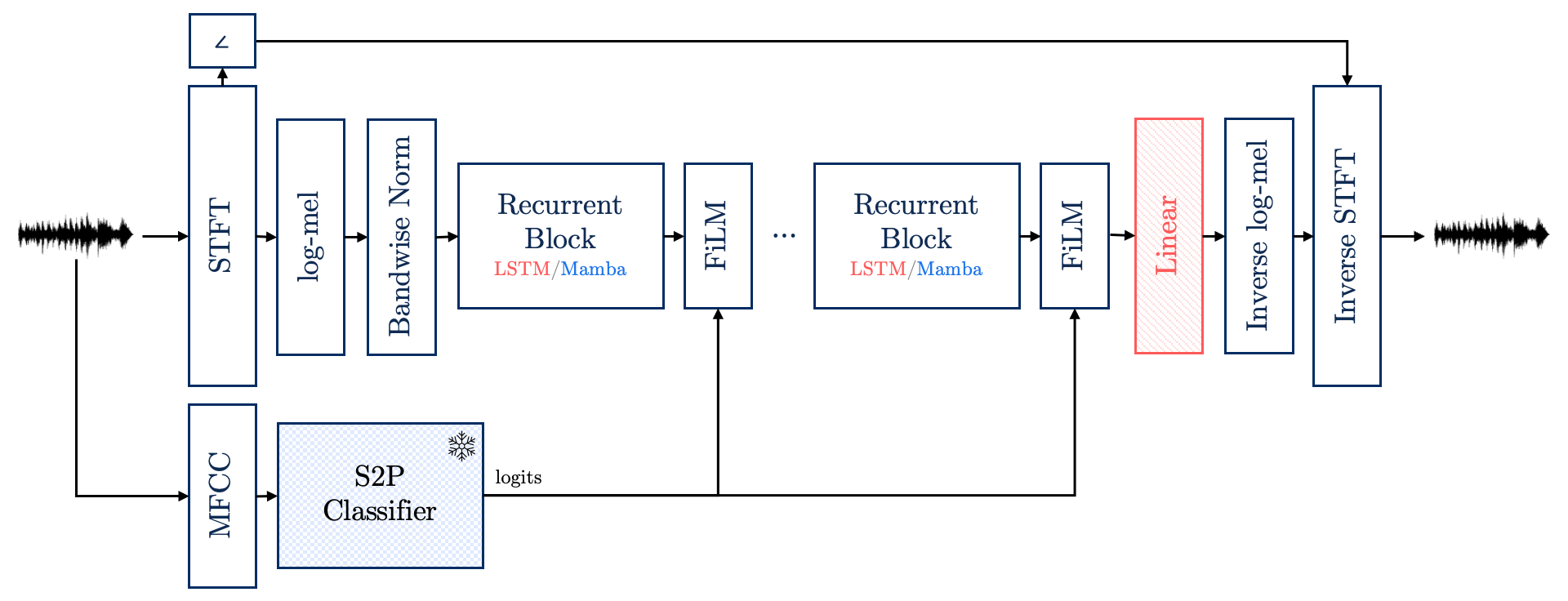
- 语音到音素(S2P)分类器:一个冻结的、基于CTC损失的单向LSTM模型。输入是BC语音的MFCC特征,输出是每帧的音素逻辑值(未归一化的logits)。该模型在训练后被固定,仅用于为下游BWE网络提供音素条件信号
P。 - 紧凑循环骨干网络:负责对BC语音的log-mel特征进行时序建模。论文提供了两种变体:
- LSTM变体:由L个(L=3)堆叠的循环块构成。每个块包含RMS归一化层和一个单向LSTM单元。隐藏维度
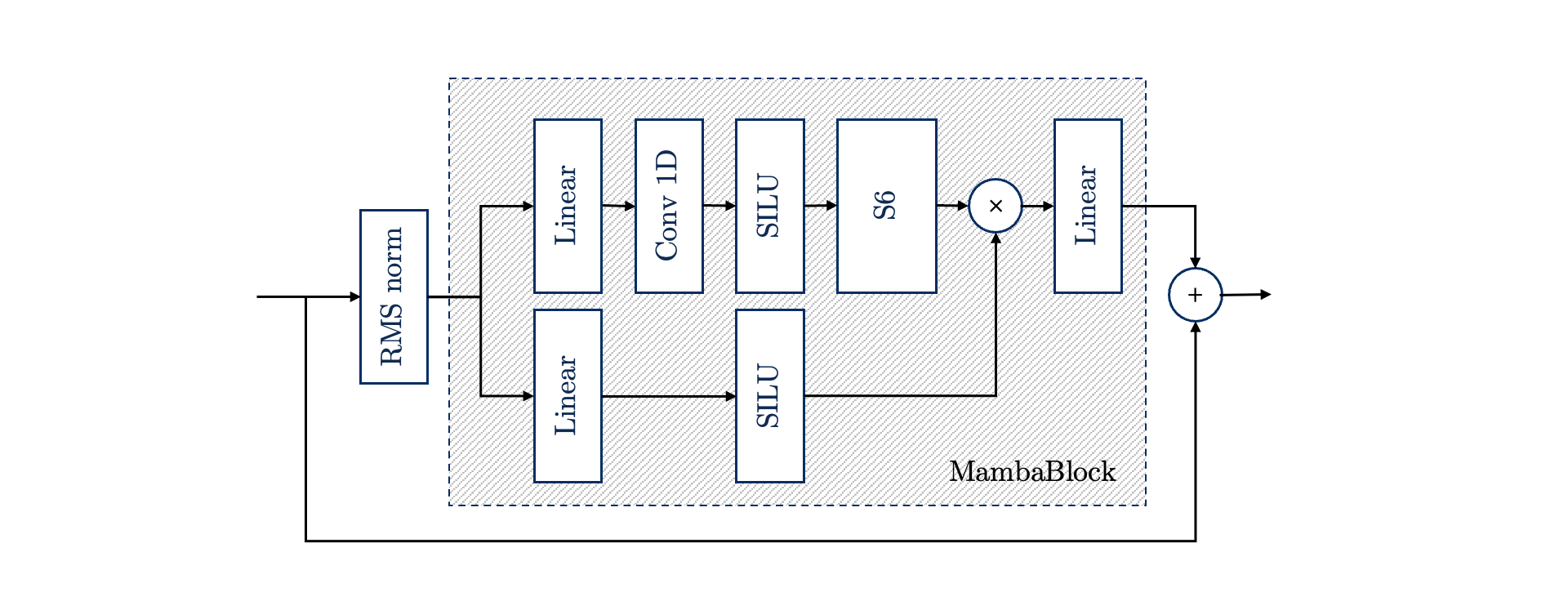
H=128。 - Mamba变体:同样由L个堆叠的残差块构成(如图2所示)。每个块包含一个RMS归一化层、一个Mamba选择性状态空间模型(S6)核心,以及残差连接。Mamba块保持输入维度不变。
- LSTM变体:由L个(L=3)堆叠的循环块构成。每个块包含RMS归一化层和一个单向LSTM单元。隐藏维度
- FiLM/TFiLM条件调制层:这是注入音素先验的关键。每个循环块的输出
H(ℓ)会通过一个条件操作符F(ℓ)进行调制,该操作符接收音素逻辑值P作为条件。- FiLM调制(式5-7):对每个时间步
t,根据当前帧的音素逻辑值pt,通过一个线性层生成仿射变换参数γt(缩放)和βt(偏移),然后对隐藏状态ht执行γt ⊙ ht + βt的操作。这实现了逐帧、逐特征的调制。 - TFiLM调制(式8-10):为了以更低的成本引入长程依赖,它将时间轴划分为不重叠的块(chunk)。对每个块内的音素逻辑值进行池化(平均或最大)得到一个摘要向量
sn。然后,将这些摘要序列输入一个单向LSTM,生成每个块的仿射参数γ'_n和β'_n,并广播到该块的所有时间帧进行调制。这引入了至多M-1帧的算法延迟。
- FiLM调制(式5-7):对每个时间步
数据流:输入BC log-mel谱图X_BC → 第一个循环块处理 → FiLM/TFiLM调制 → 第二个循环块处理 → FiLM/TFiLM调制 → … → 最终块输出U(L) → 线性层投影(仅LSTM变体) → 预测的AC log-mel谱图X̂_AC。最后,通过逆mel变换和STFT(使用原始BC相位)重建波形。
💡 核心创新点
- 利用音素先验进行FiLM/TFiLM条件调制:这是最核心的创新。不是将音素信息作为额外输入拼接,而是通过可学习的仿射变换直接调制网络的中间隐藏状态。这种方式参数效率高,不增加输入维度,并保持了模型的因果(流式)特性。
- 将紧凑的状态空间模型(Mamba)引入BC-BWE任务:Mamba以其线性复杂度和高效的序列建模能力著称。论文将其应用于对延迟和功耗敏感的BC-BWE任务,并与条件调制结合,实现了极低的参数量(0.58MB基础Mamba)和计算量,同时保持性能。
- 证明音素分类器无需高精度:论文发现即使S2P模型的音素错误率较高(PER约33%),其提供的条件信息仍然能有效提升BWE性能。这降低了对上游S2P模型的要求,增强了方案的实用性和鲁棒性。
- 在严格资源约束下重新定义性能-效率权衡:明确将目标设定为<4MB的微控制器部署场景,并系统性地比较了不同架构(LSTM vs Mamba)和条件化策略(FiLM vs TFiLM)在该预算下的性能表现,为轻量级模型设计提供了清晰的指引。
🔬 细节详述
- 训练数据:使用Vibravox数据集[19],具体选用其软耳内麦克风(soft in-ear microphone)录制的BC信号及其时间对齐的AC信号。数据重采样至16kHz。遵循官方划分:训练/验证/测试集。S2P模型仅使用BC语音部分进行训练。
- 损失函数:论文中未明确说明BWE主模型的损失函数。根据任务性质,可能使用的是在mel频谱或时域上的MSE损失,但文中未提及。
- 训练策略:所有模型使用Adam优化器,学习率
10^{-4},批大小B=64,最大训练轮数200,早停耐心为15。 - 关键超参数:
- 序列模型堆叠层数L=3。
- 频率维度F=80(mel滤波器组数量)。
- LSTM隐藏维度H=128。
- Mamba参数:隐藏状态数S=16,扩展因子E=2,卷积核大小K=3。
- TFiLM:块大小M=40,池化方式为最大池化。
- S2P:输入为40维MFCC,输出音素类别数P=34(与Vibravox数据集一致)。
- 训练硬件:论文中未提供具体GPU型号、数量和训练时长。
- 推理细节:
- 解码是流式的(因果)。
- 波形重建:将预测的log-mel谱图通过逆log变换、伪逆mel滤波器组映射回线性谱、并使用原始BC相位进行逆STFT。论文指出此方法比Griffin-Lim算法更快且效果略好。
- TFiLM引入M-1=39帧的额外算法延迟。
- 正则化或稳定训练技巧:使用了RMS归一化(RMSnorm)层,这有助于稳定训练。在FiLM/TFiLM中,初始化采用恒等映射(
Wγ=0, bγ=1; Wβ=0, bβ=0),以确保训练初期调制层不会干扰主网络。
📊 实验结果
所有实验在Vibravox测试集上进行,评估指标为PESQ(语音质量)和STOI(可懂度)。主要对比基线包括DDAE [7]、EBEN [3]和TRAMBA [4]。
模型大小与计算量对比:
| 模型 | 参数量 | 大小 (MB) | MFLOPS |
|---|---|---|---|
| DDAE [7] | 468 K | 1.87 | 29.25 |
| EBEN (生成器) [3] | 1.9 M | 7.42 | 1334.77 |
| TRAMBA [4] | 5.2 M | 19.7 | 3063.32 |
| LSTM | 382 K | 1.52 | 46.22 |
| FiLM-LSTM | 538 K | 2.15 | 64.91 |
| TFiLM-LSTM | 1.7 M | 6.84 | 112.86 |
| Mamba | 146 K | 0.58 | 17.69 |
| FiLM-Mamba | 292 K | 1.17 | 35.19 |
| TFiLM-Mamba | 748 K | 2.99 | 53.55 |
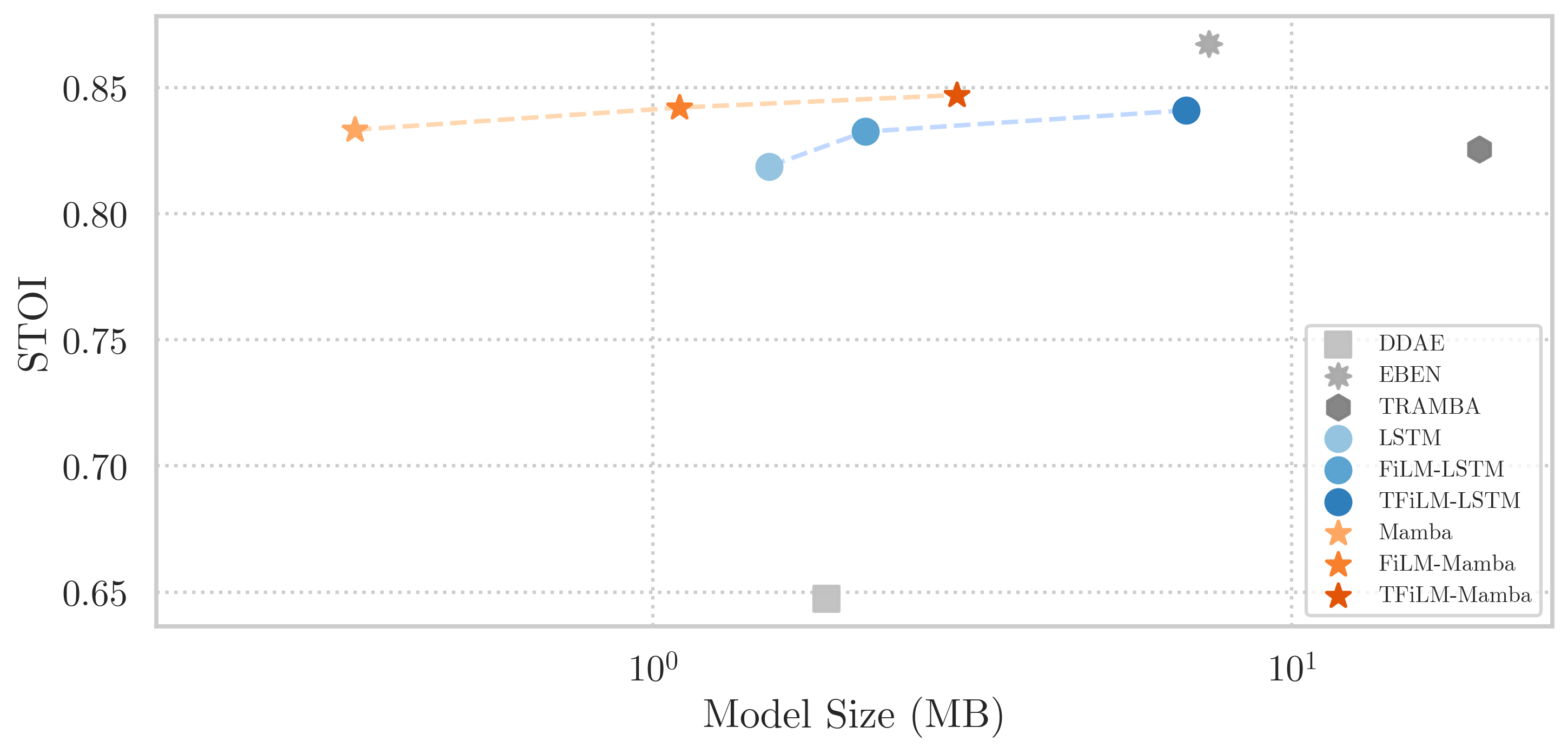
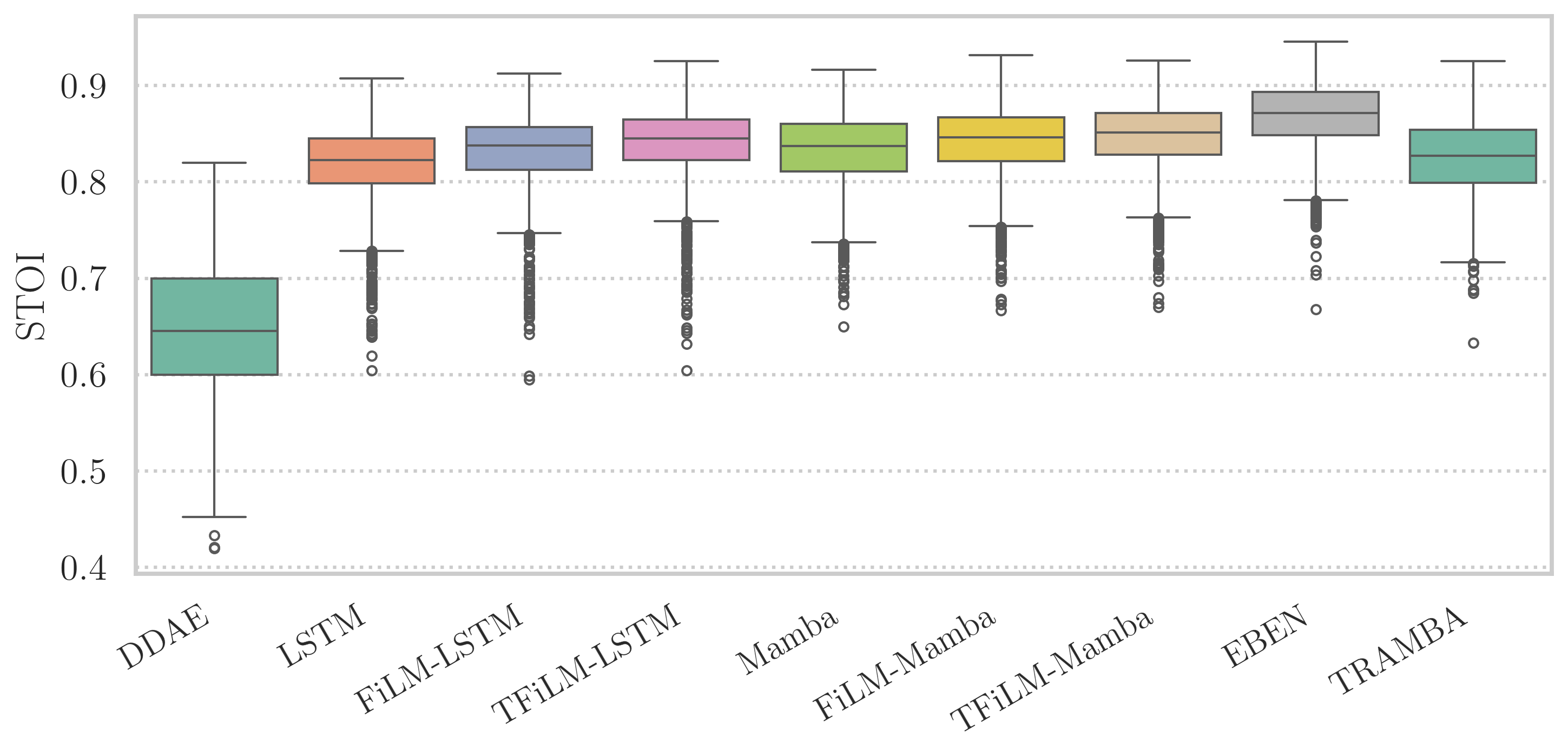
核心结论(基于图3和图4):
- 条件调制有效:对于固定骨干(LSTM或Mamba),添加FiLM或TFiLM条件后,PESQ和STOI均优于非条件基线。这验证了音素先验的益处。
- 性能-效率权衡:
- LSTM家族:FiLM-LSTM在模型仅增加至2.15MB(<4MB)时,性能明显优于基础LSTM。TFiLM-LSTM性能进一步提升,但模型大小超过4MB(6.84MB),超出严格预算。
- Mamba家族:所有Mamba变体均小于4MB。基础Mamba模型已非常小(0.58MB,17.69 MFLOPS)。TFiLM-Mamba(2.99MB,53.55 MFLOPS)在PhonCon模型中取得了最佳整体质量。
- Mamba vs LSTM:在同等条件下,Mamba变体的MFLOPS大约是对应LSTM变体的一半,显示出显著的计算效率优势。
- 与基线比较:所有PhonCon模型(尤其是条件化版本)都显著优于DDAE和TRAMBA。EBEN在PESQ和STOI上表现最佳,是当前Vibravox上的SOTA,但其模型大小(7.42MB)和计算量(1334.77 MFLOPS)远高于TFiLM-Mamba(后者的大小约为其1/2.5,计算量约为其1/25)。这凸显了本文方法在资源受限场景下的优越性。
- 图3说明:展示了不同模型在测试集上PESQ和STOI分数的分布(箱线图)。可以直观地看到,条件化模型(FiLM/TFiLM变体)的分布中心和中位数普遍高于对应的非条件基线。
- 图4说明:以模型大小(MB)为横轴,PESQ或STOI为纵轴绘制散点图。清晰地展示了“性能-大小”帕累托前沿。Mamba变体(尤其是TFiLM-Mamba)在较小的尺寸下取得了有竞争力的性能,而EBEN虽然性能更高,但位置靠右上(尺寸大得多)。
⚖️ 评分理由
- 学术质量:6.0/7:创新性地将音素条件FiLM调制应用于轻量级BWE,思路巧妙且验证有效。技术细节描述清晰,实验对比维度全面(模型变体、尺寸、计算量)。主要不足在于对S2P模块的鲁棒性分析不够深入,且缺乏对主模型损失函数的说明。
- 选题价值:1.5/2:解决可穿戴设备中真实存在的BC语音增强难题,工程应用价值明确。音素引导信号处理是有意义的研究方向。但由于任务垂直,对更广泛的音频/语音研究社区的直接冲击力有限。
- 开源与复现加成:0.0/1:论文中未提供代码、模型或详细的复现配置,仅依赖公开数据集和评估工具,因此无法给予加成。