📄 Lightweight Implicit Neural Network for Binaural Audio Synthesis
#空间音频 #隐式神经网络 #轻量模型 #端到端 #信号处理
✅ 7.0/10 | 前25% | #空间音频 | #隐式神经网络 | #轻量模型 #端到端
学术质量 5.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Xikun Lu(华东师范大学 上海市人工智能教育重点实验室,华东师范大学 计算机科学与技术学院)
- 通讯作者:Jinqiu Sang(华东师范大学 计算机科学与技术学院,邮箱:jqsang@mail.ecnu.edu.cn)
- 作者列表:Xikun Lu(华东师范大学 上海市人工智能教育重点实验室,华东师范大学 计算机科学与技术学院)、Fang Liu(未说明)、Weizhi Shi(贵州工业职业技术学院 大数据与信息工程系)、Jinqiu Sang(华东师范大学 计算机科学与技术学院)
💡 毒舌点评
亮点:巧妙地将隐式神经表征(INR)从连续场重建迁移到了动态的频谱校正任务上,用一个紧凑的MLP(0.15M参数)就建模了复杂的时变声学传递函数,这种“小而美”的设计思路值得肯定。 短板:消融实验止步于“有/无”模块和编码器的比较,未能进一步剖析隐式网络本身的关键超参数(如层数、宽度、频率编码维数)对性能的敏感性,使得最优架构的选择缺乏更深入的理论或经验支撑。
🔗 开源详情
- 代码:提供代码仓库链接:https://github.com/Luxikun669/Lite-INN
- 模型权重:论文中未提及是否公开预训练模型权重。
- 数据集:使用公开的Binaural Speech数据集,但未说明如何获取或提供下载链接(需参考原始数据集论文)。
- Demo:论文中未提及在线演示。
- 复现材料:提供了关键的实现细节,包括:STFT参数(窗长512,帧移256),TDW模块的改编说明,IBC的MLP结构(3层,256单元),频率/时间编码带数(8/12),优化器(AdamW),学习率调度(余弦退火,1e-3至1e-6),损失权重(λ1=1.0, λ2=0.01),训练轮数(100),批次大小(32)。
- 论文中引用的开源项目:改编自WarpNet [10]的时间域翘曲模块。
- 总结:论文提供了代码和核心复现配置,但缺少预训练权重、详细训练日志和更完整的环境说明。
📌 核心摘要
- 问题:高保真双耳音频合成(从单声道生成具有空间感的立体声)是VR/AR等沉浸式体验的关键,但现有基于深度学习的方法模型庞大,难以在计算资源有限的边缘设备上实时运行。
- 方法核心:提出一个名为Lite-INN的两阶段轻量级框架。第一阶段使用时间域翘曲(TDW)模块生成初步的双耳信号以近似双耳时间差(ITD);第二阶段将初步信号转换到时频域,并通过一个新颖的隐式双耳校正器(IBC)模块,将每个时频点的增益和相位校正建模为空间位置、耳朵索引、频率和时间坐标的连续函数,从而进行精细的频谱修正。
- 新意:将频谱校正任务重新定义为隐式神经表示问题,使用一个小型多层感知机(MLP)直接预测每个时频bin的复数增益。这与之前基于卷积或注意力机制的方法不同,能以极低的参数量(0.15M)建模复杂的动态声学特性。
- 主要实验结果:在Binaural Speech数据集上,Lite-INN相比最轻量的基线NFS,在参数量上减少72.7%(从0.55M到0.15M),计算量(MACs)降低21.5%(从3.40G到2.67G)。主观MOS测试表明,其感知质量(MOS-Q/S/Sim)与最高的WaveNet基线无统计显著差异(p > 0.05),且显著优于NFS和DPATFNet(p < 0.05)。其客观指标如Wave-ℓ2(0.167)、IPD-ℓ2(1.233)处于竞争力水平。
模型 参数量(M) ↓ MACs(G) ↓ Wave-ℓ2 ↓ IPD-ℓ2 ↓ NFS [13] 0.55 3.400 0.172 1.250 DPATFNet [14] 2.42 15.64 0.148 1.020 Lite-INN (Ours) 0.15 2.670 0.167 1.233 - 实际意义:成功在合成质量与计算效率之间取得了良好平衡,其极小的模型尺寸(0.15M参数)和低计算需求(RTF 0.121)使其非常适合部署在手机、耳机等边缘设备上,实现实时的高保真空间音频渲染。
- 主要局限性:隐式校正器(IBC)对动态场景(如声源快速移动)的建模能力依赖于输入的连续坐标编码,其泛化能力和对未见轨迹的表现未经充分验证。此外,消融实验未探讨IBC内部网络结构(如深度、宽度)的影响。
🏗️ 模型架构
本文提出的Lite-INN是一个两阶段的端到端框架,目标是从单声道音频x和随时间变化的声源位姿P(t)合成双耳音频y。
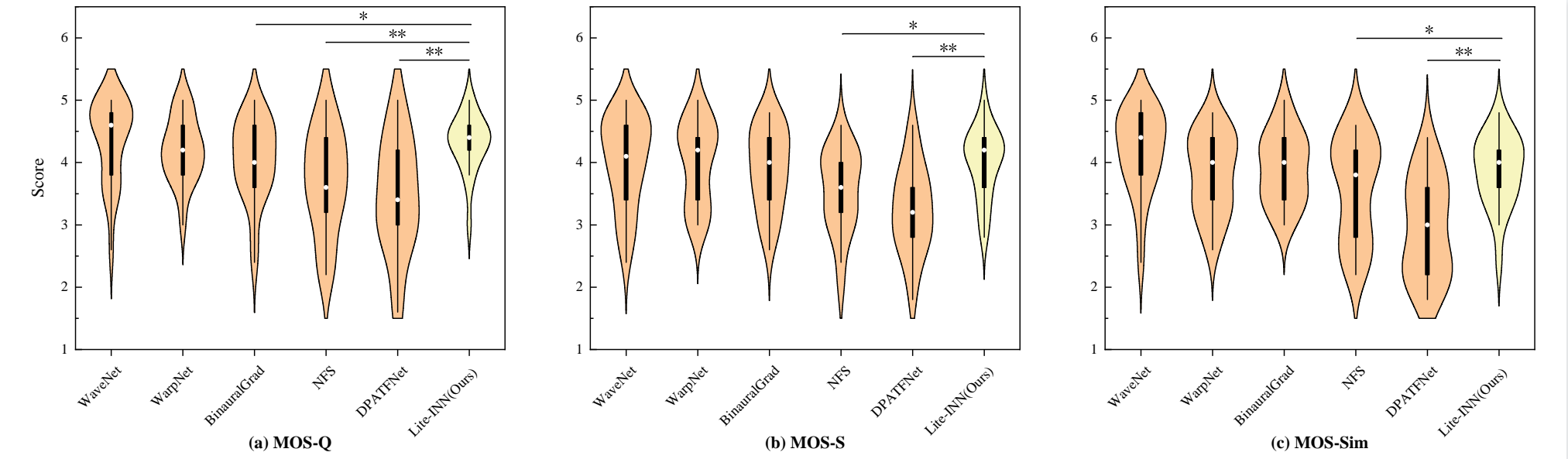 图1:Lite-INN架构示意图。这是一个两阶段过程:第一阶段由时间域翘曲(TDW)网络进行初始合成,第二阶段由隐式双耳校正器(IBC)进行频谱细化。
图1:Lite-INN架构示意图。这是一个两阶段过程:第一阶段由时间域翘曲(TDW)网络进行初始合成,第二阶段由隐式双耳校正器(IBC)进行频谱细化。
完整流程:
- 输入:单声道音频波形
x ∈ R^{B×1×L},以及对应的时变声源位姿P(t) ∈ R^{B×7×T}(包含3维位置p(t)和4维方向q(t))。 - 第一阶段:时间域翘曲(TDW):
- 功能:根据声源的几何位置
p(t)和方向q(t),对单声道音频进行重采样,以近似模拟双耳时间差(ITD),生成初步的左右声道信号(y^init_l, y^init_r)。 - 结构:论文指出该模块改编自
[10],但为减少复杂度而减少了一层卷积层。具体结构未详细说明。
- 功能:根据声源的几何位置
- 第二阶段:隐式双耳校正器(IBC):
- 功能:在时频域对初步信号进行精细的复数增益校正,以建模头相关传递函数(HRTF)等复杂声学效应。
- 数据流:将初步信号
y^init进行短时傅里叶变换(STFT)得到复数谱。对于谱图上的每个时频点(t, f),构造坐标向量c,输入IBC,预测该校正点对应的复数增益G(t, f)。将增益与初步谱图进行逐元素复数乘法,然后通过逆短时傅里叶变换(iSTFT)得到最终的双耳波形y。公式为:y = iSTFT(STFT(y^init) ⊙ G(t, f))。
- IBC内部结构:
- 坐标输入构造:坐标向量
c由以下部分拼接而成:- 声源位姿编码:直接使用
(p, q)。 - 耳朵索引编码:使用one-hot向量表示左/右耳。
- 频率位置编码(FreqPE):对频率索引
f使用正弦位置编码,共N_f=8个频带,生成高频特征向量γ_f(f)。 - 时间位置编码(TimePE):对时间索引
t使用类似正弦编码,共N_t=12个频带。
- 声源位姿编码:直接使用
- 核心网络:一个由
L=3个隐藏层组成的MLP,每层有H=256个神经元,使用SiLU激活函数。最后是一个线性层,输出二维向量(Δlog A, Δφ)。 输出处理:使用tanh函数将原始输出缩放到有界范围,并乘以缩放因子α=0.8和π,得到振幅校正量δ_A(t,f) = α tanh(Δlog A)和相位校正量δ_φ(t,f) = π tanh(Δφ)。最终复数增益为G(t,f) = exp(δ_A) exp(j·δ_φ)。 - 设计动机:这种设计允许网络将双耳校正视为一个连续函数,仅通过查询每个输出点的坐标即可生成校正掩码,无需大型卷积或注意力网络,从而实现极高的参数效率。
- 坐标输入构造:坐标向量
💡 核心创新点
- 将频谱校正建模为隐式神经表示:这是本文最核心的创新。传统方法(如NFS, DPATFNet)使用参数化的网络(如CNN、Transformer)直接预测校正掩码或特征。Lite-INN则将校正任务视为一个从连续输入坐标(位置、方向、时间、频率、耳朵)到输出(复数增益)的函数拟合问题。这种范式转变使得模型可以用一个非常紧凑的MLP来编码复杂的、依赖于多个连续变量的声学映射。
- 局限:之前的方法受限于离散的表示和较大的网络容量。
- 如何起作用:IBC网络学习了一个连续函数。推理时,只需将目标谱图每个点的坐标输入这个共享的MLP,即可获得该点的校正值。
- 收益:实现了极高的参数效率(0.15M参数),同时保持了强大的表达能力,能够建模随位置、频率动态变化的声学特性。
- “先粗后精”的两阶段解耦架构:将任务分解为“几何近似(TDW)”和“精细频谱修正(IBC)”两个阶段。
- 局限:单阶段端到端模型需要从头学习所有复杂性,负担较重。
- 如何起作用:TDW先利用几何知识解决主要的ITD问题,生成一个合理的初始猜测。IBC则专注于用隐式建模来修正更精细的、非线性的频谱细节(如ILD、HRTF滤波)。
- 收益:分工降低了每个模块的学习难度。消融实验表明,两个阶段都是必需的,移除任何一个都会导致性能急剧下降。
- 针对边缘设备的极致轻量化设计:论文从目标(边缘部署)出发,进行了全方位的设计选择以压缩模型。
- 局限:之前的方法追求性能,导致模型庞大(如BinauralGrad有13.8M参数)。
- 如何起作用:采用紧凑的隐式MLP而非大型卷积网络;简化第一阶段的TDW模块(减少一层卷积);使用轻量级的输入表示(位置编码而非密集特征图)。
- 收益:最终模型仅0.15M参数,2.67G MACs,实时因子(RTF)达到0.121,非常适合在资源受限的设备上实时运行。
🔬 细节详述
- 训练数据:使用公开的Binaural Speech数据集[10]。包含约2小时的48kHz音频录音,来自8位说话人。数据包含单声道输入、对应的真值双耳信号,以及120Hz采样的6自由度(6-DoF)声源位姿。使用官方提供的训练、验证、测试集划分。论文中未提及具体的数据预处理或增强方法。
- 损失函数:总损失
L是时域L2损失和频域相位损失的加权和:L = λ1 ||y - y||_2 + λ2 ||∠Y - ∠Y||_1。其中y和y分别是预测和真值波形,Y和Y是它们的复数谱,∠提取相位。λ1=1.0,λ2=0.01。该损失强调波形保真度和相位准确性,这对空间定位至关重要。 - 训练策略:训练100个epoch,批次大小(batch size)为32。使用AdamW优化器。学习率采用余弦退火策略(Cosine Annealing),从
1e-3衰减至1e-6。 - 关键超参数:
- 模型规模:IBC为3层隐藏层,每层256个单元的MLP。
- 信号处理:STFT使用512样本的汉明窗,帧移(hop length)为256样本。
- 位置编码:频率编码带数
N_f=8,时间编码带数N_t=12。 - 输出缩放:振幅缩放因子
α=0.8,相位缩放因子为π。
- 训练硬件:论文中未提供GPU型号、数量或总训练时长。仅在实时因子(RTF)测量中提到使用Intel Xeon Gold 6146 CPU。
- 推理细节:推理时,对于每个输出时频点,都需要构造坐标向量并查询IBC网络,生成完整的增益掩码
G(t, f)。然后进行逐元素复数乘法和iSTFT。论文未提及是否有批处理优化或流式处理设计。 - 正则化或稳定训练技巧:使用tanh函数限制校正量的输出范围(
δ_A ∈ [-α, α],δ_φ ∈ [-π, π]),这有助于训练稳定性和防止预测值溢出。未提及其他正则化技巧。
📊 实验结果
主要基准:Binaural Speech数据集。 评估指标:Wave-ℓ2(波形L2误差),Amplitude-ℓ2(幅度谱L2误差),Phase-ℓ2(相位谱L1误差),IPD-ℓ2(耳间相位差L2误差),以及主观MOS测试(MOS-Q自然度,MOS-S空间化,MOS-Sim相似度)。
- 与最先进基线的定量对比(Table 1):
模型 年份 参数��(M) MACs(G) ↓ Wave-ℓ2 ↓ Amplitude-ℓ2 ↓ Phase-ℓ2 ↓ IPD-ℓ2 ↓ WaveNet [29] arXiv’16 4.65 22.34 0.179 0.037 0.968 1.114 WarpNet [10] ICLR’21 8.59 19.15 0.167 0.048 0.807 1.166 WarpNet* [12] NeurIPS’22 – – 0.157 0.038 0.838 – BinauralGrad [12] NeurIPS’22 13.8 229.4 0.128 0.030 0.837 1.099 NFS [13] ICASSP’23 0.55 3.400 0.172 0.035 0.999 1.250 DPATFNet [14] ICASSP’25 2.42 15.64 0.148 0.037 0.717 1.020 Lite-INN (Ours) – 0.15 2.670 0.167 0.040 0.857 1.233
关键结论:
- 效率优势:Lite-INN的参数量(0.15M)是表中最小的,比最轻量的基线NFS(0.55M)还少72.7%,MACs(2.670G)也是最低的。这直接验证了其轻量化设计的成功。
- 性能权衡:Lite-INN在Wave-ℓ2和Amplitude-ℓ2上接近NFS,在Phase-ℓ2和IPD-ℓ2上优于NFS。虽然其Amplitude-ℓ2和IPD-ℓ2指标略逊于更强的DPATFNet,但差距不大,且以极小的模型规模实现了具有竞争力的客观性能。
- 感知评估(Fig. 2):
图2:MOS听感测试的小提琴图,包括(a) MOS-Q,(b) MOS-S,和(c) MOS-Sim。统计显著性通过成对Wilcoxon符号秩检验确定(表示p < 0.05, *表示p < 0.001)。
关键结论:
- 主观质量对比:在21名参与者的评分中,Lite-INN在MOS-Q、MOS-S和MOS-Sim三项得分上均位列第二,仅次于WaveNet。
- 统计显著性:Wilcoxon检验显示,Lite-INN与WaveNet的感知评分没有统计显著差异(p > 0.05)。同时,Lite-INN的评分显著高于DPATFNet和NFS(p < 0.05)。
- 核心发现:这表明Lite-INN虽然在部分客观指标上非最优,但在人类听觉感知层面,其合成质量与计算量巨大的WaveNet处于同一梯队,且显著优于其他轻量化方法。
- 消融实验(Table 2):
模型变体 Wave-ℓ2 ↓ Amp-ℓ2 ↓ Phase-ℓ2 ↓ IPD-ℓ2 ↓ Lite-INN (完整) 0.167 0.040 0.857 1.233 w/o TDW 0.329 0.051 1.345 1.666 w/o IBC 0.377 0.058 1.038 1.461 w/o FreqPE 0.228 0.044 0.975 1.417 w/o TimePE 0.168 0.040 0.864 1.325
关键结论:
- 两阶段有效性:移除TDW(w/o TDW)或移除IBC(w/o IBC)均导致所有指标大幅恶化,证实了“粗-精”两阶段设计的必要性。
- 频率编码至关重要:移除频率位置编码(w/o FreqPE)导致性能明显下降,特别是相位和IPD误差,说明显式频率坐标对于隐式网络建模频率依赖的声学线索不可或缺。
- 时间编码影响较小:移除时间位置编码(w/o TimePE)对性能影响微弱。论文解释这是因为时间建模任务已主要由TDW阶段承担,IBC可以专注于频谱校正。
- 可解释性分析(Fig. 3):
图3:IBC预测的幅度校正(∆logA)和相位校正(∆φ)随声源位置变化的可视化(对主导强度通道的频率取平均)。(a) 纵向运动(沿y轴),(b) 横向运动(沿x轴)。
关键结论:
- 横向运动:当声源左右移动时,模型预测出相反的幅度校正(同侧耳增益增加,对侧耳减益)和非对称的相位校正。这准确地模拟了双耳水平差(ILD)和双耳时间差(ITD)这两个关键空间线索。
- 纵向运动:当声源前后移动时,双耳校正基本对称。这与物理原理一致,即位于正中面上的声源产生的ILD和ITD可忽略不计。
- 意义:这些可视化证明,IBC不仅是一个黑盒校正器,而且学习到了具有物理可解释性的声学传递函数表示。
⚖️ 评分理由
学术质量:5.0/7
- 创新性(良好):将隐式神经表示(INR)应用于动态双耳频谱校正,是一个新颖且巧妙的思路,实现了显著的模型压缩。
- 技术正确性(良好):两阶段框架设计合理,隐式网络的构建符合标准范式,损失函数选择恰当,实验验证了技术路线的有效性。
- 实验充分性(良好):与6个主流基线进行了全面对比,包含主、客观评估及统计检验,消融实验覆盖了主要设计选择。
- 证据可信度(良好):实验设置描述清晰,主观测试有统计显著性分析支撑,可解释性分析增强了说服力。
- 扣分点:创新是应用层面的迁移,非底层架构或理论突破;消融实验未深入探讨IBC内部结构(深度、宽度)的影响;部分训练细节(硬件、时长)缺失。
选题价值:1.5/2
- 前沿性(中等):双耳合成是音频领域的前沿方向,轻量化是实际部署的核心挑战,本文选题切中要害。
- 潜在影响与应用空间(良好):轻量化模型对AR/VR、移动设备、游戏等领域的实时空间音频应用有直接推动价值。
- 读者相关性(中等):对于从事空间音频、音频信号处理、高效神经网络或边缘AI的读者有较高参考价值。
开源与复现加成:+0.5/1
- 优点:提供了明确的代码仓库链接(GitHub),论文内详细列出了关键超参数(STFT设置、MLP结构、优化器、学习率、损失权重),复现友好度高。
- 缺点:未提及是否公开预训练模型权重,未提供完整的训练硬件信息和训练时长,未提及数据预处理或增强的具体细节。