📄 Leveraging Multiple Speech Enhancers for Non-Intrusive Intelligibility Prediction for Hearing-Impaired Listeners
#模型评估 #语音增强 #数据增强 #预训练 #鲁棒性
✅ 7.5/10 | 前25% | #模型评估 | #数据增强 | #语音增强 #预训练
学术质量 7.5/7 | 选题价值 1.5/2 | 复现加成 0.3 | 置信度 高
👥 作者与机构
- 第一作者:Boxuan Cao, Linkai Li (共同贡献,论文中标记为“*”)
- 通讯作者:Haoshuai Zhou, Shan Xiang Wang (论文中标记为“†”)
- 作者列表:
- Boxuan Cao (Orka Labs Inc., China)
- Linkai Li (Orka Labs Inc., China; Stanford University, Electrical Engineering, United States)
- Hanlin Yu (University of British Columbia, Electrical Engineering, Canada)
- Changgeng Mo (Orka Labs Inc., China)
- Haoshuai Zhou (Orka Labs Inc., China)
- Shan Xiang Wang (Orka Labs Inc., China; Stanford University, Electrical Engineering, United States)
💡 毒舌点评
论文巧妙地将“语音增强”这个预处理步骤变成了可懂度预测模型的一部分,通过“让模型比较增强前后差异”来模拟侵入式方法中“比较干净和嘈杂信号”的过程,这个思路既实用又有点小聪明。然而,论文对跨数据集泛化失败的根本原因(如听者特征差异、录音条件差异)只是简单描述,提出的“2-clips”增强策略虽然有效,但对其为何有效的机制解释略显单薄,更像是一个实用技巧的报告,而非深入的原理探究。
🔗 开源详情
- 代码:论文中未提及自身项目代码的开源计划。但列出了所依赖的语音增强器的开源代码仓库:
- ZipEnhancer:
https://zipenhancer.github.io/ZipEnhancer - MP-SENet:
https://github.com/yxlu-0102/MP-SENet - FRCRN:
https://github.com/alibabasglab/FRCRN
- ZipEnhancer:
- 模型权重:论文中未提及是否公开其训练好的可懂度预测模型权重。
- 数据集:使用了两个数据集:
- CPC3 Dataset:提供了下载链接(
https://doi.org/10.5281/zenodo.17039000)。 - Arehart Dataset:提供了引用论文和DOI链接(
https://doi.org/10.1371/journal.pone.0317266),未直接提供数据下载方式。
- CPC3 Dataset:提供了下载链接(
- Demo:未提及。
- 复现材料:提供了训练的关键超参数(优化器、学习率、批次大小、训练轮数、损失函数)、模型架构图、SFM(Parakeet)的具体版本和选择策略。未提供训练硬件、完整的代码脚本或配置文件。
- 论文中引用的开源项目:
- 语音增强器:ZipEnhancer, MP-SENet, FRCRN(均附有GitHub链接)。
- 语音基础模型:Parakeet (parakeet-tdt-0.6b-v2)(论文描述为“SOTA SFM”)。
- 其他基准模型:CPC2 Champion模型、HASPI模型(作为基线引用,未提供实现)。
📌 核心摘要
- 要解决什么问题:传统评估助听器效果的方法依赖干净的参考语音,这在现实中往往不可得。本文旨在解决无需干净参考信号(非侵入式)即可准确预测听障人群语音可懂度的问题。
- 方法核心:提出一个并行处理框架,同时输入带噪语音和经过语音增强器处理后的增强语音。模型通过交叉注意力机制,显式地学习两者之间的差异,以此作为侵入式方法中“干净-带噪”比较的代理,从而在非侵入式设置下获得丰富的可懂度线索。
- 与已有方法相比新在哪里:相比于直接从单一含噪表征中推断可懂度,本方法创新性地引入了“增强语音路径”作为虚拟参考。此外,论文系统评估了不同语音增强器的影响,并提出了简单的“2-clips”数据增强策略来提升跨数据集泛化能力。
- 主要实验结果如何:实验在CPC3和Arehart两个数据集上进行。最佳集成模型(ZipEnhancer + MP-SENet)在CPC3评估集上的RMSE达到25.60,显著优于强基线CPC2 Champion的26.42(降低0.82)。在跨数据集评估中,应用“2-clips”增强后,模型在未见过的Arehart数据集上的RMSE从31.52大幅降低至28.48,证明了策略的有效性。关键数据见下表:
- CPC3 数据集性能对比
模型 开发集 RMSE 开发集 NCC 评估集 RMSE 评估集 NCC CPC3 Baseline (HASPI) 28.00 0.72 29.47 0.70 CPC2 Champion 24.15 0.81 26.42 0.78 ZipEnhancer + MP-SENet 23.21 0.83 25.60 0.79 - 跨数据集泛化性能
模型 训练集 CPC3 Eval RMSE CPC3 Eval NCC Arehart Test RMSE Arehart Test NCC CPC2 Champion CPC3 26.42 0.78 32.86 0.62 ZipEnhancer + MP-SENet CPC3 25.60 0.79 31.52 0.64 ZipEnhancer + MP-SENet + 2-clips CPC3 + 2-clips 25.33 0.80 28.48 0.72
- CPC3 数据集性能对比
- 实际意义是什么:为临床和工业界提供了一种更实用、可扩展的助听器语音可懂度评估方案,摆脱了对理想条件的依赖,使在真实、复杂声学环境下评估助听器性能成为可能。
- 主要局限性是什么:预测性能强依赖于所选语音增强器的质量(如FRCRN效果不佳)。对跨数据集泛化差异的根本原因分析较浅。所提出的“2-clips”增强策略虽然有效,但作用机制解释不足。此外,模型需要额外运行语音增强器,增加了计算开销。
🏗️ 模型架构
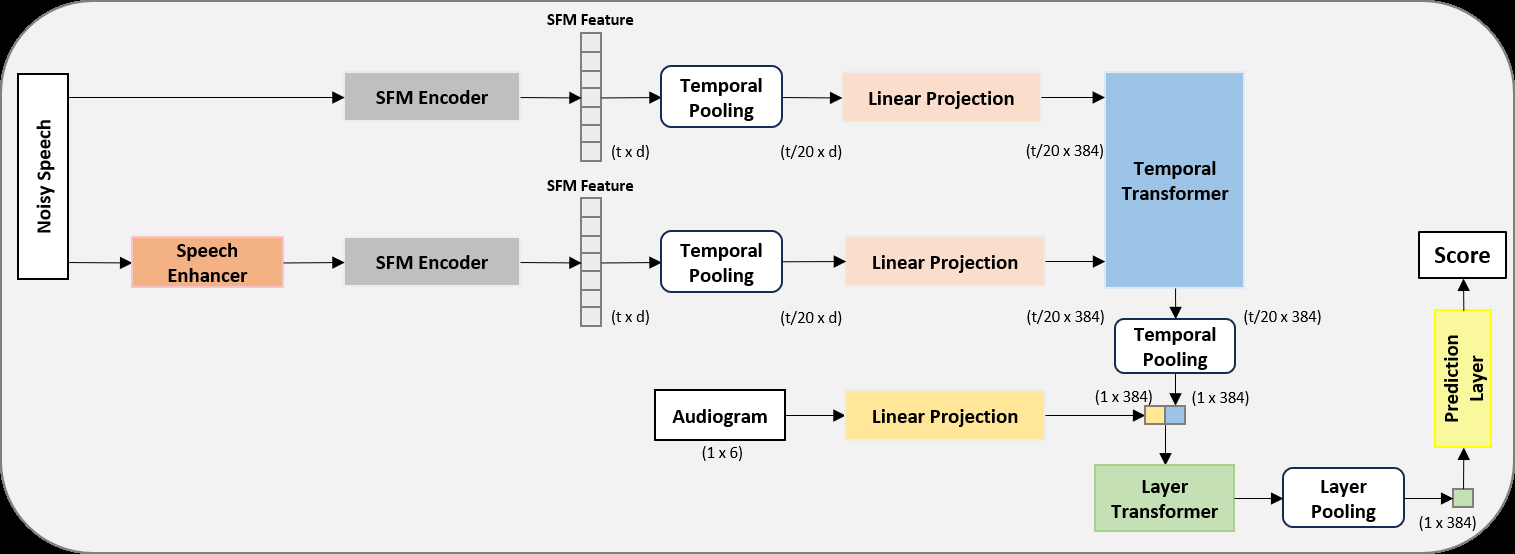
模型的整体架构如图1(a)所示,是一个端到端的可微分框架,旨在处理双耳语音信号。其核心是构建了并行的“噪声路径”和“增强路径”来提取可懂度相关表征。
完整输入输出流程:
- 输入:带噪双耳语音信号,以及对应的听者听力图(6个频率点的听力阈值)。
- 输出:一个0-100之间的标量,代表预测的语音可懂度分数(如HINT分数)。
主要组件及功能:
- 语音增强器 (Speech Enhancer):如图1(a)左上角所示,输入带噪语音,生成对应的增强语音。本文使用了三种预训练增强器(ZipEnhancer, MP-SENet, FRCRN)或其集成。其作用是生成一条更清晰的语音路径,为后续的比较推理提供虚拟参考。
- 语音基础模型编码器 (SFM Encoder):一个预训练的、参数冻结的模型(本文使用Parakeet)。它独立地对带噪语音和增强语音进行编码,提取高级声学特征。使用其第18层的输出。
- 特征编码层 (Feature Encoder Layer):将SFM输出的特征进行平均池化和20倍下采样,再通过线性投影映射到384维空间。此操作为两条路径生成紧凑的中间表示。
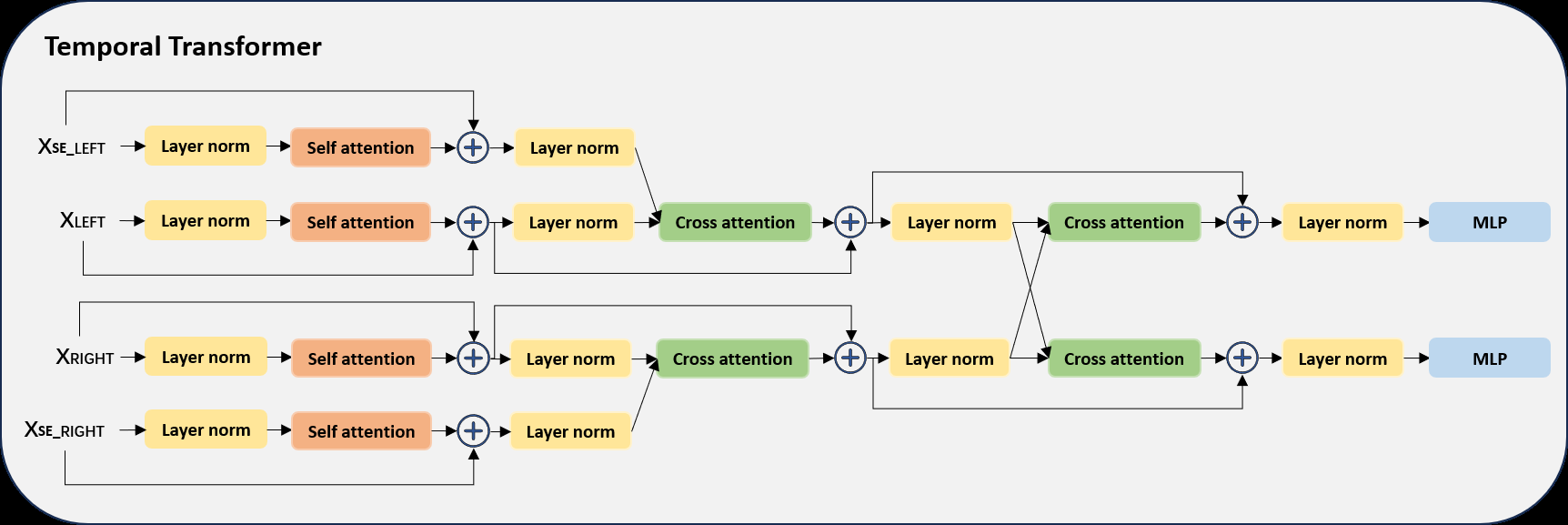
- 时序Transformer (Temporal Transformer):核心交互模块。如图1(b)所示,对于双耳信号的每一侧耳,带噪特征和增强特征首先分别经过自注意力块。随后,带噪特征作为Query,增强特征作为Key和Value进行交叉注意力计算。此设计显式地让模型学习从增强信号中“检索”能改善带噪信号可懂度判断的信息,模拟了侵入式度量中的比较过程。最后通过双耳交叉注意力块和平均池化,输出一个1x384的向量。
- 听者投影层 (Audiogram Projection Layer):将6维听力图通过线性层映射到384维,与听者生理特征相关。
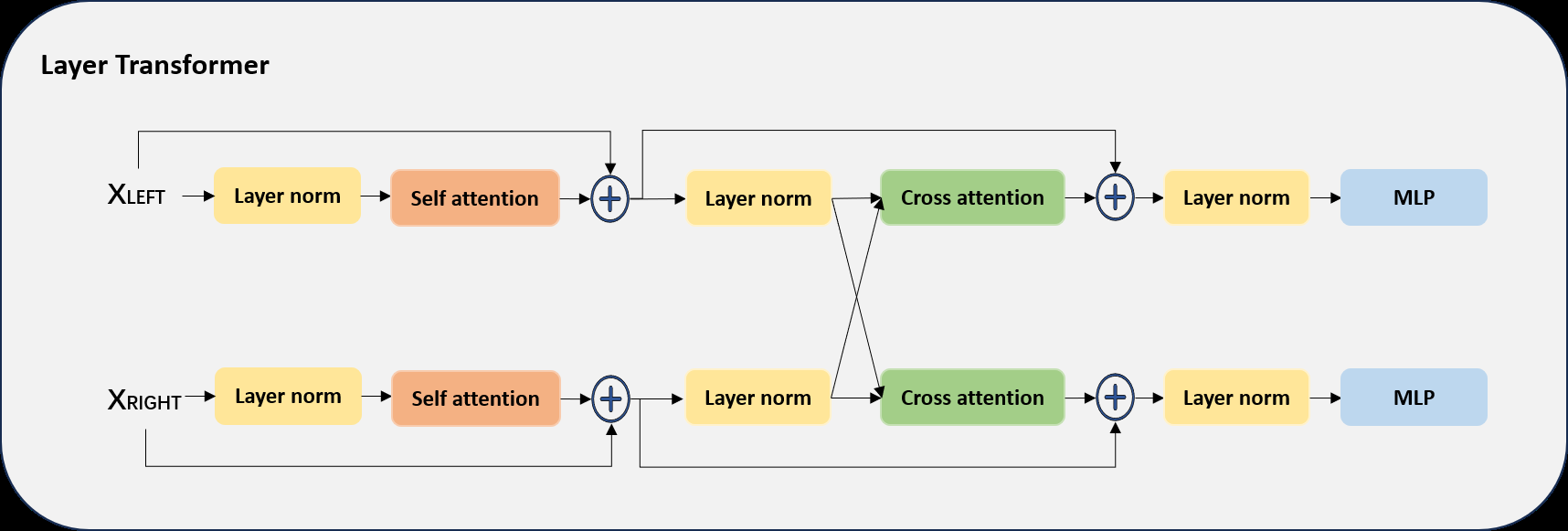
- 层Transformer (Layer Transformer):如图1(c)所示,将时序Transformer的输出(代表语音特征)与听者投影层的输出(代表听力损失特征)在特征维度上拼接(2x384),然后输入此Transformer块进行跨模态交互,使模型能根据个体听力损失情况对语音特征进行“调制”。最后通过全局平均池化得到1x384的表示。
- 预测层 (Prediction Layer):对双耳各自独立处理得到的表示取平均,通过一个线性层和sigmoid激活函数,最后乘以100,映射到最终的可懂度分数。
关键设计选择及动机:
- 并行增强路径:动机是借鉴侵入式方法成功的核心——比较,但在无干净参考时,用强大的增强器输出作为“近似参考”。
- 交叉注意力机制:在时序Transformer中显式建模两条路径的关系,是实现“比较推理”的关键技术手段。
- 分阶段处理:先分别处理时序依赖(时序Transformer),再整合听者特征(层Transformer),逻辑清晰,模仿了人类听觉感知中“声音信号分析”与“个体听力特性匹配”的过程。
- 参数共享:图1中相同颜色的模块参数共享,提高了模型效率并保证了双耳处理的一致性。
💡 核心创新点
- 非侵入式参考代理框架:是什么:提出一种架构,利用预训练语音增强器生成增强语音,与带噪语音并行输入模型,通过交叉注意力让模型学习两者差异。之前局限:传统非侵入式方法仅从单一含噪信号中推断可懂度,缺乏明确的比较参照,限制了性能上限。如何起作用:增强路径提供了与带噪信号高度相关但质量提升的信号,其差异蕴含了可懂度相关的失真和增强信息。收益:使非侵入式模型能够获得类似于侵入式方法(需干净参考)的比较推理能力,在CPC3和Arehart数据集上均超越了强基线。
- 增强器集成与特性分析:是什么:系统评估了三种不同架构的SOTA语音增强器在可懂度预测任务中的作用,并研究了其集成效果。之前局限:以往研究可能仅尝试单一增强器或未深入分析增强器特性与预测性能的关系。如何起作用:论文发现预测性能与增强器的客观增强质量(如WB-PESQ)正相关。集成互补的增强器(如ZipEnhancer + MP-SENet)能提供更丰富、稳健的虚拟参考信号。收益:指导了增强器的选择与组合,集成模型取得了最优性能。
- 2-clips 数据增强策略:是什么:一种简单的数据增强方法,在训练时随机拼接同一听者的两段语音,用其可懂度均值作为新标签。之前局限:跨数据集评估时性能严重下降,主要原因是听者特征、录音条件等数据集间差异。简单增加数据量(如加入正常听力者数据)效果不佳。如何起作用:该策略在保持听者特定听力损失特性的同时,通过拼接创造了更长、声学上下文更多样的语音样本,迫使模型学习更泛化的可懂度特征,而非过拟合到特定数据集的细节。收益:显著提升了模型在未见过的数据集(如从CPC3训练,在Arehart测试)上的鲁棒性(见表3)。
🔬 细节详述
- 训练数据:
- CPC3数据集:15,464个训练样本(双耳),33位听障听众,包含助听器输出、干净参考(训练时未使用)、可懂度分数和听力图。采样率32kHz,处理时重采样至16kHz。
- Arehart数据集:8,100个双耳样本,包含15位正常听力和15位听障听众。使用时仅用6,480个训练样本(12位HI听众),1,620个测试样本(3位HI听众)。采样率22.05kHz,重采样至16kHz。
- 数据增强:除2-clips策略外,还尝试在训练集中加入Arehart的15位正常听力听众数据,但效果有限。
- 损失函数:使用Huber损失函数(未说明具体公式)。
- 训练策略:
- 优化器:Adam(β1 = 0.9, β2 = 0.98)。
- 学习率:4e-5。
- 训练轮数:50 epochs。
- 批次大小:128。
- 验证:3折交叉验证(训练集内80%训练,20%验证),选择验证集RMSE最低的模型。
- 推理:在测试集上平均3折模型的预测分数。
- 关键超参数:
- SFM:选用Parakeet (parakeet-tdt-0.6b-v2),包含6亿参数。经评估选择其第18层输出作为特征。
- 中间表示维度:时序Transformer输出后经投影为384维。
- 特征下采样:SFM特征在进入时序Transformer前进行平均池化,下采样因子为20。
- 训练硬件:论文中未说明。
- 推理细节:见“训练策略”中推理部分。未提及流式设置。
- 正则化或稳定训练技巧:论文中未提及,如Dropout、权重衰减等。SFM和增强器参数被冻结(frozen),这是一种防止过拟合和稳定训练的常见做法。
📊 实验结果
论文在CPC3和Arehart两个主要数据集上进行了全面实验。
主要基准对比(CPC3数据集,见表1):
- 最强基线:CPC2 Champion模型(非侵入式),在评估集上RMSE为26.42,NCC为0.78。
- 本文最佳单增强器模型:ZipEnhancer模型,评估集RMSE 25.87,比基线降低0.55。
- 本文最佳集成模型:ZipEnhancer + MP-SENet,评估集RMSE 25.60,比CPC2 Champion基线显著降低0.82,同时NCC提升至0.79。
- 侵入式参考模型:作为上界参考,其评估集RMSE为26.18,低于部分非侵入式基线但高于本文的最佳非侵入式模型,突显了本框架的有效性。
跨数据集泛化性能(见表3):
- 问题:在CPC3上训练的模型,在Arehart上测试时性能急剧下降���如CPC2 Champion从26.42 RMSE升至32.86 RMSE)。
- 解决方案验证:
- 加入正常听力数据:收益微乎其微(Arehart测试RMSE从31.52降至30.14)。
- 2-clips数据增强:效果显著。在CPC3训练集上应用2-clips增强后,模型在未见过的Arehart测试集上RMSE从31.52大幅降低至28.48,NCC从0.64提升至0.72,展现了强大的泛化能力。同时,在CPC3评估集上的性能也略有提升(RMSE从25.60降至25.33)。
其他结果(见表2):
- 在Arehart数据集(无干净参考)上进行非侵入式评估,本文最佳集成模型(RMSE 26.12)优于CPC2 Champion基线(RMSE 27.00),差异为0.88。
关键结论:
- 语音增强器的质量直接影响可懂度预测性能,性能与增强器客观指标(PESQ)正相关。
- 互补的增强器集成能带来性能提升。
- 简单但针对性强的数据增强(2-clips)比增加不同类别数据(正常听力)更能有效解决跨数据集泛化问题。
- 本文提出的非侵入式框架达到了与CPC3竞赛中最佳非侵入式系统(E019: RMSE 25.31, NCC 0.79)高度竞争的性能(RMSE 25.33, NCC 0.80)。
⚖️ 评分理由
- 学术质量:6.5/7。论文提出了一个设计合理、逻辑清晰的框架,通过引入增强路径和交叉注意力,巧妙地解决了非侵入式预测中缺乏比较参考的核心问题。实验设计系统且充分,包括多种增强器对比、集成分析、跨数据集泛化测试和消融实验(数据增强策略对比),证据可信。创新性适中,属于有效的技术改进而非范式革命。技术细节描述基本完整,但对部分模块(如层Transformer内部交互)的细节和可复现性关键信息(如硬件)有所缺失。
- 选题价值:1.5/2。聚焦于助听器性能评估这一重要且实际的医疗健康问题,非侵入式方法具有很高的实用价值。选题前沿,紧跟利用预训练模型解决实际音频任务的趋势。对从事语音处理、健康科技或辅助技术的读者有直接参考价值。但任务领域相对垂直。
- 开源与复现加成:0.3/1。论文明确引用了所用增强器和SFM的开源仓库,提供了主要的超参数设置(优化器、学习率、批大小、损失函数),这对复现至关重要。然而,论文未提供其自身模型的代码、权重或完整的训练配置文件,也未说明训练使用的GPU型号和时间,这显著影响了研究的可复现性和透明度。因此,加成较低。