📄 Leveraging Diffusion U-Net Features for Predominant Instrument Recognition
#音乐信息检索 #扩散模型 #特征学习 #低资源
🔥 8.0/10 | 前25% | #音乐信息检索 | #扩散模型 | #特征学习 #低资源
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Charis Cochran(Drexel University, USA)
- 通讯作者:未说明
- 作者列表:Charis Cochran(Drexel University, USA)、Yeongheon Lee(University of Pennsylvania, USA)、Youngmoo Kim(Drexel University, USA)
💡 毒舌点评
亮点:论文巧妙地将用于生成的扩散模型“降维”用作特征提取器,并系统验证了其在音频识别任务(PIR)上的潜力,思路新颖且具有启发性。短板:实验结果虽然显示了扩散特征的竞争力,但整体上并未显著超越一个相对陈旧的CNN基线(Han et al., 2017),且部分乐器(如小号、大提琴)性能下降,暴露出该方法在特定音色上的脆弱性和数据集局限。
🔗 开源详情
- 代码:提供了GitHub仓库链接:
https://github.com/charisrenee/InstrumentRecognitionWithDiffusion。 - 模型权重:论文中未明确提及是否公开预训练的扩散模型(Model 0/A/B/C)或最终分类器的权重。
- 数据集:明确说明并发布了新创建的OpenPIR数据集,可在上述GitHub仓库获取。IRMAS是公开数据集。
- Demo:论文中未提及在线演示。
- 复现材料:提供了扩散模型训练参数表格(表1)、特征提取和分类器评估的系统化流程(图1),代码仓库应包含相关实现。但部分训练细节(如优化器、学习率)未在论文正文中详述。
- 论文中引用的开源项目:引用了
a-unet,audio-diffusion-pytorch用于构建扩散模型;SoundStream用于声码器;IRMAS、OpenMIC作为数据源。
📌 核心摘要
这篇论文旨在解决音乐信息检索(MIR)中的主要乐器识别(PIR)任务面临的数据标注有限和类间性能差异大的问题。其核心方法是:首次将预训练的音频扩散模型(U-Net结构)作为固定的特征提取器,通过探究其在不同去噪时间步(t)和网络层的中间表征,搭配轻量级分类器头(如MLP、CNN)来完成PIR任务。为弥合训练集(单标签)与测试集(多标签)的不匹配,论文还提出了一个新的多标签注释数据集OpenPIR。实验表明,在低噪声条件下的瓶颈层特征最具判别力,且使用OpenPIR数据能一致提升所有模型的性能。虽然扩散特征的整体性能(例如,最佳模型的Micro F1接近但未全面超越Han et al. CNN基线的0.65)尚未成为新的SOTA,但在电吉他、原声吉他和钢琴等特定乐器上已展现出超越基线的潜力。这项工作为“生成模型可用于判别性任务”在音频领域提供了早期证据,指明了探索统一生成-识别框架的方向。其主要局限性在于,对于大提琴、单簧管等乐器的识别依然困难,且所用扩散模型参数量(240M)远大于分类器,整体方案效率有待评估。
🏗️ 模型架构
本文的核心并非提出一个端到端的新模型,而是利用一个已有的扩散模型作为特征提取器,再外接一个轻量级分类器。其完整流程(见图1)如下:
特征提取阶段:
- 输入:一段音频的梅尔频谱图。
- 加噪:使用DDIM调度器,根据选定的时间步
t,向输入频谱图中添加噪声。 - 单步去噪:将加噪后的频谱图输入预训练且冻结的扩散U-Net,执行单步去噪(不进行条件生成,即使用空向量条件)。这一步的目的是“激活”模型在该噪声水平下的内部表征,而非真正去噪。
- 中间特征收集:从U-Net的指定层
L(如最后下采样块、瓶颈层、第一个上采样块)提取激活值。这些激活值可以是全局平均池化后的1D向量(适用于MLP),也可以是未池化的2D特征图(适用于CNN、CRNN、Attention分类器)。
分类器头训练与推理阶段:
- 分类器头:论文评估了四种轻量级分类器:MLP(约13万参数)、CNN(约16万参数)、CRNN(约20万参数)、Attention(约33万参数)。
- 训练:将提取的特征输入分类器头,使用IRMAS(或IRMAS+OpenPIR)数据集进行有监督训练。扩散U-Net本身保持冻结,不参与反向传播。
- 推理:对于新的测试音频,重复特征提取步骤,将特征输入训练好的分类器头得到乐器标签。
扩散模型本体:其骨干网络改编自
a-unet和audio-diffusion-pytorch,是一个包含三个上/下采样阶段和瓶颈层的U-Net,滤波器数量从128到1024。使用预训练的T5文本编码器的嵌入进行乐器条件注入。训练和处理的数据是16kHz的梅尔频谱图。
关键设计选择与动机:
- 冻结并单步推理:旨在高效地探测扩散模型内部“学到”的、与生成任务相关但对识别任务有用的音色表示,避免了昂贵的多步去噪或微调整个大模型。
- 系统性参数搜索:借鉴计算机视觉领域的研究,系统性地探索时间步
t、层L和分类器架构这三个关键变量,以找到最佳的特征利用组合。
💡 核心创新点
- 首次在音频/PIR领域探索扩散模型中间特征的判别能力:这是本文最核心的创新。之前扩散模型在MIR中主要用于生成或音色转换,本文首次系统性地研究了其作为特征学习器在判别任务(PIR)上的有效性。
- 提出OpenPIR多标签数据集:针对IRMAS数据集训练集(单标签)与测试集(多标签)不匹配的关键痛点,作者创建并发布了一个包含多主要乐器标注的小型互补数据集,以提升训练与评估的一致性。
- 证明简单分类器在扩散特征上的有效性:结果表明,即使是最简单的MLP分类器,搭配从扩散模型提取的低噪声瓶颈层特征,也能取得具有竞争力的性能。这降低了应用门槛,突出了扩散特征本身的质量。
🔬 细节详述
- 训练数据:
- 扩散模型训练:Model 0(基线)在IRMAS和Solo数据集上训练。Model A/B/C在Model 0基础上,分别用IRMAS或IRMAS+OpenPIR微调100个epoch。
- 分类器头训练:在提取的特征上,使用IRMAS训练集或IRMAS+OpenPIR训练集进行训练。未说明具体的损失函数(如交叉熵)、优化器、学习率等详细训练策略。
- 模型细节:
- 扩散U-Net:240M参数,三阶段上/下采样,滤波器通道数[128, 256, 512, 1024]。条件注入使用预训练冻结的T5嵌入。
- 分类器头:MLP(128隐藏单元),CNN(单层3x3卷积),CRNN(单GRU隐藏128),Attention(4头,隐藏128)。
- 训练硬件:所有扩散模型均在单张V100 GPU上以batch size 64训练。
- 输入音频:使用16kHz采样率,梅尔频谱图参数:窗口大小640,跳步320,128个频带。处理片段长度:Model 0为1秒,Model A/B/C为2秒。
- 推理:生成音频时使用冻结的SoundStream声码器。但识别任务中仅使用扩散U-Net进行特征提取,未涉及声码器。
- 关键超参数:系统搜索的噪声时间步
t、网络层L是主要变量。未说明扩散模型训练的具体学习率、调度策略等。
📊 实验结果
论文的核心实验是比较不同扩散模型变体(A/B/C)、不同数据组合(IRMAS / IRMAS+OpenPIR)、不同特征提取参数(t, L)以及不同分类器头,在IRMAS测试集上的Micro F1分数。最强基线是重新实现的Han et al. CNN(F1=0.65)。
由于论文未提供完整的数字结果表格,关键结论和部分数据从图3中提取:
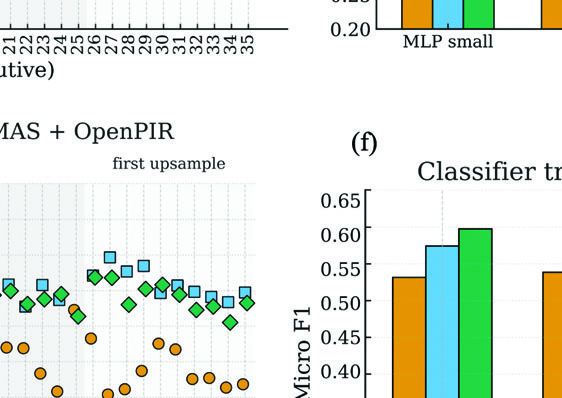
主要实验结果:
- 特征选择规律:最佳性能出现在低噪声时间步(t小)和瓶颈层(第二、三瓶颈层)。这与计算机视觉领域的发现一致。
- 分类器对比:更复杂的分类器(如Attention)通常比简单MLP更好,但MLP也表现出色。
- 数据影响:引入OpenPIR数据集一致提升了所有模型(A、B、C)在所有分类器上的性能。在扩散模型训练阶段就使用OpenPIR(Model B, C)比仅在分类器训练阶段使用(Model A + OpenPIR分类器)效果更优。
- 模型演进:从Model A -> Model B -> Model C,整体性能呈上升趋势,表明优化扩散特征有助于提升下游识别。
- 与基线对比:
- 总体:扩散特征的最佳组合性能接近但未全面超越Han CNN基线(0.65)。图3显示,最佳的“IR”(仅IRMAS训练)和“IR+OP”(IRMAS+OpenPIR训练)模型的总体F1大约在0.6左右。
- 类别差异:扩散特征在电吉他、原声吉他、钢琴上的F1分数高于基线。但在小号、大提琴、单簧管上表现较差,甚至低于基线。
关键消融/对比实验:
- 噪声水平扫描:证明了低噪声的重要性。
- 层扫描:证明了瓶颈层特征的优越性。
- 分类器扫描:证明了简单分类器的可行性。
- 数据集消融:证明了OpenPIR的价值。
⚖️ 评分理由
- 学术质量:5.5/7 - 创新性强(跨任务迁移思路),技术路线清晰,实验设计系统(探索了t, L, 分类器等多个变量),证据可信(结论与CV领域工作呼应)。扣分点在于:1)整体结果未显著超越一个2017年的基线,说服力打了折扣;2)部分实验细节(如损失函数、分类器具体训练参数)缺失;3)提出的OpenPIR数据集规模较小(1234样本),其普适性有待验证。
- 选题价值:1.5/2 - 选题具有前沿性(生成模型用于判别任务)和启发性,对MIR社区有明确价值。但PIR本身是相对垂直的MIR子任务,应用范围不如通用语音或音频任务广泛,故选题价值分未给满。
- 开源与复现加成:0.5/1 - 论文明确提供了GitHub代码仓库链接,并创建了新的OpenPIR数据集,提供了模型训练参数表格,复现基础较好。扣分点在于:未提供完整的训练超参数(如学习率)、模型权重是否开源未明确说明、详细的评估脚本等是否齐全未知。