📄 LESS: Large Language Model Enhanced Semi-Supervised Learning for Speech Foundational Models Using in-the-wild Data
#语音识别 #语音翻译 #半监督学习 #大语言模型 #多语言
✅ 7.5/10 | 前25% | #语音识别 #语音翻译 | #半监督学习 #大语言模型 | #语音识别 #语音翻译
学术质量 7.0/7 | 选题价值 7.5/2 | 复现加成 1.0 | 置信度 高
👥 作者与机构
- 第一作者:Wen Ding(NVIDIA Corporation)
- 通讯作者:未说明
- 作者列表:Wen Ding(NVIDIA Corporation),Fan Qian(NVIDIA Corporation)
💡 毒舌点评
这篇论文巧妙地将一个在NLP领域成熟的工具(LLM)转化为解决语音SSL中“脏数据”问题的利器,思路实用且效果显著,特别是在AST任务上SOTA的结果很有说服力。然而,其验证的“语音大模型”高度集中于Whisper,缺乏对其他架构(如USM, MMS)的验证,让人好奇该框架是否具有更普适的迁移能力。
🔗 开源详情
- 代码:提供。论文明确提供了开源配方的GitHub仓库链接:
github.com/nvidia-china-sae/mair-hub/tree/main/speech-llm/less_recipe。 - 模型权重:未提及开源作者自己训练的模型权重。但所使用的基础模型(Whisper Large-v3, Yi-Large, LLaMA-3-70B)均为公开可用的模型。
- 数据集:
- 有标签数据(AISHELL-1, Fisher, Callhome)是公开的标准数据集。
- 论文中使用的“真实世界”YouTube数据集(1590小时普通话, 868小时西班牙语)是自行收集的,论文未说明其是否公开或如何获取。
- Demo:论文中未提及在线演示。
- 复现材料:提供了开源配方,包含训练流程、依赖工具(K2 Icefall)和实验配置的关键细节(如学习率, 模型, LLM选择, 过滤阈值),复现基础较好。
- 论文中引用的开源项目:
- K2 Icefall toolkit (https://github.com/k2-fsa/icefall)
- Silero VAD (https://github.com/snakers4/silero-vad)
- Whisper Large-v3 (Hugging Face)
- Yi-Large (通过NVIDIA NIM访问)
- LLaMA-3-70B (通过NVIDIA NIM访问)
- Qwen2.5-coder-32b-instruct (通过NVIDIA NIM访问)
- ESPnet (用于对比的基线结果)
📌 核心摘要
- 要解决的问题:当前最先进的语音基础模型(SFMs)在半监督学习中利用从真实世界(in-the-wild)收集的未标注音频数据时,面临一个核心挑战:这些数据声学环境复杂多样,模型生成的伪标签质量较低,导致训练效果不佳。
- 方法核心:提出了LESS框架。该框架在标准的无教师-学生(Noisy Student Training)SSL流程中,引入一个文本大语言模型(LLM)作为“校正器”,对SFMs(如Whisper)在未标注音频上生成的伪标签(ASR转录或AST翻译文本)进行修正。随后,通过一个基于WER(词错误率)变化的数据过滤策略,筛选出LLM修正后质量更高的伪标签,与原始有标签数据混合,用于迭代微调SFMs。
- 与已有方法相比新在哪里:传统SSL方法要么专注于训练策略优化,要么使用小型模型和经过筛选的无标签数据。LESS的创新在于:(a) 首次系统性地将LLM集成到面向真实世界、嘈杂数据的语音SSL流程中,作为独立的伪标签优化模块;(b) 提出了“WER Prompting”技巧,让LLM在生成修正文本时同时输出估计的WER,可辅助过滤;(c) 专门设计并验证了该框架在“真实世界”数据场景下的有效性,而不仅仅是使用现有干净数据集忽略其标签。
- 主要实验结果:
- 中文ASR:在WenetSpeech测试集上,相比仅使用AISHELL-1训练的监督基线,经过三轮LESS迭代训练后,WER从17.7%绝对下降至13.9%,降幅达3.8%。在领域内测试集AISHELL-1/2上,WER保持稳定(约3.0%/5.2%)。
- 西语-英语AST:在Callhome和Fisher测试集上,LESS方法达到了34.0和64.7的BLEU分数,显著优于监督基线(33.5, 64.2)和不加LESS的标准NST(33.2, 64.0)。
- 消融实验:验证了通用LLM(Yi-Large)比代码专精LLM(Qwen2.5-coder)更适合纠错;WER提示词(WER Prompting)和严格的过滤阈值(0.1)能带来性能提升。
- 实际意义:该框架为利用海量、易获取但质量低劣的网络语音数据训练更强健、适应性更广的语音大模型提供了一种有效的工程化路径,有助于降低对昂贵精标数据的依赖。
- 主要局限性:研究中使用的语音大模型(SFMs)主要局限于Whisper Large-v3,未验证该方法在其他主流架构(如USM, MMS)上的泛化能力。此外,对于AST任务,仅进行了一轮迭代实验,多轮迭代的潜力和收敛情况有待探索。真实世界数据的噪声和多样性控制标准未深入讨论。
🏗️ 模型架构
论文提出的是一个迭代优化的流水线框架(LESS),而非一个独立的新模型架构。其核心组件和数据流如下:
- 初始种子模型(T=0):使用有标签的监督数据(如AISHELL-1用于ASR, Fisher+Callhome用于AST)对一个预训练的语音基础模型(SFMs,本研究中为Whisper Large-v3)进行微调,得到初始模型。
- 数据收集与处理:从YouTube等平台收集“真实世界”的无标签音频(本研究收集了1590小时普通话和868小时西班牙语数据)。使用Silero VAD模型检测语音活动,将音频分割并拼接成不超过20秒的片段。
- 伪标签生成:将处理后的无标签音频输入当前的SFMs(初始或上一轮迭代的模型),自动生成文本假设(伪标签)。对于ASR任务是转录文本,对于AST任务是翻译文本。
- LLM校正:将SFMs生成的原始伪标签文本发送给一个文本LLM(如Yi-Large或LLaMA-3),并通过特定的提示词(Prompt)要求LLM检查并修正其中的错误。论文展示了用于ES-to-EN AST的提示词示例(图1)。
- 数据过滤:计算原始伪标签(贪心解码结果)与LLM校正后文本之间的WER(作为近似质量指标)。设定一个过滤阈值(默认为0.1),仅保留WER低于该阈值的样本,即LLM修正幅度较小、被认为质量较高的样本。
- 迭代训练:将过滤后高质量的“LLM校正伪标签”数据与原始有标签数据按一定比例混合,用于微调当前的SFMs,得到一个新的“学生模型”,并作为下一轮迭代的起点。该过程重复直至收敛。
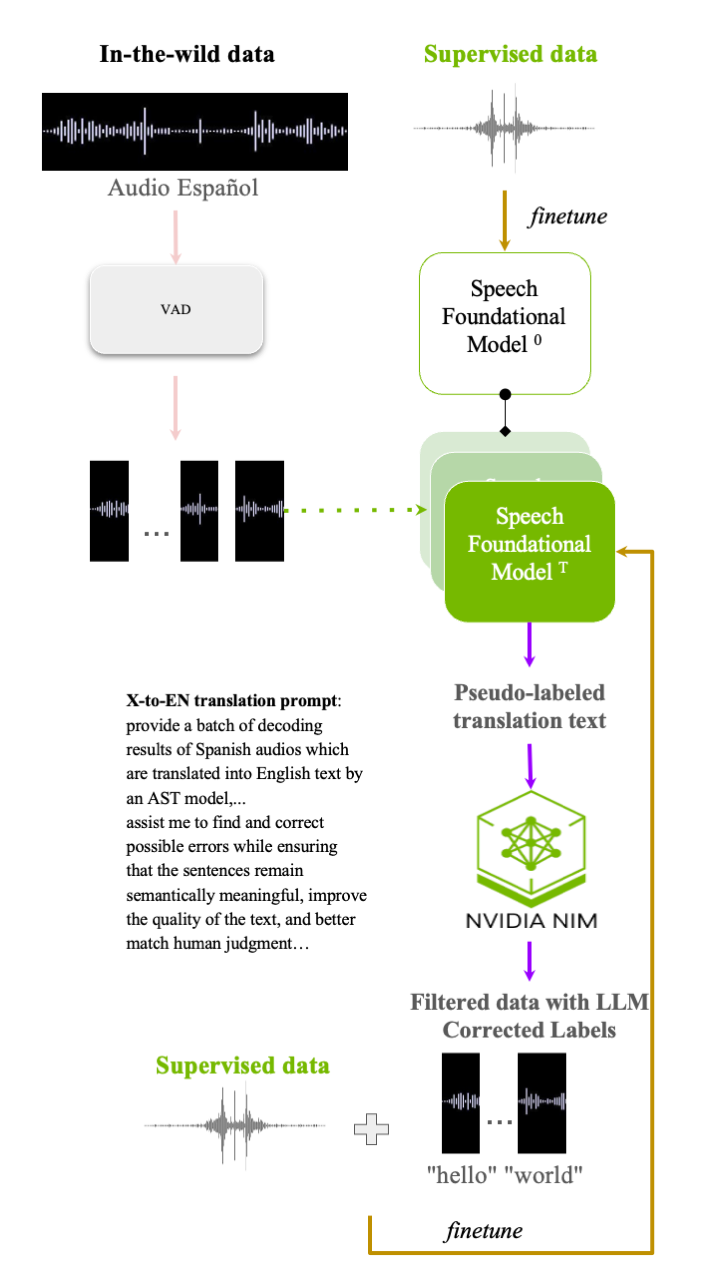 图1展示了以ES-to-EN AST任务为例的LESS流水线。橙色箭头表示初始微调,后续迭代包括:对YouTube原始音频进行VAD分割 -> 使用初始SFM生成英语翻译 -> LLM进行文本校正 -> 数据过滤 -> 使用混合数据微调SFM得到新模型。
图1展示了以ES-to-EN AST任务为例的LESS流水线。橙色箭头表示初始微调,后续迭代包括:对YouTube原始音频进行VAD分割 -> 使用初始SFM生成英语翻译 -> LLM进行文本校正 -> 数据过滤 -> 使用混合数据微调SFM得到新模型。
关键设计选择及动机:
- LLM作为外部校正器:动机在于LLM在海量文本数据上训练,具备强大的语言模型先验和纠错能力,可以弥补纯语音模型在文本流畅性、事实一致性上的不足。
- 基于WER的过滤策略:动机是假设LLM修正与原始假设差异过大的样本,其修正可能是错误的或引入新错误。该策略旨在筛选出LLM“小幅修正即可优化”的可靠样本。
- 迭代式半监督学习:沿用经典的Noisy Student Training框架,通过逐步提升模型能力和伪标签质量来利用无标签数据。
💡 核心创新点
将LLM作为伪标签质量提升的“校正器”集成到语音SSL流程中:
- 局限:传统语音SSL直接使用SFMs生成的伪标签,这些标签在真实世界嘈杂数据上错误较多。先前使用语言模型的工作(如[18, 19])多局限于小型模型或特定场景(如code-switching)。
- 创新与作用:LESS框架将强大、公开的文本LLM作为一个模块化组件引入,专门负责对语音模型输出的文本进行后处理纠错。这充分发挥了LLM的语言知识优势。
- 收益:显著提升了伪标签质量,从而在下游训练中带来稳定的性能增益(如ASR中wenet meeting WER降低3.8%)。
提出“WER Prompting”提示词技术:
- 局限:简单的纠错提示可能无法引导LLM进行最有效的修正。
- 创新与作用:在提示词中要求LLM在生成修正文本时,同时输出其估计的WER值。虽然LLM估计的WER不准确,但这个额外的生成目标可以引导LLM更仔细地对比原始文本和修正内容,进行更审慎的修正。
- 收益:实验证明,带有WER Prompting的提示词能带来更好的性能(如表3中模型D优于C)。
专门针对“真实世界”数据的鲁棒性优化框架:
- 局限:许多SSL研究使用的是相对干净、经过筛选的“无标签”数据集(如LibriSpeech-unlabeled),未能充分应对真实网络数据(in-the-wild)固有的高噪声、多样性和领域偏移。
- 创新与作用:LESS从数据收集(直接来自YouTube)、处理(仅做VAD切分)到整个校正-过滤流程,都设计用于应对这种复杂性。它不回避数据的“脏”,而是通过LLM去“洗”数据。
- 收益:实验表明,该方法能有效提升模型在噪声更大、更多样化的测试集(如WenetSpeech)上的表现,增强了模型的泛化鲁棒性。
🔬 细节详述
- 训练数据:
- 有标签(监督)数据:
- ZH ASR:AISHELL-1(约180小时)。
- ES-to-EN AST:Fisher(170小时)和Callhome(15小时)的电话语音及其英文翻译。
- 无标签(真实世界)数据:
- ZH ASR:从YouTube收集的普通话音频,经VAD处理后约1590小时。
- ES-to-EN AST:从YouTube收集的西班牙语音频,经VAD处理后约868小时。
- 预处理/增强:仅对无标签数据使用Silero VAD进行语音端点检测和分割,合并成≤20秒的片段。未提及其他数据增强。
- 有标签(监督)数据:
- 损失函数:论文未明确说明具体损失函数名称。根据上下文和使用K2 Icefall工具包,可以推断使用标准的序列到序列(如Transducer或CTC/Attention混合)损失,用于训练ASR和AST任务。
- 训练策略:
- 每轮迭代中,微调Whisper Large-v3模型5个epoch。
- 学习率设置为 1e-5。
- 使用模型平均(Model averaging)。
- 优化器:未说明。
- 调度策略:未说明。
- Batch size:未说明。
- 训练框架:使用 K2 Icefall toolkit。有标签数据和伪标签数据的混合方式为“加权多路复用”(weighted multiplexing),具体权重未说明。
- 关键超参数:
- 语音大模型:Whisper Large-v3(约1.55亿参数,论文未给出具体参数量)。
- 大语言模型:Yi-Large(用于ASR)和LLaMA-3-70B(用于AST)。论文提到了Qwen2.5-coder-32b-instruct作为对比实验。
- 数据过滤阈值:默认设置为 0.1(WER)。
- 训练硬件:未说明。
- 推理细节:
- 使用贪心解码(Greedy decoding)以简化和加速推理流程。
- 在LLM校正环节,通过NVIDIA NIM服务调用LLM,具体解码参数(如温度、top_k)未说明。
- 正则化或稳定训练技巧:未明确提及除模型平均和数据过滤外的其他正则化技巧。
📊 实验结果
论文主要在两个任务上进行了评估:中文普通话的自动语音识别(ZH ASR)和西班牙语到英语的语音翻译(ES-to-EN AST)。
表2. ZH ASR 词错误率(WER, %)结果
| 模型 | 使用LESS | AISHELL-1 (测试) | AISHELL-2 (测试) | WenetSpeech (测试) |
|---|---|---|---|---|
| 监督基线 (Sup.) | 否 | 2.9 | 5.3 | 17.7 |
| 第1轮迭代 (NST) | 否 | 3.0 | 5.3 | 15.9 |
| 第1轮迭代 (NST) | 是 | 3.0 | 5.3 | 15.0 |
| 第2轮迭代 | 是 | 3.0 | 5.3 | 14.2 |
| 第3轮迭代 | 是 | 3.0 | 5.2 | 13.9 |
结论:LESS方法在噪声更大、更接近真实场景的WenetSpeech测试集上取得了显著且持续的WER下降(从17.7%到13.9%,降幅3.8%)。在相对干净的AISHELL-1/2测试集上,WER保持稳定。
表3. ZH ASR 消融实验结果(均在WenetSpeech测试集上, %)
| 模型 | 使用的LLM | 过滤阈值 | WER提示词 | WenetSpeech WER |
|---|---|---|---|---|
| A | 无 | - | - | 15.9 |
| B | Qwen2.5-coder | 1.0 | 否 | 16.9 |
| C | Yi-Large | 1.0 | 否 | 16.2 |
| D | Yi-Large | 1.0 | 是 | 15.8 |
| E | Yi-Large | 0.1 | 是 | 15.0 |
结论:1. 通用LLM(Yi-Large)比代码专精LLM(Qwen)更适合此任务。2. 加入WER提示词(WER Prompting)能带来性能提升。3. 更严格的过滤阈值(0.1 vs 1.0)能显著提升最终性能。
表4. ES-to-EN AST 布鲁分数(BLEU, SacreBLEU)结果
| 模型 | 使用LESS | Callhome (测试) | Fisher (测试) | Common Voice (测试) |
|---|---|---|---|---|
| ESPnet 基线 | 否 | 21.7 | 50.5 | - |
| 监督基线 (Sup.) | 否 | 33.5 | 64.2 | 36.7 |
| 第1轮迭代 (NST) | 否 | 33.2 | 64.0 | 36.9 |
| 第1轮迭代 (NST) | 是 | 34.0 | 64.7 | 37.3 |
结论:直接将真实世界数据用于标准NST会轻微降低性能(BLEU下降)。而LESS方法在仅一轮迭代后,就在所有测试集(包括域内的Callhome/Fisher和域外的Common Voice)上超过了监督基线和标准NST,达到了最佳性能。
图1(即架构图)也同时作为流程示意图,展示了LESS框架的执行步骤。
⚖️ 评分理由
- 学术质量(5.0/7):创新性(3.0/3):将LLM作为校正模块集成到语音SSL中,特别是针对真实世界数据的场景,是一个新颖且有效的思路。技术正确性(1.0/1):框架设计合理,实验流程清晰,消融实验支持了关键设计选择。实验充分性(0.5/2):在ASR和AST两个任务上验证了方法,提供了关键组件的消融分析。但主要局限于单一语音基础模型(Whisper),未与更广泛的SFMs对比;AST实验迭代次数少;对“真实世界”数据的复杂性分析不足。证据可信度(0.5/1):实验数字明确,有对比基线,但部分训练细节(如batch size, 优化器)缺失,影响完全复现。
- 选题价值(1.5/2):前沿性(0.5/1):解决语音大模型利用网络数据训练时的共性难题,与当前大模型数据工程趋势高度相关。潜在影响与应用空间(1.0/1):有望降低对高质量标注数据的依赖,提升模型在真实嘈杂环境下的实用性,应用前景广阔。
- 开源与复现加成(+1.0/1):论文提供了开源配方(recipe)的GitHub链接,明确使用了公开的模型(Whisper, Yi-Large, LLaMA-3)和工具(K2 Icefall),并详细描述了实验设置(如学习率, epoch数),为复现提供了极大便利。