📄 LenslessMic: Audio Encryption and Authentication via Lensless Computational Imaging
#音频安全 #无透镜成像 #神经音频编码 #音频分类
✅ 7.5/10 | 前25% | #音频安全 | #无透镜成像 | #神经音频编码 #音频分类
学术质量 6.5/7 | 选题价值 1.0/2 | 复现加成 0.5 | 置信度 中
👥 作者与机构
- 第一作者:Petr Grinberg (Audiovisual Communications Laboratory, EPFL)
- 通讯作者:未说明(作者列表未标注,邮箱为共通格式 first.last@epfl.ch)
- 作者列表:Petr Grinberg (EPFL), Eric Bezzam (EPFL), Paolo Prandoni (EPFL), Martin Vetterli (EPFL)。所有作者均隶属于 EPFL 的 Audiovisual Communications Laboratory。
💡 毒舌点评
亮点:本文巧妙地将“无透镜相机的视觉隐私”这一特性,逆向思维用于“音频的隐私保护”,构建了一个从声到光再到密文的全新物理安全链路,构思颇具巧思。短板:系统实用性受制于笨重的硬件原型(需要显示器作为光源)和缓慢的采集速度,其宣称的“物理层安全”优势,在“已知明文攻击”下可能因音频帧尺寸过小而受到挑战,迫使采用更复杂(且效果更差)的帧分组策略来弥补。
🔗 开源详情
- 代码:论文提供了项目主页链接 (https://blinorot.github.io/projects/LenslessMic),并声明开源了代码。但论文文本中未直接给出代码仓库(如GitHub)的具体URL。
- 模型权重:论文中未明确提及是否公开预训练好的Learned等模型的具体权重文件。
- 数据集:论文明确开源了收集的多个数据集(见表1),包括Librispeech子集和SongDescriber音乐数据,以及对应的无透镜测量值。可通过项目主页获取。
- Demo:论文提供了一个在线演示页面 (https://blinorot.github.io/projects/LenslessMic),可以试听重构的音频样本。
- 复现材料:论文提供了详细的训练数据收集方法、模型架构、损失函数、训练步数(50k)、学习率(1e-4)、batch大小(4个连续帧)等复现所需的关键信息。未提及检查点文件和详细的环境配置。
- 论文中引用的开源项目:
- 神经音频编码器:DAC (Descript Audio Codec) [14]。
- 音频评估:NVIDIA NeMo 工具包 [27] 中的Parakeet-TDT-0.6B-v2(用于转录)和TitaNet-L(用于说话人嵌入)。
- 无透镜成像原型:DigiCam [15]。
- 重建算法基线:ADMM [24]。
📌 核心摘要
- 要解决什么问题:数字音频的安全传输目前主要依赖软件加密算法(如AES),论文旨在探索一种新的、基于物理硬件的补充性安全方案,为音频数据提供额外的保护层,以应对潜在的深度伪造、窃听等威胁。
- 方法核心是什么:提出LenslessMic,一个混合硬件-软件系统。其核心流程是:将音频信号通过神经音频编码器(NAC,具体使用DAC)压缩为潜在表示,将该表示重塑为图像帧;利用无透镜相机(一个基于可编程掩模的低成本原型DigiCam)对这些图像帧进行拍摄,得到多重散射的测量值(密文)。解密时,必须使用正确的点扩散函数(PSF,由掩模图案决定)对测量值进行逆向重建,恢复出潜在表示图像,再输入音频解码器恢复音频。
- 与已有方法相比新在哪里:(1) 跨模态安全范式:首次将无透镜成像的视觉隐私特性应用于音频加密,开辟了光学物理层安全在音频领域的新应用。(2) 融合架构创新:结合了NAC的鲁棒性(尤其是残差向量量化RVQ的容错能力)与无透镜成像的安全性,提出了完整的端到端加密-解密流程。(3) 主动安全机制:通过可编程掩模动态改变PSF,并结合帧分组(g)技术,主动增强系统对各类攻击的抵抗力。
- 主要实验结果如何:论文在多个数据集上进行了验证。关键结果如表2所示:使用在域数据(train-clean)训练的Learned模型,解密语音的ViSQOL为4.50,STOI达0.96,接近无加密的Ground-truth。安全性方面,图2显示当正确PSF像素比例W=7%时,WER已达100%,搜索空间等效于AES-256。认证实验(图3)显示,正确PSF与随机PSF的恢复结果在WER和UTMOS指标上可完美区分,认证准确率达100%。帧分组消融表明,g=2足以防御已知明文攻击(NoPSF模型WER=100%),但会轻微降低重建质量。
- 实际意义是什么:该研究为音频数据安全提供了一种新的防御维度——物理层安全。它证明了光学加密可以与先进的音频编码技术结合,在保证解密质量的同时,提供强大的加密强度和用户认证能力。其开源贡献有助于推动该交叉领域的研究。
- 主要局限性是什么:(1) 硬件实用性:当前原型依赖电脑显示器作为光源,体积大,不适合实际部署;采集速度慢,存储开销大于原始音频。(2) 质量与安全的权衡:增强安全性(如增大g)会导致解密质量下降。(3) 泛化能力:模型在跨音频类型(语音到音乐)和跨编码器(DAC到X-Codec)时性能有下降,表明系统对特定编码格式有依赖性。(4) 潜在攻击面:论文承认小尺寸音频帧可能使已知明文攻击在理论上可行,尽管通过增大g进行了缓解。
🏗️ 模型架构
LenslessMic是一个端到端的音频加密与认证系统,其架构包含编码、加密(物理拍摄)、解密(重建)和解码四个主要阶段。
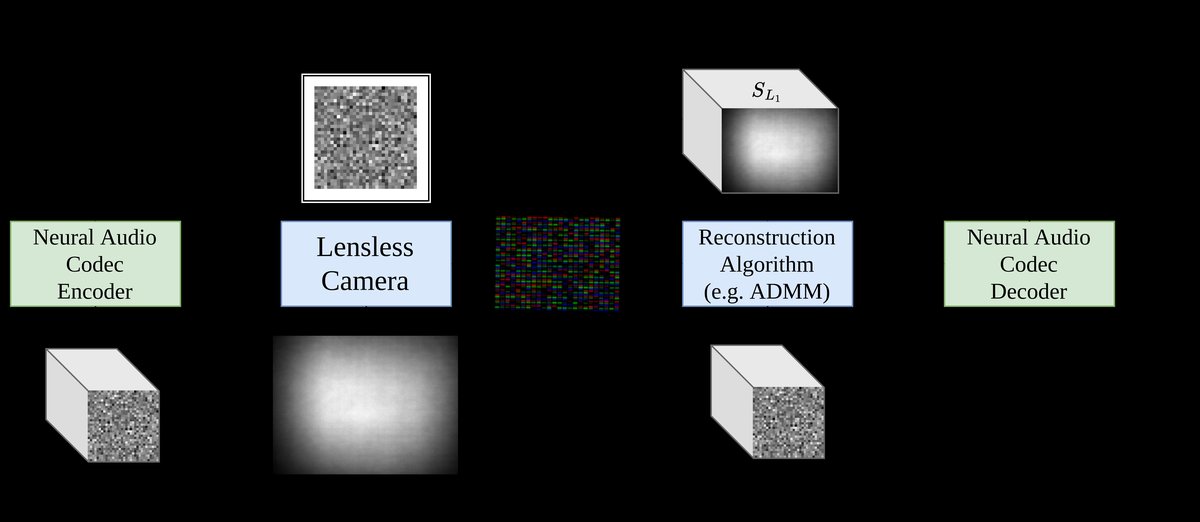 图1:LenslessMic系统流程图。展示了音频信号如何经过神经音频编码、视觉表示转换、无透镜相机捕获、计算重建,最终解密恢复音频的过程。
图1:LenslessMic系统流程图。展示了音频信号如何经过神经音频编码、视觉表示转换、无透镜相机捕获、计算重建,最终解密恢复音频的过程。
- 音频编码与视觉表示生成:
- 输入:原始音频波形
a ∈ R^T。 - 神经音频编码器 (NAC):使用状态-of-the-art的DAC编码器,将音频
a编码为一个连续的潜在表示E ∈ R^{T_E × S},其中T_E是编码帧数,S是潜在维度。 - 残差向量量化 (RVQ):
E通过具有C=12个码本(每个大小1024)的RVQ进行离散化,得到离散码字。解码时,从码本中取出对应的嵌入向量并求和,得到D,再通过卷积解码器恢复音频。 - 视觉表示重塑:关键创新在于,论文选择将编码器输出
E(而非量化后的D)重塑为一个视频序列V ∈ R^{T_E × √S × √S}。对于DAC,S=1024,因此每帧大小为32×32。这些帧被归一化(min-max)后,将作为“明文”图像。
- 物理加密(无透镜成像捕获):
- 显示与捕获:每个视频帧
F_t被放大到显示屏上,尺寸为√(r²S) × √(r²S)(r=8),形成由“超级像素”组成的网格图案。 - 无透镜相机:一个基于可编程掩模(如DigiCam)的无透镜系统捕获显示屏上的图像。其成像模型为
y = Hx + n,其中H是由掩模图案决定的系统矩阵(PSF),x是显示的图像(即F_t的放大版),y是传感器捕获的多重散射测量值(密文)。由于缺少透镜,y是视觉上无法理解的噪声状图像。
- 解密(计算重建):
- 输入:捕获的测量值
y。 - 逆问题求解:需要已知正确的PSF矩阵
H来求解x。论文测试了基线ADMM算法和提出的 Learned 模型。Learned模型是一个参数化的展开式优化网络(共8.1M参数),它学习了5个迭代步骤的ADMM参数,并集成了DRUNet组件用于PSF校正和前后处理。 - 目标函数:训练时使用三种损失之和:
L_raw(确保重建图像呈超级像素网格结构),L_SSIM(保持噪声状结构的相似性),和L_MSE(控制像素值相似性)。 - 输出:重建的潜在表示图像
ûV,经逆归一化和形状还原得到ûE。
- 音频解码:
- 将重建的潜在表示
ûE输入DAC的解码器(使用其RVQ码本),恢复最终的音频波形。
安全设计关键点:
- PSF作为密钥:PSF
H的知识是解密必需的。错误的PSF(∆非零)会导致解密图像严重畸变,从而恢复出无意义的音频(如公式2所示)。 - 可编程掩模:掩模图案可更改,从而改变PSF,增加了系统的可重配置性和密钥空间。
- 帧分组 (Grouping):为抵抗选择明文攻击(CPA),可将
g个连续帧合并成一个大帧进行加密。这增大了单次捕获的图像尺寸,使得攻击者难以学习直接映射,但同时也使合法重建更困难。
💡 核心创新点
- 物理-数字混合音频安全新范式:核心创新在于开创性地将无透镜计算成像这一物理层技术应用于音频加密与认证。传统音频安全依赖信号处理或软件算法,而LenslessMic在信号被数字化之前(在光域)就引入了加密层,提供了全新的安全维度。
- 利用NAC的鲁棒性与量化特性:创新性地将神经音频编码器(NAC)的潜在表示作为无透镜成像的“图像”输入。这带来了双重好处:(a) NAC(特别是其RVQ)对重建误差具有鲁棒性——即使重建的潜在表示
ûE不完美,其量化后的离散码字仍可能与原始码字一致(表2中QM-1/2列支持了这一点)。(b) NAC压缩了音频的时间维度,使得标准帧率的相机可以捕获,克服了音频高采样率带来的挑战。 - 主动防御与安全-质量权衡分析:系统设计并非静态,提出了帧分组(g) 这一可调参数来主动增强安全性。通过增大
g,可以有效抵御选择明文攻击(CPA)和已知明文攻击(KPA),如实验所示(NoPSF模型性能随g增大急剧恶化)。论文系统地分析了安全强度(g与PSF正确率W)与解密质量之间的权衡关系,为实际部署提供了指导。 - 完整的端到端开源实现:论文不仅提出了方法,还构建了完整的原型系统(基于Raspberry Pi的DigiCam),并提供了大规模收集的数据集(包含数十万帧)、训练好的模型、代码和演示,极大地促进了该交叉领域的可复现研究。
🔬 细节详述
- 训练数据:
- 数据集:主要使用 Librispeech (train-clean, train-other, test-clean, test-other 子集) 和 SongDescriber (test-music) 数据集。具体规模见表1。
- 预处理:截取了特定长度的片段(如test-clean小于3秒)。
- 数据增强/构造:为训练重建模型,收集了大量成对数据:(1) 使用100个不同的随机掩模图案,在训练集音频上运行LenslessMic流程,捕获对应的无透镜测量值
y作为输入,将显示屏上的原始图像V作为目标。(2) 另外收集了100个随机掩模用于测试。还收集了从N(0,1)采样的图像的测量值,用于训练R-Learned模型以提升泛化性。
- 损失函数:
- 最终损失为三项之和:
L = L_raw + L_SSIM + L_MSE。 L_raw:基于SSIM,确保重建图像在放大尺寸上呈现预期的r²-超级像素网格结构。L_SSIM:基于较小核的SSIM,控制重建图像ûV与目标V在噪声状结构上的相似性。L_MSE:均方误差,控制像素值层面的相似性。- 注意:论文尝试添加音频损失但未带来提升。
- 最终损失为三项之和:
- 训练策略:
- 优化器:未明确提及具体优化器(如Adam),但给出了学习率。
- 学习率:恒定学习率
10⁻⁴。 - Batch Size:随机选择4个连续帧作为一个batch。
- 训练步数:Learned模型训练了50k步。
- 调度策略:未说明(使用恒定学习率)。
- 关键超参数:
- 编码器:DAC,潜在维度
S=1024,RVQ码本数C=12,码本大小1024。 - 无透镜成像:传感器降采样率
c=8,得到测量值分辨率507×380。显示超像素放大系数r=8,因此显示帧大小为256×256。 - 帧分组:
g=1,2,3,4。 - 可编程掩模:像素数
N=1296,位深b=8。 - Learned模型参数量:8.1M。
- 编码器:DAC,潜在维度
- 训练硬件:论文中未明确说明使用的GPU型号和数量。
- 推理细节:
- 重建算法:对比了ADMM(100次迭代)和Learned模型。
- Learned模型在推理时直接进行前向传播。
- 解码音频使用DAC的解码器。
- 正则化/稳定训练技巧:
- Learned模型通过展开优化算法(ADMM)的迭代并学习其参数,是一种隐式的正则化。
- 使用DRUNet组件进行PSF校正和预/后处理,有助于处理模型失配和噪声。
📊 实验结果
论文主要从图像重建质量、音频恢复质量、安全性和认证能力四个方面进行评估。
主要定量结果对比表(源自表2):
| 方法 | 测试集 | g/r | PSNR↑ | SSIM↑ | MSE↓ | ViSQOL↑ | SI-SDR↑ | Mel↓ | STOI↑ | WER↓ | SMA↑ | QM-1/2↑ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ground-truth | test-clean | - | - | - | - | 4.66 | - | 0.96 | 0.97 | 3.03 | 100 | - |
| ADMM | test-clean | 1/8 | 10.82 | 0.04 | 25.01 | 1.01 | -44.60 | 7.95 | 0.38 | 100 | 0.00 | 0.01/0.00 |
| NoPSF | test-clean | 1/8 | 17.12 | 0.47 | 5.79 | 2.36 | -11.61 | 2.71 | 0.67 | 54.25 | 0.28 | 4.15/0.12 |
| R-Learned | test-clean | 1/8 | 19.49 | 0.70 | 3.41 | 4.13 | 7.52 | 2.06 | 0.95 | 3.36 | 100 | 28.81/5.48 |
| Learned | test-clean | 1/8 | 22.20 | 0.85 | 1.83 | 4.50 | 9.06 | 1.14 | 0.96 | 3.31 | 100 | 39.19/15.35 |
| Learned (fixed) | test-clean | 1/8 | 22.20 | 0.85 | 2.12 | 4.40 | 8.53 | 1.39 | 0.96 | 3.22 | 100 | 37.22/12.60 |
| Learned | test-music | 1/8 | 19.26 | 0.70 | 3.80 | 4.29 | 8.05 | 1.94 | - | - | - | 24.66/6.37 |
| R-Learned | test-music | 1/8 | 19.70 | 0.72 | 3.33 | 4.33 | 9.43 | 1.79 | - | - | - | 32.92/8.41 |
| Learned | test-xcodec | 1/8 | 15.38 | 0.19 | 21.61 | 1.81 | -17.42 | 6.08 | 0.58 | 68.09 | 9.18 | 2.68/0.04 |
| R-Learned | test-xcodec | 1/8 | 16.35 | 0.37 | 18.42 | 2.83 | -7.95 | 4.46 | 0.73 | 29.79 | 61.61 | 20.63/3.73 |
| 帧分组消融 (test-clean): | ||||||||||||
| NoPSF | test-clean | 2/4 | 16.39 | 0.39 | 6.92 | 1.70 | -29.10 | 3.14 | 0.54 | 100 | 0 | 1.93/0.02 |
| Learned | test-clean | 2/4 | 21.38 | 0.81 | 2.19 | 4.27 | 5.97 | 1.29 | 0.93 | 3.38 | 100 | 22.47/4.35 |
| NoPSF | test-clean | 3/3 | 15.57 | 0.29 | 8.64 | 1.20 | -40.63 | 4.40 | 0.32 | 100 | 0 | 1.05/0.01 |
| Learned | test-clean | 3/3 | 19.47 | 0.69 | 3.44 | 3.65 | -1.27 | 1.84 | 0.82 | 5.63 | 90.08 | 12.42/1.03 |
| NoPSF | test-clean | 4/2 | 15.04 | 0.22 | 9.83 | 1.15 | -43.45 | 5.42 | 0.20 | 100 | 0 | 0.51/0.00 |
| Learned | test-clean | 4/2 | 17.43 | 0.52 | 5.50 | 2.63 | -9.83 | 2.48 | 0.66 | 64.60 | 1.70 | 4.70/0.12 |
关键结论与图表分析:
- 重建质量:Learned模型显著优于基线ADMM,在测试集上解密的音频ViSQOL (4.50) 和STOI (0.96) 非常接近无加密的Ground-truth (ViSQOL 4.66, STOI 0.97),表明高质量恢复是可能的。在域内数据(train-clean训练,在test-clean测试)效果最佳。
- 泛化能力:
- 跨内容类型:在语音上训练的模型可以恢复音乐数据,但质量略有下降(Learned: ViSQOL 4.29 for music)。
- 跨编码器:在DAC上训练的Learned模型在X-Codec数据上表现较差(WER 68.09%)。而在随机数据上训练的R-Learned模型泛化性更好(WER 29.79%),表明训练数据的多样性有助于泛化。
- 安全性分析:
- 暴力破解 (BFA) / 密文攻击 (COA):图2显示了重建质量(WER)与正确PSF像素百分比W的关系。当W=7%时,WER已达到100%,SMA为0,等效于AES-256的搜索空间。即使攻击者尝试猜测RVQ码本(2^120种可能),对于TE≥3帧,其搜索空间也达到AES-256水平。
- 选择明文攻击 (CPA) / 已知明文攻击 (KPA):通过训练不包含PSF逆问题的NoPSF模型来模拟此类攻击。表2显示,当g=1时,NoPSF模型仍能部分解密(WER 54.25%)。但当g≥2时(如g=2, r=4),NoPSF模型的WER达到100%,证明帧分组能有效防御此类攻击。
- 认证能力:图3展示了使用Learned (g=1) 模型,正确PSF与10个随机PSF恢复结果的WER和UTMOS分布。两者在指标上完全分离(正确PSF: WER<3.31, UTMOS>4.5;随机PSF: WER=100, UTMOS≈1.2),可以设置阈值实现100%的认证准确率。
⚖️ 评分理由
学术质量:6.5/7
- 创新性 (高):将无透镜成像与音频安全结合,提出了一个全新的跨模态物理安全架构,具有显著的新颖性。
- 技术正确性 (高):系统设计逻辑严密,从信号处理、计算成像到机器学习,技术路径合理,实验验证了其可行性。
- 实验充分性 (高):实验设计全面,包含了与基线的对比、多维度指标评估、安全性量化分析、消融研究(g, 编码器, 训练数据域),并提供了大量定量结果和可视化证据(图2, 图3)。
- 证据可信度 (中高):大部分结论有坚实的实验数据支撑。但部分高级安全性声称(如对RVQ码本暴力破解的复杂度)更多是理论分析。系统在最优配置下(g=1)对CPA/KPA的抵抗力有明确弱点,尽管论文通过引入g进行了缓解,但这本身是系统设计的一个权衡。
选题价值:1.0/2
- 前沿性 (高):开辟了“光学物理层音频安全”这一新的研究方向。
- 潜在影响 (中):为音频安全提供了新思路,可能在高保密通信等特定场景有价值。但其影响受限于硬件依赖性和部署成本。
- 应用空间 (中):潜在应用于需要极高安全性且接受专用硬件的领域,如军事、外交或关键基础设施的音频通信保护。
- 与读者相关性 (中):对于关注音频处理、计算成像和交叉安全研究的读者,相关性较高。
开源与复现加成:0.5/1
- 论文明确承诺并提供了代码、数据集和演示的访问链接(项目主页)。
- 详细描述了模型架构、训练流程、损失函数和关键超参数,为复现提供了良好基础。
- 扣分点:未提供具体的代码仓库URL(仅有项目主页),且未提及训练硬件的具体配置(如GPU型号),这可能会增加完全复现的难度。