📄 Learning Vocal-Tract Area And Radiation With A Physics-Informed Webster Model
#歌唱语音合成 #物理信息神经网络 #信号处理 #语音合成
✅ 7.0/10 | 前50% | #歌唱语音合成 | #信号处理 | #物理信息神经网络 #语音合成
学术质量 6.0/7 | 选题价值 1.0/2 | 复现加成 0.0 | 置信度 中
👥 作者与机构
- 第一作者:Minhui Lu(Queen Mary University of London, Centre for Digital Music)
- 通讯作者:未说明(论文中未明确标注通讯作者,但根据常见惯例,第一作者或最后作者可能是。此处严格按论文内容判断,未明确提及。)
- 作者列表:Minhui Lu(Queen Mary University of London, Centre for Digital Music)、Joshua D. Reiss(Queen Mary University of London, Centre for Digital Music)
💡 毒舌点评
亮点:论文将经典的Webster声学方程与物理信息神经网络(PINN)结合,不仅学习了声道面积函数,还创新性地引入了可学习的端口辐射边界条件,为语音合成提供了高度可解释的物理控制参数。短板:然而,整个实验建立在合成的、高度理想化的稳态元音数据上,缺乏对真实歌唱语音的验证;其宣称的“物理可解释性”参数(如辐射系数ζ)在实际复杂声源和噪声环境下的鲁棒性与可区分性存疑。
🔗 开源详情
- 代码:论文中提及“代码和音频示例可在项目页面获取”,并给出了URL:https://minhuilu.github.io/webster-pinn-svs/。但未明确说明是否包含完整训练和评估代码。
- 模型权重:未提及是否公开。
- 数据集:论文使用的训练数据为作者自己合成的,未说明是否公开合成脚本或数据本身。
- Demo:提供了项目页面链接,可能包含音频示例demo。
- 复现材料:论文中提及“权重调度和归一化细节在发布代码中指定”,表明部分训练细节需要在代码中查找。未提供详细的超参数列表、训练日志等。
- 论文中引用的开源项目:未明确列出依赖的第三方开源项目,但技术栈隐含了使用SIREN、DDSP等已有概念或库。
📌 核心摘要
- 要解决什么问题:现有歌唱语音合成(SVS)的后端渲染器(如神经声码器)参数纠缠、可解释性差,且难以对音色、发音进行精细控制。论文旨在构建一个基于物理模型的渲染器,从音频中反演出可解释的声学控制参数。
- 方法核心是什么:提出一个基于Webster时域方程的物理信息神经网络(PINN)。该网络(DualNet)同时预测声速势场ψ(x,t)、静态声道面积函数Â(x)和一个可学习的开口端Robin辐射系数ζ。训练时结合PDE/BC残差损失与音频损失,并辅助以一个仅用于训练的轻量级DDSP路径来稳定学习;推理时完全基于物理方程进行渲染。
- 与已有方法相比新在哪里:1) 联合估计:首次在PINN框架下,同时从音频中反演声道几何形状(A(x))和显式可学习的边界条件(ζ)。2) 训练-推理分离:训练时可使用神经网络辅助,但推理时是纯粹的、与离散化无关的物理求解器,增强了模型的可解释性和可控性。3) 离图评估:提出使用独立的FDTD求解器对恢复的参数进行后渲染,以验证其作为可迁移物理控制量的有效性,减少了“逆犯罪”风险。
- 主要实验结果如何:在合成的/a/, /i/, /u/元音上测试。核心结果:将估计的(Â, ζ)导出到独立FDTD求解器后,其渲染波形的频谱包络(LSD)相比DDSP基线在/a/和/u/上降低了6-9 dB,效果接近参考信号。然而,在图PINN渲染的波形周期性(HNR)比参考和后渲染结果低2-4 dB,存在明显的“周期性差距”(breathiness)。恢复的Â(x)捕捉了元音相关的宏观趋势,但细部模糊。
关键结果表(来自Table 2 & Table 3):
元音 PINN (post-render) mSTFT ↓ DDSP-only mSTFT ↓ PINN (in-graph) mSTFT ↓ /a/ 1.292 2.749 6.046 /i/ 3.295 2.097 6.363 /u/ 1.846 2.988 6.413 元音 Ref. HNR PINN (post-render) HNR DDSP-only HNR PINN (in-graph) HNR /a/ 8.439 8.449 8.434 2.827 /i/ 9.225 7.806 6.833 4.243 /u/ 7.901 7.803 7.664 2.284 - 实际意义是什么:该研究为语音合成探索了一条“白盒”路径,有望实现对合成声音音色(声道形状)和发音位置(辐射特性)的精细、可解释的控制,对于需要高可控性的专业语音合成(如角色扮演、语音治疗)有潜在价值。
- 主要局限性是什么:1) 数据局限:仅在合成的、干净的、稳态元音上验证,未涉及真实录音、辅音、动态语流。2) 可辨识性问题:从单通道音频反推声道形状本身是病态问题,恢复的A(x)和ζ可能不唯一,论文也承认其为“频谱等效控制”而非真实解剖结构。3) 周期性缺陷:在图渲染存在系统性问题,表明当前的物理损失与音频损失组合不足以约束出精确的准周期激励。4) 评估不足:未与完整的SVS系统对比,实际应用性能未知。
🏗️ 模型架构
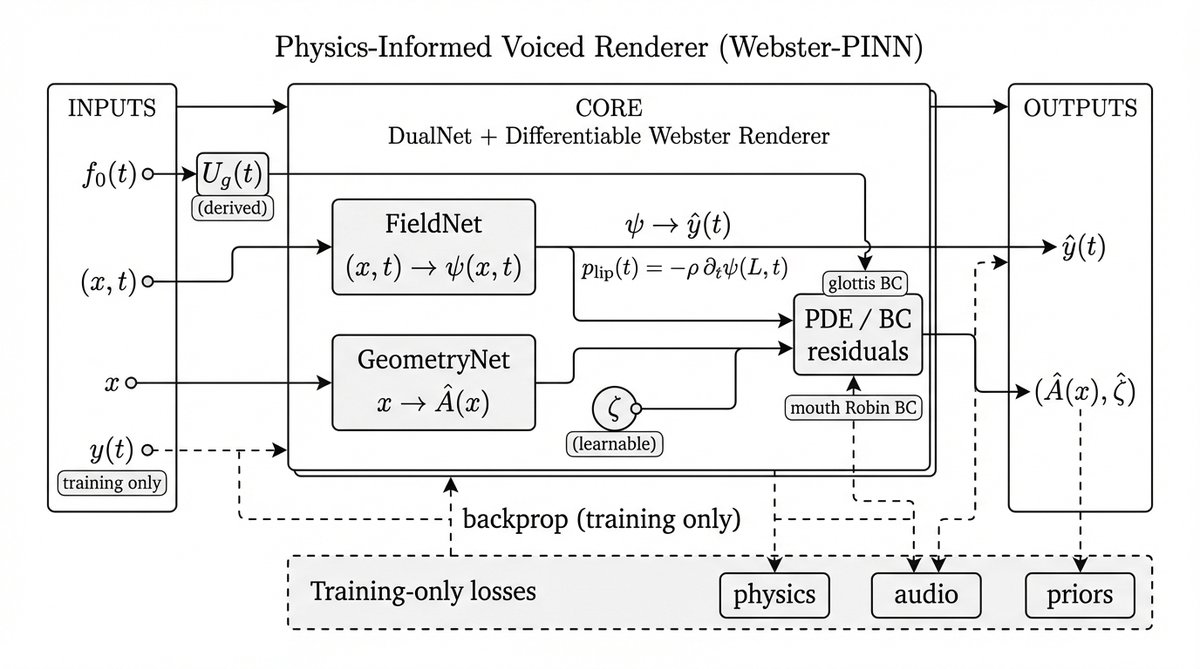
论文的整体架构如图1所示,是一个双阶段、训练与推理分离的系统。
整体输入输出流程:
- 训练阶段输入:时空坐标(x, t),基频轨迹f0(t),参考波形y(t)。
- 训练阶段输出:训练后的模型参数。
- 推理阶段输入:基频轨迹f0(t)。
- 推理阶段输出:渲染波形ŷ(t),恢复的声学控制参数(Â(x), ζ)。
主要组件:
- DualNet:核心神经网络,包含两个子网络。
- SIREN场网络:一个基于周期激活函数(SIREN)的紧凑型神经网络,输入为(x, t),输出为声速势ψ(x, t)。它负责学习满足波动方程的时空场。
- 几何MLP:一个多层感知机,输入为空间坐标x,通过softplus输出层确保输出为正的声道面积函数Â(x)。
- 全局参数ζ:一个可学习的标量,参数化嘴部的Robin辐射边界条件。SIREN场网络对ψ的自动微分用于计算PDE/BC残差。
- 可微Webster渲染路径(仅训练时使用):
- 根据预测的ψ, Â, ζ,通过物理公式计算唇部压力plip(t)和最终波形ŷ(t)。
- 该路径与DualNet相连,允许音频损失和探测器损失的梯度回传至DualNet参数,用于训练。
- 辅助DDSP渲染器(仅训练时使用):
- 一个轻量级的DDSP风格加法合成器,由谐波频谱包络Henv(从DualNet的另一个输出或直接从ψ导出)驱动,产生一个教师波形。
- 其作用是在训练中期稳定优化,提供包络正则化信号,但在推理时被完全移除。
- 独立FDTD-Webster求解器(用于评估):
- 这是一个与训练图完全分离的、显式有限差分时间域(FDTD)求解器。
- 将训练好的(Â, ζ)和f0(t)导出到此求解器,生成最终用于评估的波形。此步骤确保了参数验证的“离图”性质,避免了训练与评估使用同一离散化带来的“逆犯罪”问题。
关键设计选择:
- 静态A(x):为简化问题,假设声带形状在发音期间不变,这符合元音稳态的假设。
- Robin辐射边界:用一个标量ζ参数化复杂的口端辐射阻抗,在低频近似下合理,且使问题可解。
- 训练/推理分离:这是本文的核心创新之一,旨在平衡学习稳定性(训练时可用神经辅助)与结果的可解释性和可迁移性(推理时是纯物理求解)。
💡 核心创新点
- Webster PINN与可学习辐射边界:将经典的Webster声道声学方程嵌入PINN框架,并首次引入一个可学习的Robin边界系数ζ。这使得模型能从音频中联合估计声道几何形状和辐射特性,超越了以往固定边界或单参数估计的方法。
- “训练用神经,推理用物理”的分离架构:在训练阶段,允许使用一个辅助的、基于神经网络的DDSP渲染器来稳定梯度优化,但在实际使用(推理)时,完全移除所有神经网络组件,仅依赖由PINN恢复的物理参数(Â, ζ)驱动一个纯物理的Webster方程求解器来生成音频。这显著提升了输出结果的可解释性和作为物理控制量的可信度。
- 面向参数迁移的离图(Out-of-graph)评估范式:不满足于在训练图内评估,而是将恢复的物理参数导出到一个完全独立的、不同代码实现的FDTD求解器中进行后渲染和评估。这有力地验证了学习到的参数是可迁移的物理控制量,而非训练图特定的数值拟合产物。
🔬 细节详述
- 训练数据:
- 数据集名称、来源:未提供外部数据集名称。参考波形y(t)由论文作者自己使用独立的FDTD-Webster求解器合成。
- 数据生成:使用Rosenberg声门流作为边界驱动,Robin边界条件(ζref=0.06)作为口端条件,在Webster方程上进行FDTD仿真生成。
- 规模:每个元音(/a/, /i/, /u/)一个模型。每个样本约0.8秒,采样率16kHz。
- 预处理/增强:未提及额外预处理或数据增强。使用合成数据,无需典型的数据增强。
- 损失函数:
- 总损失公式 (Eq.9):
L = λphys LPDE/BC + λaud Laudio + λprobe Lprobe + λprior Lprior - 各分项说明:
LPDE/BC:物理残差损失,包括Webster PDE残差 (LPDE)、嘴部Robin边界条件残差 (LBC,mouth) 和声门流量边界条件残差 (LBC,glot)。这是PINN的核心,强制预测的ψ(x,t)满足物理定律。Laudio:音频损失,包括多分辨率STFT损失和对数梅尔包络损失(RMS归一化),可能辅以弱全句STFT和时域项。用于将预测波形ŷ(t)与参考波形y(t)对齐。Lprobe:探测器损失,基于从ψ导出的可微分声学特征(共振峰F1..F3和谐波频谱包络Henv)。作为辅助引导和诊断。Lprior:先验/正则化损失,包括几何正则化 (Lgeom,LA''),用于约束Â(x)的平滑性和范围。
- 总损失公式 (Eq.9):
- 训练策略:
- 优化器:未说明。
- 学习率/调度:未说明具体数值,但提到使用“简单的分阶段权重调度(预热和渐变)”来稳定训练。
- Batch size/训练步数:未说明。
- 权重调度:λphys, λaud, λprobe, λprior 的具体权重和调度策略在发布代码中指定。
- 关键超参数:
- 模型大小:SIREN场网络和几何MLP的具体结构(层数、维度)未在论文中明确给出,需查阅代码。
- 声学参数:空气密度ρ,声速c,声道长度L。具体数值未说明,但应为标准值。
- 边界参数:参考解的辐射系数ζref=0.06。学习到的ζ收敛到约0.127±0.001。
- 训练硬件:未说明。
- 推理细节:
- 渲染方式:从DualNet获取(ψ, Â, ζ),直接代入Webster方程的解析形式或通过简单的有限差分进行时间步进,生成波形ŷ(t)。
- 无随机性:推理是确定性的物理求解,无温度、beam size等参数。
- 正则化技巧:
- 几何先验
Lgeom和LA''用于保证声道面积函数的物理合理性。 - 辅助DDSP路径作为训练正则化手段。
- 在PDE/BC损失中使用配点法(collocation points)。
- 几何先验
📊 实验结果
主要基准与设置:
- 任务:从合成的单通道稳态元音中估计声道参数并验证其物理有效性。
- 基线:一个紧凑的、仅基于DDSP的谐波加法合成器(由f0和响度驱动),作为非物理基线。
- 评估流程:核心评估采用“离图后渲染”(Post-render),即把训练PINN恢复的参数(Â, ζ)输入独立的FDTD求解器生成波形,再与参考波形比较。
主要结果:
频谱包络拟合(Table 2):
- 关键发现:在离图后渲染设置下,PINN方法在/a/和/u/上实现了比DDSP基线更好的包络拟合(更低的mSTFT和LSD)。例如,在/a/上,PINN后渲染的LSD为6.704 dB,而DDSP基线为15.881 dB。但在/i/上,PINN后渲染(15.634 dB)略逊于DDSP基线(13.219 dB)。
- 对比:PINN后渲染显著优于训练时在图内的渲染结果(In-graph),证明了离图评估的有效性和参数的可迁移性。
关键结果表(来自Table 2):
元音 PINN (post-render) mSTFT ↓ DDSP-only mSTFT ↓ PINN (in-graph) mSTFT ↓ PINN (post-render) LSD ↓ DDSP-only LSD ↓ PINN (in-graph) LSD ↓ /a/ 1.292 2.749 6.046 6.704 15.881 24.711 /i/ 3.295 2.097 6.363 15.634 13.219 27.437 /u/ 1.846 2.988 6.413 9.186 15.452 27.382 周期性(HNR)(Table 3):
- 关键发现(周期性差距):PINN在图内渲染(In-graph)的波形周期性(HNR)显著低于参考和后渲染结果(约差2-4 dB),这揭示了当前训练目标在约束精细时间结构上的不足。离图后渲染的HNR与参考非常接近,再次证明了恢复的参数在正确的求解器中能产生准周期波形。
关键结果表(来自Table 3):
元音 Ref. HNR PINN (post-render) HNR DDSP-only HNR PINN (in-graph) HNR /a/ 8.439 8.449 8.434 2.827 /i/ 9.225 7.806 6.833 4.243 /u/ 7.901 7.803 7.664 2.284 鲁棒性测试(Table 4):
- 固定学习到的(Â, ζ),在独立求解器中引入不同偏差进行后渲染。
- 结果:网格/CFL变化(离散化不匹配)和源特性(β, Oq/Cq)变化引起很小的指标漂移(中位数ΔLSD < 0.6 dB)。±10%的音高偏移引起更大的包络漂移(1.541 dB),但周期性变化仍适中(0.481 dB)。这支持(Â, ζ)作为稳定控制量的论点。
关键结果表(来自Table 4):
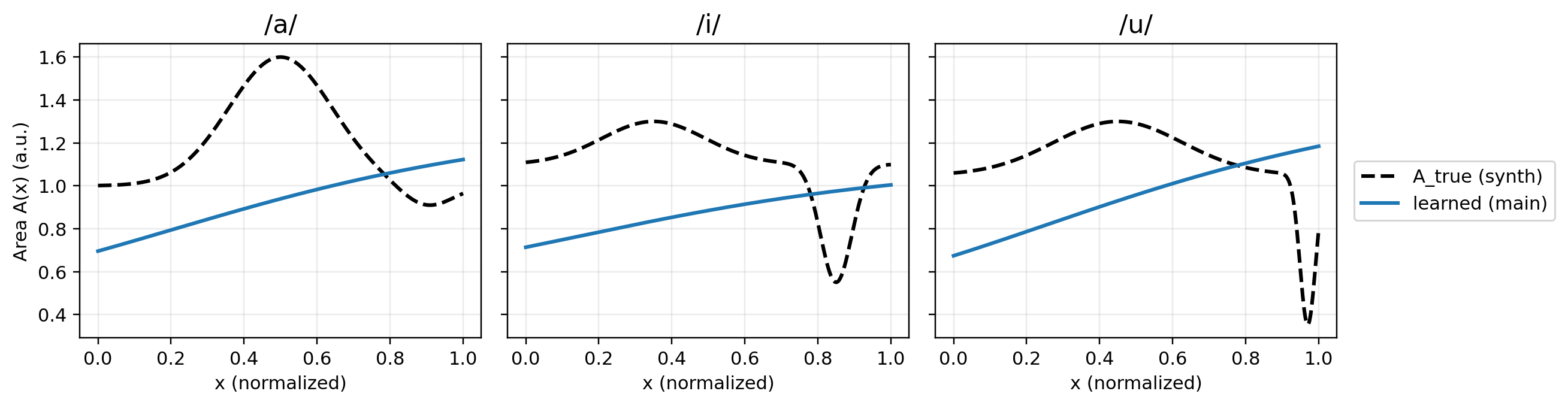
不匹配类型 中位数 ΔLSD (dB) ↓ 中位数 ΔHNR (dB) ↓ 离散化 (网格/CFL) 0.287 0.013 声源 (β, Oq/Cq) 0.554 0.025 音高 ±10% 1.541 0.481 恢复的参数可视化(Fig. 2):
- 恢复的Â(x)曲线平滑且为正,捕捉了元音的宏观特征,如/i/在前端的窄化和/u/在口端的窄化。但细部(如/i/的精确收缩点)在单通道稳态监督下是模糊和非唯一确定的。
- 恢复的辐射系数ζ在不同元音间高度一致(~0.127),表明它可能吸收了模型误差。
⚖️ 评分理由
学术质量:5.5/7
- 创新性:将Webster PINN、可学习边界、训练推理分离架构结合用于语音参数反演,具有明确的新颖性。
- 技术正确性:物理模型应用合理,PINN损失函数设计符合常规,实验流程(离图评估)设计严谨以避免逆犯罪。
- 实验充分性:实验设计了有说服力的离图验证和鲁棒性测试,但严重局限在于仅在最理想的合成稳态元音上进行,缺乏对真实语音、动态音素、噪声环境的测试,结论的普适性存疑。
- 证据可信度:合成数据实验可信度较高,数字结果清晰。但核心声明(可解释控制)的实际意义因缺乏真实场景验证而打折扣。
选题价值:1.0/2
- 前沿性:物理模型与深度学习的融合是当前热点,但具体到“从单音反演声道形状”是一个经典且相对狭窄的声学逆问题。
- 潜在影响与应用空间:对于提高语音合成可控性有理论价值,但距离实用(尤其是在娱乐、通信等主流应用)较远。更可能应用于科研、乐器建模或特定医疗场景。
- 读者相关性:对从事语音物理建模、可控合成、PINN应用的研究者有较高参考价值,但对广大语音/AI开发者直接相关性较低。
开源与复现加成:0.0/1
- 论文承诺在项目页面提供代码和音频示例,这增加了潜在的复现可能性。但当前提供的论文文本中未包含链接,也未详细说明训练所有超参数、硬件、代码框架等信息,因此无法判断其复现友好度。根据规则,信息不足时不加不减分。