📄 Learning to Align with Unbalanced Optimal Transport in Linguistic Knowledge Transfer for ASR
#语音识别 #迁移学习 #知识蒸馏 #端到端
✅ 6.5/10 | 前50% | #语音识别 | #迁移学习 | #知识蒸馏 #端到端
学术质量 3.4/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 中
👥 作者与机构
- 第一作者:Xugang Lu(日本信息通信研究机构, National Institute of Information and Communications Technology, Japan)
- 通讯作者:未明确说明(论文中未明确指定通讯作者)
- 作者列表:Xugang Lu(日本信息通信研究机构)、Peng Shen(日本信息通信研究机构)、Hisashi Kawai(日本信息通信研究机构)
💡 毒舌点评
论文的核心亮点在于将数学理论上的“非平衡最优传输”巧妙地应用于解决ASR知识迁移中声学与语言表征“长对短、多对一、有噪音”的尴尬对齐困境,理论动机清晰。然而,短板也很明显:实验仅在两个中文朗读语料上用CTC系统验证,如同只在一个特定鱼塘测试新渔网;更关键的是,完全不公开代码和模型,让后续研究者“巧妇难为无米之炊”,极大削弱了工作的实际影响力。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及公开模型权重。
- 数据集:AISHELL-1和MagicData均为公开数据集,但论文未说明具体获取或预处理脚本。
- Demo:未提供在线演示。
- 复现材料:给出了主要模型架构尺寸、损失函数权重η、熵正则化系数ε、优化器和学习率等关键信息,但缺乏完整的配置文件、检查点和训练日志。对于UOT求解器的实现细节(如迭代停止条件)描述不足。
- 论文中引用的开源项目:引用了bert-base-chinese(HuggingFace)、Conformer实现(可能基于ESPnet等框架),但未明确说明其代码基于哪个开源项目。
- 总结:论文中未提及开源计划。
📌 核心摘要
- 问题:在基于预训练语言模型(PLM)的跨模态知识迁移中,将语言知识从文本域转移到声学域,核心挑战在于声学序列(帧数多、含噪音)与语言序列(token数少)之间存在固有的、不对齐且不平衡的对应关系。
- 方法核心:提出一种基于非平衡最优传输(UOT)的对齐框架。UOT通过引入边际惩罚项(λ₁, λ₂),放松了传统OT的质量守恒约束,允许声学或语言侧的部分“质量”(信息)不被匹配,从而实现软性、部分的对齐。
- 创新之处:与标准OT(平衡约束)或传统的交叉注意力(仅局部相似性)相比,UOT能显式地建模模态间的分布失配和结构不对称。通过调整λ₁和λ₂,可以灵活控制对齐策略(如优先保证每个语言token都有对应声学帧),从而更鲁棒地处理噪声帧和冗余信息。
- 主要实验结果:在AISHELL-1(普通话)测试集上,最优UOT配置(λ₁=0.5, λ₂=1.0)的CER为4.06%,相比作为基线的标准OT方法(OT-BERT-CTC)的4.19%有约3%的相对改进。在MagicData数据集上,改进更明显,测试集CER从2.17%降至2.02%(约7%相对改进)。
- 实际意义:提供了一种更符合声学-语言对齐先验知识的数学框架,可提升知识迁移的效率和最终ASR性能,且迁移后模型保持CTC解码的高效性。
- 主要局限性:实验范围有限,仅在中文普通话的两个朗读语料库和CTC-based ASR系统上进行验证,未展示在其他语言、自发性语音或主流Transformer-Transducer等系统上的效果;未提供代码,复现困难;对UOT中λ₁, λ₂选择的讨论偏向经验性,缺乏自动选择机制。
🏗️ 模型架构
论文提出一个基于UOT的跨模态知识迁移框架,用于增强CTC-based ASR。其整体架构如下图所示(对应原文图1):
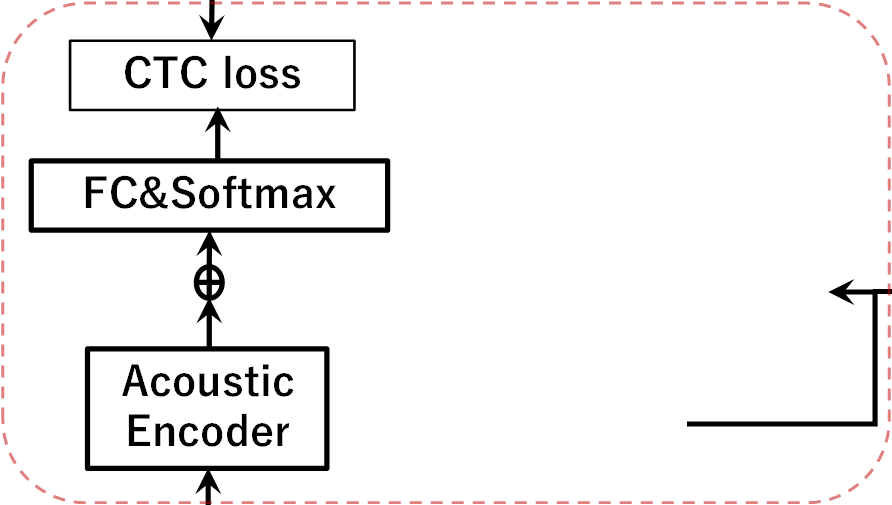
架构详解:
- 输入与编码:
- 声学模态分支:输入语音信号X,经一个Conformer声学编码器(Encoder_A)提取声学特征A(维度dₐ=256)。
- 语言模态分支:输入文本标签序列y,经一个预训练BERT语言编码器(Encoder_L,bert-base-chinese)提取语言特征L(维度dₗ=768)。
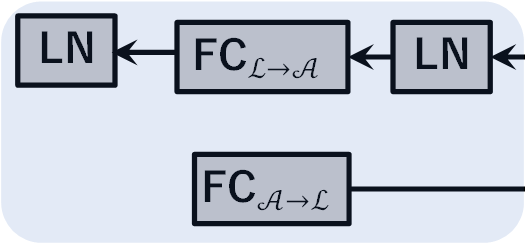
- 适配器模块:由于两个编码器输出维度不同,适配器中包含线性变换层进行维度对齐。
FC_{A→L}: 将声学特征A(dₐ=256)映射到语言维度dₗ=768,得到H。FC_{L→A}: 将语言特征L(dₗ=768)映射到声学维度dₐ=256。- 变换后均经过层归一化(LN)。
- 匹配模块(核心):这是知识迁移的关键。基于声学表示H和语言表示L,利用UOT计算最优传输计划γ*。
- 距离矩阵C:由余弦相似度计算得到。
UOT优化:求解公式(3)-(6)得到γ,它表示声学帧与语言token间的软对齐概率矩阵。
投影:通过
L̃_{H←L} = γᵀ × H(公式7),将声学特征投影到语言空间,得到与语言token对齐的声学表示。
- 距离矩阵C:由余弦相似度计算得到。
UOT优化:求解公式(3)-(6)得到γ,它表示声学帧与语言token间的软对齐概率矩阵。
投影:通过
- 知识融合与预测:
- 将原始声学特征A与经过语言信息调制的特征(通过
FC_{L→A}和LN处理后)进行融合:Ã = A + LN(FC_{L→A}(LN(H)))(公式9)。 - 融合后的特征Ã送入全连接层和Softmax,输出词表概率分布。
- 将原始声学特征A与经过语言信息调制的特征(通过
- 损失函数:
- 主任务损失:CTC损失
L_{CTC},作用于最终输出预测P̃。 - 对齐损失:
L_{align}(公式8),最小化投影后的语言表示L̃与真实语言表示L的余弦距离。 - UOT损失:
L_{UOT}(公式3),即UOT目标函数本身。 总损失:L = η L_{CTC} + (1-η) * (L_{align} + L_{UOT})。
- 主任务损失:CTC损失
- 训练与推理:训练时,优化过程分为内循环(固定γ优化神经网络参数)和外循环(更新γ)。推理时,仅保留声学编码器分支和适配器中的融合路径(图1左支),丢弃语言编码器和匹配模块,因此解码速度与标准CTC系统相当。
💡 核心创新点
- 引入非平衡最优传输(UOT)理论进行跨模态对齐:这是最核心的创新。以往基于OT的对齐(如文献[18])假设质量守恒(平衡OT),无法处理声学帧远多于语言token且存在大量无意义帧(如静音、噪声)的情况。UOT通过边际惩罚项(λ₁, λ₂)允许“质量”的不守恒,能更自然地建模这种不对称的“多对一”和“部分匹配”关系。
- 提供灵活可控的对齐策略:通过不等式设置λ₁和λ₂(如λ₂ > λ₁ 或 λ₁ > λ₂),可以显式控制对齐的偏向:是优先确保每个语言token都被匹配(A2L),还是尽量利用所有声学帧(L2A)。这比黑盒的注意力机制更具可解释性和可控性。
- 将UOT优化嵌入端到端训练:论文设计了一个两步优化的训练范式,在内循环中求解UOT问题(固定γ),在外循环中更新网络参数(固定γ计算梯度),使UOT能与神经网络训练有效地结合。
🔬 细节详述
- 训练数据:
- AISHELL-1:约150小时训练集,10小时验证集,5小时测试集,普通话朗读语料。
- MagicData:755小时,按51:1:2的比例划分训练/验证/测试,普通话朗读语料。
- 预处理:输入为Mel滤波器组特征与基频相关特征的拼接(配置同文献[18])。使用了数据增强(具体未详细说明,参考[22])。
- 损失函数:
L_{CTC}: 标准CTC损失。L_{align}:n ∑ (1 - cos(l̃ⱼ, lⱼ)),即投影语言表示与真实语言表示间的余弦距离和。L_{UOT}: 公式(3)定义的熵正则化UOT目标。- 权重η:固定为0.3。
- 训练策略:
- 优化器:Adam,初始学习率0.002。
- 学习率调度:包含20,000步warm-up。
- 训练轮数:130轮(epochs)。
- 模型平均:使用最后10个epoch的检查点进行平均。
- UOT求解:采用Sinkhorn迭代算法,固定熵正则化系数ε=0.05,迭代直到收敛或达到固定阈值(具体未说明)。
- 关键超参数:
- 声学编码器:Conformer,16层,dₐ=256,4个注意力头,前馈维度2048。
- 语言编码器:bert-base-chinese,12层Transformer,dₗ=768。
- UOT参数:λ₁, λ₂ 根据实验变化(如0.5, 1.0, 10.0);ε=0.05。
- 适配器:
FC_{A→L}为256×768矩阵,FC_{L→A}为768×256矩阵。
- 训练硬件:未说明。
- 推理细节:仅使用声学编码器分支,解码策略为CTC贪心搜索(greedy search)。未提及beam search或其他复杂解码策略。
- 正则化:未提及除UOT熵正则外的其他正则化技巧。
📊 实验结果
主要对比实验:在两个中文ASR数据集上与多个基线系统进行对比。
| 模型/方法 | AISHELL-1 开发集 CER(%) | AISHELL-1 测试集 CER(%) | MagicData 开发集 CER(%) | MagicData 测试集 CER(%) |
|---|---|---|---|---|
| Conformer+CTC (Baseline) | 5.16 | 5.76 | 4.12 | 3.16 |
| Conformer+CTC/AED [26] | 4.31 | 4.82 | 3.81 | 2.96 |
| NAR-BERT-ASR [2] | 4.18 | 4.68 | 3.21 | 2.58 |
| OT-BERT-CTC [18] | 3.81 | 4.19 | 3.04 | 2.17 |
| UOT-BERT-CTC (λ₁=10.0, λ₂=10.0) | 3.82 | 4.21 | 3.01 | 2.21 |
| UOT-BERT-CTC (λ₁=1.0, λ₂=1.0) | 3.70 | 4.13 | - | - |
| UOT-BERT-CTC (λ₁=0.5, λ₂=1.0) | 3.64 | 4.06 | 2.77 | 2.02 |
| UOT-BERT-CTC (λ₁=1.0, λ₂=0.5) | 3.81 | 4.13 | 2.90 | 2.08 |
关键结论与图表分析:
- 相对优势:在所有参数设置下,提出的UOT-BERT-CTC均优于或持平于OT-BERT-CTC基线。当λ₁, λ₂足够大(10.0)时,性能与标准OT方法非常接近,符合理论预期。
- 参数影响:当λ₂ > λ₁(如0.5, 1.0)时,性能最佳。这表明在ASR任务中,采用“声学到语言”(A2L)的对齐策略(即确保每个语言token都有对应声学帧,同时允许跳过噪声帧)更为有效。
- 对齐可视化:下图(对应原文图2)展示了不同λ₁, λ₂设置下的对齐矩阵γ*。
- (a) 原始余弦相似度矩阵。(b) 均匀高斯对齐(理想参考)。(c) λ₁=λ₂=1.0:保留较多对应,对齐较平滑。(d) λ₁=0.01, λ₂=1.0:强烈偏向语言侧(λ₂大),对齐更稀疏、更聚焦于语言token。(e) λ₁=1.0, λ₂=0.01:偏向声学侧(λ₁大),尝试利用更多声学帧。(f) λ₁=λ₂=0.05:双方约束都弱,对齐高度选择性,丢弃大量帧。
- 改进幅度:在MagicData测试集上,最优配置相比OT基线实现了约7%((2.17-2.02)/2.17)的相对CER降低,改进明显。在AISHELL-1上,相对改进约为3%。
⚖️ 评分理由
- 学术质量:3.4/7:论文将UOT理论清晰地应用于ASR跨模态对齐,解决了特定问题,技术实现正确。但创新点主要是方法的适配和调整,而非提出全新模型或解决更广泛问题。实验仅在两个中文数据集上验证,缺乏对更复杂场景(如噪声、方言、多语言)和现代E2E架构(如Transducer)的验证,证据强度一般。
- 选题价值:1.5/2:ASR中的知识迁移是提升性能的重要途径,对齐是其中的核心瓶颈。本文针对这一具体问题提出解决方案,对ASR和跨模态学习领域的研究者有参考价值。但其应用场景相对垂直。
- 开源与复现加成:0.0/1:论文未提供代码、预训练模型、详细训练脚本或硬件信息,只给出了有限的超参数。复现需要大量额外工作,这严重限制了工作的可验证性和后续影响力。