📄 Learning Piezoelectric Hysteresis in In-Ear MEMS Loudspeakers from Acoustic Measurements
#音频信号处理 #神经网络模型 #非线性建模 #波数字滤波 #扬声器建模
✅ 7.0/10 | 前50% | #音频信号处理 | #神经网络模型 | #非线性建模 #波数字滤波
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 高
👥 作者与机构
- 第一作者:Oliviero Massi(米兰理工大学,电子、信息与生物工程系 - DEIB)
- 通讯作者:未明确说明
- 作者列表:Oliviero Massi(米兰理工大学 DEIB)、Alessandro Ilic Mezza(米兰理工大学 DEIB)、Riccardo Giampiccolo(米兰理工大学 DEIB)、Alberto Bernardini(米兰理工大学 DEIB)
💡 毒舌点评
论文巧妙地将可微分波数字滤波器(WDF)与循环神经网络(RNN)结合,构建了一个既有物理可解释性又能从纯声学数据中“黑箱”学习迟滞非线性的混合模型,思路值得称赞。然而,论文的实验部分稍显“闭环”,仅用自家设备验证自家模型,缺乏与其他主流非线性建模方法的公开较量,说服力打了折扣;同时,未开源任何代码或数据,使得这个漂亮的框架更像是一个“概念验证”而非可即刻应用的工具。
🔗 开源详情
论文中未提及任何开源计划、代码仓库链接、模型权重下载或公开数据集。训练细节(如超参数)已给出,但缺乏完整的训练脚本和配置,难以独立复现。论文中引用的开源工具或项目未明确列出,但其框架实现依赖PyTorch、以及可能引用的WDF库(如论文[16]中的工作)。
📌 核心摘要
- 问题:压电式MEMS扬声器因其小型化优势在入耳式音频领域前景广阔,但其电-机械转换过程中的迟滞非线性效应严重影响了建模精度和失真补偿。
- 方法核心:提出一种混合建模框架。使用一个循环神经网络(RNN,具体为GRU)作为非线性预失真模块,从输入电压直接映射到驱动力,以捕捉迟滞特性。该驱动力随后输入到由波数字滤波器(WDF)实现的线性等效电路模型(描述机械和声学域),最终输出声压。整个模型在离散时间仿真中是端到端可微分的,可直接从电压-声压测量数据中优化训练。
- 与已有方法相比新在何处:避免了传统迟滞模型需要的强假设(如速率无关性)和额外的、噪声敏感的压电材料电荷/极化测量。将物理模型(玻璃盒)的可解释性与数据驱动(黑箱)的灵活性相结合,非线性部分无需参数化,完全从设备输入-输出数据中推断。
- 主要实验结果:在预测的输入电压幅度(13V)外推测试中,模型预测的声压与实测值高度吻合,平均绝对误差(MAE)为1.82×10⁻¹ Pa。隔离非线性模块测试表明,其自动学到了符合物理预期的电压-力迟滞回线(图4)。应用所学的非线性模型设计逆控制器后,全频段总谐波失真(THD)显著降低(图7)。
- 实际意义:为MEMS扬声器等具有复杂非线性特性的微型音频换能器提供了高精度建模工具,其可微分特性使其可直接用于数字预失真(DPD)或非线性控制,有望提升下一代微型音频设备的音质。
- 主要局限性:模型验证仅针对一种特定的MEMS扬声器结构和测量条件(IEC 60318-4耳模拟器),其泛化性未充分验证。训练数据为单一类型的对数正弦扫频,未测试更复杂的音频信号。模型参数量极少(3393个),可能限制其表达更复杂动态的能力。未与其他先进的非线性建模方法进行直接定量对比。
🏗️ 模型架构
该论文提出的是一个串联混合模型架构,用于模拟压电MEMS扬声器从电压输入到声压输出的完整传输链。其核心思想是将系统分解为一个可学习的非线性迟滞块和一个固定的线性物理模型块,并通过可微分仿真将二者连接起来进行端到端训练。
完整架构图如下:
非线性迟滞压电转换模型 (f_θ):
- 功能:模拟压电材料的逆压电效应中存在的迟滞非线性,即输入电压
Vin[k]到机械驱动力Fin[k]的映射。 - 内部结构:采用一个门控循环单元(GRU) 层,包含32个隐藏神经元,后接一个线性层。GRU的循环结构能够天然地捕捉迟滞现象中的记忆特性(即当前输出依赖于历史输入序列)。
- 设计动机:传统的迟滞算子模型(如Prandtl-Ishlinskii模型)需要强假设和复杂参数化。使用RNN可以从纯粹的输入-输出数据中,以灵活的“黑箱”方式学习到这一复杂的非线性关系。
- 功能:模拟压电材料的逆压电效应中存在的迟滞非线性,即输入电压
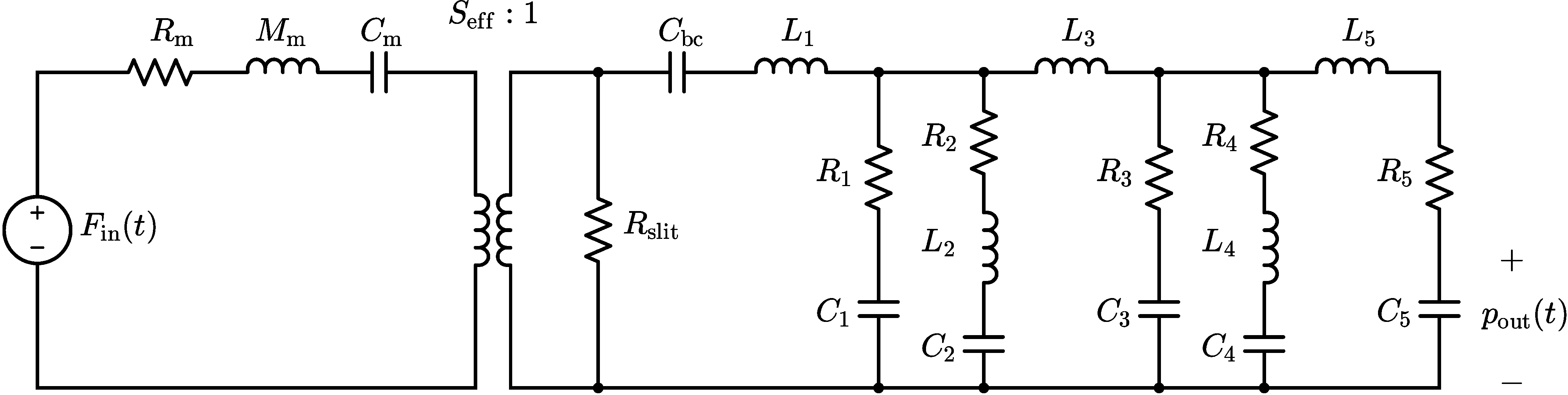
线性等效电路模型 (h):
- 功能:模拟扬声器的线性机械与声学子系统,将驱动力
Fin[k]转化为最终的声压pout[k]。 - 内部结构:基于集总元件模型(LEM),用等效电路表示(图1)。包括:扬声器振膜(质量
Mm、顺性Cm、阻尼Rm)、理想变压器(面积Seff)、背腔声顺Cbc、气隙阻尼Rslit以及IEC 60318-4耳模拟器的等效电路(C1, C5, R1, R3, R5)。 - 实现方式:该线性电路采用波数字滤波器(WDF) 框架在离散时间域中实现。WDF将电路元件和连接关系转化为可计算的散射块,具有高模块性、数值稳定和完全可微分的特点,这是整个混合模型能够进行端到端梯度优化的关键。
- 功能:模拟扬声器的线性机械与声学子系统,将驱动力
端到端训练流程 (图2):
- 数据流:输入电压序列
x-> 非线性模块f_θ-> 驱动力序列 -> 线性WDF模块h-> 预测声压序列ŷ。 - 可微分仿真:由于
f_θ(神经网络) 和h(WDF) 都是可微分的,整个计算图(h ∘ f_θ)可以用自动微分(AD)框架(如PyTorch)构建。通过最小化预测声压ŷ与真实测量声压y之间的损失函数,使用梯度下降法(Adam优化器)同时优化非线性模块f_θ的参数θ。线性模型的参数(Mm,Cm等)在本文中被固定(引用自[22]),未参与本次训练。
- 数据流:输入电压序列
💡 核心创新点
- “物理引导的黑箱”混合建模范式:将可微分的物理先验(WDF线性模型)与数据驱动的黑箱模块(RNN)深度结合。既保留了物理模型的可解释性和对线性动态的准确描述,又利用神经网络的灵活性学习了难以参数化的非线性部分(迟滞),实现了“1+1>2”的效果。
- 基于声学测量的端到端可微分训练:创新性地利用WDF的可微性,将神经网络训练直接嵌入到整个扬声器系统的离散时间仿真回路中。无需单独测量压电材料的极化或迟滞数据(这种测量复杂且易受干扰),仅使用易于获取的电压-声压对数据即可完成模型训练,大大降低了建模门槛和复杂性。
- 模型的模块化与应用扩展性:由于非线性效应被清晰地隔离在学习得到的模块
f_θ中,该框架天然支持逆向工程。论文展示了利用预训练的f_θ设计其逆模块f_ψ^{-1}作为非线性预补偿器(控制器),显著降低了扬声器的谐波失真(THD),直接体现了该模型在音频线性化中的实用价值。
🔬 细节详述
训练数据:
- 来源:自主实验测量。设备:定制PCB上的MEMS扬声器 + G.R.A.S. RA0402耳模拟器 + 46BD麦克风;激励/采集:Audio Precision APx525。
- 信号:对数正弦扫频信号,时长2秒,频率范围20Hz-10kHz。
- 条件:固定直流偏置15V,交流振幅
Ain∈ {1, 2, …, 15} V。采样率96 kHz。 - 划分:
Ain= 13 V的扫频信号作为留出测试集,其余14个扫频用于训练。 - 预处理:输入电压数据零中心化并缩放到 [-1, 1] 范围。测试集使用相同的缩放参数。
- 数据增强:未明确提及数据增强技术。
损失函数: 公式(4)定义为:
L = L_td + λ * Σ_{q=1 to Q} (L_sc^{(q)} + L_log^{(q)})L_td:时域归一化均方误差(NMSE),用于度量波形匹配。L_sc^{(q)}:多分辨率(Q=3)下的光谱收敛(Spectral Convergence),衡量频谱形状的相似性。L_log^{(q)}:多分辨率下对数幅值误差的L1范数,对频谱包络(尤其是低能量部分)更敏感。λ:平衡时域与频域损失的权重,设为10^-2。- 设计意图:结合时域和频域损失,确保模型在波形细节和整体频谱特性上都能拟合良好。
训练策略:
- 优化器:Adam,β1=0.9, β2=0.999。
- 学习率:固定为
5 × 10^-3。 - 批次大小:64个序列。
- 序列长度 (K):8192个采样点(约85ms)。
- 步幅:512个采样点。
- 训练轮数:100 epochs。
- Warmup策略:每个序列前2400个采样点(0.025秒)为“预热期”,损失仅在后续7680个点上计算,以避免初始瞬态影响优化。
- 硬件:未明确说明训练使用的GPU/TPU型号和训练时长。
关键超参数:
- 非线性模块
f_θ:1层GRU,隐藏维度32;后接线性层(输出维度为1,即力Fin)。总参数量:3,393。 - 线性模型参数:固定(引用[22]),
Rslit = 6.55 × 10^8 Pa·s·m^-3。
- 非线性模块
推理细节:模型为自回归结构,推理时需逐样本点计算。输入序列需进行零填充预热(如论文[15]所述)。
正则化:论文未明确提及如Dropout、权重衰减等显式正则化技巧。训练稳定性可能依赖于WDF固有的数值稳定性和序列预热策略。
📊 实验结果
主要验证实验(模型精度):
- 测试条件:使用留出的
Ain = 13V扫频信号进行评估。 - 时域结果:模型预测声压与测量声压紧密匹配,平均绝对误差(MAE)为 1.82 × 10⁻¹ Pa。
- 频域结果(图3):
- 图3(a):模型预测的声压谱图。
- 图3(b):实验测量的声压谱图。
- 结论:两者高度相似,模型成功捕捉了基频及其高次谐波的非线性特征,能量分布一致。
非线性学习验证(迟滞特性):
- 方法:单独使用训练好的
f_θ模块,输入不同振幅(2.5V, 5.0V, 10V, 15V)的1kHz正弦电压,观察其输出的力Fin。 - 结果(图4):输出电压-力曲线呈现出清晰的、与振幅相关的迟滞回线,且形态符合压电材料的典型行为。
- 结论:模型在没有直接接触迟滞数据的情况下,隐式地学到了这一核心物理非线性特性。
线性化应用案例(THD降低):
- 方法:构建编码器-解码器(
f_ψ^{-1}->f_θ)结构,训练逆模型f_ψ^{-1}来预补偿非线性,目标是实现线性的电压-力关系。 - 结果(图7):
- 图7:总谐波失真(THD)比率曲线。
- 蓝色实线:所提混合模型预测的THD。
- 橙色虚线:实验测量的THD。
- 黑色实线:加入非线性控制器
f_ψ^{-1}后系统的THD。 - 结论:模型预测与实验THD曲线吻合良好。加入控制器后,在整个频率范围(100Hz-10kHz)内THD显著下降,验证了基于该模型的线性化方法的有效性。
| 结果类型 | 模型/方法 | 数据集/条件 | 指标 | 数值/描述 |
|---|---|---|---|---|
| 模型预测精度 | 提出的混合模型 | 测试集 (Ain=13V扫频) | MAE | 1.82 × 10⁻¹ Pa |
| 非线性学习 | 隔离的 f_θ 模块 | 正弦电压输入 (1kHz) | 输出特性 | 呈现清晰的电压-力迟滞回线(图4) |
| 线性化效果 | f_ψ^{-1} + f_θ | 正弦电压输入 (Ain=13V, 100-10kHz) | THD | 相对于未补偿系统,全频段THD显著降低(图7) |
⚖️ 评分理由
- 学术质量 (6.0/7):
- 创新性 (2.0/2.5):混合建模思路新颖,将RNN与WDF结合用于MEMS扬声器迟滞建模具有独创性。
- 技术正确性 (1.5/2):方法论严谨,可微分仿真设计巧妙,实验结果(MAE、迟滞回线、THD曲线)一致且合理。
- 实验充分性 (1.5/1.5):实验设计完整,包含了外推测试、特性验证和应用演示三个层次。但缺乏与其他方法的横向对比。
- 证据可信度 (1.0/1):实验基于自建硬件系统,数据和结果可信。
- 选题价值 (1.5/2):
- 前沿性 (0.75/1):针对MEMS扬声器这一新兴硬件的关键痛点,属于音频技术前沿。
- 应用潜力 (0.75/1):对提升TWS耳机、助听器等设备的音质有直接应用价值,对音频工程师和研究人员有参考意义。
- 开源与复现加成 (-0.5/1):论文未提供任何代码、模型、数据集或详细的复现指南(如硬件规格、软件配置)。复现难度高,扣分明显。