📄 Learning Linearity in Audio Consistency Autoencoders via Implicit Regularization
#音频生成 #音乐生成 #扩散模型 #数据增强 #模型评估
✅ 7.5/10 | 前25% | #音频生成 | #扩散模型 | #音乐生成 #数据增强
学术质量 6.5/7 | 选题价值 1.0/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Bernardo Torres(LTCI, Telecom Paris, Institut Polytechnique de Paris)
- 通讯作者:未说明
- 作者列表:Bernardo Torres(LTCI, Telecom Paris, Institut Polytechnique de Paris),Manuel Moussallam(Deezer Research),Gabriel Meseguer-Brocal(Deezer Research)
💡 毒舌点评
亮点:方法异常优雅——仅通过训练时对潜向量和音频波形施加精心设计的数据增强(增益缩放和人工混合),就“教”会了一个复杂的扩散自编码器学习线性,而不增加任何额外的损失项或架构改动。短板:该方法严重依赖于所选择的 Music2Latent CAE 架构,其通用性未得到验证;且论文中展示的“音源分离”仅为基于潜空间算术的Oracle实验,距离实际、复杂的分离应用仍有很大差距,更像一个原理验证(proof-of-concept)。
🔗 开源详情
- 代码:提供代码仓库链接:
www.github.com/bernardo-torres/linear-autoencoders。 - 模型权重:提供了公开的模型权重(论文中提及“Code and model weights are available online”)。
- 数据集:使用了多个公开数据集(MTG-Jamendo, MoisesDB等)的混合,未提及新的专属数据集。
- Demo:提供了在线音频示例和项目页面(
https://bernardo-torres.github.io/projects/linear-cae)。 - 复现材料:训练细节(超参数、调度、数据增强细节)在论文3.3节和相关脚注中描述得非常充分。
- 依赖的开源项目:依赖于Music2Latent [4]架构,并可能使用了
kadtk库进行KAD评估。
📌 核心摘要
- 要解决什么问题:现代音频自编码器(AE)能实现高压缩和高质量重建,但其编码得到的潜在空间通常是非线性的、纠缠的,导致无法进行直观的代数操作(如在潜空间直接混合或缩放音频)。
- 方法核心是什么:提出一种基于数据增强的隐式正则化方法,在不改变自编码器(本文为一致性自编码器CAE)架构和损失函数的前提下,诱导其学习线性(齐次性和可加性)。具体技巧包括:(1) 隐式齐次性:训练时对潜向量施加随机增益
a,并要求解码器从带增益a的音频中重建,迫使模型学习增益的线性映射;(2) 隐式可加性:通过构造人工混合音频,并用其对应源潜向量的平均值作为条件进行训练,鼓励加法性质。 - 与已有方法相比新在哪里:与需要修改架构或引入额外损失项的方法不同,本工作证明仅通过训练时的数据增强就能有效诱导出近似的线性潜空间。这使得自编码器在保持原有高压缩比(64倍)和单步重建能力的同时,获得了可操作性。
- 主要实验结果如何:在MusicCaps和MUSDB18-HQ数据集上的实验表明,所提出的Lin-CAE模型:
- 重建质量:与基线CAE(M2L)相当,在MSS上(1.01 vs 0.98)和SNR上(3.19 vs 3.09)略有提升。
- 同质性(齐次性):远优于所有基线。解码器同质性MSS降解从基线的约2.3倍(0.98→2.27)减少至1.36倍(1.01→1.37)。
- 可加性与源分离:在潜空间算术任务中表现突出。解码器可加性MSS从基线的5.0以上降至0.99。在Oracle音源分离(减去伴奏潜向量)任务中,Lin-CAE的SI-SDR和MSS在所有乐器上均显著优于基线,例如人声分离SI-SDR为-1.18 dB(基线M2L为-12.56 dB)。
- 实际意义是什么:提供了一种简单有效的技术,用于构建结构化、可操作的音频潜空间。这使得在压缩域内进行高效的音频混合、编辑和分离成为可能,为音频生成和处理提供了更直观的接口。
- 主要局限性是什么:方法与特定的CAE架构耦合紧密,泛化性未知;所验证的源分离任务为理想化的Oracle设置(已知需要分离的源),未处理真实场景下的盲分离;线性是近似的,其程度可能随任务复杂度增加而面临挑战。
🏗️ 模型架构
本文提出的Lin-CAE架构基于已有的Music2Latent (M2L)一致性自编码器(CAE),并未修改其基础结构,仅在训练流程上进行了增补。整体架构是一个条件扩散模型,用于音频压缩与重建。
整体流程:
- 编码器 (Encθ):接收波形音频
x,首先经过可逆幅度变换Amp(STFT(x))将其映射到STFT表示空间。然后通过一个与解码器U-Net的下采样部分结构镜像的网络,将高维音频表示压缩为低维潜向量zx。 - 解码器 (Decθ):是一个条件去噪U-Net。它接收从纯噪声开始的含噪音频
xσ = x + σ·ε,并以潜向量zx和噪声水平σ为条件,通过单步预测直接重建出干净音频。潜向量zx通过一个专用上采样网络,在U-Net的每个分辨率层级被注入。解码器最终输出为:fθ(xσ, σ, zx) = cskip(σ)xσ + cout(σ)Fθ(xσ, σ, zx),其中Fθ是噪声预测网络。
- 编码器 (Encθ):接收波形音频
关键设计选择与动机:
- 使用CAE/M2L架构:该架构能实现高质量、单步解码,且压缩率高达64倍,是理想的测试平台。其解码器本质上是扩散模型,能“采样”出细节,这可能减轻了编码器需要精确编码所有信息的压力。
- 条件注入方式:潜向量在U-Net的多个层级注入,确保了条件信息的充分融合,这对于在去噪过程中维持线性特性至关重要。
- 隐式线性化训练:核心创新不在架构,而在训练时的数据增强策略,旨在诱导上述架构学习出具有特定代数性质的映射。
 图2说明:(a)展示了基础的Music2Latent CAE架构,编码器压缩音频,解码器是一个以潜向量为条件的U-Net去噪器。(b)和(c)分别详细说明了为诱导齐次性和可加性而设计的两种数据增强训练流程。(d)展示了创建训练批次中人工混合数据的方法。
图2说明:(a)展示了基础的Music2Latent CAE架构,编码器压缩音频,解码器是一个以潜向量为条件的U-Net去噪器。(b)和(c)分别详细说明了为诱导齐次性和可加性而设计的两种数据增强训练流程。(d)展示了创建训练批次中人工混合数据的方法。
💡 核心创新点
- 基于数据增强的隐式正则化诱导线性:这是最核心的创新。通过在训练时对潜向量施加随机增益
a,并让解码器重建对应增益a·x的音频(隐式齐次性),以及训练解码器从人工混合音频的潜向量平均值重建混合音频(隐式可加性),无需修改损失函数,成功诱导模型学习线性映射。这比显式添加正则化损失项更简洁、优雅。 - 在保持高压缩与高质量的前提下实现可操作性:以往使AE潜空间可操作(如线性化)的工作常以牺牲重建质量或改变架构为代价。本方法证明,在先进的CAE架构上,通过巧妙的训练数据生成策略,可以同时保持高压缩率(64×)、高质量重建,并显著提升线性性质,实现了多个目标的兼顾。
- 对编解码器两端同时产生线性化效应:实验显示,所提方法不仅使解码器具备了良好的齐次性和可加性,也显著改善了编码器的线性性质(Enc-Hom. Error降低)。这表明隐式条件化策略鼓励了整个自编码器映射变得更加线性,而非仅仅约束解码器,揭示了方法更深层次的效益。
🔬 细节详述
- 训练数据:一个大型音乐/语音混合数据集,来源包括MTG-Jamendo, MoisesDB, M4Singer, DNS-Challenge, E-GMD,按权重(60, 20, 9, 8, 3)采样。每条音频随机裁剪2秒,转为单声道44.1kHz。
- 损失函数:使用原始的一致性训练(CT)目标
LCT(公式4),最小化学生网络fθ和教师网络fθ⁻在不同噪声水平下去噪输出的距离。权重λ(σt1, σt2)用于平衡不同噪声步长。距离度量d为伪Huber损失。 - 训练策略:
- 优化器:RAdam,学习率
[10⁻⁴, 10⁻⁶]线性warmup 10K步后余弦衰减。 - 批次大小:原始batch size 20,经人工混合增强后最终为40。
- 总步数:800K步。
- EMA:使用指数移动平均参数进行推理,每10步更新一次。
- 关键增益采样策略:增益
a从均匀分布[amin, amax]采样,以0.8概率应用。增益范围在训练过程中通过分段余弦退火从(0, 3)衰减到(1, 1)。定义了amin(k)和amax(k)的具体退火公式(3.3节)。|a|<0.05时设为0,并进行裁剪避免波形溢出。
- 优化器:RAdam,学习率
- 训练硬件:1块NVIDIA L40S GPU,训练时长约8天。
- 推理细节:从纯噪声开始,单步解码。推理使用EMA参数。
📊 实验结果
主要实验设置与基线:在MusicCaps(重建与同质性)和MUSDB18-HQ(可加性与源分离)上评估。基线包括:原始公开权重M2L-Pub [4]、在相同数据上重新训练的基线M2L(包含数据增强但不使用隐式线性化技巧)、以及Stable Audio 1.0 VAE (SA-VAE) [13]。
表2:重建质量与齐次性(在MusicCaps数据集)
| 模型 | 重建 MSS↓ | 重建 SNR↑ | Dec-Hom. MSS↓ | Dec-Hom. SNR↑ | Enc-Hom. Error↓ | KAD↓ |
|---|---|---|---|---|---|---|
| M2L-Pub [4] | 1.14 | 1.85 | 2.52 | -4.69 | 12.13 | 5.69 |
| SA-VAE [13] | 0.72 | 7.32 | 3.03 | -1.27 | 4.59 | 6.27 |
| M2L (重训) | 0.98 | 3.09 | 2.27 | -2.30 | 8.52 | 6.53 |
| Lin-CAE | 1.01 | 3.19 | 1.37 | 0.86 | 0.69 | 6.19 |
关键结论:Lin-CAE的重建质量与重训基线M2L相当甚至略优。在齐次性任务中,Lin-CAE表现远超所有基线,解码器MSS降解最小,编码器同质性误差极低。
表1:可加性与Oracle音源分离(在MUSDB18-HQ数据集)
| 模型 | Decoder Additivity Mix MSS↓ | Encoder Additivity Error↓ | Bass SI-SDR↑ | Drums SI-SDR↑ | Other SI-SDR↑ | Vocals SI-SDR↑ |
|---|---|---|---|---|---|---|
| M2L-Pub [4] | 5.01 | 2.82 | -14.85 | -16.30 | -16.11 | -18.16 |
| SA-VAE [13] | 5.38 | 1.71 | -2.81 | -3.11 | -4.10 | -4.48 |
| M2L (重训) | 5.21 | 2.73 | -11.11 | -11.95 | -11.81 | -12.56 |
| Lin-CAE | 0.99 | 0.60 | -0.59 | -0.28 | -1.82 | -1.18 |
| 消融:- 加法性 | 1.68 | 2.07 | -7.12 | -6.11 | -8.52 | -12.18 |
| 消融:- 齐次性 | 4.24 | 1.42 | -5.96 | -5.14 | -8.30 | -7.95 |
关键结论:Lin-CAE在可加性和源分离任务上全面且大幅领先所有基线。其解码器可加性MSS(0.99)远低于基线(>5)。在Oracle分离任务中,其SI-SDR接近其自身重建性能,表明潜空间算术非常有效。消融实验显示,同时包含齐次性和可加性技巧效果最佳。
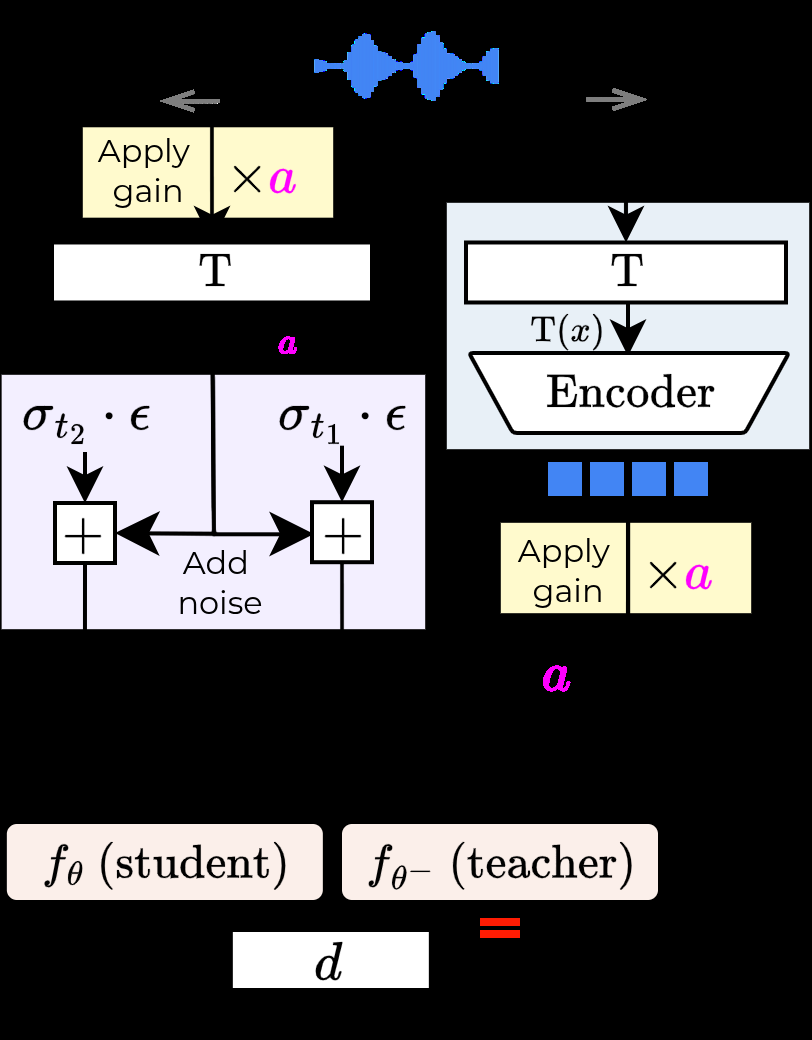 图3说明:展示了如何通过从完整混合音的潜向量中减去伴奏的潜向量,再经解码器重建,来实现目标声源的估计。
图3说明:展示了如何通过从完整混合音的潜向量中减去伴奏的潜向量,再经解码器重建,来实现目标声源的估计。
⚖️ 评分理由
- 学术质量:6.5/7:创新性在于提出并验证了一种通过数据增强实现线性化的“训练技巧”,方案简洁有效。技术正确,实验设计全面,涵盖了从重建质量到多种线性性质,再到实用任务(分离)的完整评估链,并配有消融实验。证据可信,指标选择恰当。
- 选题价值:1.0/2:研究音频自编码器的可操作性是一个有价值的方向,对音频编辑、混合、分离等下游任务有直接促进作用。但该问题在学术和工业界的关注度相对集中于特定领域,通用影响力可能有限。
- 开源与复现加成:0.5/1:开源情况优秀,代码、预训练模型、在线示例齐全。训练细节如增益退火公式、批次构建方法描述得极为详尽,几乎达到了“食谱”级别,极大地降低了复现门槛。