📄 Learning Domain-Robust Bioacoustic Representations for Mosquito Species Classification with Contrastive Learning and Distribution Alignment
#生物声学 #对比学习 #领域适应 #音频分类
✅ 7.5/10 | 前25% | #生物声学 | #对比学习 | #领域适应 #音频分类
学术质量 6.0/7 | 选题价值 1.0/2 | 复现加成 0.5 | 置信度 中
👥 作者与机构
- 第一作者:Yuanbo Hou(University of Oxford, UK)
- 通讯作者:Yuanbo Hou(Yuanbo.Hou@eng.ox.ac.uk, University of Oxford, UK)
- 作者列表:Yuanbo Hou(University of Oxford, UK)、Zhaoyi Liu(KU Leuven, Belgium)、Xin Shen(University of Oxford, UK)、Stephen Roberts(University of Oxford, UK)
💡 毒舌点评
亮点在于针对生物声学数据的特性(物种间声学特征相似、域间差异大)设计了包含对比学习和条件分布对齐的多损失函数框架,消融实验设计合理。短板是方法的理论分析部分较弱,更多是现象驱动;实验中的“非严格留一域外评估”设计是一个明显妥协,削弱了“跨域泛化”这一核心主张的证明力度。
🔗 开源详情
- 代码:提供代码仓库链接:https://github.com/Yuanbo2020/DR-BioL。
- 模型权重:论文中未提及是否公开预训练模型权重。
- 数据集:论文中使用的数据集来自已公开的HumBugDB、Kasetsart、UFRGS、Abuzz数据集。论文未提及是否提供了组合后的数据集下载链接。
- Demo:论文中未提及提供在线演示。
- 复现材料:论文给出了主要训练超参数(优化器、学习率、batch size、早停策略)、模型架构描述(CNN块结构)和损失函数定义,但未提供完整的训练脚本、配置文件或详细日志。
- 引用的开源项目:论文依赖了多个公开数据集(HumBugDB, Kasetsart, UFRGS, Abuzz)。模型部分参考了VGG架构、PANNs、YAMNet、MobileNetV2等经典模型或预训练模型。
📌 核心摘要
- 要解决什么问题:蚊子物种分类(MSC)模型在不同录音环境(域)下性能急剧下降,因为模型倾向于学习易于区分的“域特征”(如背景噪声、设备差异)而非真正的物种声学特征,导致跨域泛化能力差。
- 方法核心是什么:提出DR-BioL框架,结合监督对比学习和物种条件分布对齐。对比学习通过两个损失(物种内聚损失ScoL、域不变损失DicL)拉近同类样本、推远异类样本,同时抑制域差异;条件分布对齐损失(SdaL)使用最大均值差异(MMD)对齐同一物种在不同域的表示分布。
- 与已有方法相比新在哪里:不同于传统域对抗训练(DAT)通过梯度反转层强制消除所有域特征(可能损害物种判别性),DR-BioL采用更灵活的对比学习策略,旨在引导模型优先学习物种判别特征,并选择性地抑制域差异。这是针对生物声学数据特性的定制化设计。
- 主要实验结果如何:在一个包含4个域、8个物种、约33小时的多域蚊子音频数据集上进行实验。
- 表1(跨域泛化示例):
训练集 测试集 CNN DR-BioL CNN D1 + D2 D1 + D2 99.79% 92.81% D1 + D2 D3 41.40% 74.92% 注:在同分布测试时CNN准确率更高,但在新域D3上DR-BioL显著更优,证明了其鲁棒性。 - 表2(消融实验):逐步移除物种相关损失(#2, #3),验证集准确率从82.19%降至80.57%;移除域相关损失(#5),准确率升至82.68%,表明模型利用域特征获得“虚假”提升。
- 表3(权重调优):调整损失权重,最佳组合(#3)将验证集准确率从82.19%提升至84.64%。
- 表4(主要对比结果):
模型 参数量(M) FLOPs(G) 准确率(%) AUC AP Baseline CNN 4.9530 2.6152 80.031 0.9680 0.8616 PANNs 79.6902 3.9787 81.679 0.9653 0.8511 DAT CNN 5.0854 2.6155 79.583 0.9607 0.8481 DR-BioL 5.0854 2.6155 85.345 0.9732 0.9002 DR-BioL在准确率、AUC、AP上均优于所有基线,包括参数效率模型(YAMNet, MobileNetV2)和强大的预训练模型(PANNs)。 - 图4:t-SNE可视化显示,DAT将域嵌入混合成模糊曲线,而DR-BioL的嵌入虽跨域收敛但保留了部分结构,表明其学习到了更平衡的表示。
- 表1(跨域泛化示例):
- 实际意义是什么:该工作推动了生物声学监测技术在真实多变环境中的可靠性,使基于声音的蚊子监控更有可能从实验室走向大规模野外部署,辅助疟疾等疾病防控。
- 主要局限性是什么:实验数据集中部分物种(4-7)仅存在于单一域(D1),导致测试集与训练集无法完全分离,存在一定程度的域重叠,这虽然被论文提及并部分归因于数据稀缺,但仍是对“跨域”评估严格性的一个妥协。
🏗️ 模型架构
DR-BioL是一个基于CNN的端到端框架,包含一个共享的音频编码器和多个特定任务分支,通过五个联合优化的损失函数进行训练。
完整输入输出流程:
- 输入:64-bin对数梅尔能量特征图(音频预处理后的时频表示)。
- 编码器:一个类VGG的CNN编码器,提取高层声学表示。
- 分支与输出:编码器的输出被送入四个并行的全连接(FC)分支:
- 物种嵌入层 -> 物种分类层 -> 输出物种预测概率分布
ŷs。 - 域嵌入层 -> 域分类层 -> 输出域预测概率分布
ŷd。
- 物种嵌入层 -> 物种分类层 -> 输出物种预测概率分布
- 用于对比学习的两个分支(物种内聚、域不变)直接从物种嵌入层和域嵌入层的输出(即表示向量)中计算损失,不产生分类输出。
主要组件:
- 生物声学表示编码器:一个4块的VGG-like CNN。每个块包含2个3x3卷积层、批归一化和ReLU激活。通道数依次为64、128、256、512。功能是从梅尔频谱图中提取鲁棒的声学特征。
- 物种分类分支:由物种嵌入层(512维FC)和物种分类层(
Ns维FC,Ns为物种数)组成。使用二元交叉熵损失(LScL),支持多标签分类(一个样本可能对应多个物种)。 - 域分类分支:由域嵌入层(256维FC)和域分类层(
Nd维FC,Nd为域数)组成。使用交叉熵损失(LDcL),是一个单标签多分类任务。 - 对比学习组件:不引入新层,而是利用物种嵌入层和域嵌入层的输出向量,根据不同的正样本定义策略(按物种标签、按域标签),计算两个监督对比损失(
LScoL,LDicL)。 - 分布对齐组件:同样不引入新层,而是对物种嵌入层的输出向量,计算同一物种样本对之间的最大均值差异(MMD),形成
LSdaL。
数据流与交互:所有分支共享编码器的输出特征。物种分类损失、对比学习损失(物种内聚)、分布对齐损失共同作用于物种相关的表示(来自物种嵌入层),旨在学习具有物种判别性和跨域一致性的特征。域分类损失和域不变对比损失则作用于域相关的表示(来自域嵌入层),并反向传播以影响共享编码器,旨在让编码器学习的特征对域差异不敏感。五个损失加权求和(
L = λ1LScL + λ2LScoL + λ3LSdaL + λ4LDcL + λ5*LDicL)进行联合优化。关键设计选择与动机:
- 分离的嵌入层:物种嵌入和域嵌入的FC层分离,允许模型学习对任务专门化的子空间。
- 多损失函数组合:动机在于蚊子数据特性——物种间声学特征相似(需要强判别性,故用
LScoL),录音间域差异大(需要域不变性,故用LDicL和LSdaL)。单一损失无法同时优化这些目标。 - 对比正样本的两种定义:
Pspecies(i)将同物种的所有样本作为正对,增强类内紧凑性;Pdomain(i)将所有来自不同域的样本作为正对,强制模型将不同域的同类样本拉近,实现“跨域物种内聚”。
 图2展示了DR-BioL的CNN实例化结构。输入梅尔频谱图经过CNN编码器提取特征,随后分支进入物种嵌入层、域嵌入层。物种嵌入层后接物种分类层(计算LScL),并作为对比学习(计算LScoL)和分布对齐(计算LSdaL)的输入。域嵌入层后接域分类层(计算LDcL),并作为域不变对比学习(计算LDicL)的输入。五个损失加权求和进行端到端训练。
图2展示了DR-BioL的CNN实例化结构。输入梅尔频谱图经过CNN编码器提取特征,随后分支进入物种嵌入层、域嵌入层。物种嵌入层后接物种分类层(计算LScL),并作为对比学习(计算LScoL)和分布对齐(计算LSdaL)的输入。域嵌入层后接域分类层(计算LDcL),并作为域不变对比学习(计算LDicL)的输入。五个损失加权求和进行端到端训练。
💡 核心创新点
- 针对生物声学数据特性的多损失函数框架设计:将对比学习与条件分布对齐相结合,形成一个针对蚊子声学数据“物种相似、域差异大”特性的优化框架。这超越了通用域适应方法(如DAT),提供了更灵活的域鲁棒学习机制。
- 双重对比学习策略(物种内聚与域不变):
LScoL通过监督对比学习增强类内表示的一致性;LDicL则创新性地将不同域的样本作为正对进行对比,直接促进跨域的特征对齐。这种双重约束协同作用于共享编码器,是平衡判别性与不变性的关键。 - 物种条件分布对齐损失:在对比学习拉近同类样本的基础上,使用MMD(
LSdaL)进一步显式地对齐每个物种在不同域的表示分布,提供了更强的分布级对齐保证,提升了跨域鲁棒性。
🔬 细节详述
- 训练数据:使用了四个公开的多域蚊子音频数据集组合而成的新数据集。
- D1 (HumBugDB):坦桑尼亚录制,7种蚊子,37688片段,约20.94小时。
- D2 (Kasetsart):泰国录制,1种蚊子(Ae. albopictus),655片段,约0.37小时。
- D3 (UFRGS):巴西录制,2种蚊子(Ae. aegypti, Ae. albopictus),16727片段,约9.30小时。
- D4 (Abuzz):美国录制,4种蚊子,5054片段,约2.81小时。
- 总时长33.42小时,划分为训练(23.46h)、验证(4.26h)、测试(5.70h)。
- 预处理:将原始音频转换为64-bank对数梅尔能量特征。
- 数据增强:论文中未提及使用特定数据增强方法。
- 损失函数:五个损失函数及其默认权重
λi均为1。具体定义见公式(1)至(9)。对比学习温度项τ默认为0.01。MMD使用RBF核。 - 训练策略:
- 优化器:AdamW。
- 学习率:0.0005。
- 批大小:64。
- 轮数:最大500 epochs。
- 早停:在50个epoch后,如果验证集准确率连续10个epoch未提升则停止。
- 正则化:使用了Dropout和归一化(批归一化)。
- 关键超参数:编码器为4块VGG-like CNN。嵌入层维度:物种嵌入512,域嵌入256。分类层维度由物种数
Ns和域数Nd决定。 - 训练硬件:论文中未提及训练使用的GPU型号、数量及具体训练时长。
- 推理细节:论文中未提及解码策略、温度、beam size等。推理时使用训练好的模型直接进行前向传播得到分类结果。
- 正则化或稳定训练技巧:使用了Dropout、批归一化和早停。
📊 实验结果
表1:CNN在Ae. albopictus上的测试准确率(带与不带域特征考虑)
| 训练集来源 | 测试集来源 | CNN | DR-BioL CNN |
|---|---|---|---|
| D1 + D2 | D1 + D2 | 99.79% | 92.81% |
| D1 + D2 | D3 | 41.40% | 74.92% |
| 结论:普通CNN在跨域(新域D3)测试时性能骤降,而DR-BioL CNN虽然在同分布测试时性能略低,但跨域性能显著更优,验证了其鲁棒性。 |
表2:DR-BioL在验证集上的消融实验
| # | LScL | LScoL | LSdaL | LDcL | LDicL | 准确率(%) | AP |
|---|---|---|---|---|---|---|---|
| 1 | ✓ | ✓ | ✓ | ✓ | ✓ | 82.189 ± 0.215 | 0.884 ± 0.001 |
| 2 | ✓ | ✗ | ✓ | ✓ | ✓ | 81.253 ± 0.639 | 0.881 ± 0.004 |
| 3 | ✓ | ✗ | ✗ | ✓ | ✓ | 80.571 ± 0.453 | 0.873 ± 0.003 |
| 4 | ✓ | ✓ | ✓ | ✗ | ✓ | 81.731 ± 0.372 | 0.883 ± 0.006 |
| 5 | ✓ | ✓ | ✓ | ✗ | ✗ | 82.683 ± 1.183 | 0.887 ± 0.013 |
| 结论:移除物种相关损失(#2, #3)导致性能下降;移除域相关损失(#5)性能反而提升,表明模型利用了域特征。 |
表3:不同损失权重λi对验证集的影响
| # | λ1 | λ2 | λ3 | λ4 | λ5 | 准确率(%) | AP |
|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 1 | 1 | 1 | 82.189 ± 0.215 | 0.884 ± 0.001 |
| 2 | 1 | 1 | 1 | 0.01 | 1 | 83.902 ± 0.302 | 0.891 ± 0.006 |
| 3 | 1 | 1 | 1 | 0.01 | 0.1 | 84.644 ± 0.305 | 0.904 ± 0.007 |
| 4 | 1 | 0.1 | 1 | 0.01 | 0.1 | 84.271 ± 0.342 | 0.893 ± 0.009 |
结论:通过调整损失权重(特别是降低λ4和λ5),可以进一步提升性能。#3组合在准确率和AP上达到最优。 |
表4:MSC模型在测试集上的比较
| # | 模型 | 参数(M) | FLOPs(G) | 准确率(%) | AUC | AP |
|---|---|---|---|---|---|---|
| 1 | Baseline CNN | 4.9530 | 2.6152 | 80.031 | 0.9680 | 0.8616 |
| 2 | YAMNet | 3.2147 | 0.0052 | 77.360 | 0.9591 | 0.8332 |
| 3 | MobileNetV2 | 2.2335 | 0.0738 | 76.307 | 0.9543 | 0.8206 |
| 4 | PANNs | 79.6902 | 3.9787 | 81.679 | 0.9653 | 0.8511 |
| 5 | DAT CNN | 5.0854 | 2.6155 | 79.583 | 0.9607 | 0.8481 |
| 6 | DR-BioL | 5.0854 | 2.6155 | 85.345 | 0.9732 | 0.9002 |
| 结论:DR-BioL在准确率、AUC和AP上全面超越了其他模型,包括轻量级模型、预训练大模型以及同样旨在解决域偏移的DAT方法,且计算开销与DAT相同。 |
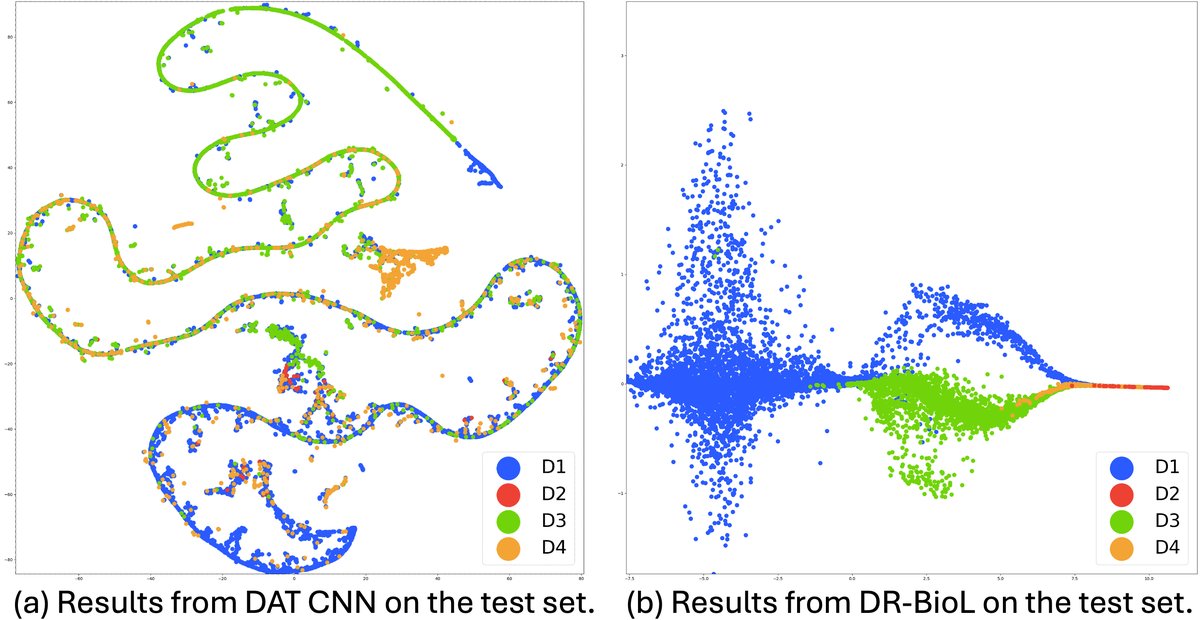 图4展示了DAT (a) 和 DR-BioL (b) 学习到的域嵌入的t-SNE可视化。图(a)中DAT的嵌入被混淆成一条混合曲线;图(b)中DR-BioL的嵌入虽然跨域(D2, D4向D1, D3连线收敛)但保留了部分结构,表明其学习到了更平衡的表示,既减少了域差异,又保留了一定信息。
图4展示了DAT (a) 和 DR-BioL (b) 学习到的域嵌入的t-SNE可视化。图(a)中DAT的嵌入被混淆成一条混合曲线;图(b)中DR-BioL的嵌入虽然跨域(D2, D4向D1, D3连线收敛)但保留了部分结构,表明其学习到了更平衡的表示,既减少了域差异,又保留了一定信息。
⚖️ 评分理由
- 学术质量:6.0/7。论文工作扎实,问题定义明确,针对蚊子声学数据的具体挑战提出了一个合理且有效的多损失函数框架。实验设计相对完整,包括了与多种基线(包括域适应方法DAT)的对比和详尽的消融实验。主要扣分点在于:核心方法创新是现有技术(对比学习、MMD)的组合与适配,原创性有限;实验设计中存在已知的域重叠妥协,影响了结论的绝对严格性。
- 选题价值:1.0/2。研究针对的是生物声学中的一个具体应用(蚊子分类)及其关键技术瓶颈(域偏移),具有明确的实际应用导向(公共卫生监测),在垂直领域内有价值。但在更广泛的音频/语音研究社区中,该任务的知名度和影响力相对较小。
- 开源与复现加成:0.5/1。论文明确提供了代码仓库链接(https://github.com/Yuanbo2020/DR-BioL),并在文中给出了关键的训练配置(优化器、学习率、早停)和模型架构细节,为复现提供了必要信息。但未提供训练好的模型权重、具体的训练硬件与时间、超参搜索的详细过程,因此复现便利性未达满分。