📄 Language-Infused Retrieval-Augmented CTC with Adaptive Soft-Hard Gating for Robust Code-Switching ASR
#语音识别 #检索增强 #端到端 #零样本 #多语言
🔥 8.0/10 | 前25% | #语音识别 | #检索增强 | #端到端 #零样本
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.2 | 置信度 高
👥 作者与机构
- 第一作者:Zhichao Liang(香港中文大学(深圳)数据科学学院)
- 通讯作者:Satoshi Nakamura*(香港中文大学(深圳)数据科学学院与人工智能学院)
- 作者列表:Zhichao Liang(香港中文大学(深圳)数据科学学院)、Satoshi Nakamura(香港中文大学(深圳)数据科学学院与人工智能学院)
💡 毒舌点评
该工作巧妙地将语言后验信息“注入”kNN检索的查询空间,使检索过程本身具有语言意识,这是一个非常直观且有效的改进点。然而,实验仅局限于中英代码切换场景,且与更强或更新的基线(如基于大模型的零样本方法)对比不足,削弱了结论的普适性和说服力。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开权重。
- 数据集:使用的是公开的ASCEND数据集,但未提供获取方式链接(论文中引用了原始数据集论文)。
- Demo:未提供在线演示。
- 复现材料:提供了部分实现细节(如使用WeNet和FAISS,关键超参数值),但不足以保证完整复现。
- 论文中引用的开源项目:WeNet [22], FAISS [24], Conformer [23](作为基线模型), Whisper [16](在引言中提及)。
📌 核心摘要
- 解决的问题:针对代码切换自动语音识别中语言边界模糊和跨语言声学干扰的挑战,特别是现有门控检索增强CTC模型(如双单语数据存储)存在的边界决策不稳定和语言意识不足的问题。
- 方法核心:提出LIRA-CTC框架,通过将帧级语言后验概率与编码器特征拼接,形成“语言信息注入”的检索查询,使检索空间与语言身份对齐;并设计自适应软硬门控策略,在数据存储距离差大时硬选择,在距离差小时软插值。
- 与已有方法的创新:不同于先前仅使用编码器特征进行检索或在解码器端使用语言信息的方法,该工作将语言后验直接融入检索的“键/查询”构造中,并引入了平滑过渡的软硬混合门控机制。
- 主要实验结果:在ASCEND中文-英文数据集上的实验表明,LIRA-CTC相较于基线Conformer、kNN-CTC和门控kNN-CTC,在官方测试集(TEST)和混合训练集(SMIX)上均取得了更低的混合错误率(MER)。关键数据见下表:
方法 TEST MER (%) SMIX MER (%) RTF CTC 26.10 28.77 0.0139 kNN-CTC 25.49 27.24 0.0145 Gated kNN-CTC 24.97 26.33 0.0152 LIRA-CTC 23.60 24.98 0.0155 - 实际意义:为零样本代码切换ASR提供了一种有效且计算开销增加有限的新框架,通过增强检索过程的语言感知能力和决策稳定性,提升了模型对混合语言语音的识别鲁棒性。
- 主要局限性:实验仅验证于中英代码切换场景,其有效性是否能扩展至其他语言对或更复杂的多语言场景有待证明;与当前前沿的零样本ASR方法(如基于大型预训练模型的方法)对比不足。
🏗️ 模型架构
整体架构基于预训练的CTC ASR模型(Conformer编码器+Transformer解码器),核心扩展在于检索增强解码部分。
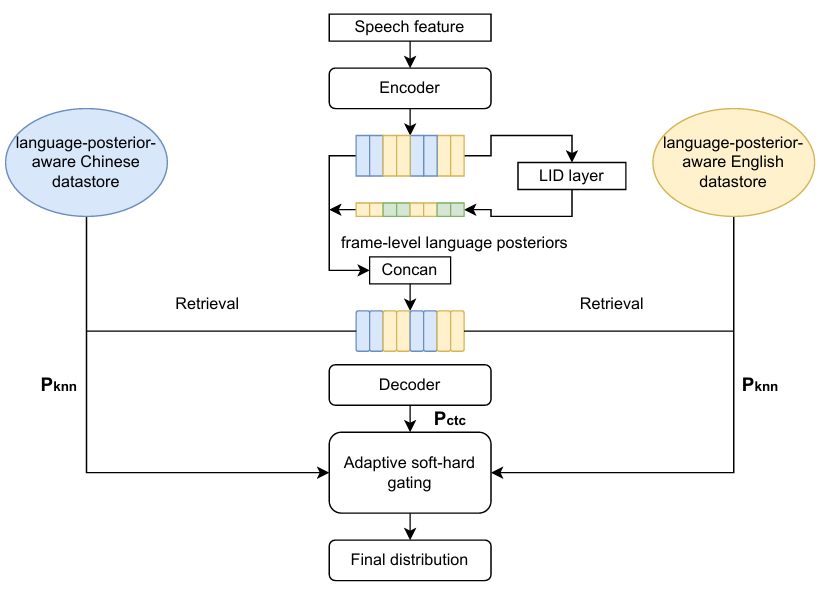 图1:LIRA-CTC框架概述
图1:LIRA-CTC框架概述
- 输入与特征提取:音频输入经过Conformer编码器,产生帧级隐藏表示
f(X)。 - 语言后验生成:一个辅助的语言识别模块为每个帧生成中文/英文的后验概率向量
p。 - 语言信息注入查询:将编码器特征
f(x)与语言后验p拼接,形成增强的查询表示f'(x) = concat(f(x), p)。同样,构建数据存储的“键”也使用f'(X)。 - 双单语数据存储:分别从中文(SCN)和英文(SEN)单语训练集中构建数据存储
D_CN和D_EN,每个存储包含键值对(f'(X), Ŷ)。 - 自适应软硬门控:
- 对于查询
f'(x),计算其与中文和英文数据存储中top-n邻居的平均距离d_CN和d_EN。 - 计算相对距离差
Δrel。当|Δrel|大于阈值(0.10)时,进行硬选择(选择平均距离更小的数据存储);当|Δrel|较小时,通过sigmoid函数计算权重α,对两个数据存储的检索分布进行软插值。 - 根据门控选择,还会对非目标语言的分布进行降权(乘以
1/t),以强化语言区分。
- 对于查询
- 检索与预测:使用增强查询在选定的数据存储(或插值的分布)中进行kNN检索,得到
P_kNN(y|x)。最终预测P(y|x)是CTC分数和kNN检索分数的加权插值。
💡 核心创新点
语言信息注入的检索查询:
- 局限:传统kNN-CTC仅依赖声学特征进行检索,在声学相似但语言不同的区域易混淆。
- 如何起作用:将帧级语言后验概率与编码器特征拼接,使检索查询在向量空间中包含了明确的语言身份信息,从而引导检索到语言一致的邻居。
- 收益:减少了跨语言检索干扰,消融实验显示单独使用此方法即可降低MER(在TEST集上从24.97%降至23.92%)。
自适应软硬门控机制:
- 局限:先前的二元硬门控在语言边界附近(两种语言距离相似时)决策不稳定,导致“抖动”。
- 如何起作用:引入基于相对距离差的混合策略。在语言归属明确时(距离差大)采用硬切换以保持纯净性;在模糊地带(距离差小)进行概率插值以实现平滑过渡。
- 收益:稳定了语言边界附近的解码过程,与语言注入查询结合使用效果最佳(完整LIRA-CTC MER最低)。
对交替语言分布的调整:
- 当门控选择某一语言时,通过参数
t降低非目标语言检索分布的概率质量,进一步抑制干扰。
- 当门控选择某一语言时,通过参数
🔬 细节详述
- 训练数据:使用ASCEND语料库。仅使用中文单语子集SCN(4799句)和英文单语子集SEN(2331句)对预训练模型进行微调,并构建单语数据存储。混合子集SMIX和测试集TEST仅用于评估。
- 损失函数:论文中未明确说明微调阶段使用的损失函数,但基于CTC框架,推测为标准CTC损失。
- 训练策略:使用WeNet工具包。学习率为5e-5,批大小为16,warmup步数为5000。优化器等细节未提供。
- 关键超参数:Conformer编码器层数:12;Transformer解码器层数:6。kNN检索邻居数 k=1024。门控计算使用top-n邻居平均距离,n=300。相对距离差阈值 |Δrel|=0.10。门控sigmoid缩放因子 β=5.0。交替语言调整因子 t=5.0。CTC与kNN插值权重:α_kNN=0.3,α_CTC=0.7。
- 训练硬件:未说明。
- 推理细节:使用CTC贪婪搜索解码。检索过程使用FAISS库实现。
- 正则化或稳定训练技巧:未提及额外的正则化技巧。
📊 实验结果
主要Benchmark与结果:在ASCEND数据集的TEST和SMIX子集上进行评估,指标为混合错误率(MER)。LIRA-CTC在两个集合上均取得最优,见核心摘要中的表格。
与最强基线对比:相对于消融实验中“仅使用语言信息注入查询”的版本,完整LIRA-CTC在TEST集上MER从23.92%降至23.60%,在SMIX集上从25.47%降至24.98%,证明了两个组件的互补性。
消融实验:详细结果见下表。
方法 TEST MER (%) SMIX MER (%) + 仅语言信息注入查询 23.92 25.47 + 仅自适应软硬门控 24.45 26.01 + 两者结合 (完整LIRA-CTC) 23.60 24.98 参数敏感性分析:论文提到对k、α_m和门控阈值进行了扫描,结论是性能在k=1024附近稳定,α_kNN在[0.20, 0.40]范围内表现良好。
⚖️ 评分理由
- 学术质量:6.5/7。论文提出了清晰的技术创新(语言信息注入、自适应门控),并在一个具体问题(零样本CS-ASR)上进行了验证。实验设计包含必要的基线对比和消融分析,结果支持其主张。但创新程度为增量式而非颠覆式,且实验范围有限(仅中英、单一数据集、未对比最新方法),降低了普遍影响力。
- 选题价值:1.5/2。代码切换ASR是多语言社会的现实需求,零样本方法能降低数据标注成本,具有明确的应用价值和前沿性。
- 开源与复现加成:0.2/1。论文提供了核心超参数和实现工具(WeNet, FAISS),便于理解方法。但未提供代码、模型权重、详细训练配置或复现脚本,使得完全复现存在障碍。