📄 Keeping Models Listening: Segment- and time-aware attention rescaling at decoding time
#音频问答 #音频分类 #音频大模型 #推理时调整
✅ 7.5/10 | 前25% | #音频问答 | #推理时调整 | #音频分类 #音频大模型
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Hangyu Du(新加坡国立大学,设计与工程学院)
- 通讯作者:Jingxing Zhong(福州大学,明智国际工程学院)
- 作者列表:Hangyu Du(新加坡国立大学,设计与工程学院),Jingxing Zhong(福州大学,明智国际工程学院)(论文注明两位作者贡献相等)。
💡 毒舌点评
亮点:精准地诊断出ALLMs解码时“听着听着就忘了音频”的顽疾,并用一个免训练、近乎零开销的“解码时注意力微调”插件(AttnAdapter)显著缓解了这个问题,效果立竿见影,实用性很强。 短板:方法更像是对症下药的“经验性工程”,虽然能“work”,但对于注意力漂移的根本原因(为何系统令牌会成为sink?为何音频注意力会衰减?)缺乏更深层次的理论或神经机制层面的剖析,略显“知其然而不知其所以然”。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:实验使用公开的MMAU-mini和AIR-Bench数据集,但论文中未提及数据集获取方式或自有数据。
- Demo:未提及。
- 复现材料:提供了Algorithm 1伪代码和完整的超参数设置,足以复现核心方法。但缺乏具体代码实现和运行脚本。
- 引用的开源项目:论文未提及直接依赖的开源项目代码。
📌 核心摘要
- 要解决什么问题:本文发现并研究了音频大语言模型(ALLMs)在自回归解码过程中普遍存在的“注意力路由退化”现象。随着解码进行,模型对音频输入(Audio Tokens)的注意力会系统性衰减,转而过度依赖语言先验和早期生成的“汇聚”令牌,导致回答偏离输入音频,产生幻觉。
- 方法核心是什么:提出AttnAdapter,一个训练无关、可插拔的模块。它在解码的每一步,对注意力计算中的原始对数几率(logits)进行分段、时间感知的乘性重缩放。具体包含三个组件:(1) 系统令牌汇聚抑制,(2) 音频关键点时序增强,(3) 局部输出窗口稳定。
- 与已有方法相比新在哪里:与现有方法(如EAH、MemVR)相比,AttnAdapter的特点是:完全在解码时操作,无需训练或修改模型架构;设计上明确针对音频模态的序列性、密集性特点,提出时间感知的增强策略;并且组合了多种干预(抑制、增强、稳定)以协同工作。
- 主要实验结果如何:在MMAU-mini和AIR-Bench两个基准上,AttnAdapter为LLaMa-Omni、Qwen-Omni和Audio Flamingo 3三个模型带来了稳定的性能提升。
- 在LLaMa-Omni上,MMAU-mini平均准确率从0.71提升至0.85(+14%),AIR-Bench平均准确率从0.69提升至0.82(+13%)。
- 在Qwen-Omni上,MMAU-mini平均准确率从0.73提升至0.87(+14%),AIR-Bench平均准确率从0.71提升至0.84(+13%)。
- 在Audio Flamingo 3上,MMAU-mini平均准确率从0.73提升至0.87(+14%),AIR-Bench平均准确率从0.70提升至0.83(+13%)。
- 所有方法中,AttnAdapter均取得了最高的分数,尤其在“混合音频”子任务上改进明显。
- 实际意义是什么:提供了一个即插即用、计算开销极低(延迟增加<2%)的解决方案,可以增强现有ALLMs的音频接地能力,使其在长序列对话和推理中能持续“听”音频,减少基于文本先验的幻觉,提升在音频问答、分析等实际应用中的可靠性和准确性。
- 主要局限性是什么:(1) 方法的有效性依赖于经验调优的超参数(σ, η, g, w, β),对于新模型或任务可能需要重新搜索。(2) 论文主要关注准确率提升,对模型生成文本的流畅性、连贯性等质量指标的详细分析不足。(3) 机制解释偏经验性,缺乏对ALLMs内部信息流动的深层理论分析。
🏗️ 模型架构
本文提出的AttnAdapter并非一个完整的端到端模型,而是一个推理时的插件模块,旨在修改现有基于解码器的音频大语言模型(ALLMs)在解码阶段的注意力计算过程。
整体流程:
- 输入:给定一个ALLM,其解码器的某一层在自回归解码的某一步,接收查询向量 Q,键向量 K,值向量 V 以及注意力掩码 M。输入序列 x 由系统令牌(S)、音频令牌(A)和文本令牌(O)组成。
- AttnAdapter干预:在计算标准注意力分数
L = QK^T/√d_h之后、应用softmax之前,AttnAdapter对L进行乘性重缩放,得到ẽL。重缩放由三个独立的因子矩阵s(S),s(A),s(W)决定,它们分别针对序列中的不同片段(S, A, O)进行操作。 - 输出:重缩放后的注意力分数
ẽL与掩码M相加,再经softmax得到注意力权重 A,最终计算出上下文向量H_final = AV,供后续层使用。
AttnAdapter内部组件:
- Sink Suppression (
s(S)):将系统令牌 S 对应的列(所有查询行关注第1个键位置)的对数几率乘以一个衰减因子 σ (0<σ≤1),以抑制该“汇聚点”。 - Time-Aware Audio Ramp (
s(A)):为音频令牌块 A(第2到第1+N_a个键位置)的对数几率提供一个随解码步数 c 增加而平滑增长的增强因子r(c)。r(c)从1开始,渐近线为 η ≥1。此因子仅作用于非音频的查询行(q > 1+N_a),确保增强的是文本/输出对音频的关注。 - Local Output Stabilization (
s(W)):对当前解码步 i 的查询行,轻微增强其对最近 w 个生成的输出令牌(属于O集合)的注意力,增强幅度为 (1+β),以提升生成流畅性。
与已有架构的关系:AttnAdapter不改变原模型的架构、位置编码(RoPE)、掩码机制、KV缓存更新逻辑,也不改变计算复杂度。它被设计为一个即插即用的模块,可以在推理时启用。
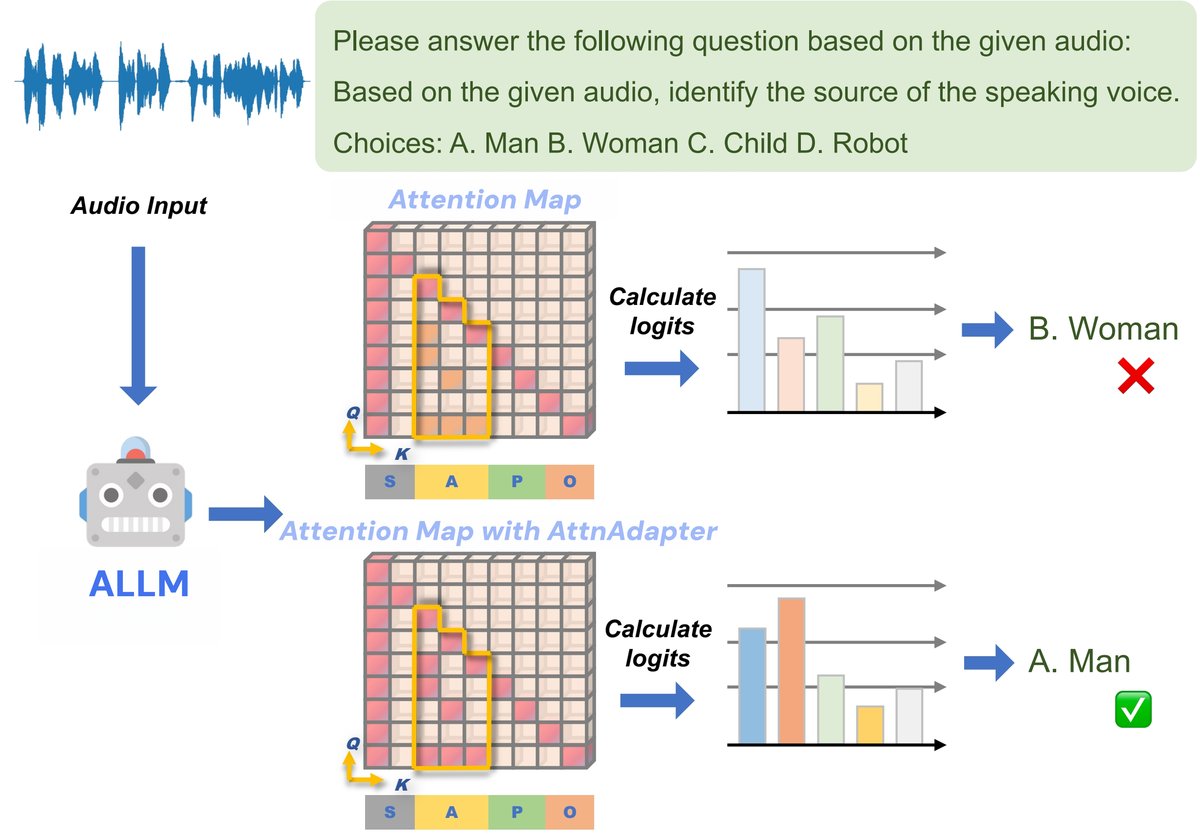 图1 展示了ALLMs推理过程及注意力漂移现象。左侧是模型输入序列(系统、音频、文本令牌),右侧是解码生成的文本。图中示意了解码过程中,注意力(红色箭头)从音频块逐渐减弱并偏向已生成的文本令牌,导致回答可能与音频输入脱节。AttnAdapter(下方插图)则试图通过重缩放注意力来缓解这一问题。
图1 展示了ALLMs推理过程及注意力漂移现象。左侧是模型输入序列(系统、音频、文本令牌),右侧是解码生成的文本。图中示意了解码过程中,注意力(红色箭头)从音频块逐渐减弱并偏向已生成的文本令牌,导致回答可能与音频输入脱节。AttnAdapter(下方插图)则试图通过重缩放注意力来缓解这一问题。
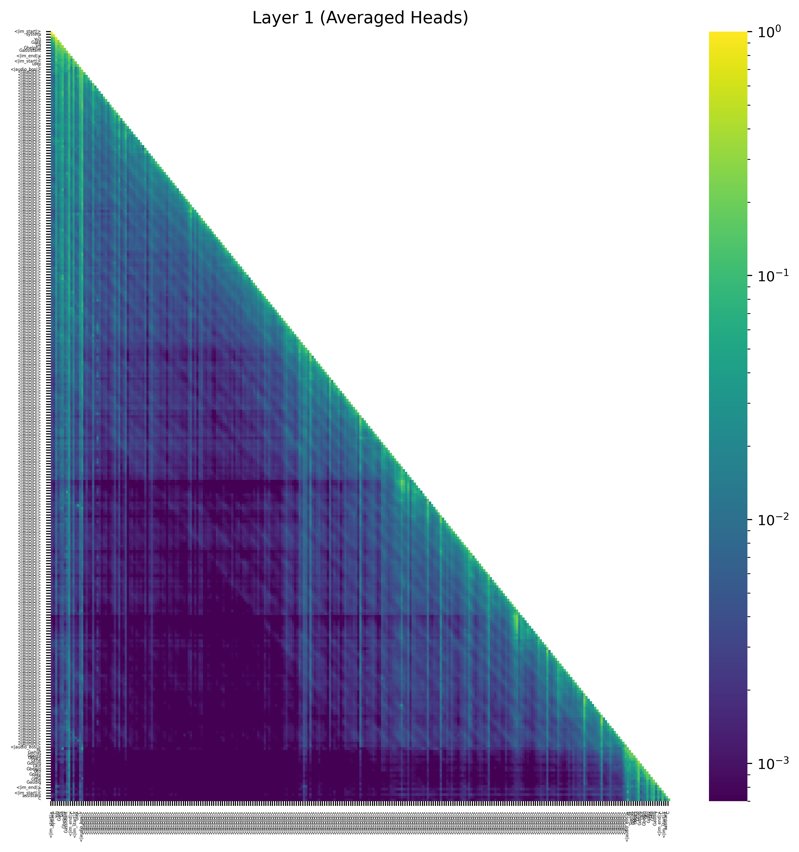 图2 展示了注意力路由退化现象。图示了在解码器的早期、中期和晚期层中,查询对不同键段(S:系统, A:音频, P:提示/生成文本)的注意力分布。可以清晰看到,随着层加深,对音频块A的注意力明显减弱,而对文本块P的注意力增强。
图2 展示了注意力路由退化现象。图示了在解码器的早期、中期和晚期层中,查询对不同键段(S:系统, A:音频, P:提示/生成文本)的注意力分布。可以清晰看到,随着层加深,对音频块A的注意力明显减弱,而对文本块P的注意力增强。
💡 核心创新点
- 首次系统分析ALLMs中的注意力路由退化:本文明确识别并可视化了在音频大语言模型解码过程中,注意力从音频令牌向语言先验和早期令牌“漂移”的系统性问题,揭示了ALLMs的一个关键可靠性短板。
- 提出分段感知、时间感知的解码时注意力重缩放机制:AttnAdapter是第一个专门针对音频模态特性设计的解码时干预方法。其创新性体现在将干预分解为三个功能明确、协同工作的模块(抑制、增强、稳定),并设计了随时间变化的增强策略以对抗衰减。
- 训练无关(Training-free)且即插即用的实现:方法完全在推理时生效,无需对模型进行任何再训练或微调,也不改变模型结构,极大降低了应用门槛,可直接用于提升现有模型的性能。
🔬 细节详述
- 训练数据:论文中未提及AttnAdapter自身的训练数据,因为它是一个训练无关的模块。实验所用的基础模型(LLaMa-Omni等)的训练数据信息未在本文提供。
- 损失函数:未说明,因为AttnAdapter不涉及训练。
- 训练策略:未说明,因为AttnAdapter不涉及训练。
- 关键超参数:
- AttnAdapter超参数:σ (系统令牌抑制强度), η (音频最大增强倍数), g (时间增长率), w (局部稳定窗口大小), β (窗口增强强度)。
- 为三个模型设置了不同超参数:LLaMa-Omni (σ=0.35, η=1.7, g=0.05, w=32, β=0.15); Qwen-Omni (0.25, 1.9, 0.04, 48, 0.20); AF3 (0.25, 1.9, 0.031, 64, 0.20)。
- 解码计数器 c = max(0, i − (1+N_a+M)),其中 i 是当前查询索引, N_a 是音频令牌数, M 是文本提示长度。
- 训练硬件:未说明基础模型的训练硬件。AttnAdapter的评估在单个NVIDIA A100 80GB GPU上进行。
- 推理细节:
- 解码策略:论文未明确说明,但基于其任务(分类、生成)和基准(MMAU-mini, AIR-Bench),推测为标准的贪心解码或类似策略。
- AttnAdapter延迟开销:增加平均解码延迟小于2%。
- 正则化或稳定训练技巧:不适用,因为AttnAdapter不参与训练。
📊 实验结果
本文在两个主流音频-语言理解基准上进行了评估,主要指标为分类准确率。
主要对比实验结果:
| 方法 | 模型骨干 | MMAU-mini (Sound/Music/Speech/Avg.) | AIR-Bench (Sound/Music/Speech/Mixed/Avg.) |
|---|---|---|---|
| LLaMa-Omni (基线) | LLaMa-Omni | 0.68/0.71/0.75/0.71 | 0.65/0.69/0.73/0.70/0.69 |
| + EAH | LLaMa-Omni | 0.75/0.77/0.79/0.77 | 0.71/0.74/0.77/0.73/0.74 |
| + MemVR | LLaMa-Omni | 0.78/0.80/0.82/0.80 | 0.74/0.77/0.80/0.76/0.77 |
| + AttnAdapter (Ours) | LLaMa-Omni | 0.83/0.85/0.87/0.85 | 0.79/0.82/0.85/0.81/0.82 |
| Qwen-Omni (基线) | Qwen-Omni | 0.70/0.73/0.76/0.73 | 0.67/0.70/0.74/0.71/0.71 |
| + EAH | Qwen-Omni | 0.77/0.79/0.81/0.79 | 0.73/0.76/0.79/0.75/0.76 |
| + MemVR | Qwen-Omni | 0.80/0.82/0.84/0.82 | 0.76/0.79/0.82/0.78/0.79 |
| + AttnAdapter (Ours) | Qwen-Omni | 0.85/0.87/0.89/0.87 | 0.81/0.84/0.87/0.83/0.84 |
| Audio Flamingo 3 (基线) | AF3 | 0.79/0.74/0.66/0.73 | 0.75/0.71/0.64/0.72/0.70 |
| + EAH | AF3 | 0.85/0.81/0.73/0.80 | 0.80/0.76/0.69/0.75/0.75 |
| + MemVR | AF3 | 0.86/0.83/0.77/0.82 | 0.84/0.79/0.72/0.78/0.78 |
| + AttnAdapter (Ours) | AF3 | 0.90/0.86/0.84/0.87 | 0.87/0.83/0.79/0.81/0.83 |
关键结论:
- 一致性提升:AttnAdapter在所有三个骨干模型和两个基准上均带来了显著的平均准确率提升(绝对值约+7%到+14%)。
- 超越现有方法:在相同的骨干模型上,AttnAdapter的性能一致优于EAH和MemVR这两种注意力调整方法,尤其在AIR-Bench的“混合音频”这一复杂子任务上提升明显。
- 全面性:提升覆盖了“声音”、“音乐”、“语音”以及“混合音频”等多个类别,证明了方法的普适性。
- 高效性:带来显著性能提升的同时,计算开销极低(延迟增加<2%)。
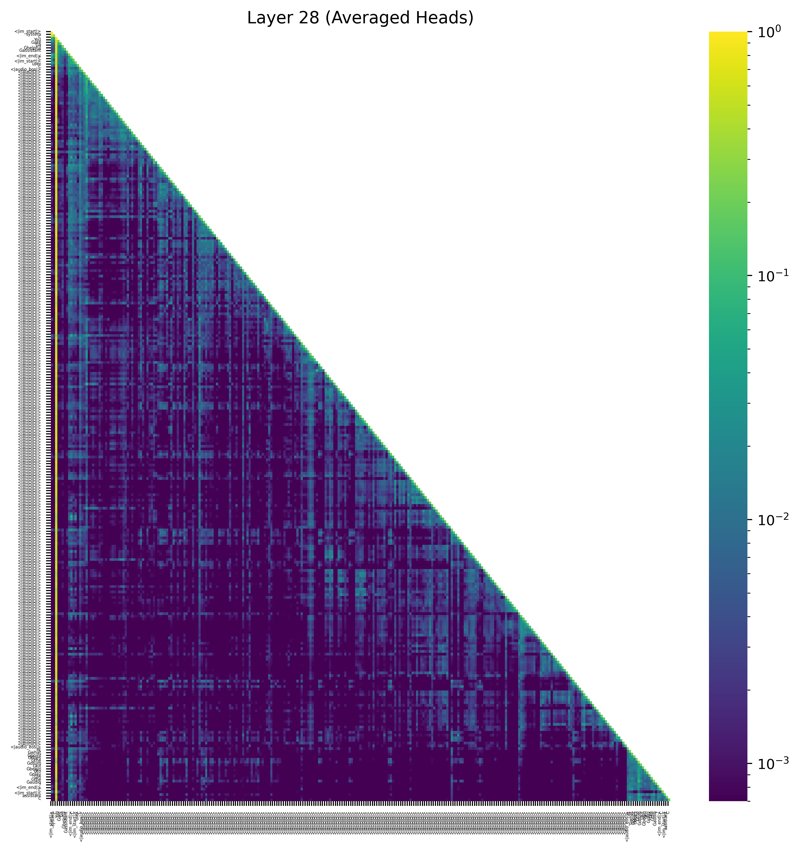 图3 展示了在有无AttnAdapter的情况下,解码某一步的注意力图对比。左侧“Original”图显示注意力集中在文本令牌上;右侧“Adapted”图显示应用AttnAdapter后,对音频令牌块的注意力被显著加强。
图3 展示了在有无AttnAdapter的情况下,解码某一步的注意力图对比。左侧“Original”图显示注意力集中在文本令牌上;右侧“Adapted”图显示应用AttnAdapter后,对音频令牌块的注意力被显著加强。
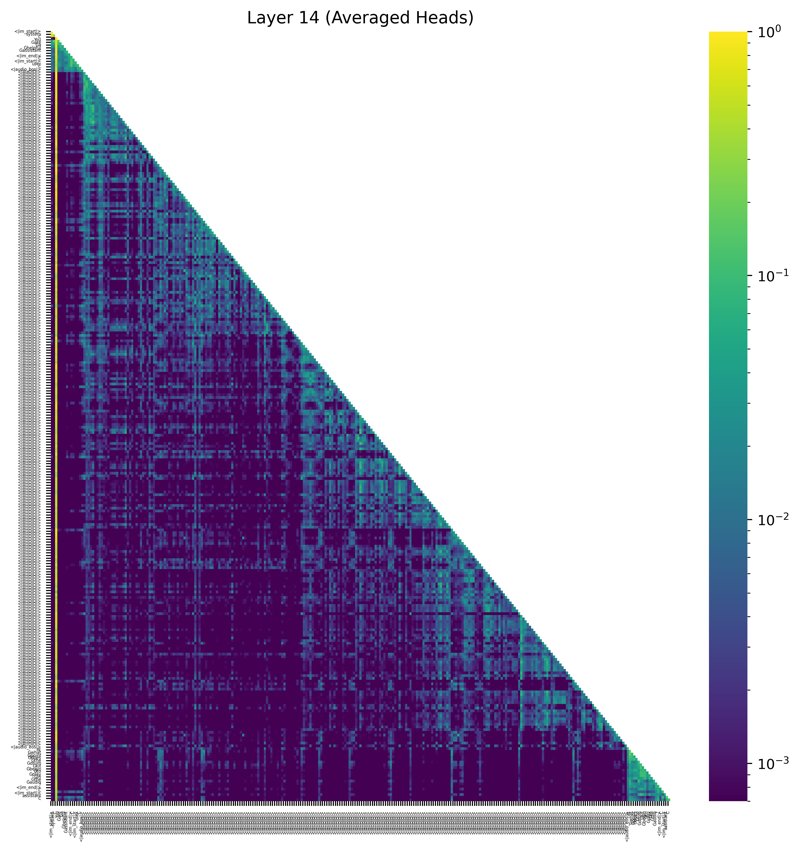 图4 进一步阐释了AttnAdapter的工作机制。当模型在解码过程中对下一步生成的内容不确定性较高时(图中紫色区域),AttnAdapter会增强对音频关键点的访问,帮助模型“重新聆听”以获得更准确的信息。
图4 进一步阐释了AttnAdapter的工作机制。当模型在解码过程中对下一步生成的内容不确定性较高时(图中紫色区域),AttnAdapter会增强对音频关键点的访问,帮助模型“重新聆听”以获得更准确的信息。
⚖️ 评分理由
学术质量(5.5/7):
- 创新性(2.0/3):提出了针对ALLMs音频接地问题的、结构化的解码时干预方案,具有明确的针对性和实用性。
- 技术正确性(2.0/2):方法设计逻辑清晰,数学公式定义准确,实验设置合理,结果可验证。
- 实验充分性(1.5/2):在多个模型、多个基准上进行了广泛对比实验,结果稳定。但消融实验和理论分析深度稍显不足。
选题价值(1.5/2):
- 前沿性(1.0/1):直击音频大模型实用化过程中的关键痛点(长序列接地可靠性),研究方向非常前沿。
- 应用与影响(0.5/1):方法可即插即用提升现有系统性能,对语音助手、音频内容分析等应用有直接价值。
开源与复现加成(0.5/1):论文公开了完整的算法伪代码和所有关键超参数,具备良好的可复现性基础,但未开源代码和模型,因此给予基础分0.5。