📄 KAN We Make Models Simpler for Audio Deepfake Detection with Kolmogorov–Arnold Networks?
#音频深度伪造检测 #自监督学习 #KAN
✅ 7.5/10 | 前25% | #音频深度伪造检测 | #自监督学习 | #KAN
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Hoan My Tran (Univ Rennes, CNRS, IRISA, Lannion, France)
- 通讯作者:David Guennec (Univ Rennes, CNRS, IRISA, Lannion, France), Aghilas Sini (Univ Le Mans, LIUM, Le Mans, France)
- 作者列表:Hoan My Tran†, Aghilas Sini∗, David Guennec†, Arnaud Delhay†, Damien Lolive‡, Pierre-François Marteau‡
- †: Univ Rennes, CNRS, IRISA, Lannion, France
- ∗: Univ Le Mans, LIUM, Le Mans, France
- ‡: Univ Bretagne Sud, CNRS, IRISA, Vannes, France
💡 毒舌点评
亮点:这篇论文的核心价值在于其“反常识”的结论——在强大的预训练模型(XLS-R)面前,复杂的下游分类器可能是不必要的,一个简单的全连接层(甚至只有2K参数)就能达到极具竞争力的性能,这为轻量化部署提供了重要思路。短板:虽然论文展示了KAN在平均EER上的优势,但其提升在部分数据集(如FoR)上并不一致,且论文缺乏对“为何KAN能更有效利用高维SSL特征”这一核心机制的深入理论或可视化分析,更像是一次成功的实验观察而非深刻的机理解释。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开的模型权重。
- 数据集:实验使用了多个公开的基准数据集(如ASVspoof系列),但未提及提供新的数据集。
- Demo:未提及。
- 复现材料:论文中给出了详细的训练超参数、数据增强方法、损失函数设置等复现所需的关键信息。
- 论文中引用的开源项目:引用了XLS-R、RawBoost等作为基础工具。
📌 核心摘要
这篇论文旨在探索一种极简化的音频深度伪造检测架构,以解决当前方法模型复杂、参数量大的问题。方法核心是利用强大的自监督学习模型XLS-R提取高维语音特征,并直接将其输入到一个简单的后端分类器(全连接层或KAN层)进行真伪判断,跳过了传统的降维步骤。与已有方法(如使用Conformer、Mamba等复杂后端)相比,本文的新颖之处在于证明了在特征足够强大时,极简后端即可取得优异性能。主要实验结果表明,在ASVspoof等多个数据集上,仅使用22.54K参数的KAN后端(平均EER为1.07%)能取得与使用数百万参数复杂模型相当甚至更优的性能(表3)。实际意义在于,该工作为构建轻量、高效、易于部署的音频深度伪造检测系统指明了方向。其主要局限性在于,尽管KAN在平均指标上占优,但在某些特定数据集(如FoR)上性能不及全连接层,且论文未能深入揭示KAN性能优势的内在原理。
🏗️ 模型架构
论文提出了一种极简的两阶段架构,整体流程清晰(如图1所示):
- 特征提取器:使用预训练的多语言自监督模型XLS-R。该模型包含一个7层的CNN特征编码器(将原始波形X映射为潜在特征Z)和一个24层的Transformer上下文网络(产生上下文化嵌入K ∈ R^{T × D})。其输出是经过时间平均池化后的固定维度向量
k̄ ∈ R^D,保留了完整的高维特征(论文中未明确D的具体值,但XLS-R通常为1024维)。 - 分类器:将池化后的向量
k̄直接送入一个简单的分类器j,该分类器可以是:- 全连接线性层(FC):一个标准的线性变换层。
- Kolmogorov-Arnold网络层(KAN):一种基于Kolmogorov-Arnold表示定理的新型网络层,其激活函数是可学习的样条函数(本文中使用FastKAN,即基于径向基函数的快速版本)。
分类器的输出是二分类的logits
y ∈ R^2,分别对应“真实(bona fide)”和“伪造(spoof)”。
关键设计选择与动机:该架构的核心创新在于避免了对SSL特征进行降维。作者认为传统的降维投影层(将维度从D降到d,d « D)可能会丢失对检测任务有用的判别信息。因此,他们提出直接利用完整的高维XLS-R特征,并用一个极度轻量化的后端进行分类,以验证“强大的特征+简单的分类器”这一范式的有效性。
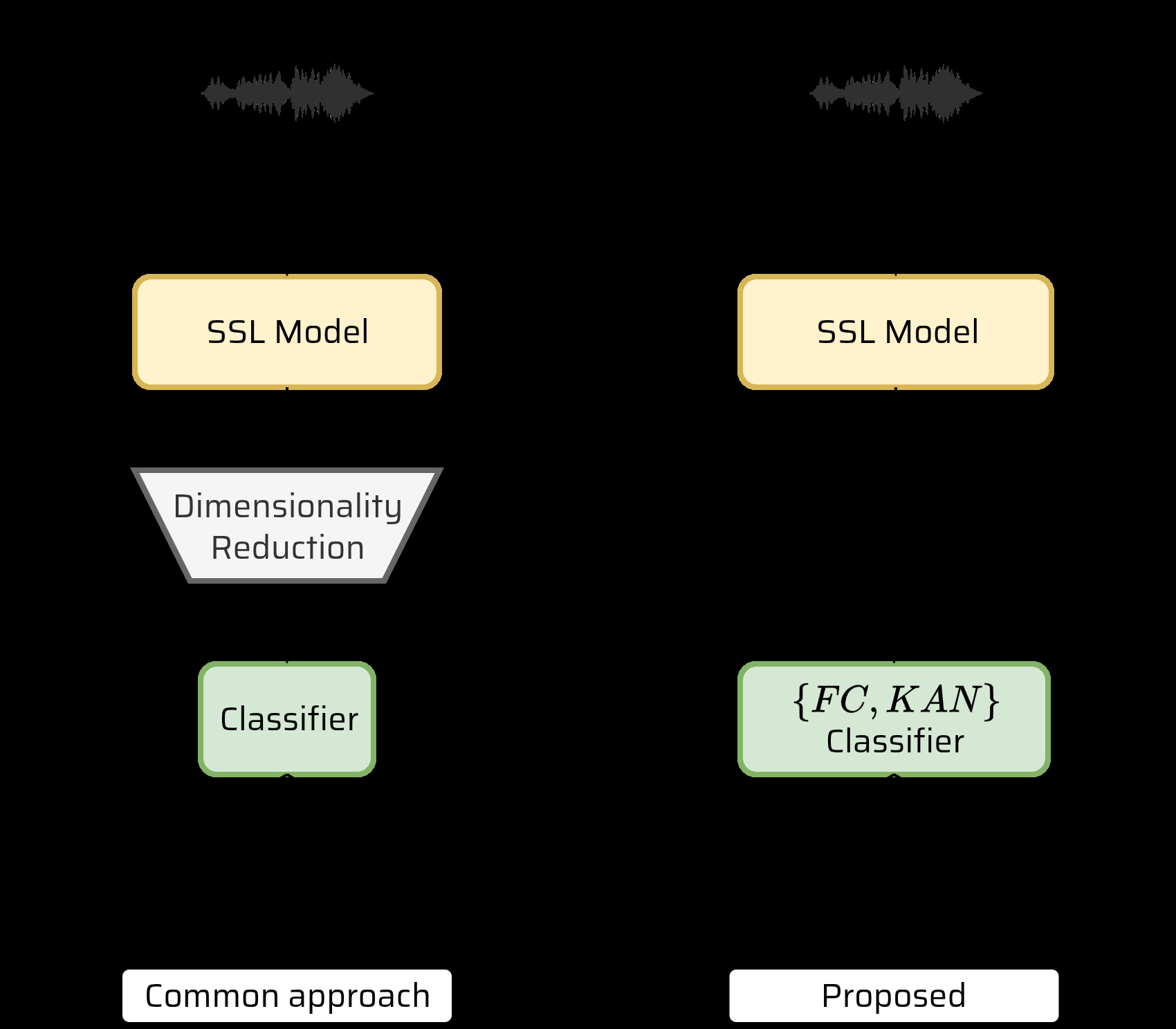 图1展示了论文提出的模型整体流程。左侧为XLS-R特征提取器,右侧为简单的分类器(FC或KAN)。输入为原始音频波形,经过XLS-R处理得到固定维度的嵌入向量,再直接送入分类器输出结果。该图直观地体现了架构的简洁性。
图1展示了论文提出的模型整体流程。左侧为XLS-R特征提取器,右侧为简单的分类器(FC或KAN)。输入为原始音频波形,经过XLS-R处理得到固定维度的嵌入向量,再直接送入分类器输出结果。该图直观地体现了架构的简洁性。
💡 核心创新点
- 极简化的下游架构设计:在音频深度伪造检测任务中,首次系统性地论证了在高维SSL特征之上,仅需一个单层的FC或KAN作为后端,即可达到与复杂后端(如Conformer、Mamba)相竞争的性能。这挑战了当前“特征提取+复杂分类器”的主流范式。
- 将KAN引入该任务并进行全面比较:在保留特征维度的前提下,将KAN作为一种轻量级、高表达能力的分类器与经典的FC层进行公平对比。实验表明,KAN在大多数情况下能取得更低的EER,证明了其在处理高维语音特征上的潜力。
- 通过极低参数量实现强泛化:论文提出的后端模型参数量极低(FC仅2.05K,KAN为22.54K),远低于表3中列出的所有SOTA系统(从447.24K到23.40M不等)。这证明了利用好预训练模型本身的能力,可以极大压缩下游模型的规模,有利于资源受限场景下的部署。
🔬 细节详述
- 训练数据:主要使用ASVspoof 2019 Logical Access (19LA) 训练集进行微调。采用了RawBoost数据增强方法,包括线性/非线性卷积噪声、脉冲信号相关噪声、平稳信号无关噪声和随机着色噪声。
- 损失函数:加权交叉熵损失(Weighted Cross-Entropy Loss)。为应对类别不平衡,对少数类(真实语音)赋予权重0.9,对多数类(伪造语音)赋予权重0.1。
- 训练策略:
- 优化器:Adam优化器。
- 学习率:2.5 × 10^{-6}。
- 权重衰减:1 × 10^{-4}。
- 批次大小:5。
- 训练轮数:采用早停法,耐心(patience)为3个epoch,基于19LA开发集上的最佳性能保存检查点。
- 关键超参数:
- 后端参数量:FC为2.05K,KAN为22.54K。
- 输入处理:训练时动态填充音频至批次内最长;评估时使用批次大小1,不进行填充。
- 训练硬件:所有实验在单块NVIDIA A100 GPU上完成。
- 推理细节:论文中未提及特殊的解码策略或流式处理设置。
- 正则化技巧:除数据增强和权重衰减外,未提及额外的正则化方法。
📊 实验结果
论文在多个数据集上进行了广泛的实验评估,主要指标为等错误率(EER%),结果汇总于表3中。本文模型的性能与表中的其他SOTA系统进行了直接对比。
域内分析 (ASVspoof 2021 LA评估集,表1)
模型类型 A07-A16 (TTS) 池化EER A17-A19 (VC) 池化EER 总体池化EER FC 1.09 1.20 2.38 KAN 0.49 1.08 1.07 结论:KAN在TTS类攻击上显著优于FC,将总体池化EER从2.38%降低至1.07%。 域内分析 (ASVspoof 2021 DF评估集,表2)
模型类型 Trad. Wav. N-AR N-nAR Unk. 总体池化EER FC 1.05 0.76 2.51 0.65 1.35 1.49 KAN 0.82 0.88 2.25 0.67 1.36 1.35 结论:KAN在传统和神经自回归攻击上优于FC,总体池化EER略优(1.35% vs. 1.49%)。 跨数据集综合对比 (表3) 下表列出了本文模型(XLS-R+FC和XLS-R+KAN)与部分SOTA系统在关键数据集上的EER(%)对比:
系统 (后端参数量) 19LA 21LA 21DF ITW FoR LibSeVoc DFADD MLAAD (M-EN) MLAAD (D-EN) XLS-R+Mamba (2.08M) 0.11 1.78 1.51 5.12 1.77 1.82 8.62 9.63 1.74 XLS-R+Nes2Net-X (512.04K) 0.12 2.17 1.49 7.74 5.12 3.49 11.25 10.70 1.61 XLS-R+FC (2.05K) 0.10 2.38 1.49 4.69 0.93 1.74 17.51 12.44 3.48 XLS-R+KAN (22.54K) 0.11 1.07 1.35 3.89 4.68 1.51 7.41 6.43 4.45 结论:在参数量极少的情况下,XLS-R+KAN在21LA, 21DF, ITW, LibSeVoc, DFADD等多个数据集上取得了最佳或接近最佳的性能,证明了其竞争力和泛化能力。
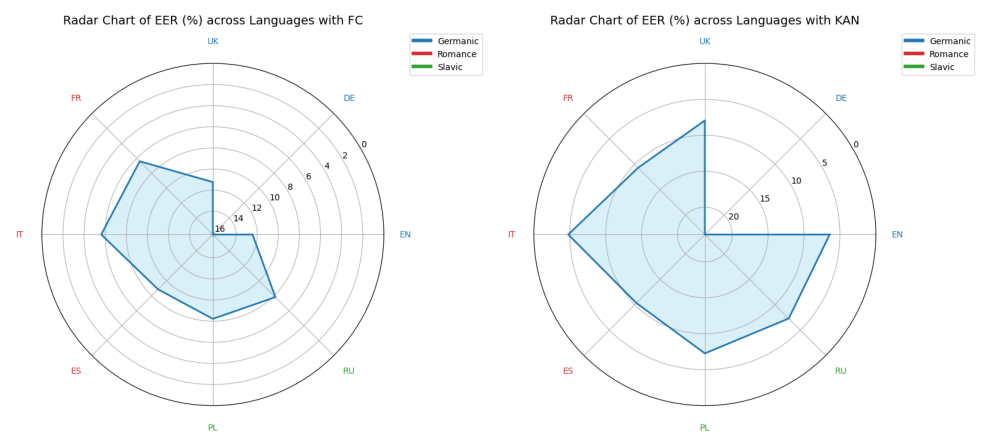 图2的雷达图展示了在MLAAD多语言数据集上,KAN(蓝色)相对于FC(橙色)在大多数语言(尤其是英语、意大利语)上的EER优势,直观地体现了KAN在跨语言泛化上的潜力。
图2的雷达图展示了在MLAAD多语言数据集上,KAN(蓝色)相对于FC(橙色)在大多数语言(尤其是英语、意大利语)上的EER优势,直观地体现了KAN在跨语言泛化上的潜力。
⚖️ 评分理由
- 学术质量:6.0/7 - 论文技术路线正确,实验设计严谨(涵盖域内、域外、多语言多数据集),数据翔实,对比充分(包括多个SOTA和消融实验)。创新性主要体现在架构设计的理念(极简后端)和对KAN的有效应用上,但非原理性突破。KAN的有效性缺乏更深层次的解释。
- 选题价值:1.5/2 - 音频深度伪造检测是当前语音安全领域的热点和刚需问题。本文提出的轻量化、高性能的解决方案具有明确的实际应用价值和部署吸引力,对相关从业者和研究者有较强参考意义。
- 开源与复现加成:0.0/1 - 论文提供了非常详细的实现细节(学习率、优化器、损失函数权重、数据增强方法等),这大大有助于复现。然而,论文中未提供代码仓库链接、预训练模型权重或最终检查点,因此无法给予复现加成。