📄 Joint Multichannel Acoustic Feedback Cancellation and Speaker Extraction via Kalman Filter and Deep Non-Linear Spatial Filter
#语音增强 #语音分离 #信号处理 #麦克风阵列 #多通道
✅ 7.0/10 | 前25% | #语音增强 | #信号处理 | #语音分离 #麦克风阵列
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Ze Li(南京大学现代声学研究所 & NJU-Horizon智能音频实验室,地平线机器人;南京大学)
- 通讯作者:未说明
- 作者列表:Ze Li(南京大学现代声学研究所 & NJU-Horizon智能音频实验室,地平线机器人;南京大学),Haocheng Guo(华为技术有限公司),Xiaoyang Ge(南京大学现代声学研究所 & NJU-Horizon智能音频实验室,地平线机器人),Kai Chen(南京大学现代声学研究所 & NJU-Horizon智能音频实验室,地平线机器人),Jing Lu(南京大学现代声学研究所 & NJU-Horizon智能音频实验室,地平线机器人)
💡 毒舌点评
亮点:该工作切中了公共广播和助听器系统中“反馈”与“干扰”两大痛点,提出的AFC-SPEX框架在系统设计上逻辑清晰,将经典卡尔曼滤波与深度空间滤波器巧妙结合,并通过教师强制策略有效解决了训练难题。短板:尽管仿真实验对比了众多基线,但结论的说服力止步于“在模拟环境中表现良好”;对于声学反馈这类严重依赖实际硬件与声场交互的问题,缺乏真实录音数据的验证是一个明显的遗憾,限制了其向实际产品转化的说服力。
🔗 开源详情
- 代码:论文中提供了代码仓库链接:
https://github.com/ZLiNJU/AFC-SPEX。 - 模型权重:论文中未提及公开预训练模型权重。
- 数据集:训练所用的仿真数据集未公开,但提供了仿真设置细节和使用的公开语音库(WSJ0)。
- Demo:论文中未提及在线演示。
- 复现材料:提供了论文中描述的主要超参数(帧长、帧移、分块数等)、仿真设置以及依赖的开源项目(
pyroomacoustics)。但缺乏完整的训练脚本、配置文件、训练日志及检查点。 - 论文中引用的开源项目:引用了
pyroomacoustics用于房间声学仿真,以及Rank2-MWF的开源实现。
📌 核心摘要
这篇论文旨在解决公共广播和助听器等系统中同时存在的声学反馈和干扰噪声问题。核心方法AFC-SPEX将分块频域卡尔曼滤波器(PBFDKF)作为自适应反馈消除模块,其输出的残差信号与原始麦克风信号一起输入到一个深度非线性空间滤波器(DNSF)中,后者通过LSTM网络学习时、频、空特征以估计复数理想比值掩膜,从而提取目标语音。与现有级联方案或单独使用深度网络的方法相比,该工作的主要创新在于联合优化与交互设计:DNSF不仅依赖原始信号,还利用AFC模块的输出作为辅助参考,以联合抑制反馈和干扰;同时,采用了针对闭环问题的教师强制训练策略。实验结果(在模拟的带反馈和干扰的房间声学环境中)表明,所提方法在SI-SDR、PESQ、STOI及最大稳定增益提升(ΔMSG)等多项指标上均优于直接级联、单独DNSF以及一种传统的多通道维纳滤波方法(Rank2-MWF)。例如,在同时存在反馈和干扰的场景(Simulation A)中,AFC-SPEX的SI-SDR达到4.38,优于AFC+DNSF的-1.78和Rank2-MWF的-26.00。该工作的实际意义在于为需要同时处理声学反馈和语音提取的音频系统提供了一种高性能的算法框架。其主要局限性是所有实验均基于仿真,未进行真实世界数据的验证。
🏗️ 模型架构
论文提出的AFC-SPEX系统架构如图1(a)所示。整体是一个针对“单扬声器、多麦克风”场景的闭环系统。
- 输入:M个麦克风信号
d_m(n),其中包含目标语音s_m(n)、干扰语音x_m(n)和来自扬声器的声学反馈信号y_m(n)。 - AFC模块(PBFDKF):每个通道
m独立运行一个分块频域卡尔曼滤波器。该模块的核心任务是估计反馈路径h_m(n)并从d_m(n)中减去估计的反馈信号ŷ_m(n),得到反馈补偿后的信号e_m(n)。PBFDKF以分块方式在频域更新,兼顾了低延迟和快速收敛。 - DNSF模块(深度非线性空间滤波器):这是系统的核心神经网络后端。其输入是4M通道的数据:由原始麦克风信号
D_m(k)的实部与虚部,以及AFC模块的补偿信号E_m(k)的实部与虚部拼接而成。这里,E_m(k)被用作辅助参考,帮助DNSF学习如何更干净地提取语音。DNSF的结构如图1(b)所示,包含:- 一个双向LSTM层(256个隐藏单元):处理频域序列(F)和空间通道(C),以捕捉空间-频谱依赖关系。
- 一个单向LSTM层(128个隐藏单元):沿时间维度(T)处理,保持时序因果性。
- 一个全连接层+Tanh激活:输出一个复数理想比值掩膜
F_s(k)。
- 输出与闭环:参考麦克风(0通道)的最终目标语音估计为
Ŝ_0(k) = F_s(k) ⊙ D_0(k)(⊙为哈达玛积)。这个估计值被放大(增益K)和延迟(Δt)后作为扬声器信号u(n)播放,重新进入声学环境,形成闭环。DNSF被设计为流式处理,每帧独立生成cIRM。
架构图:
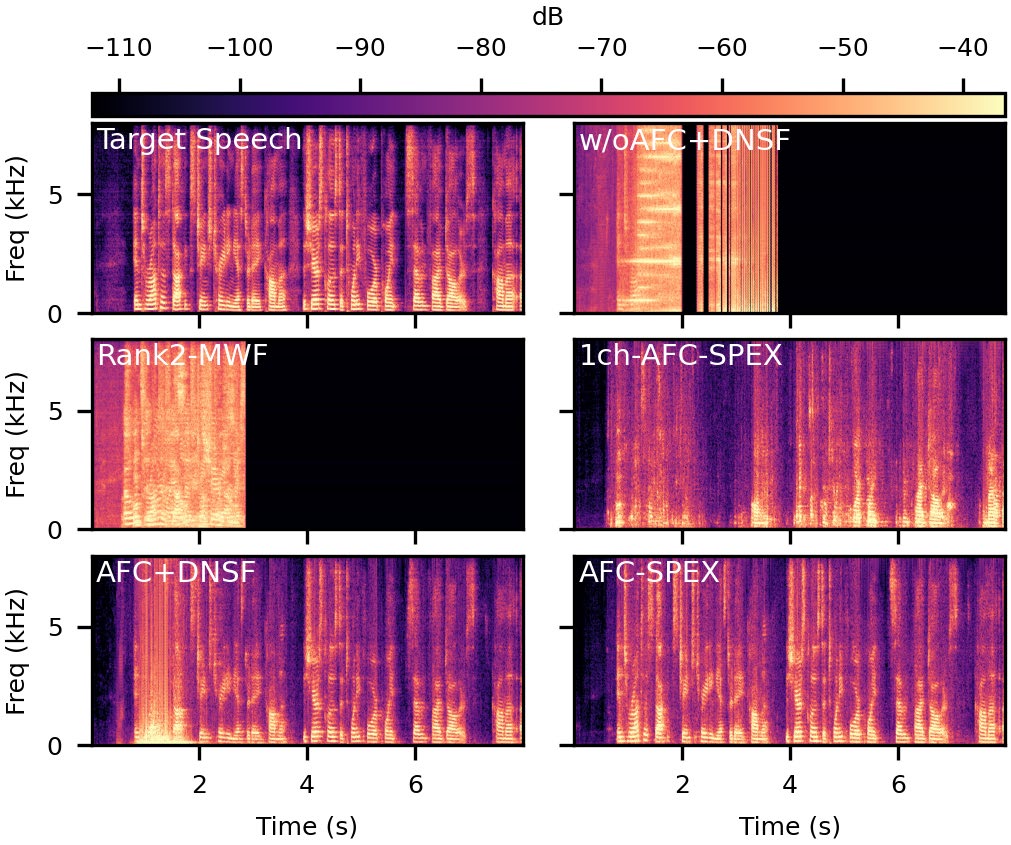 图1(a)展示了AFC-SPEX的完整信号流。
图1(a)展示了AFC-SPEX的完整信号流。d_m(n)进入PBFDKF得到补偿信号e_m(n)。D_m(k)和E_m(k)的实虚部作为输入送入DNSF,DNSF输出掩膜F_s(k)作用于D_0(k)得到目标语音估计ŝ_0(n)。ŝ_0(n)经过增益K和延迟Δt后生成扬声器信号u(n),u(n)与反馈路径卷积产生y_m(n),形成闭环。图1(b)展示了DNSF内部结构:输入被reshape后,依次通过双向LSTM、单向LSTM和全连接层,最终输出cIRM。
💡 核心创新点
- 联合处理框架:区别于传统将反馈消除(AFC)和语音增强(SE)简单级联的思路,本文提出了一个深度整合的框架。AFC模块的输出不是直接送入DNSF的“干净输入”,而是作为辅助参考与原始信号一起输入,允许DNSF学习如何利用AFC的估计信息来联合优化反馈抑制和语音提取,从而避免了级联导致的误差传播和次优解。
- 针对闭环训练的教师强制策略:由于系统输出的估计语音
ŝ_0(n)会影响下一时刻的输入(反馈),直接训练DNN非常困难。本文采用教师强制策略,在训练时用真实的ŝ_0(n)(教师信号)来生成反馈y_m(n),从而构建“开环”的训练数据集。这有效规避了闭环依赖,显著降低了训练复杂度,同时保证了训练时AFC模块(PBFDKF)的正常工作。 - 将AFC补偿信号作为空间滤波器的先验:DNSF本身是一种强大的非线性空间滤波器。本文的关键洞察是,PBFDKF输出的补偿信号
e_m(n)可以提供关于反馈成分的额外信息。将e_m(n)的频域表示与原始信号D_m(k)一同输入,相当于为DNSF提供了一个关于“反馈可能存在”的隐式提示,使其能更有效地从空间上区分和抑制反馈信号,从而增强了系统的整体反馈抑制能力(如实验B所示)。 - 在PBFD格式下保持一致性:为了最小化额外计算开销,DNSF直接处理PBFD格式的频域信号,而不是转换为标准的STFT格式,这体现了工程实现的细致考虑。
🔬 细节详述
- 训练数据:使用
pyroomacoustics仿真生成。房间尺寸和混响时间随机变化。麦克风阵列为3元圆形阵列(半径5cm)。一个目标说话者和三个干扰说话者随机分布在房间内(确保角度分离)。数据来源为WSJ0的干净语音。生成5000个训练样本、500个验证集和500个测试集,每个样本10秒,采样率16kHz。干扰和目标语音先独立生成,然后对训练集使用教师强制策略注入反馈。 - 损失函数:采用公式(13)的组合损失
L = L_SF + L_DN。其中L_SF是针对目标语音的L1损失(在PBFD域),L_DN是针对(干扰+反馈)信号的L1损失,两者权重通过α(设为0.1)平衡。 - 训练策略:未详细说明优化器、学习率、batch size等。仅提到使用教师强制策略构建开环数据集进行离线训练。
- 关键超参数:帧移R=256,帧长N=512,分块数B=4。DNSF参数量0.88M,计算量14.18 GMAC/s。PBFDKF的状态转移参数A=0.99999。循环增益K=1,循环延迟Δt=32ms。反馈路径
h_m(n)长度1024。 - 训练硬件:论文中未提及。
- 推理细节:采用流式推理策略,DNSF逐帧估计cIRM并应用于
D_0(k)。
📊 实验结果
实验在两种场景下进行:A(带反馈和干扰)和B(仅带反馈)。评估指标包括SI-SDR、PESQ、STOI和最大稳定增益提升(ΔMSG)。主要结果如表1所示。
表1:闭环仿真平均评估结果(500次测试运行)
| 算法 | 仿真A:带反馈与干扰 | 仿真B:仅带反馈 | |||||
|---|---|---|---|---|---|---|---|
| SI-SDR | PESQ | STOI | SI-SDR | PESQ | STOI | ΔMSG (dB) | |
| idealAFC+DNSF (上界) | 7.16 | 2.28 | 0.83 | - | - | - | - |
| w/oAFC+DNSF | -32.21 | 1.33 | 0.35 | - | - | - | - |
| DNSFe2e | 3.03 | 1.93 | 0.78 | 5.47 | 2.37 | 0.87 | 37.02 |
| Rank2-MWF | -26.00 | 1.46 | 0.39 | -24.18 | 1.59 | 0.56 | 8.36 |
| AFC+DNSF | -1.78 | 1.99 | 0.77 | 0.59 | 2.77 | 0.88 | 21.26 |
| AFCres+DNSF | 4.11 | 2.04 | 0.80 | 7.49 | 2.77 | 0.92 | 43.17 |
| 1ch-PBFDKF | - | - | - | -12.46 | 2.31 | 0.84 | 3.76 |
| 1ch-AFC-SPEX | -5.30 | 1.39 | 0.49 | 3.01 | 2.07 | 0.79 | 35.63 |
| AFC-SPEX (本文) | 4.38 | 2.04 | 0.80 | 8.36 | 2.91 | 0.92 | 37.60 |
关键结论:
- 整体性能:AFC-SPEX在场景A和B中均表现优异。在场景A,其SI-SDR(4.38)和PESQ(2.04)远优于传统Rank2-MWF(-26.00, 1.46),也优于简单的直接级联AFC+DNSF(-1.78, 1.99)。在场景B,其PESQ(2.91)达到最高,ΔMSG(37.60 dB)也很高。
- 消融分析证明联合优势:
AFCres+DNSF(将AFC输出作为输入,并使用教师强制训练)在ΔMSG上取得最高(43.17 dB),表明强耦合的训练方式对提升反馈抑制极为有效。AFC-SPEX在语音质量指标上与其持平或略优,且作为完整框架更优。单独的DNSF(w/oAFC+DNSF,DNSFe2e)和单通道方法(1ch-)性能均不足,证明了多通道联合处理的必要性。 - 空间信息的重要性:对比
1ch-AFC-SPEX和AFC-SPEX,多通道版本在场景A的SI-SDR从-5.30提升到4.38,证明空间信息对于在复杂声学场景中区分目标与干扰/反馈至关重要。
图表:
图3展示了仿真A中不同方法的输出频谱图(与表1结果对应)。从图中可以直观看到,AFC-SPEX的输出频谱相比Rank2-MWF和AFC+DNSF,能够更干净地保留目标语音(高频部分清晰),同时有效抑制了反馈(啸叫成分)和干扰语音。
⚖️ 评分理由
- 学术质量(6.0/7):论文结构清晰,问题定义明确。提出的AFC-SPEX框架和教师强制训练策略具有合理性和有效性。实验设计周全,包含了多种有说服力的基线(如级联、单通道、传统方法)和消融实验,并在两个不同场景下验证。结果一致显示了方法的优越性。扣分主要因为:1)缺乏真实世界实验,所有结果基于仿真,而声学反馈问题在实际产品中表现可能截然不同;2)与最强的消融基线(
AFCres+DNSF)相比,完整框架AFC-SPEX在部分指标(ΔMSG)上并无优势,其“联合”设计的增量收益需更细致地解读。 - 选题价值(1.5/2):选题针对音频系统中一个具体且持久的痛点,具有明确的工程应用价值。结合自适应滤波和深度学习是当前信号处理领域的一个重要趋势。但该任务相对垂直和小众,对广大语音/音频读者的直接影响有限。
- 开源与复现加成(0.5/1):论文提供了可复现的核心代码仓库链接,这是巨大的加分项。但公开的资源有限(未提供模型权重、详细训练配置和真实数据),完整复现仍需自行搭建仿真环境和进行大量实验。