📄 Joint Estimation of Piano Dynamics and Metrical Structure with a Multi-Task Multi-Scale Network
#音乐理解 #多任务学习 #时频分析 #端到端
✅ 7.5/10 | 前25% | #音乐理解 | #多任务学习 | #时频分析 #端到端
学术质量 7.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Zhanhong He(The University of Western Australia, Perth, Australia)
- 通讯作者:未说明(根据署名顺序,可能是Defeng (David) Huang或Roberto Togneri,但论文未明确指出)
- 作者列表:Zhanhong He(The University of Western Australia)、Hanyu Meng(The University of New South Wales)、Defeng (David) Huang(The University of Western Australia)、Roberto Togneri(The University of Western Australia)
💡 毒舌点评
亮点:将Bark尺度特征与多任务学习框架巧妙结合,把模型参数量从千万级压缩到50万,在保持竞争力的同时大幅提升了实用性,这种“螺蛳壳里做道场”的工程优化思维值得肯定。
短板:研究完全局限于肖邦玛祖卡这一特定音乐风格和单一数据集(MazurkaBL),其结论能否泛化到其他乐器、风格乃至更复杂的管弦乐场景,存疑。
🔗 开源详情
- 代码:论文中提供了代码和预训练模型的GitHub链接:
https://github.com/zhanh-he/piano-dynamic-estimation。 - 模型权重:论文提到“pre-trained models are available”,表明提供了预训练权重。
- 数据集:使用的是公开的MazurkaBL数据集,论文中提供了原始论文的引用,表明其可公开获取。
- Demo:论文中未提及在线演示。
- 复现材料:论文提供了极其详细的复现指南,包括特征提取(自定义PyTorch BSSL提取器)、模型架构、训练配置、评估代码和超参数设置。
- 论文中引用的开源项目:
- 特征提取参考了Pampalk的MATLAB工具箱中的
ma_sone函数。 - 多尺度网络骨干改编自[18],其代码公开可用。
- 节拍跟踪的后处理和部分基线(Beat This [26], TCN+DBN [27])的代码也来自公开仓库。
- 特征提取参考了Pampalk的MATLAB工具箱中的
📌 核心摘要
- 要解决的问题:从音频录音中准确估计钢琴的力度(动态)及其节拍结构是一个核心挑战。传统方法依赖MIDI速度作为代理目标或使用独立的模型处理不同子任务,存在泛化差、依赖人工设计流水线等问题。
- 方法核心:提出一个紧凑的多任务多尺度网络。以Bark尺度特定响度(BSSL)为输入,通过一个三尺度并行分支的编码器提取共享表示,再利用多门混合专家(MMoE)模块为四个任务(动态级别、变化点、节拍、下拍)生成特化的特征表示,最后通过各自的线性头进行预测。
- 与已有方法相比新在哪里:
- 特征创新:采用BSSL替代主流的log-Mel频谱,使输入特征维度从128降至22,在保持信息量的同时将模型参数从14.7M压缩至0.5M,支持更长的音频输入(60秒)。
- 架构创新:设计多任务框架,共享编码器并通过MMoE动态分配专家资源,以解决不同任务(需要长时上下文 vs. 需要高时间分辨率)对时频分辨率的矛盾需求。
- 训练策略:采用60秒音频分段(带重叠)进行训练,并设计了针对不同任务(二分类/多分类)的组合损失函数。
- 主要实验结果:
- 在MazurkaBL数据集(1,999段肖邦玛祖卡录音)的5折交叉验证中,所提多任务模型在所有四个任务上均取得了最优(SOTA)性能。
- 关键结果对比表:
方法 特征 动态 F1 变化点 F1 节拍 F1 下拍 F1 参数量 ANN [28] (基线) BSSL 29.4 – – – n/a PELT [28] (基线) BSSL – 10.8 – – n/a Beat This [26] (基线) log-Mel – – 80.5 ± 2.7 52.8 ± 6.2 20.3 M 单任务多尺度网络 BSSL 50.6 ± 10.1 21.0 ± 9.9 84.0 ± 1.5 45.0 ± 1.7 0.4 M 多任务多尺度网络 (本文) BSSL 54.4 ± 8.9 26.1 ± 9.7 84.1 ± 1.3 55.2 ± 4.2 0.5 M - 消融实验结果表 (使用BSSL特征):
配置 动态 F1 变化点 F1 节拍 F1 下拍 F1 平均分 完整模型 54.4 26.1 84.1 55.2 55.0 去除 MMoE 52.8 22.0 82.9 51.8 52.4 去除多尺度 (s=1) 50.5 13.3 80.3 41.9 46.5 去除数据增强 50.5 19.6 83.2 51.7 51.2 使用30秒片段 49.1 19.2 83.4 52.7 51.1
- 实际意义:提供了一个参数高效、端到端的工具,能够从纯音频直接推断出带有节拍对齐的动态标记,可用于丰富自动音乐转录的乐谱,或直接用于大规模的钢琴演奏表现力分析。
- 主要局限性:研究仅在单一乐器(钢琴)和单一音乐风格(玛祖卡)的特定数据集上进行验证,其结论对更广泛的音乐类型、其他独奏乐器或混合声源的有效性有待验证。此外,模型依赖BSSL特征提取器,其计算复杂度与标准的频谱特征提取相比未作详细分析。
🏗️ 模型架构
模型的核心是一个多任务多尺度网络,其架构如Fig. 2所示,可以分为三个主要部分:
共享编码器 (Multi-scale Backbone):
- 输入:BSSL特征矩阵(22个Bark频带 × T个时间帧)。同时也支持log-Mel特征作为输入。
- 结构:首先通过2D批归一化进行预处理。编码器由三个并行分支构成,每个分支处理不同时间分辨率的特征,长度分别为T, T/s, T/s²(s是可配置的缩放因子,本文中设为5)。下采样和上采样分别通过步长最大池化和转置卷积实现。每个分支内部由一系列残差块和自注意力块组成(具体结构参考自[18])。
- 输出:三个分支的输出被整合成一个共享的潜在序列 Z ∈ R^{T × 8}。这种设计旨在通过不同的时间感受野,同时捕获动态估计所需的长期依赖和节拍检测所需的瞬态信息。
任务感知解码器 (MMoE Module):
- 共享专家池:包含8个共享的轻量级时间卷积块(1D卷积 + ReLU + 1D卷积)。所有专家并行处理共享潜在序列Z,产生一组专家输出 {e_{i,t}}。
- 任务特定门控:针对四个任务(动态、变化点、节拍、下拍),每个任务k有一个专属的门控网络 G_k(·)。它是一个简单的线性层,对每个时间步t的潜在特征 z_t 进行处理,输出一个softmax归一化的权重向量 w_k(t) ∈ R^8。
- 特征融合:每个任务k在每个时间步t的最终特征 y_{k,t} 是所有专家输出按门控权重 w_k(t) 的加权和。这实现了根据任务动态路由和选择最相关的专家特征。
任务头与后处理:
- 每个任务都有一个独立的线性层,将Y_k映射到对应任务的输出logits(动态为6类分类,其余为二分类)。
- 后处理:对原始帧级概率输出进行处理:节拍/下拍通过阈值(50%)和峰值拾取;动态级别在节拍位置取argmax;变化点先通过阈值(75%)筛选,再对齐到最近的节拍上。
架构图:
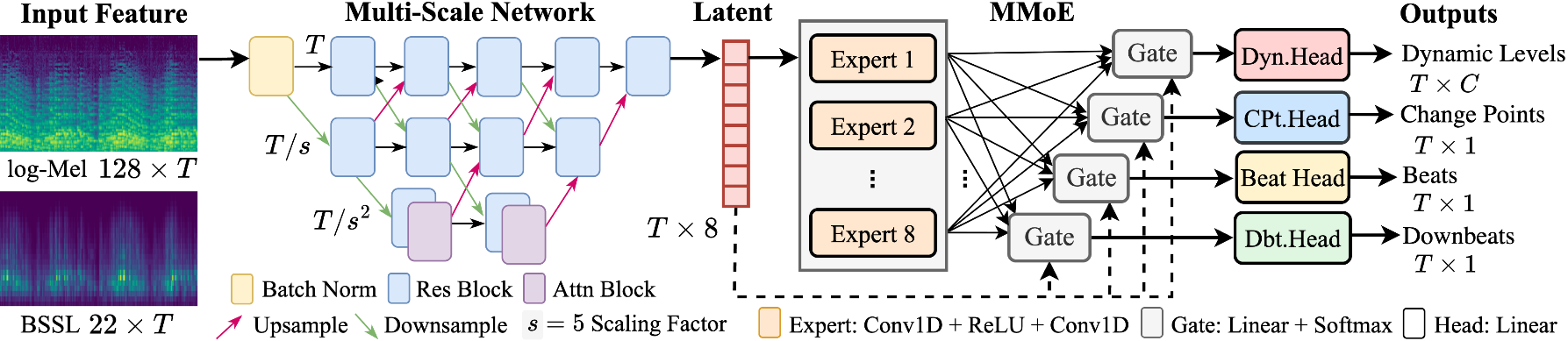 图2详细展示了从输入BSSL/log-Mel特征,经过三尺度编码器生成共享表示Z,再通过MMoE模块(8个专家+4个门控)为每个任务生成特化表示,最终通过线性头输出的完整数据流。
图2详细展示了从输入BSSL/log-Mel特征,经过三尺度编码器生成共享表示Z,再通过MMoE模块(8个专家+4个门控)为每个任务生成特化表示,最终通过线性头输出的完整数据流。
💡 核心创新点
- 引入Bark尺度特定响度(BSSL)作为紧凑输入特征:针对log-Mel频谱参数量大的问题,采用更符合心理声学感知且维度更低的BSSL(22维 vs. 128维)。这使得模型参数量从千万级降至百万级(0.5M),并能够处理更长的音频序列(60秒),为多任务学习提供了效率基础。
- 多任务多尺度联合学习框架:提出一个统一的网络,从共享表示中联合预测动态、变化点、节拍和下拍四个相关目标。这解决了传统流水线方法中任务割裂、误差累积的问题,并利用任务间的相关性互相促进,特别是通过节拍信息来约束动态标注的位置。
- MMoE实现动态任务解耦与融合:在共享编码器后使用多门混合专家模块。它允许不同任务根据自身需求,动态地对共享专家池进行加权组合,从而有效缓解了多任务学习中可能出现的“负迁移”(不同任务需求冲突)问题。
- 长时上下文建模:通过采用60秒的训练音频片段(并使用重叠增强),以及BSSL特征带来的效率提升,使模型能够利用更长的音乐上下文信息,这对需要宏观理解的动态和变化点任务尤为关键。
🔬 细节详述
- 训练数据:使用MazurkaBL数据集,包含2,098段独奏钢琴录音(肖邦玛祖卡),剔除2段后剩余1,999段。数据集提供了对齐的乐谱、节拍时间和动态标注。
- 数据增强:训练时,将音频切分为60秒的片段,重叠率为50%。评估时不重叠。
- 损失函数:总损失 L_MTL 是四个任务损失的简单求和。
- 节拍、下拍、变化点:使用带偏移容忍的加权二元交叉熵。它通过加权正样本来缓解目标稀疏性,并通过±3帧(70ms)的容忍窗口来处理标注的时间误差。
- 动态级别:使用标准的交叉熵损失,但仅在真实的节拍位置进行计算。这相当于一个先验约束,引导模型只在节拍位置预测动态,忽略节拍间的波动。
- 训练策略:
- 优化器:AdamW,学习率 3e-4。
- 训练轮数:120个epoch。
- 批大小:10。
- 验证与选择:5折交叉验证(按44首玛祖卡分层),每个epoch在验证集上计算F1,选择最佳检查点。
- 随机种子:固定为86。
- 关键超参数:
- 多尺度缩放因子 s:经验值为5。
- 音频长度:训练/评估均为60秒。
- STFT参数:窗口1024点,帧率50fps(20ms帧移),重采样至22.05kHz。
- MMoE专家数:8。
- 输出类别数:动态为6类(空白类 + pp, p, mf, f, ff)。
- 训练硬件:NVIDIA RTX 3090 GPU(24 GiB)。
- 训练时长:完整的5折交叉验证耗时约20小时,峰值显存占用4 GiB。
- 推理细节:无特殊解码策略,直接输出帧级概率,后处理逻辑如01所述。
📊 实验结果
论文在MazurkaBL数据集上进行了全面的对比实验和消融研究。
主要性能对比 (Table 1):
| 方法 | 特征 | 动态 F1 (%) | 变化点 F1 (%) | 节拍 F1 (%) | 下拍 F1 (%) | 参数量 |
|---|---|---|---|---|---|---|
| ANN [28] | BSSL | 29.4 | – | – | – | n/a |
| PELT [28] | BSSL | – | 10.8 | – | – | n/a |
| TCN+DBN [27] | log-Mel | – | – | 60.9 ± 1.8 | 30.4 ± 1.3 | 0.1 M |
| Beat This [26] | log-Mel | – | – | 80.5 ± 2.7 | 52.8 ± 6.2 | 20.3 M |
| 单任务多尺度网络 | BSSL | 50.6 ± 10.1 | 21.0 ± 9.9 | 84.0 ± 1.5 | 45.0 ± 1.7 | 0.4 M |
| 单任务多尺度网络 | log-Mel | 50.4 ± 11.1 | 17.5 ± 5.4 | 83.8 ± 1.8 | 54.7 ± 7.5 | 13.3 M |
| 多任务多尺度网络 (本文) | BSSL | 54.4 ± 8.9 | 26.1 ± 9.7 | 84.1 ± 1.3 | 55.2 ± 4.2 | 0.5 M |
| 多任务多尺度网络 (本文) | log-Mel | 50.8 ± 10.9 | 23.1 ± 6.1 | 83.7 ± 1.7 | 58.5 ± 6.2 | 14.7 M |
关键结论:
- 本文提出的多任务模型(BSSL)在动态和变化点任务上达到了SOTA性能,显著超越了之前最好的单任务网络和传统方法(ANN/PELT)。在节拍跟踪上与专门为节拍设计的SOTA模型(Beat This)性能持平,在下拍跟踪上也具有竞争力。
- 多任务学习带来了普遍提升:相比使用相同BSSL特征的单任务基线,多任务模型在四个任务上分别提升了3.8%, 5.1%, 0.1%, 10.2%的F1分数。
- BSSL特征在模型参数效率上优势巨大:使用BSSL的多任务模型仅0.5M参数,而使用log-Mel的同架构模型需要14.7M参数。
消融研究 (Table 2):
| 配置 | 动态 F1 | 变化点 F1 | 节拍 F1 | 下拍 F1 | 平均分 |
|---|---|---|---|---|---|
| Proposed | 54.4 | 26.1 | 84.1 | 55.2 | 55.0 |
| w/o. MMoE | 52.8 | 22.0 | 82.9 | 51.8 | 52.4 |
| w/o. Temp. Scal. (s=1) | 50.5 | 13.3 | 80.3 | 41.9 | 46.5 |
| w/o. Data Augm. | 50.5 | 19.6 | 83.2 | 51.7 | 51.2 |
| uses 30s Segment | 49.1 | 19.2 | 83.4 | 52.7 | 51.1 |
关键结论:
- 多尺度机制(Temp. Scal.)是性能基石,移除后所有任务性能急剧下降,尤其是需要长上下文的变化点和下拍。
- MMoE模块有效提升了所有任务,证明了其在动态分配专家资源、缓解任务冲突上的作用。
- 数据增强(重叠分段)和长输入(60秒) 对性能有稳定贡献,特别是对动态和变化点任务。
⚖️ 评分理由
- 学术质量:6.5/7:论文问题定义清晰,技术路线完整且合理。创新性地将心理声学特征(BSSL)与先进的多任务框架(MMoE+多尺度)结合,解决了效率和性能的平衡问题。实验设计严谨,在标准数据集上进行了全面的对比和充分的消融研究,所有关键组件的有效性都得到了数据支持。结论有充分证据支撑,技术正确性高。得分未达满分是因为其创新更多是组件间的巧妙整合与参数优化,而非提出全新的核心理论或架构范式。
- 选题价值:1.0/2:钢琴动态估计是音乐信息检索的一个具体分支,研究目标明确,对自动乐谱标注、音乐表现分析有直接的应用价值。然而,该问题领域相对垂直、狭窄,关注的乐器和音乐风格有限,与更广泛的语音、音频处理主流任务(如语音识别、音频事件检测)的普适性关联较弱。因此,对于广大音频/语音领域的读者,其直接参考价值有限。
- 开源与复现加成:+0.5/1:论文明确提供了代码和预训练模型的GitHub仓库链接。在实现细节部分,详细说明了特征提取、模型配置、训练超参数(优化器、学习率、批大小、轮数)、数据增强策略、评估协议(5折交叉验证)和硬件环境(GPU型号、训练时长),复现信息非常充分。模型权重是否公开未在正文中明确说明,但代码链接已提供。