📄 Inverse-Hessian Regularization for Continual Learning in ASR
#语音识别 #持续学习 #正则化 #领域适应
✅ 7.5/10 | 前25% | #语音识别 | #持续学习 #正则化 | #持续学习 #正则化
学术质量 6.8/7 | 选题价值 1.7/2 | 复现加成 1.0 | 置信度 高
👥 作者与机构
- 第一作者:Steven Vander Eeckt(KU Leuven, ESAT-PSI部门)
- 通讯作者:Hugo Van hamme(KU Leuven, ESAT-PSI部门)
- 作者列表:Steven Vander Eeckt(KU Leuven, ESAT-PSI部门)、Hugo Van hamme(KU Leuven, ESAT-PSI部门)
💡 毒舌点评
亮点在于优雅地将“往平坦方向走”的优化直觉转化为一个无需存储旧数据的实用合并步骤,并在实验中证明了其有效性,甚至超越了需要记忆库的方法。短板是其实验验证场景(两个小规模单语口音/麦克风适应任务)相对“温室”,离证明其在真实世界复杂、多语言、流式ASR系统中的鲁棒性还有距离。
🔗 开源详情
- 代码:论文明确提供了GitHub仓库链接:
https://github.com/StevenVdEeckt/inverse-hessian-regularization。论文中写道“更多细节,包括代码和详细结果,可在我们的GitHub仓库中找到。” - 模型权重:论文中未提及公开模型权重。
- 数据集:使用了Common Voice和LibriSpeech/Libri-Adapt等公开数据集。论文中未提及提供额外数据集。
- Demo:论文中未提供在线演示。
- 复现材料:论文提供了方法算法伪代码(Algorithm 1)、关键超参数(τ值)、以及基于ESPnet2���架的实现环境。代码仓库预计包含更多训练细节。
- 论文中引用的开源项目:ESPnet2[17](实验框架)、SentencePiece[24](分词器)、Adam优化器[25]。
📌 核心摘要
- 问题:自动语音识别(ASR)系统在持续学习新领域(如新口音、方言、麦克风类型)时,会遭遇灾难性遗忘,即在新任务上学习后,性能在旧任务上急剧下降。现有的无记忆方法(如权重平均)是启发式的,忽略了任务损失曲面的几何信息,限制了适应性。
- 方法核心:提出逆Hessian正则化(IHR)。在模型于新任务上微调后,得到参数更新量Δθ。IHR不直接使用该更新量,而是将其乘以旧任务损失函数在旧参数处的逆Hessian矩阵(或近似),从而将更新方向调整到对旧任务不敏感(即位于旧任务低损失区域)的方向,再与旧参数合并得到最终模型。
- 创新与新意:
- 首次将逆Hessian信息应用于ASR持续学习的合并步骤:与在训练中加入正则化项不同,IHR将其作为后处理,计算量小。
- 轻量级分层实现:采用Kronecker分块对角近似,仅针对占模型绝大多数参数的线性层计算并应用逆Hessian更新,保持计算和存储开销恒定。
- 实证优势:在两个基准测试上显著优于现有无记忆方法,并在遗忘指标上优于需要存储旧数据的回放缓存(ER)方法。
- 主要实验结果:
- 实验1(Common Voice口音适应):IHR的平均WER为13.32%,显著优于最强基线FTA(13.71%)和ER(13.97%)。BWT为-0.1(近乎零遗忘),而FTA为-0.3,Fine-Tuning为-3.6。
- 实验2(LibriSpeech → Libri-Adapt麦克风+口音适应):IHR的平均WER为7.40%,优于FTA(8.97%)、UOE(12.10%)等基线,但略逊于ER(6.43%)。BWT为-1.4。
- 消融实验证实,仅使用最近任务的逆Hessian近似(而非所有历史任务之和)效果相当,且对剩余参数使用1/t平均能进一步减少遗忘。
- 实际意义:为ASR模型提供了一种无需存储历史数据、计算高效且原理更合理的持续适应方案,有助于部署能够安全、隐私地不断学习新用户特征的ASR服务。
- 主要局限性:
- 实验验证的场景相对简单,均为单一语言、小规模任务序列的领域适应。在任务差异更大、序列更长或更复杂的持续学习场景下的有效性有待验证。
- 方法依赖于对Hessian的近似(特别是忽略跨层交互),且仅应用于线性层,其近似效果在更大模型上的理论保证和实际影响未深入分析。
- 超参数τ需要针对不同场景调整。
🏗️ 模型架构
本文的核心贡献在于优化策略(持续学习方法),而非全新的ASR模型架构。ASR模型本身采用标准的编码器-解码器结构:
- 编码器:12层Conformer块,结合了卷积和自监督注意力机制,用于处理输入声学特征序列。
- 解码器:6层Transformer块,用于自回归生成子词token序列。
- 输入/输出:输入为语音特征序列X,输出为词片段序列ŷ。模型采用混合训练方式,结合了CTC损失和交叉熵损失。
- 方法集成点:逆Hessian正则化(IHR)方法作用于模型的所有线性层(权重矩阵W)。在微调后,IHR会计算每个线性层的权重更新量ΔW_t,并用该层旧任务的逆Hessian近似H_{t-1}进行调整,最后合并回原权重。对于非线性层(如卷积、归一化)的参数,则采用简单的标量平均(α_p = 1/t)。
论文中未提供专门的模型架构图。 方法流程在论文图1中有示意性说明。
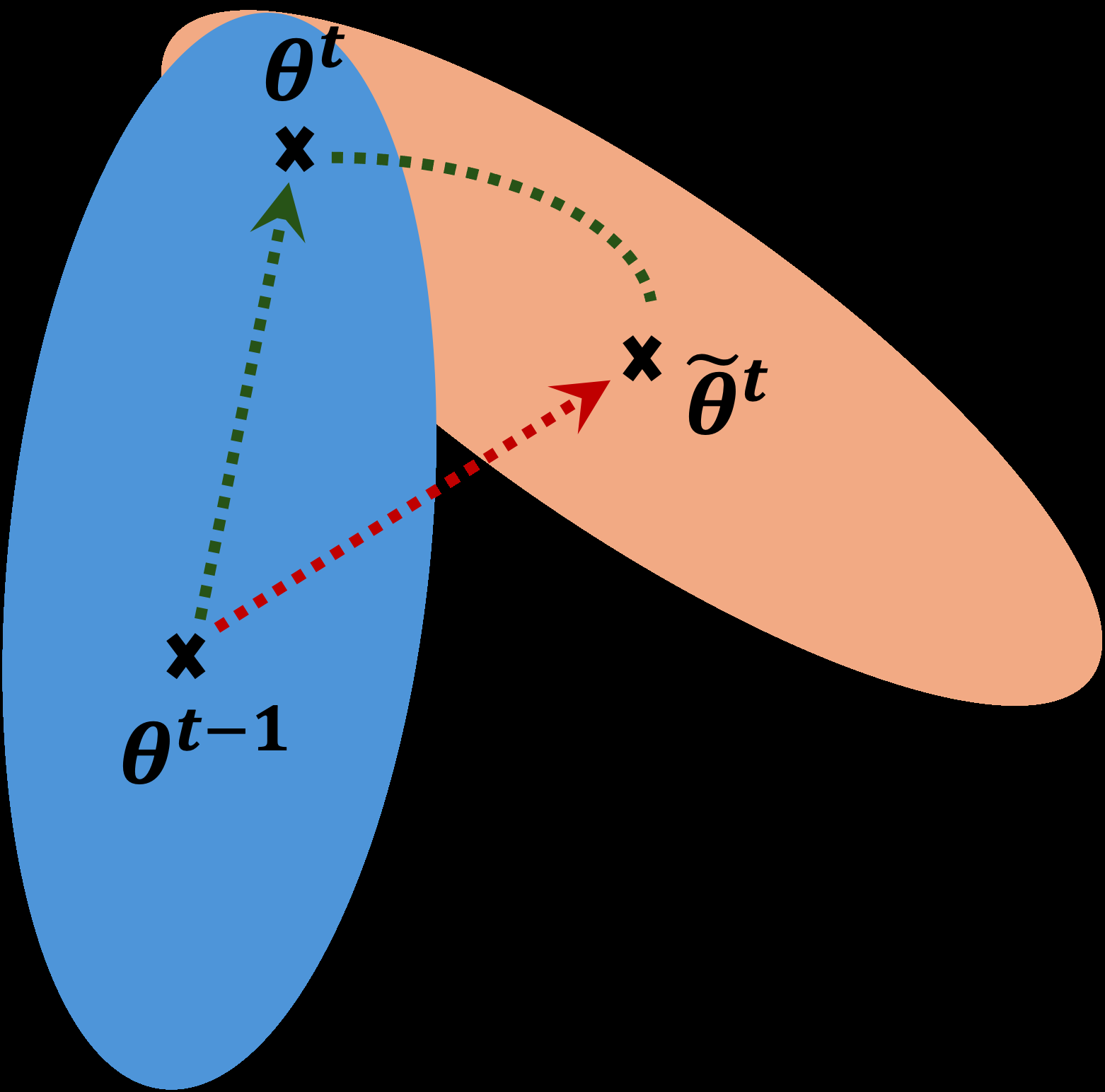 图1说明:该图直观展示了问题与解决思路。左侧蓝点θ_{t-1}是旧模型,橙点˜θ_t是微调后的新模型,但其可能位于旧任务(蓝色区域)的高损失区。IHR方法通过逆Hessian调整更新方向,使最终模型θ_t(绿点)仍位于新旧任务低损失区域的交集中。
图1说明:该图直观展示了问题与解决思路。左侧蓝点θ_{t-1}是旧模型,橙点˜θ_t是微调后的新模型,但其可能位于旧任务(蓝色区域)的高损失区。IHR方法通过逆Hessian调整更新方向,使最终模型θ_t(绿点)仍位于新旧任务低损失区域的交集中。
💡 核心创新点
- 将逆Hessian正则化应用于合并步骤(Merging Step):传统基于正则化的方法(如EWC)在训练过程中增加损失项来约束参数更新。IHR将这一思想后置,在微调后一次性应用,作为对更新向量的“预处理”。这大幅降低了计算开销,同时保留了利用损失曲率信息引导更新方向的理论优势。
- 轻量级、存储高效的分层Kronecker近似:为实现逆Hessian-向量乘积,IHR没有计算完整的N×N Hessian矩阵,而是:
- 分层处理:假设层间独立,在每层内独立近似Hessian。
- Kronecker近似:在线性层内,进一步将Hessian分解为两个较小矩阵的Kronecker积,仅需存储和操作这两个矩阵。
- 仅存储最近任务:为符合持续学习无记忆的原则,IHR仅存储并使用上一个任务(t-1) 的逆Hessian近似来更新当前任务(t)的参数。这使存储需求恒定。
- 在“稳定性-可塑性”平衡中取得更优实证结果:与启发式权重平均(FTA)相比,IHR能更好地平衡新旧任务。实验显示,IHR不仅减少了遗忘(BWT更接近0),更重要的是显著提升了对新任务的适应能力(例如在实验1的最后任务SCO上WER更低),这正是利用曲率信息将更新引导至“平坦”方向所带来的好处。
🔬 细节详述
- 训练数据:
- 实验1:Common Voice英语数据集,划分为5个口音:US, ENG, AUS, IND, SCO。任务按此顺序呈现。
- 实验2:以LibriSpeech-360h为初始任务,依次适应4个Libri-Adapt任务,涉及麦克风类型(USB, Matrix)和口音(US, IN, GB)的双重领域偏移。
- 损失函数:混合损失,结合CTC损失和解码器交叉熵损失,权重分别为c和1-c。在训练中,c=0.3。
- 训练策略:
- 优化器:Adam,在每个新任务前重新初始化。
- 学习率:第一个任务训练80个epoch,后续任务(2到T)训练10个epoch,学习率相比初始任务降低10倍。
- 具体学习率值、batch size、warmup等细节论文中未说明。
- 关键超参数:
- 模型大小:46.7M参数,其中90.7%位于线性层。
- 架构:12层Conformer编码器 + 6层Transformer解码器,4个注意力头,头维度256,前馈维度2048。
- 词汇表:5000个子词(SentencePiece),在第一个任务上生成。
- IHR超参数:τ(调整更新缩放的标量),在实验1中τ=1,实验2中τ=3。对于非线性层参数,α_p=1/t。
- 训练硬件:论文中未说明。
- 推理细节:未特别提及,推测使用标准的CTC/Attention联合解码。
- 正则化技巧:IHR方法本身即为核心正则化技巧。此外,训练可能使用了常规的dropout等,但论文中未具体说明。
📊 实验结果
主要实验结果对比表:
| 方法 | 实验1 平均WER↓ | 实验1 BWT↑ | 实验2 平均WER↓ | 实验2 BWT↑ |
|---|---|---|---|---|
| 初始模型 | 15.25 | — | 17.08 | — |
| Fine-Tuning | 15.07 | -3.6 | 12.43 | -9.0 |
| ER†(有记忆库) | 13.97 | -2.3 | 6.43 | -1.1 |
| FTA | 13.71 | -0.3 | 8.97 | -0.1 |
| UOE | 15.36 | -3.8 | 12.10 | -8.2 |
| CLRL-T | 15.26 | -2.8 | 11.02 | -5.5 |
| IHR | 13.32 | -0.1 | 7.40 | -1.4 |
†表示使用记忆库的方法。Best WER per column (across memory-free CL methods) is bold.
关键结论:
- 在无记忆方法中,IHR在两个实验上均取得了最低的平均WER,且统计显著。
- IHR的遗忘(BWT)极少(实验1接近0),显著优于FTA、Fine-Tuning等基线。
- 相比于需要存储旧数据的ER方法,IHR在实验1中性能更优且遗忘更少;在实验2中虽略逊于ER,但作为无记忆方法,性能已非常接近。
- 消融研究(Table 2)显示:使用仅最近任务的逆Hessian(H_{t-1}^{t-1})与使用所有历史任务之和(∑H_i^i)效果相当;对剩余参数使用α_p=1/t的平均进一步提升了性能。
图2分析:超参数τ的影响
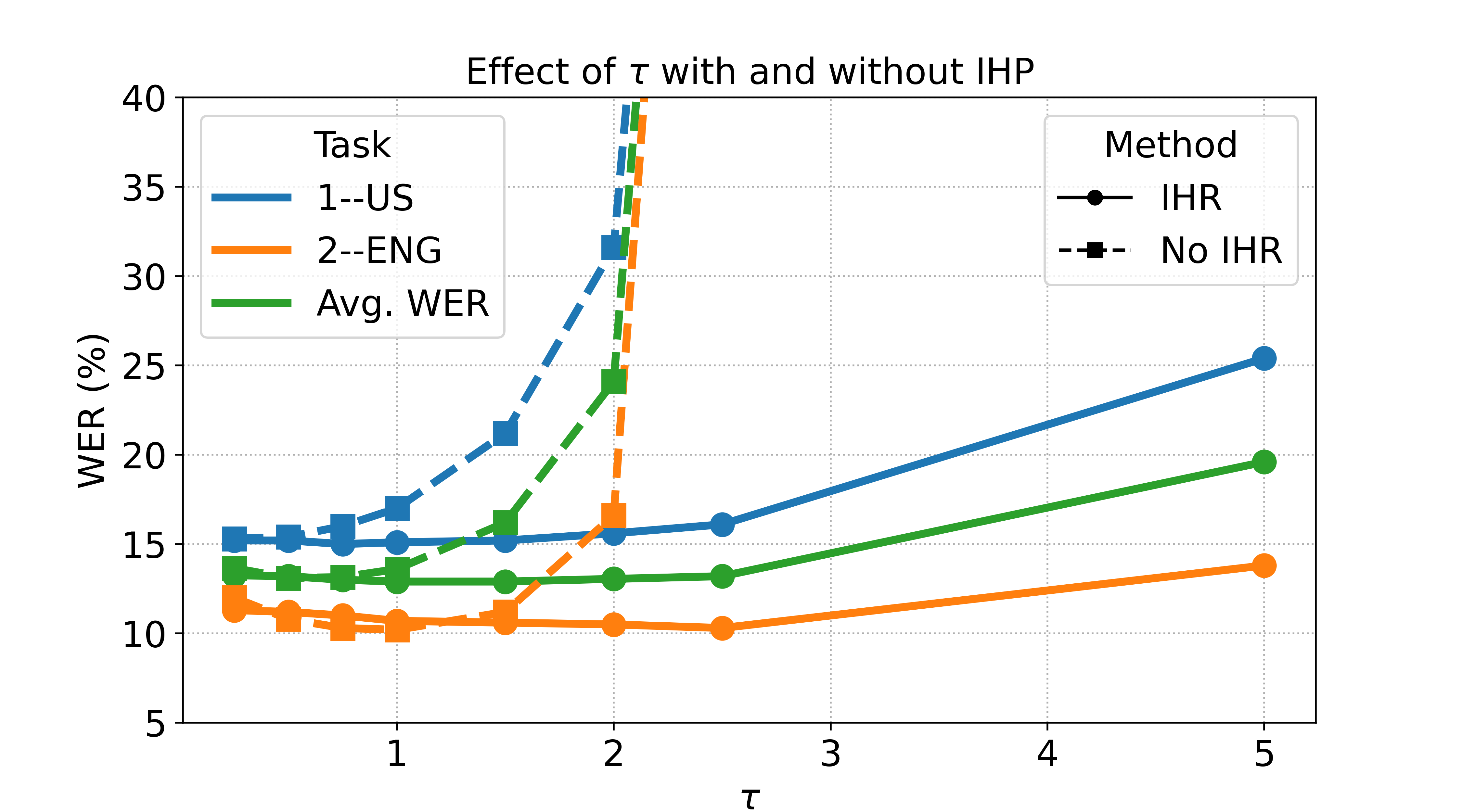 图2说明:该图展示了在第一次适应步骤(1-US → 2-ENG)中,WER随缩放因子τ的变化。虚线(No IHR)表示不应用逆Hessian,直接移动更新步长。可以观察到,应用逆Hessian(实线)后,模型对τ的取值鲁棒得多。即使τ增大到5.0,平均WER和旧任务WER仍保持稳定;而无IHR时,从τ=2.0开始性能就快速恶化。这直观证明了逆Hessian正则化将更新引导至“安全方向”的有效性。
图2说明:该图展示了在第一次适应步骤(1-US → 2-ENG)中,WER随缩放因子τ的变化。虚线(No IHR)表示不应用逆Hessian,直接移动更新步长。可以观察到,应用逆Hessian(实线)后,模型对τ的取值鲁棒得多。即使τ增大到5.0,平均WER和旧任务WER仍保持稳定;而无IHR时,从τ=2.0开始性能就快速恶化。这直观证明了逆Hessian正则化将更新引导至“安全方向”的有效性。
⚖️ 评分理由
- 学术质量:6.5/7。创新点明确且有实用价值(将逆Hessian正则化从训练中约束转化为合并后处理)。技术实现正确,分层Kronecker近似是处理大模型Hessian的经典方法。实验设计全面,包含了多种强基线(包括需要记忆的ER)和消融研究,结果可信且有统计显著性。扣分主要因为核心思想(利用Hessian预处理更新)并非全新,而是对已有优化思想在特定领域的巧妙应用。
- 选题价值:1.5/2。持续学习是ASR实用化的关键瓶颈,本文针对“无记忆”这一更具挑战和隐私优势的设定,提出了原理更清晰、效果更优的方法,对工业界部署自适应ASR模型有直接参考价值。相关性高。
- 开源与复现加成:1.0/1。论文提供了明确的GitHub代码仓库链接,承诺包含代码和详细结果,这为复现和进一步研究奠定了坚实基础,是显著的加分项。