📄 Interpretable Music Harmonic Analysis Through Multilinear Mixture of Experts
#音乐理解 #混合专家模型 #模型评估 #音乐信息检索 #数据集
✅ 7.5/10 | 前25% | #音乐理解 | #混合专家模型 | #模型评估 #音乐信息检索
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Thanasis Triantafyllou(雅典大学信息与电信系)
- 通讯作者:未说明(论文未明确指定)
- 作者列表:
- Thanasis Triantafyllou(雅典大学信息与电信系)
- Mihalis A. Nicolaou(塞浦路斯大学,塞浦路斯研究所)
- Yannis Panagakis(雅典大学信息与电信系,Archimedes, Athena R.C.)
💡 毒舌点评
亮点在于首次将内在可解释架构(µMoE) 引入罗马数字分析任务,让模型决策变得对音乐学家“透明”,专家激活模式确实呈现出符合理论的五度圈和V-I关系。短板是性能相比基准模型RNBERT有1-2个点的下降,且实验局限于单一任务和特定数据集,未能充分展示该架构在其他音乐分析任务或更大规模模型上的潜力和鲁棒性。
🔗 开源详情
- 代码:论文提供了代码仓库链接:https://github.com/TomusD/muMoE-RNBERT
- 模型权重:论文中未提及是否公开µMoE-RNBERT的预训练模型权重。
- 数据集:论文使用的数据集由多个公开集合(如TAVERN, When in Rome等)组成,但未提供统一的下载链接或具体的预处理脚本。原始数据集需从各自来源获取。
- Demo:论文中未提及在线演示。
- 复现材料:论文详细描述了训练策略、超参数、硬件环境、数据预处理和增强方法,为���现提供了充分的必要信息。
- 依赖的开源项目:明确依赖并基于MusicBERT模型进行微调。实现使用PyTorch框架。张量分解和µMoE的具体实现参考了论文[13](Oldfield et al., NeurIPS 2024)的方法。
📌 核心摘要
- 问题:现有基于Transformer的罗马数字分析(RNA)模型(如RNBERT)虽然性能先进,但缺乏可解释性,无法向音乐学家解释其分析背后的音乐理论依据,限制了其在学术研究中的应用价值。
- 核心方法:提出µMoE-RNBERT,通过用多线性混合专家(µMoE)层替换RNBERT中前馈网络(MLP)的线性层,构建第一个内在可解释的深度RNA系统。不同的专家子网络能够学习并专门处理不同的和声模式。
- 创新之处:是首个为RNA任务设计的内在可解释深度学习系统。不同于事后解释,其可解释性源于模型架构本身。该方法在保持与原始RNBERT几乎相同参数量(~26.7M)和计算成本的前提下,引入了专家专业化机制。
- 实验结果:在相同数据集和评估协议下,µMoE-RNBERT取得了与基准RNBERT可比但略低的性能。具体而言,整体罗马数字准确度(RN Accuracy)在74.6%-74.9%之间(基准为76.2%),在关键、质量、音级等子任务上也略有差距。但定性分析表明,专家激活显著遵循音乐理论,例如,不同专家专注于特定调性及其中的V-I进行,并呈现出五度圈的邻近调性模式。
- 实际意义:为音乐信息检索(MIR)和计算音乐学研究提供了一个可解释的AI工具。音乐学家可以观察并验证模型分析所依据的内部“音乐规则”,从而增进对模型行为的信任,并可能从中发现新的音乐结构洞见。
- 主要局限性:a) 性能相比当前最优基线有轻微损失;b) 可解释性分析主要基于可视化和统计观察,缺乏更系统的量化评估框架;c) 该方法的有效性尚未在其他音乐理解任务(如旋律生成、节奏分析)上得到验证。
🏗️ 模型架构
µMoE-RNBERT的整体架构基于RNBERT,其核心改动是将标准MLP层替换为µMoE层。
- 输入:乐谱采用OctupleMIDI表示,每个音符被编码为一个八元组(包含音高、时值、速度、节拍位置等)。输入序列被分块处理(1000个token,250个重叠)。
- 骨干网络:使用预训练的MusicBERT作为编码器,包含12层Transformer。实验中冻结前9层,仅微调后3层。
- 核心改造(µMoE层):在后3层的每个Transformer块中,将原始的前馈网络(FFN)中的两个线性层替换为对应的µMoE层。每个µMoE层通过张量分解(CP或TR分解)表示权重,结合门控网络(使用entmax激活)为每个输入token(音符)计算专家系数,从而动态、稀疏地激活一组专家。这允许不同的专家子网络学习不同的输入表示模式。
- 输出:在µMoE编码器输出之上,为四个子任务(调性、音级、和弦性质、转位)分别设置分类头(两层MLP),并行预测每个音符token的四个标签。
- 交互与设计动机:选择替换FFN层,是因为FFN位于自注意力之后,被认为是模型进行“事实知识”或模式识别的关键位置,且FFN的共享性有利于专家在不同任务间形成专业化分工,而任务特定的分类头则处理最终输出。这种设计保持了训练流程和推理过程的兼容性。
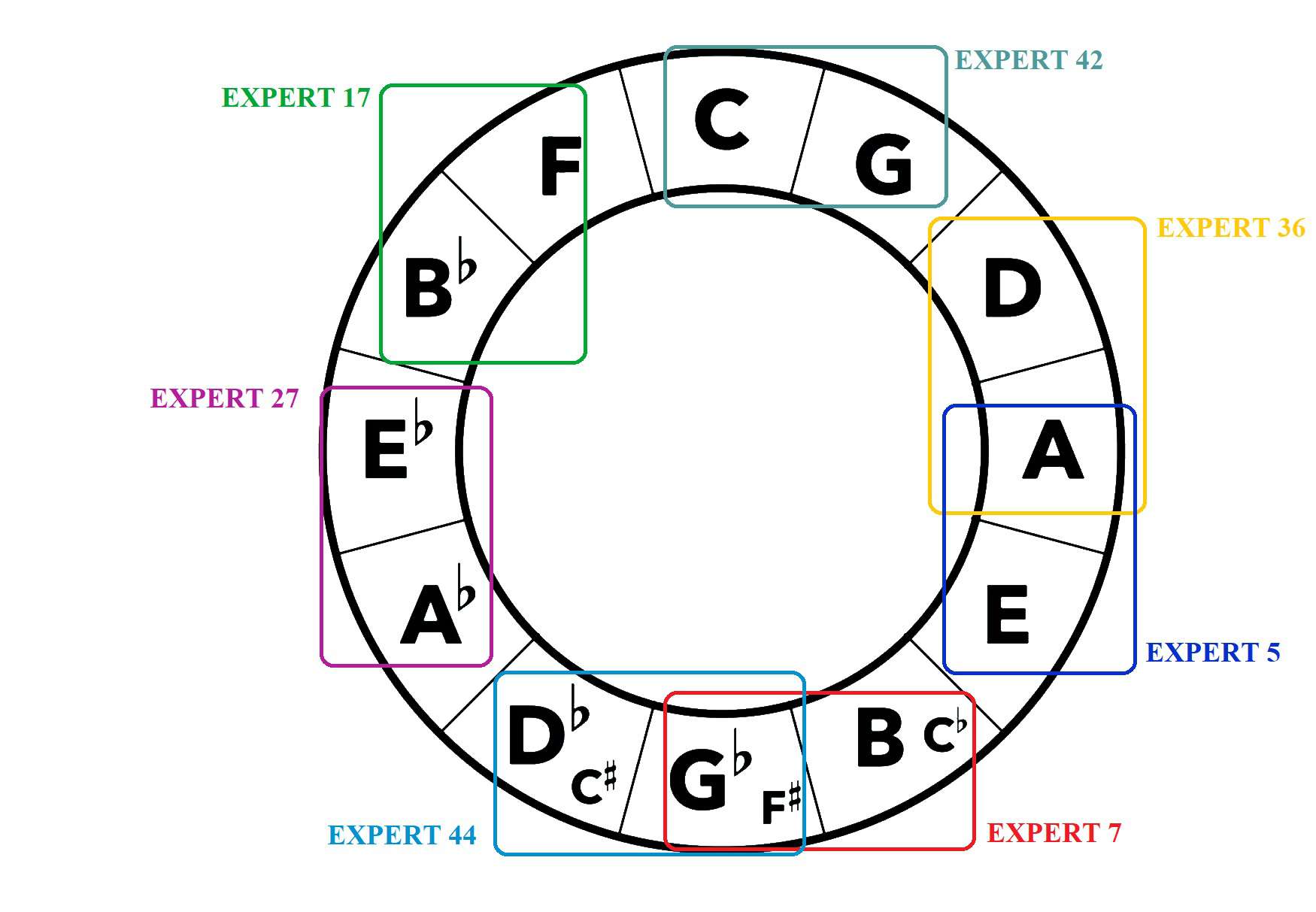 图1:展示了在测试集上,第12层(最后一层)中三个最活跃专家(专家7、17、27)在不同罗马数字标签上的激活次数(阈值≥0.4)。每个图显示了该专家最常激活的15个罗马数字标签。图的右下角用五度圈示意图总结了每个专家的主要调性专门化。可以看到,专家的高激活区域集中在主导和主音(V和I)上,且不同专家活跃于五度圈上的不同调性区域。
图1:展示了在测试集上,第12层(最后一层)中三个最活跃专家(专家7、17、27)在不同罗马数字标签上的激活次数(阈值≥0.4)。每个图显示了该专家最常激活的15个罗马数字标签。图的右下角用五度圈示意图总结了每个专家的主要调性专门化。可以看到,专家的高激活区域集中在主导和主音(V和I)上,且不同专家活跃于五度圈上的不同调性区域。
💡 核心创新点
- 首个内在可解释的RNA深度学习系统:直接针对音乐分析领域对可解释性的迫切需求,将可解释性作为模型设计的一部分,而非事后添加的补丁。这使得模型推理过程对领域专家(音乐学家)变得透明。
- 在保持性能与效率的前提下实现专家专业化:采用µMoE技术,在不增加原始模型参数量(均约26.7M)和计算复杂度的情况下,引入了数千个潜在的专家组合。通过张量分解和稀疏门控,实现了细粒度的专家分工,同时避免了传统稀疏MoE的训练不稳定问题。
- 专家学习音乐理论上有意义的模式:通过定量(统计激活系数)和定性(钢琴卷帘图可视化)分析,证实了不同的专家子网络确实学习到了符合理论的和声模式:例如,专家专门处理特定调性、关注V-I进行、以及模式在五度圈上的邻近性。这验证了模型内部表示的音乐学有效性。
🔬 细节详述
- 训练数据:使用与基准RNBERT相同的大型混合语料库,包括多个公开数据集:Digital and Cognitive Musicology Lab的多个作品集(如[15]-[17])、TAVERN集合(贝多芬与莫扎特作品)[18]、贝多芬钢琴奏鸣曲第一乐章[8]以及“When in Rome”元语料库[19]。具体数据集名称、来源、规模在论文中未提供详细数字(如总曲目数、总时长)。
- 预处理:采用salami-slicing将乐谱分割为单和弦标签的片段;以64分音符为最小时间单位进行量化;移除同时发声的重复音符;序列分块为1000个token,重叠250个token。
- 数据增强:对训练集进行所有半音阶的移调和基于时长的缩放。
- 损失函数:联合四个子任务(调性、音级、和弦性质、转位)的交叉熵损失。论文未提及各损失项的权重。
- 训练策略:
- 优化器:Adam
- 学习率:2.5e-4,带2500步线性预热,然后线性衰减至0。
- Batch size:4
- 训练步数:50,000步
- 硬件:单张NVIDIA RTX 3080 GPU (10GB VRAM),32GB DDR5 RAM,Ryzen 7 7700X CPU。
- 关键超参数:
- 基线模型:RNBERT,参数量26.7M。
- µMoE专家数量(N):实验测试了N=48和N=256两种配置。
- 张量分解方法:CP分解和TR分解(其中R1=R2=4)。
- 门控激活:entmax。
- 专家系数阈值(用于分析):≥0.4。
- 推理细节:对重叠的输入分块,预测结果通过输出logits的交叉融合进行合并。在专家分析中,对重叠音符的专家系数取平均值。
- 正则化:冻结MusicBERT前9层是主要的防过拟合手段。
📊 实验结果
主要性能对比 论文使用与基准模型相同的测试集,并报告了准确度(Accuracy)。
| 模型 | 整体RN准确度 | 调性(Key) | 性质(Quality) | 转位(Inversion) | 音级(Degree) | 参数量 |
|---|---|---|---|---|---|---|
| RNBERT (基准) | 76.2 | 86.7 | 87.2 | 82.2 | 62.0 | 26.7M |
| CPµMoE-RNBERT N=48 | 74.7 | 86.5 | 86.9 | 81.4 | 60.9 | 26.7M |
| TRµMoE-RNBERT N=48 | 74.6 | 86.3 | 86.8 | 81.6 | 60.4 | 26.7M |
| CPµMoE-RNBERT N=256 | 74.9 | 86.4 | 87.2 | 82.3 | 61.4 | 26.8M |
| TRµMoE-RNBERT N=256 | 74.7 | 86.2 | 87.1 | 82.1 | 61.0 | 26.2M |
关键结论:
- µMoE-RNBERT的所有变体性能均略低于基准RNBERT,整体RN准确度差距在1.3-1.6个百分点。
- 论文通过双比例Z检验(p=0.80)和Cohen’s h(最大0.033)证明性能差异不显著且效应量可忽略,即µMoE的引入没有带来显著的性能损失。
- 参数量几乎与原始模型持平。
- 消融实验:论文未明确设计消融实验,但通过比较不同专家数量(N=48 vs N=256)和分解方法(CP vs TR),观察到这些选择对最终性能影响很小,但对可解释性有影响(见下文)。
可解释性分析结果
- 定量分析:通过统计测试集(146首乐曲)上专家的激活系数(图1),发现活跃专家(阈值≥0.4)的高激活区域高度集中在特定调性的主音(I)和属音(V)上,这与主导-主音(V-I)的和声进行理论一致。不同专家活跃于五度圈上不同的调性区域(如专家7活跃于B大调/F#大调区域,专家27活跃于Eb大调/Ab大调区域)。
- 定性分析(图2,论文中未提供图2的URL,仅文字描述):通过钢琴卷帘热图可视化专家在巴赫作品(如《平均律》前奏曲No.23)上的激活模式,直观展示了:
- 专家调性特异性:如专家7在B大调片段高激活,在G#小调片段低激活。
- V-I关系的体现:如在C大调片段,不同专家分别对应主音和属音。
- 模式分析:专家在10-11层倾向于协同工作,专门处理某个和声功能(如专家29专门识别属七和弦)。
- 专家数量的影响:论文指出,48个专家是最佳平衡点。专家数过少(<48)会导致专家“多义”,学习多个调性;专家数过多(128-512)会导致专家“单义”,但可能丧失音阶内其他音符的激活,破坏音乐上下文的完整性;专家数超过1000则失去可解释性。
⚖️ 评分理由
- 学术质量:5.5/7:
- 创新性:明确且有价值的创新——将内在可解释架构引入RNA,填补了该领域的空白。
- 技术正确性:方法描述清晰,µMoE的集成方式合理,实验设计(控制变量、使用相同基准)严谨。
- 实验充分性:性能对比实验完整,可解释性分析(定量+定性)是论文的核心贡献且设计得当。但缺少与其他潜在可解释方法(如基于注意力的方法)的对比,也未展示模型在不同数据规模或音乐任务上的鲁棒性。
- 证据可信度:性能数据统计检验支持了“无显著差异”的结论;可解释性发现通过可视化和统计模式展示,具有说服力。
- 选题价值:1.5/2:
- 前沿性:解决AI可解释性在特定领域(音乐学)落地的前沿需求。
- 潜在影响:对计算音乐学和AI辅助音乐研究有直接价值,可能促进音乐理论研究新范式。
- 应用空间:面向专业音乐分析软件和学术研究工具,市场相对垂直。
- 读者相关性:对于从事音乐信息检索、可解释AI、音乐理论计算的读者高度相关。
- 开源与复现加成:+0.5:
- 论文提供了明确的代码仓库链接(GitHub)。
- 详细说明了训练超参数、优化器、硬件配置、数据处理方法等复现所需的关键细节。
- 未提及是否公开预训练的µMoE-RNBERT模型权重。
- 未提及是否提供了处理后的数据集或具体的评估脚本。
- 依赖的开源项目:MusicBERT(论文中明确指出)。