📄 Inter-Dialog Contrastive Learning for Multimodal Emotion Recognition in Conversations
#语音情感识别 #对比学习 #多模态模型 #跨模态
✅ 7.5/10 | 前25% | #语音情感识别 | #对比学习 | #多模态模型 #跨模态
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0 | 置信度 中
👥 作者与机构
- 第一作者:Dong-Hyuk Lee (Department of Electronics and Communications Engineering, Kwangwoon University)
- 通讯作者:Young-Seok Choi (Department of Electronics and Communications Engineering, Kwangwoon University, yschoi@kw.ac.kr)
- 作者列表:Dong-Hyuk Lee (Department of Electronics and Communications Engineering, Kwangwoon University)、Dae Hyeon Kim (Department of Electronics and Communications Engineering, Kwangwoon University)、Young-Seok Choi (Department of Electronics and Communications Engineering, Kwangwoon University)
💡 毒舌点评
亮点在于提出了“跨对话上下文”(Inter-dialog context)这一新颖维度,并设计了IDCL对比学习框架来有效利用它,为传统上仅关注对话内部的上下文建模提供了补充。短板在于方法创新的深度略显不足,核心是对比学习在模态间和对话间的应用组合,且论文缺少代码和模型细节,使得复现存在不确定性。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用了公开数据集IEMOCAP和MELD,但未提供论文特有的数据处理或增强脚本。
- Demo:未提供在线演示。
- 复现材料:提供了一些训练细节(优化器、学习率、批大小、特征提取器型号、模型隐藏维度等),但缺少关键超参数(如对比损失温度τ)、完整的模型配置文件、训练脚本和预训练检查点。因此,复现信息不够充分。
- 论文中引用的开源项目:Sentence-BERT (SBERT)、OpenSMILE 3.0、AdamW优化器。
- 开源计划:论文中未提及开源计划。
📌 核心摘要
- 问题:对话中的多模态情感识别(MERC)面临挑战,现有方法大多仅关注单个对话内部(intra-dialog)的上下文,而忽略了不同对话之间共享的情感模式(inter-dialog context)这一重要信息源。
- 方法核心:提出跨对话对比学习(IDCL)框架。该框架的核心假设是,具有相似情感轨迹的对话应共享底层的上下文模式。IDCL通过识别锚定对话在同一模态(如文本)中的Top-K最近邻对话,并将这些对话在另一模态(如语音)的表示作为正样本对,来增强对话级表示的学习。
- 创新点:与传统仅在单一对话内建模上下文的方法相比,IDCL首次系统地探索并利用了对话间的上下文信息。它通过跨模态、跨对话的对比学习,使模型能够学习到更具鲁棒性和泛化性的情感特征。
- 实验结果:在IEMOCAP数据集上进行了实验。在更具挑战性的6分类任务中,IDCL取得了66.4%的准确率(Acc.)和66.6%的加权F1值(WF1),超过了包括COSMIC、RGAT在内的多种现有方法。在4分类任务中,IDCL达到了85.9%的准确率和85.8%的加权F1值,达到了新的最先进水平(SOTA)。消融实验表明,Top-K邻居大小(K)的选择对性能有显著影响,存在一个最优区间。
- 实际意义:验证了跨对话依赖关系对于构建更鲁棒、准确的情感识别系统的潜力,为多模态情感分析领域提供了新的建模视角。
- 局限性:论文未充分讨论IDCL框架在更大规模、更多样化数据集上的泛化能力;其核心假设(即跨对话的情感模式一致性)的强度和适用范围有待进一步验证;此外,论文未提供代码,限制了结果的完全复现。
🏗️ 模型架构
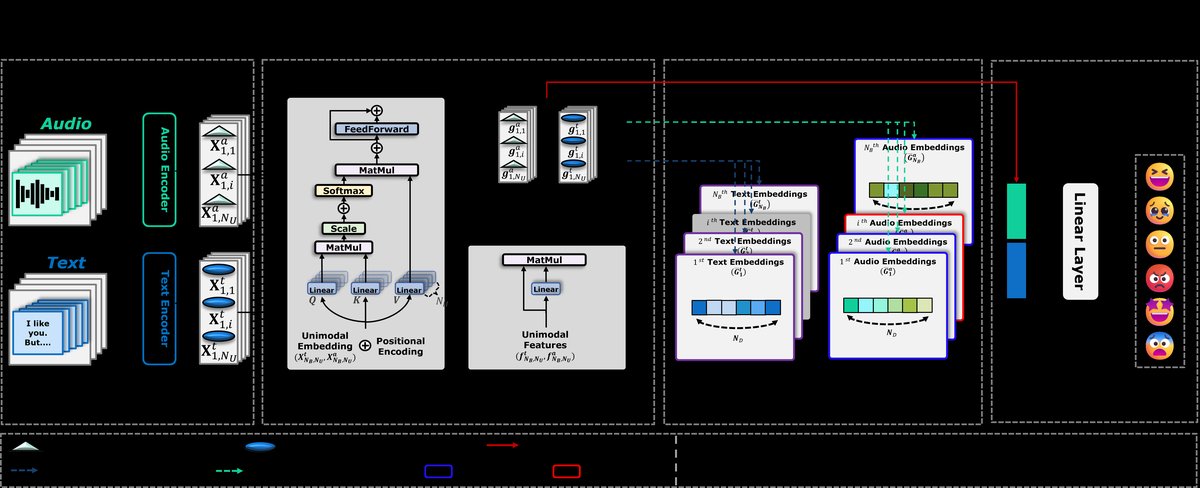
该模型采用两阶段训练架构:对比预训练 + 监督微调。
- 输入与特征提取阶段:
- 输入为一个对话(Dialog),包含NU个顺序话语(Utterance)。每个话语包含文本(t)和语音(a)两种模态信息。
- 使用单模态Transformer编码器(f)分别提取文本和语音的序列级特征,得到模态特征序列 F_m_i(维度:NU x ND)。
- 单模态门控融合(Unimodal Gated Fusion):
- 该模块作为滤波器,为每个模态选择重要特征。它首先通过一个可学习的线性层和Sigmoid函数生成门控值 Z_m_i(公式1),然后对原始特征进行逐元素加权 G_m_i = F_m_i ⊙ Z_m_i(公式2)。此步骤旨在保留各模态中最显著的信息,为后续跨模态融合做准备。
- 跨对话对比学习(IDCL)预训练阶段(核心创新):
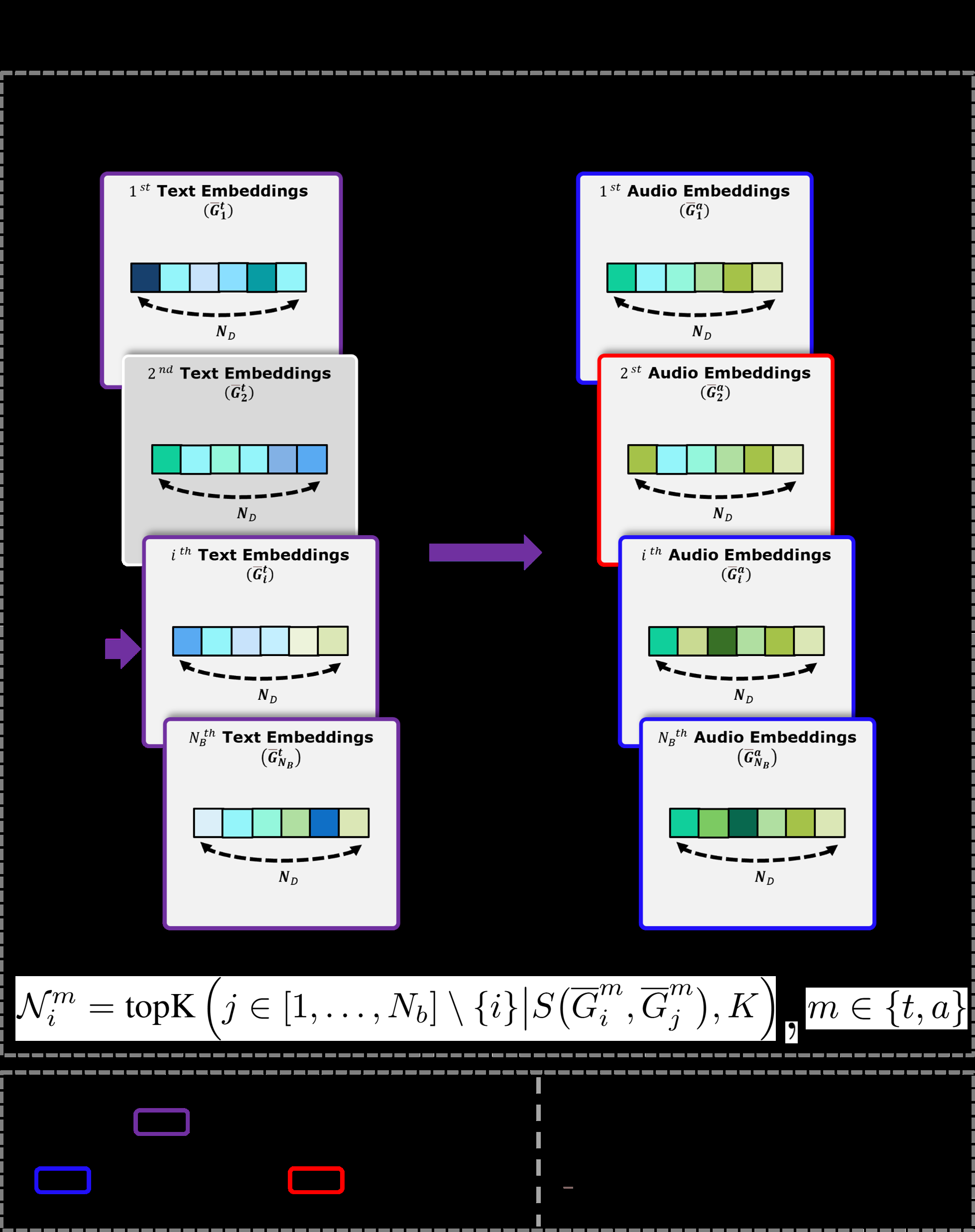
- 对话级表示聚合:对每个模态的门控特征 G_m_i 沿话语维度取平均,得到对话级表示 G^m_i(维度:1 x ND)(公式3)。
- 跨模态、跨对话正样本对构造:对于锚定对话i在模态m(如文本)上的表示 G^m_i,首先在同一模态的批量(batch)中,通过余弦相似度S(·,·)寻找与其最相似的K个对话,得到邻居索引集合 N^m_i(公式4)。然后,用这些索引去定义在另一模态 (非m) 上的正样本对。即 (G^m_i, G^m_k) 其中 k ∈ N^m_i 是一个正样本对。批量内所有其他对话l(l ∉ N^m_i)则构成负样本对。
- 对比损失:使用InfoNCE损失(公式5)最大化正样本对的相似度,最小化负样本对的相似度。温度参数τ控制分布的平滑度。这一策略迫使模型学习跨模态一致的对话表示:如果两个对话在文本上相似,那么在语音上也应相似。
- 分类与微调阶段:
- 将两个模态的门控特征 G^t_i 和 G^a_i 在特征维度拼接,得到联合表示 H_i(维度:NU x 2ND)(公式6)。
- 通过一个线性层进行情绪分类,预测每个话语的情绪类别(公式7)。
- 微调阶段的损失函数为交叉熵损失(L_CE)与IDCL对比损失(L_IDCL)的加权和:L_overall = L_CE + γL_IDCL(公式8),其中γ平衡两项损失(实验设为0.05)。这旨在保留预训练获得的泛化表示。
关键设计选择与动机:
- 门控融合:动机是模态噪声和无关信息会降低性能,门控机制在早期进行特征筛选。
- IDCL框架:核心动机是挖掘“跨对话上下文”这一未被充分利用的信息,通过对比学习强制模型学习更本质、更具判别性的情绪表达特征。
- 两阶段训练:先通过对比学习在对话粒度上对齐表示空间,再通过监督任务微调,兼顾表示的泛化性与任务针对性。
💡 核心创新点
- 引入“跨对话上下文”概念:这是本工作最核心的创新。作者指出,人类交流中存在可复用的情感弧线和表达风格,但现有方法局限于单一对话分析。IDCL首次将这一观察形式化,并设计了利用该信息的方法。
- 提出IDCL对比学习框架:这是一种新颖的对比学习策略,其创新在于跨模态、跨对话的正样本对构造方式。它不直接使用同一对话的不同模态作为正样本,而是利用同一模态内的相似性来定义另一模态的相似性,从而同时实现跨模态对齐和跨对话上下文利用。
- 平衡、稳健的情感表示学习:通过在大量不同对话中学习“情绪表达的共性”,IDCL被认为能学到更稳定、更少受说话人个体或特定场景干扰的特征。实验中IDCL在“Happy”和“Neutral”等通常难以区分的类别上表现突出,验证了这一点。
🔬 细节详述
- 训练数据:
- 主要评测数据集:IEMOCAP(包含7433个话语,151个对话),包含6分类和4分类两种设置。
- 预训练数据集:使用MELD(13708个话语)进行预训练以利用其规模,这在情感识别领域是常见做法。
- 特征提取:文本特征使用Sentence-BERT提取,语音特征使用OpenSMILE 3.0提取。数据预处理细节未详细说明。
- 损失函数:
- L_IDCL:InfoNCE对比损失,用于跨对话、跨模态表示对齐。
- L_CE:标准的交叉熵分类损失。
- L_overall:两者加权和,权重γ=0.05。
- 训练策略:
- 优化器:AdamW。
- 学习率:预训练阶段 1e-4,微调阶段 1e-3。
- 训练轮数:预训练1000轮,微调200轮。
- 批大小(NB):128个对话。
- 调度策略:未说明是否使用学习率衰减或warmup。
- 关键超参数:
- 隐藏维度(ND):512。
- 注意力头数:8。
- Dropout率:0.5。
- 对比损失温度(τ):未说明具体值。
- Top-K邻居大小(K):关键超参数,消融实验显示其最优值因任务而异(6分类K=15,4分类K=25)。
- 训练硬件:NVIDIA 3090 GPU。训练时长未说明。
- 推理细节:标准前向传播,未提及特殊的解码策略或流式设置。
- 正则化:使用了Dropout(率0.5)。
📊 实验结果
主要对比结果(IEMOCAP数据集):
表1. IEMOCAP 6分类任务结果对比
| 方法 | Happy | Sad | Neutral | Angry | Excited | Frustrated | Acc. | WF1 |
|---|---|---|---|---|---|---|---|---|
| Mult | 48.2 | 76.5 | 52.4 | 60.0 | 54.7 | 57.5 | 58.0 | 58.1 |
| FE2E | 44.8 | 65.0 | 56.1 | 62.1 | 61.0 | 57.1 | 58.3 | 57.7 |
| DiaRNN | 32.9 | 78.1 | 59.1 | 63.4 | 73.7 | 59.4 | 63.3 | 62.9 |
| COSMIC | 53.2 | 78.4 | 62.1 | 65.9 | 69.6 | 61.4 | 64.9 | 65.4 |
| Af-CAN | 37.0 | 72.1 | 60.7 | 67.3 | 66.5 | 66.1 | 64.6 | 63.7 |
| AGHMN | 52.1 | 73.3 | 58.4 | 61.9 | 69.7 | 62.3 | 63.6 | 63.5 |
| RGAT | 51.6 | 77.3 | 65.4 | 63.0 | 68.0 | 61.2 | 65.6 | 65.2 |
| IDCL (Ours) | 54.5 | 77.4 | 66.2 | 66.1 | 73.3 | 59.7 | 66.4 | 66.6 |
结论:IDCL在整体准确率和WF1上取得最佳,且在“Happy”和“Neutral”类别上优势明显,表明其学习到的特征更具区分度和稳定性。
表2. IEMOCAP 4分类任务结果对比
| 方法 | Happy | Sad | Neutral | Angry | Acc. | WF1 |
|---|---|---|---|---|---|---|
| SAWC | 83.0 | 77.6 | 66.2 | 80.6 | 76.8 | 76.6 |
| CTNet | 83.5 | 86.1 | 83.6 | 80.0 | 83.6 | 83.8 |
| JOYFUL | – | – | – | – | 82.6 | 82.5 |
| MFGCN | 79.7 | 77.1 | 80.4 | 73.3 | – | – |
| ESERNet | 65.5 | 88.8 | 78.3 | 79.1 | 76.9 | 76.8 |
| IDCL (Ours) | 78.8 | 87.0 | 86.4 | 88.5 | 85.9 | 85.8 |
结论:IDCL在4分类任务上全面超越现有方法,特别是在“Neutral”和“Angry”类别上达到了最优性能,取得了新的SOTA。
消融实验:Top-K邻居大小的影响 表3. 不同K值对性能的影响
| K | IEMOCAP (6-way) Acc. | IEMOCAP (6-way) WF1 | IEMOCAP (4-way) Acc. | IEMOCAP (4-way) WF1 |
|---|---|---|---|---|
| 5 | 65.8 (↓0.6) | 65.9 (↓0.7) | 82.2 (↓3.7) | 82.2 (↓3.6) |
| 10 | 64.2 (↓2.2) | 64.6 (↓2.0) | 83.9 (↓2.0) | 83.8 (↓2.0) |
| 15 | 66.4 | 66.6 | 84.9 (↓1.0) | 84.9 (↓0.9) |
| 25 | 64.8 (↓1.6) | 65.4 (↓1.2) | 85.9 | 85.8 |
| 50 | 65.1 (↓1.3) | 65.5 (↓1.1) | 84.7 (↓1.2) | 84.7 (↓1.1) |
结论:K值需要仔细权衡。过小(如5)导致上下文信息不足,过大(如50)则引入噪声,稀释对比信号。最优K值因任务而异(6分类K=15,4分类K=25)。
⚖️ 评分理由
学术质量:6.0/7
- 创新性(2/3):提出了“跨对话上下文”的新视角并设计了相应的IDCL框架,具有明确的创新动机和设计。但其核心是现有对比学习技术在特定场景(跨对话、跨模态)的应用组合,在方法论层面的突破性有限。
- 技术正确性(2/2):方法描述清晰,公式完整,逻辑自洽,实验设计合理,能支持其主张。
- 实验充分性(1.5/2):在主流数据集IEMOCAP上进行了充分的对比实验和消融实验(Top-K),并设置了跨数据集预训练,实验结果具有说服力。但缺少在MELD等其他数据集上的直接评测,也缺乏对模型失败案例的分析。
- 证据可信度(0.5/1):实验结果详实,但论文未提供���码或模型,且部分超参数(如温度τ)未说明,一定程度上影响了结果的完全可复现性和可信度。
选题价值:1.5/2
- 前沿性(0.8/1):多模态情感识别是情感计算和人机交互领域的热点,对话上下文建模是该领域的核心挑战之一。本工作从“对话间”维度切入,为解决这一挑战提供了新的思路,具有一定的前沿性。
- 潜在影响与应用空间(0.7/1):所提出的方法可能提升情感识别系统的泛化能力和鲁棒性,对心理健康监测、智能客服、人机交互等应用有潜在价值。然而,其效果高度依赖于训练数据中是否存在丰富的“跨对话情感模式”,在实际部署中可能面临数据多样性的挑战。
开源与复现加成:0.0/1 论文中未提及代码、模型权重或详细的复现指南。虽然给出了一些实现细节(如特征提取器、优化器、学习率),但缺乏关键的超参数(温度τ)、训练脚本和模型配置,导致完全复现存在显著困难,因此没有加成。
总分 = 6.0 + 1.5 + 0.0 = 7.5