📄 InstructAudio: Unified Speech and Music Generation with Natural Language Instruction
#语音合成 #音乐生成 #扩散模型 #多任务学习 #统一音频模型
✅ 7.5/10 | 前25% | #语音合成 | #扩散模型 | #音乐生成 #多任务学习
学术质量 6.0/7 | 选题价值 2.0/2 | 复现加成 -0.5 | 置信度 中
👥 作者与机构
- 第一作者:Chunyu Qiang(天津大学,快手科技)
- 通讯作者:Longbiao Wang(天津大学)
- 作者列表:Chunyu Qiang(天津大学,快手科技),Kang Yin(快手科技),Xiaopeng Wang(快手科技),Yuzhe Liang(快手科技),Jiahui Zhao(天津大学),Ruibo Fu(中国科学院自动化研究所),Tianrui Wang(天津大学),Cheng Gong(天津大学),Chen Zhang(快手科技),Longbiao Wang†(天津大学),Jianwu Dang(天津大学)
💡 毒舌点评
这篇论文的最大亮点在于其“野心”——试图用一个统一的框架和自然语言指令,同时搞定语音合成(TTS)和音乐生成(TTM)这两个本就差异显著的任务,这在思路上确实领先。但短板也很明显:论文在展示音乐生成对比结果时,坦诚其5-20秒的生成长度可能对长时序模型不公平,这种实验设计的局限性削弱了结论的说服力;更关键的是,论文几乎未提供任何可复现的开源信息,这对于一个宣称“统一框架”的工作而言,是个不小的遗憾。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:论文中未提及公开的模型权重下载地址。
- 数据集:论文中使用了自收集的50K小时语音和20K小时音乐数据,但未提及是否会公开数据集或获取方式。
- Demo:提供了在线音频示例演示页面:https://qiangchunyu.github.io/InstructAudio/
- 复现材料:论文给出了模型参数量(1.34B)、主要架构层数、优化器、初始学习率和GPU数量,但缺少学习率调度策略、训练步数/轮数、梯度裁剪等关键训练细节,复现材料不充分。
- 论文中引用的开源项目:引用了多个开源模型(如CosyVoice2, ACE-Step, DiffRhythm+)和工具(如Resemblyzer, emotion2vec, Qwen2.5),但未提及是否在代码或模型中集成了其他特定开源项目。
- 总结:论文中未提及开源计划(如代码、模型、数据的开源时间表)。
📌 核心摘要
- 问题:现有的文本转语音(TTS)和文本转音乐(TTM)系统在基于指令(自然语言描述)的控制方面存在显著局限。TTS模型通常依赖参考音频控制音色,属性控制能力有限;TTM模型则依赖专业标注,且两类任务长期独立开发,难以统一建模。
- 方法核心:提出InstructAudio,一个基于多模态扩散Transformer(MM-DiT)和条件流匹配的统一框架。它采用标准化的“指令-音素”输入格式,通过联合和单一扩散Transformer层,处理无噪的梅尔VAE潜在表示,从而在统一模型中实现语音和音乐的生成与控制。
- 新意:这是首个通过自然语言指令统一控制语音和音乐生成的框架。它消除了对参考音频的依赖,能通过文本指令控制音色(性别、年龄)、副语言(情感、风格、口音)和音乐(类型、乐器、节奏、氛围)等多种属性,并支持双说话人对话生成。
- 主要实验结果:
- TTS任务:在Seed-TTS基准的WER指标上,InstructAudio在可控条件下达到了最佳的英文(1.52%)和中文(1.35%)错误率(见表1)。在指令控制任务上,其分类控制准确率(如性别100%、年龄86.67%、对话90%)和说话人/情感相似度均优于强基线CosyVoice2,且在LSD、MCD等失真指标上更优(见表2)。
- TTM任务:在SongEval音乐评估基准的所有指标(连贯性、音乐性等)上均取得最佳分数。在分类控制准确率上,于歌手性别(98.89%)、年龄(97.22%)和氛围(95.00%)控制上表现突出(见表3)。
- 综合对比:论文通过图1可视化比较,声称在多项指标上实现了TTS和TTM能力的全面领先。
- 实际意义:为内容创作(如生成带有特定情感和风格的旁白或背景音乐)、交互式媒体、娱乐等领域提供了一种更通用、交互更自然的音频内容生成工具,降低了专业音频制作的门槛。
- 主要局限性:1) 统一输入格式(纯文本指令)导致了“一对多”的映射歧义,可能牺牲了生成音频的自然度和质量(NMOS分数低于使用参考音频的基线);2) 为了联合建模,将音乐生成长度限制在5-20秒,限制了其在长时音乐生成场景的应用,并且对基线模型的评估可能不公平;3) 论文未提供开源代码、模型或数据,可复现性低。
 InstructAudio整体架构示意图(图2)。
InstructAudio整体架构示意图(图2)。
- 输入:接受两种模态的输入。文本模态:对于语音任务,输入为包含说话人描述(性别、年龄、情感等)的指令文本和待合成文本;对于音乐任务,输入为包含歌曲属性(类型、乐器、情绪等)的指令文本和歌词。文本经过G2P转换为音素序列。音频模态:在训练时,输入是从真实音频中提取的梅尔VAE潜在表示,并添加了高斯噪声。
- 核心组件:
- 指令编码器(Instruct Encoder):使用预训练的Qwen2.5-7B大语言模型,将自然语言指令描述编码为高维嵌入向量。
- 音素编码器(Phoneme Encoder):基于Zipformer,将音素序列编码为嵌入向量。指令嵌入和音素嵌入在时间维度上拼接,形成统一的文本模态条件输入
Ctext。 - 梅尔编码器(Mel Encoder)与梅尔解码器(Mel Decoder):构成一个VAE。编码器将44.1kHz的原始波形编码为连续的潜在表示(梅尔VAE latent),实现高达1024倍的下采样。解码器负责将模型生成的潜在表示还原为音频波形。这两个模块在InstructAudio训练期间被冻结。
- 联合扩散Transformer(Joint Diffusion Transformer):由N2(14)层组成。每一层接收拼接后的文本嵌入
Ctext和无噪的音频潜在表示xt作为输入。两种模态通过联合注意力机制进行深度交互:查询、键、值来自两个模态,经缩放点积注意力计算后,输出再分割回各自模态。这是实现跨模态对齐和条件控制的关键。 - 单一扩散Transformer(Single Diffusion Transformer):由N1(6)层组成。这些层只处理音频潜在表示,将联合注意力退化为自注意力,专注于提升语音和歌唱声音生成的内部质量。
- 生成过程:采用条件流匹配。训练时,优化目标是让模型学习的速度场
vθ接近由噪声到数据的目标速度场u。推理时,从高斯噪声出发,通过ODE求解器,沿着学习到的路径迭代求解,最终得到目标音频的VAE潜在表示,再经解码器生成最终音频。
- 首个统一指令控制的语音-音乐生成框架:
- 局限:以往TTS和TTM任务独立开发,输入控制条件异构(TTS需参考音频或简单标签,TTM需专业标注),难以统一。
- 创新与收益:InstructAudio首次证明,通过设计标准化的“自然语言指令+音素”输入格式,可以使用同一个MM-DiT架构同时处理TTS和TTM任务,实现了跨模态的统一建模和生成。
- 全面的自然语言指令控制能力:
- 局限:现有TTS模型在基于文本的细粒度属性控制(尤其是音色、对话)上不足;TTM模型控制粒度较粗或不全面。
- 创新与收益:通过引入强大的指令编码器(Qwen2.5),模型能够解析复杂的自然语言描述,从而实现对音色(性别、年龄)、副语言(情感、风格、口音)和音乐属性(类型、乐器、节奏、氛围)的精细控制,并在TTS任务上首次实现了文本可控的双说话人对话生成。
- 高效的音频表征与架构设计:
- 局限:高保真音频生成需要高效的潜空间表征。不同任务的生成质量要求不同。
- 创新与收益:采用高下采样率(1024x)的梅尔VAE,将音频压缩到紧凑的连续潜在空间,显著提升了训练效率和重建质量。同时,创新性地设计了“联合层+单一层”的扩散Transformer结构:联合层负责跨模态理解与对齐,单一层专注于音频内部结构的精细化,这种设计在统一性和生成质量之间取得了平衡。
训练数据:收集了50K小时的语音数据和20K小时的音乐数据,来源于互联网。通过内部数据处理管道生成指令描述和文本/歌词标注。语音描述包含性别、年龄、情感、风格、口音属性;音乐描述包含类型、乐器、性别、年龄、节奏、氛围。音频片段长度为2-20秒,中文与英文、男性与女性比例约为1:1,90%以上为中性情感,0.5%为对话数据。统一采样率为44.1kHz。
损失函数:采用条件流匹配的损失函数,即最小化模型预测速度场
vθ与目标速度场u之间的均方误差:E[ ||vθ(t, Ctext, xt) - u(t, xt)||^2 ]。其中t是时间步。训练策略:
- 优化器:Adam
- 初始学习率:1e-4
- 训练硬件:32块NVIDIA Tesla A800 80GB GPU
- 批量大小(Batch Size):每块GPU 16
- 学习率调度策略、warmup步数、总训练步数/轮数:论文中未提及。
关键超参数:
- 模型总参数量:1.34B
- 条件流匹配前馈维度:1024
- 联合扩散Transformer层数(N2):14
- 单一扩散Transformer层数(N1):6
- 位置编码:RoPE
- 音素编码器:基于Zipformer,前馈维度512。
- 梅尔编码器:处理44.1kHz波形,输出43Hz的潜在表示,实现1024倍下采样。
推理细节:
- 解码策略:使用ODE求解器(具体类型未说明)从噪声迭代求解目标VAE潜在表示。
- 生成长度:语音和音乐均被限制在2-20秒。
- 温度(Temperature)、Beam Size:论文中未提及。
- 流式设置:论文中未提及。
正则化或稳定训练技巧:论文中未提及除使用预训练模块和标准扩散模型训练外的特殊技巧。
表1:主流TTS模型在基础能力和指令控制上的对比
模型 数据(hrs) 参数 文本控制 WER(%)↓ G&A E&S&A Dial EN ZH Ground Truth – – – – – 2.14 1.25 MaskGCT 100K Speech 1B ✗ ✗ ✗ 2.26 2.40 E2-TTS 100K Speech 333M ✗ ✗ ✗ 2.49 1.91 F5-TTS 100K Speech 336M ✗ ✗ ✗ 1.89 1.53 ZipVoice 100K Speech 123M ✗ ✗ ✗ 1.70 1.40 CosyVoice1 170K Speech 416M ✗ ✓ ✗ 4.29 3.63 CosyVoice2 167K Speech 618M ✗ ✓ ✗ 2.57 1.45 InstructAudio 50K Speech + 20K Music 1.3B ✓ ✓ ✓ 1.52 1.35 注:G&A = Gender&Age, E&S&A = Emotion&Style&Accent, Dial = Dialog. 结论:InstructAudio是唯一支持全部文本控制维度(包括对话)的模型,并在WER指标上取得了最佳成绩,证明其基础语音合成质量高。 表2:指令控制TTS任务的详细性能对比
模型 分类控制准确率(%)↑ 相似度↑ 失真/误差↓ MOS↑ Gender Age Emotion Style Accent Dialog Speaker Emotion LSD MCD MSEP MR QMOS NMOS Ground Truth 100.00 100.00 100.00 100.00 100.00 100.00 1.00 1.00 0.00 0.00 0.00 0.00 – – CosyVoice2 – – 58.33 65.00 100.00 – 0.68 0.53 2.57 7.11 547.87 0.46 3.90±0.11 3.65±0.22 InstructAudio 100.00 86.67 83.33 86.67 100.00 90.00 0.76 0.71 1.88 5.71 437.58 0.33 3.73±0.24 3.46±0.32 结论:InstructAudio在几乎所有控制准确率指标上大幅领先CosyVoice2(后者不支持性别、年龄和对话控制)。在说话人和情感相似度上也更高。在所有失真误差指标上均优于CosyVoice2。CosyVoice2的主观质量(QMOS)和自然度(NMOS)更高,论文认为这是因为其使用了参考音频输入,而InstructAudio是纯文本控制,存在“一对多”歧义。 表3:文本转音乐任务的性能对比
模型 数据(hrs) 参数 分类控制准确率(%)↑ SongEval↑ MOS↑ Genre Instrument Gender Age Rhythm Atmosphere Coh Mus Mem Cla Nat QMOS MMOS Ground Truth – – 100.00 100.00 100.00 100.00 100.00 100.00 3.60 3.52 3.56 3.43 3.34 – – DiffRhythm+ 120K Music 1B 51.33 81.67 22.22 44.44 93.33 87.22 2.68 2.61 2.57 2.48 2.37 3.04±0.46 2.79±0.54 ACE-Step 100K Music 3B 94.44 85.56 96.11 95.00 89.44 90.56 2.89 2.87 2.83 2.77 2.71 3.30±0.28 2.88±0.20 InstructAudio 50K Speech + 20K Music 1.3B 92.78 83.89 98.89 97.22 94.44 95.00 3.08 2.98 3.00 2.89 2.82 2.82±0.26 2.91±0.35 结论:InstructAudio在歌手性别、年龄、节奏和氛围控制上取得了最高准确率。在SongEval基准的所有5个指标上均获得最佳分数。在主观评价中,其音乐性(MMOS)得分最高,但感知质量(QMOS)低于ACE-Step。论文指出其音乐测试片段较短(5-20秒),可能对优化长时音乐的ACE-Step和DiffRhythm+不利。 图1 (pdf-image-page1-idx0) :模型能力对比雷达图。
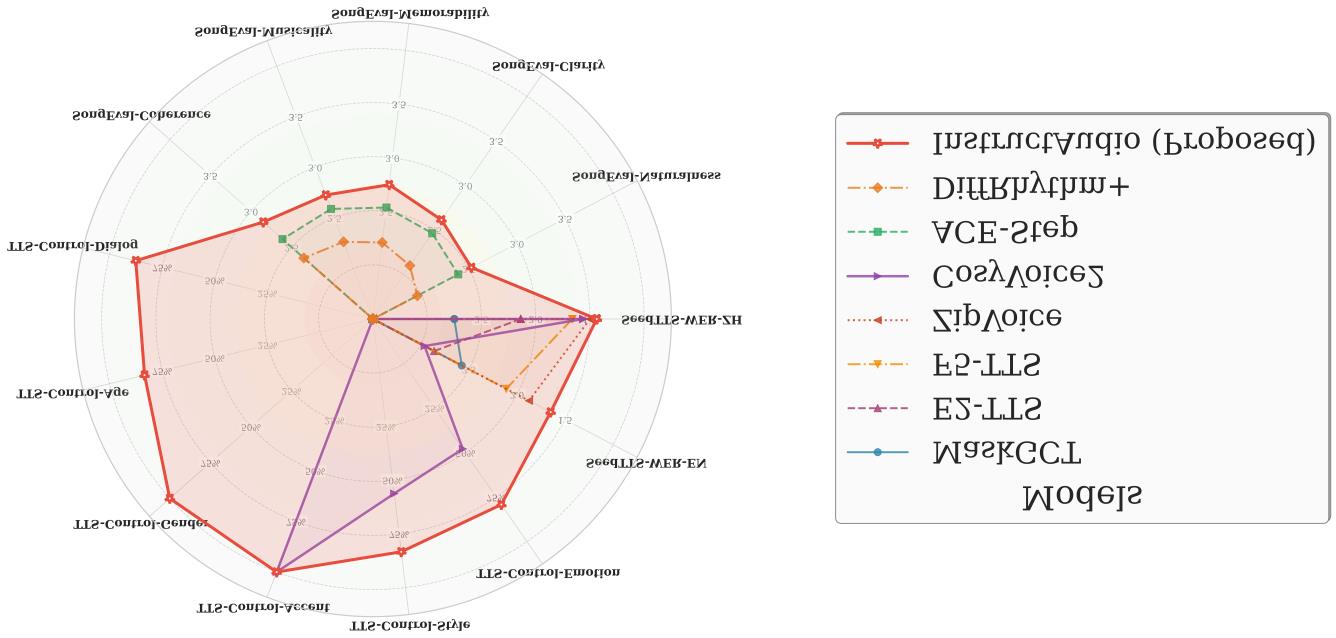 说明:此图将TTS和TTM的多个性能指标(如WER、控制能力、SongEval子指标)归一化到[0,1]区间进行可视化。红色线条代表InstructAudio,它在大部分指标维度上都达到了最外圈(最优),尤其在“支持所有评估维度”(TTS-Control和TTM属性)上表现突出,直观展示了其“统一”和“全能”的特点。
说明:此图将TTS和TTM的多个性能指标(如WER、控制能力、SongEval子指标)归一化到[0,1]区间进行可视化。红色线条代表InstructAudio,它在大部分指标维度上都达到了最外圈(最优),尤其在“支持所有评估维度”(TTS-Control和TTM属性)上表现突出,直观展示了其“统一”和“全能”的特点。
- 学术质量:6.0/7:创新性强,首次实现了基于自然语言指令的统一语音-音乐生成框架,技术路线(MM-DiT+条件流匹配)先进且选择合理。实验设计全面,覆盖了多个维度的控制能力和生成质量评估。扣分点主要在于:1)音乐生成任务的对比存在潜在的不公平性(生成长度限制);2)TTS对比中,部分基线不支持指令控制,控制能力对比的全面性有限;3)部分关键训练细节(如学习率调度)缺失。
- 选题价值:2.0/2:选题极具前沿性和实用价值。统一语音和音乐生成、采用自然语言交互,是生成式音频领域的明确趋势,能显著降低创作门槛,应用前景广阔。对音频和语音领域的读者来说,这是一个高度相关且启发性强的工作。
- 开源与复现加成:-0.5/1:扣分项明确。论文未提供代码、模型权重、训练数据集的获取链接。仅提供了音频样本演示页面。训练超参数(如学习率调度、训练步数)和硬件训练时长等细节不足,极大地阻碍了论文的复现。这是其主要短板之一。
开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:论文中未提及公开的模型权重下载地址。
- 数据集:论文中使用了自收集的50K小时语音和20K小时音乐数据,但未提及是否会公开数据集或获取方式。
- Demo:提供了在线音频示例演示页面:https://qiangchunyu.github.io/InstructAudio/
- 复现材料:论文给出了模型参数量(1.34B)、主要架构层数、优化器、初始学习率和GPU数量,但缺少学习率调度策略、训练步数/轮数、梯度裁剪等关键训练细节,复现材料不充分。
- 论文中引用的开源项目:引用了多个开源模型(如CosyVoice2, ACE-Step, DiffRhythm+)和工具(如Resemblyzer, emotion2vec, Qwen2.5),但未提及是否在代码或模型中集成了其他特定开源项目。
- 总结:论文中未提及开源计划(如代码、模型、数据的开源时间表)。
🏗️ 模型架构
InstructAudio整体架构示意图(图2)。
- 输入:接受两种模态的输入。文本模态:对于语音任务,输入为包含说话人描述(性别、年龄、情感等)的指令文本和待合成文本;对于音乐任务,输入为包含歌曲属性(类型、乐器、情绪等)的指令文本和歌词。文本经过G2P转换为音素序列。音频模态:在训练时,输入是从真实音频中提取的梅尔VAE潜在表示,并添加了高斯噪声。
- 核心组件:
- 指令编码器(Instruct Encoder):使用预训练的Qwen2.5-7B大语言模型,将自然语言指令描述编码为高维嵌入向量。
- 音素编码器(Phoneme Encoder):基于Zipformer,将音素序列编码为嵌入向量。指令嵌入和音素嵌入在时间维度上拼接,形成统一的文本模态条件输入
Ctext。 - 梅尔编码器(Mel Encoder)与梅尔解码器(Mel Decoder):构成一个VAE。编码器将44.1kHz的原始波形编码为连续的潜在表示(梅尔VAE latent),实现高达1024倍的下采样。解码器负责将模型生成的潜在表示还原为音频波形。这两个模块在InstructAudio训练期间被冻结。
- 联合扩散Transformer(Joint Diffusion Transformer):由N2(14)层组成。每一层接收拼接后的文本嵌入
Ctext和无噪的音频潜在表示xt作为输入。两种模态通过联合注意力机制进行深度交互:查询、键、值来自两个模态,经缩放点积注意力计算后,输出再分割回各自模态。这是实现跨模态对齐和条件控制的关键。 - 单一扩散Transformer(Single Diffusion Transformer):由N1(6)层组成。这些层只处理音频潜在表示,将联合注意力退化为自注意力,专注于提升语音和歌唱声音生成的内部质量。
- 生成过程:采用条件流匹配。训练时,优化目标是让模型学习的速度场
vθ接近由噪声到数据的目标速度场u。推理时,从高斯噪声出发,通过ODE求解器,沿着学习到的路径迭代求解,最终得到目标音频的VAE潜在表示,再经解码器生成最终音频。
💡 核心创新点
- 首个统一指令控制的语音-音乐生成框架:
- 局限:以往TTS和TTM任务独立开发,输入控制条件异构(TTS需参考音频或简单标签,TTM需专业标注),难以统一。
- 创新与收益:InstructAudio首次证明,通过设计标准化的“自然语言指令+音素”输入格式,可以使用同一个MM-DiT架构同时处理TTS和TTM任务,实现了跨模态的统一建模和生成。
- 全面的自然语言指令控制能力:
- 局限:现有TTS模型在基于文本的细粒度属性控制(尤其是音色、对话)上不足;TTM模型控制粒度较粗或不全面。
- 创新与收益:通过引入强大的指令编码器(Qwen2.5),模型能够解析复杂的自然语言描述,从而实现对音色(性别、年龄)、副语言(情感、风格、口音)和音乐属性(类型、乐器、节奏、氛围)的精细控制,并在TTS任务上首次实现了文本可控的双说话人对话生成。
- 高效的音频表征与架构设计:
- 局限:高保真音频生成需要高效的潜空间表征。不同任务的生成质量要求不同。
- 创新与收益:采用高下采样率(1024x)的梅尔VAE,将音频压缩到紧凑的连续潜在空间,显著提升了训练效率和重建质量。同时,创新性地设计了“联合层+单一层”的扩散Transformer结构:联合层负责跨模态理解与对齐,单一层专注于音频内部结构的精细化,这种设计在统一性和生成质量之间取得了平衡。
🔬 细节详述
- 训练数据:收集了50K小时的语音数据和20K小时的音乐数据,来源于互联网。通过内部数据处理管道生成指令描述和文本/歌词标注。语音描述包含性别、年龄、情感、风格、口音属性;音乐描述包含类型、乐器、性别、年龄、节奏、氛围。音频片段长度为2-20秒,中文与英文、男性与女性比例约为1:1,90%以上为中性情感,0.5%为对话数据。统一采样率为44.1kHz。
- 损失函数:采用条件流匹配的损失函数,即最小化模型预测速度场
vθ与目标速度场u之间的均方误差:E[ ||vθ(t, Ctext, xt) - u(t, xt)||^2 ]。其中t是时间步。 - 训练策略:
- 优化器:Adam
- 初始学习率:1e-4
- 训练硬件:32块NVIDIA Tesla A800 80GB GPU
- 批量大小(Batch Size):每块GPU 16
- 学习率调度策略、warmup步数、总训练步数/轮数:论文中未提及。
- 关键超参数:
- 模型总参数量:1.34B
- 条件流匹配前馈维度:1024
- 联合扩散Transformer层数(N2):14
- 单一扩散Transformer层数(N1):6
- 位置编码:RoPE
- 音素编码器:基于Zipformer,前馈维度512。
- 梅尔编码器:处理44.1kHz波形,输出43Hz的潜在表示,实现1024倍下采样。
- 推理细节:
- 解码策略:使用ODE求解器(具体类型未说明)从噪声迭代求解目标VAE潜在表示。
- 生成长度:语音和音乐均被限制在2-20秒。
- 温度(Temperature)、Beam Size:论文中未提及。
- 流式设置:论文中未提及。
- 正则化或稳定训练技巧:论文中未提及除使用预训练模块和标准扩散模型训练外的特殊技巧。
📊 实验结果
表1:主流TTS模型在基础能力和指令控制上的对比
模型 数据(hrs) 参数 文本控制 WER(%)↓ G&A E&S&A Dial EN ZH Ground Truth – – – – – 2.14 1.25 MaskGCT 100K Speech 1B ✗ ✗ ✗ 2.26 2.40 E2-TTS 100K Speech 333M ✗ ✗ ✗ 2.49 1.91 F5-TTS 100K Speech 336M ✗ ✗ ✗ 1.89 1.53 ZipVoice 100K Speech 123M ✗ ✗ ✗ 1.70 1.40 CosyVoice1 170K Speech 416M ✗ ✓ ✗ 4.29 3.63 CosyVoice2 167K Speech 618M ✗ ✓ ✗ 2.57 1.45 InstructAudio 50K Speech + 20K Music 1.3B ✓ ✓ ✓ 1.52 1.35 注:G&A = Gender&Age, E&S&A = Emotion&Style&Accent, Dial = Dialog. 结论:InstructAudio是唯一支持全部文本控制维度(包括对话)的模型,并在WER指标上取得了最佳成绩,证明其基础语音合成质量高。 表2:指令控制TTS任务的详细性能对比
模型 分类控制准确率(%)↑ 相似度↑ 失真/误差↓ MOS↑ Gender Age Emotion Style Accent Dialog Speaker Emotion LSD MCD MSEP MR QMOS NMOS Ground Truth 100.00 100.00 100.00 100.00 100.00 100.00 1.00 1.00 0.00 0.00 0.00 0.00 – – CosyVoice2 – – 58.33 65.00 100.00 – 0.68 0.53 2.57 7.11 547.87 0.46 3.90±0.11 3.65±0.22 InstructAudio 100.00 86.67 83.33 86.67 100.00 90.00 0.76 0.71 1.88 5.71 437.58 0.33 3.73±0.24 3.46±0.32 结论:InstructAudio在几乎所有控制准确率指标上大幅领先CosyVoice2(后者不支持性别、年龄和对话控制)。在说话人和情感相似度上也更高。在所有失真误差指标上均优于CosyVoice2。CosyVoice2的主观质量(QMOS)和自然度(NMOS)更高,论文认为这是因为其使用了参考音频输入,而InstructAudio是纯文本控制,存在“一对多”歧义。 表3:文本转音乐任务的性能对比
模型 数据(hrs) 参数 分类控制准确率(%)↑ SongEval↑ MOS↑ Genre Instrument Gender Age Rhythm Atmosphere Coh Mus Mem Cla Nat QMOS MMOS Ground Truth – – 100.00 100.00 100.00 100.00 100.00 100.00 3.60 3.52 3.56 3.43 3.34 – – DiffRhythm+ 120K Music 1B 51.33 81.67 22.22 44.44 93.33 87.22 2.68 2.61 2.57 2.48 2.37 3.04±0.46 2.79±0.54 ACE-Step 100K Music 3B 94.44 85.56 96.11 95.00 89.44 90.56 2.89 2.87 2.83 2.77 2.71 3.30±0.28 2.88±0.20 InstructAudio 50K Speech + 20K Music 1.3B 92.78 83.89 98.89 97.22 94.44 95.00 3.08 2.98 3.00 2.89 2.82 2.82±0.26 2.91±0.35 结论:InstructAudio在歌手性别、年龄、节奏和氛围控制上取得了最高准确率。在SongEval基准的所有5个指标上均获得最佳分数。在主观评价中,其音乐性(MMOS)得分最高,但感知质量(QMOS)低于ACE-Step。论文指出其音乐测试片段较短(5-20秒),可能对优化长时音乐的ACE-Step和DiffRhythm+不利。 图1 (pdf-image-page1-idx0) :模型能力对比雷达图。
说明:此图将TTS和TTM的多个性能指标(如WER、控制能力、SongEval子指标)归一化到[0,1]区间进行可视化。红色线条代表InstructAudio,它在大部分指标维度上都达到了最外圈(最优),尤其在“支持所有评估维度”(TTS-Control和TTM属性)上表现突出,直观展示了其“统一”和“全能”的特点。
⚖️ 评分理由
- 学术质量:6.0/7:创新性强,首次实现了基于自然语言指令的统一语音-音乐生成框架,技术路线(MM-DiT+条件流匹配)先进且选择合理。实验设计全面,覆盖了多个维度的控制能力和生成质量评估。扣分点主要在于:1)音乐生成任务的对比存在潜在的不公平性(生成长度限制);2)TTS对比中,部分基线不支持指令控制,控制能力对比的全面性有限;3)部分关键训练细节(如学习率调度)缺失。
- 选题价值:2.0/2:选题极具前沿性和实用价值。统一语音和音乐生成、采用自然语言交互,是生成式音频领域的明确趋势,能显著降低创作门槛,应用前景广阔。对音频和语音领域的读者来说,这是一个高度相关且启发性强的工作。
- 开源与复现加成:-0.5/1:扣分项明确。论文未提供代码、模型权重、训练数据集的获取链接。仅提供了音频样本演示页面。训练超参数(如学习率调度、训练步数)和硬件训练时长等细节不足,极大地阻碍了论文的复现。这是其主要短板之一。