📄 Influence of Clean Speech Characteristics on Speech Enhancement Performance
#语音增强 #模型比较 #多语言 #声学特征
🔥 8.0/10 | 前25% | #语音增强 | #模型比较 | #多语言 #声学特征
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.3 | 置信度 高
👥 作者与机构
- 第一作者:Mingchi Hou(Idiap Research Institute, Switzerland; École Polytechnique Fédérale de Lausanne, Switzerland)
- 通讯作者:未说明(论文未明确指出通讯作者)
- 作者列表:Mingchi Hou(Idiap Research Institute, Switzerland; École Polytechnique Fédérale de Lausanne, Switzerland)、Ina Kodrasi(Idiap Research Institute, Switzerland)
💡 毒舌点评
亮点: 论文提出了一个此前被忽视的、极具启发性的研究视角——即干净语音本身的“内在特征”如何影响语音增强的难度,并通过严谨的跨模型、跨语言实验设计,无可辩驳地证明了共振峰振幅(尤其是F3)与增强性能的强相关性,为领域内理解“为何某些语音样本难以增强”提供了新解释。 短板: 作为一篇ICASSP论文,其核心贡献是“相关性分析”而非提出一个新模型或新算法,对实际的语音增强系统改进方案(如如何利用这些特征设计模型或数据集)探讨略显不足;此外,PESQ指标在西班牙语上的弱相关性,一定程度上削弱了“跨语言结论一致性”的说服力。
🔗 开源详情
- 代码: 论文中未提及代码仓库链接。
- 模型权重: 未提及。
- 数据集: 使用公开数据集WSJ0、CROWD和CHiME3,并在论文中给出了获取方式或引用。
- Demo: 未提及。
- 复现材料: 论文提供了较详细的训练细节(优化器、学习率、批大小、停止准则)、模型参数量、硬件信息以及特征提取的具体工具(openSMILE, GeMAPS)和参数,为复现提供了良好基础。
- 论文中引用的开源项目: 主要依赖openSMILE工具库进行特征提取。SE模型本身的实现参考了多篇文献(如[2, 8, 23, 30]),但未说明是否基于特定开源代码库。
- 总结: 论文未提及具体的开源代码或模型发布计划,但提供了足够的技术细节和使用公开工具/数据,理论上可根据描述进行复现。
📌 核心摘要
问题: 传统语音增强(SE)研究主要关注噪声特性和信噪比(SNR),而干净语音信号本身的内在特性如何影响增强性能这一问题尚不明确。
方法: 本文系统性地研究了干净语音的声学特征(音高、共振峰、响度、频谱通量)与多种SOTA SE模型(掩码、回归、扩散、薛定谔桥)增强性能之间的相关性。实验在英语和西班牙语上进行,并控制了所有外部因素(如噪声类型和SNR)。
创新点: 首次系统量化并证实了干净语音内在特征对SE难度的影响,特别强调了共振峰振幅是增强性能最一致且最强的预测因子。同时,揭示了说话人内部(同一说话人不同话语)的声学变异性对性能的巨大影响,补充了现有说话人感知SE研究的视角。
主要结果: 共振峰均值与增强增益(ΔfwSSNR)呈强正相关(如CR模型在英语上相关系数达0.78),标准差呈强负相关。以第三共振峰(F3)均值划分,其最高25%(Q4)的样本相比最低25%(Q1)的样本,在所有模型和语言上平均可获得2-3 dB的ΔfwSSNR提升,以及在英语上约0.2-0.3的ΔPESQ提升。相关系数表和分组性能表是核心证据。
模型 语言 ΔfwSSNR [dB] Q4 ΔfwSSNR [dB] Q1 ΔPESQ Q4 ΔPESQ Q1 MM English 4.35 ± 1.13 1.86 ± 0.96 1.10 ± 0.13 0.91 ± 0.24 CR English 7.01 ± 1.11 3.93 ± 1.03 1.46 ± 0.15 1.14 ± 0.29 SB English 8.06 ± 1.12 5.37 ± 0.97 1.59 ± 0.18 1.29 ± 0.27 (注:表格节选自原文Table 3,展示了英语数据集上的关键对比) 实际意义: 研究结果为设计更平衡的训练数据集、制定新的评估协议(考虑语音内在难度)以及开发“声学特征感知”的增强模型提供了理论依据和新思路。
主要局限性: 分析基于客观指标(fwSSNR, PESQ),未深入涉及主观听感;研究重点在于揭示现象和相关性,未直接提出利用这些特征改进SE模型的具体架构或算法;PESQ指标在非英语语言(如西班牙语)上的适用性限制了部分跨语言结论的强度。
🏗️ 模型架构
本文的核心是分析框架,而非提出一个新的SE模型架构。研究者选择了四种代表性的SOTA SE模型作为分析对象,其架构如下简述:
- 掩码模型(MM): 基于5层双向LSTM,预测理想比率掩码,输出范围[0,1],使用SISDR损失训练。处理流程:带噪语音STFT → BiLSTM → Sigmoid → 掩码 → 与带噪幅度谱相乘 → 增强后语音。
- 复数回归模型(CR): 采用修改后的NCSN+ U-Net架构,直接估计带噪STFT系数的实部和虚部,使用时域MSE损失训练。
- 分数扩散模型(SGMSE+): 基于NCSN+骨干网络,训练DNN估计分数函数,通过反向扩散过程从噪声中恢复语音。使用30步预测-校正采样器。
- 薛定谔桥模型(SB): 同样基于NCSN+骨干,但将增强任务建模为带噪语音分布到干净语音分布的最优传输问题,通过50步SDE采样生成波形。
分析框架流程:
- 准备干净语音数据(WSJ0英语, CROWD西班牙语),切成固定2秒片段。
- 对每段干净语音提取一组声学特征(音高、共振峰、响度、频谱通量的均值和标准差)。
- 对同一段干净语音,添加四种噪声(来自CHiME3)和三种固定SNR(-5, 5, 15 dB),生成12个不同的带噪版本。
- 用四种预训练的SE模型处理所有带噪样本,计算每个增强样本相对于其带噪版本的ΔfwSSNR和ΔPESQ。
- 将同一干净语音的12个Δ值平均,得到该样本的平均增强性能。
- 计算这些平均性能值与步骤2中提取的声学特征之间的皮尔逊相关系数,并进行显著性检验。
💡 核心创新点
- 研究视角创新: 将SE性能差异的根源从“外部退化条件”(噪声、SNR)拓展到“干净语音内在声学特性”,这是一个被长期忽视但至关重要的维度。
- 关键特征发现: 通过跨模型、跨语言、多特征的系统分析,明确指出共振峰振幅(尤其是其均值和稳定性)是预测SE难度的最强且最一致的指标,提供了可量化的“内在难度”度量。
- 变异性分析: 强调并实证了说话人内部变异性(同一说话人不同话语)对SE性能的影响巨大,补充了当前主要关注说话人间差异的个性化SE研究。
- 方法论严谨性: 实验设计巧妙,通过固定噪声类型和SNR,并取平均值,严格控制了外部变量,确保所发现的相关性确实源于干净语音本身的特性,证据链清晰。
🔬 细节详述
- 训练数据: 英语数据集为WSJ0(120说话人, 28.6小时),西班牙语数据集为CROWD子集(规模与WSJ0匹配, 26.7小时)。测试集从每种语言的8位测试说话人中随机选取200个2秒片段,共1600个干净样本/语言。
- 噪声数据: 使用CHiME3数据集中的四种环境噪声(bus, cafe, pedestrian area, street)。
- 预处理: 信号下采样至16kHz。STFT使用510点窗、128点帧移。功率谱进行α=0.5, β=0.33的压缩。
- 声学特征提取: 使用openSMILE工具包,提取GeMAPS特征集的子集,包括:音高(F0均值/标准差)、第一至第三共振峰(F1, F2, F3)振幅均值/标准差、响度均值/标准差、频谱通量均值/标准差。
- 模型训练:
- 优化器:Adam。
- 批大小:8。
- 初始学习率:1e-4。
- 最大训练轮数:1000,若验证集损失连续20轮不下降则停止。
- 参数量:MM (7.6M), CR (22.1M), SGMSE+ (25.2M), SB (25.2M)。
- 硬件:CR, SGMSE+, SB在NVIDIA H100 GPU上训练;MM在RTX 3090 GPU上训练。具体训练时长未说明。
- 推理细节: 对于扩散模型(SGMSE+)和SB模型,SGMSE+使用30步预测-校正采样,SB使用50步SDE采样。其他模型为确定性前向传播。
- 评估指标: 使用频率加权分段信噪比(fwSSNR)和感知语音质量评估(PESQ),并计算其提升量ΔfwSSNR和ΔPESQ。
- 统计分析: 使用皮尔逊相关系数,并用双侧t检验(p<0.001)评估显著性。
📊 实验结果
主要相关性结果(见Table 1):
- 在所有四种模型和两种语言中,共振峰振幅(F1, F2, F3)的均值与ΔfwSSNR呈强正相关(英语上相关系数约0.65-0.78,西班牙语约0.30-0.72)。
- 共振峰振幅的标准差与ΔfwSSNR呈强负相关,表明稳定的共振峰更易增强。
- 响度和频谱通量的标准差也与性能呈负相关,尤其在英语中。
- 音高(f0)的影响中等且不稳定;音高变异性的相关性很弱。
- 相关性在英语数据集上通常比在西班牙语数据集上更强。
关键性能分组对比(见Table 3):
- 以F3均值划分的最高(Q4)和最低(Q1)25%样本对比显示,Q4样本的ΔfwSSNR在所有模型上平均比Q1样本高2-3 dB。例如,SB模型在英语上:Q4为8.06 dB, Q1为5.37 dB。
- 在英语数据集上,ΔPESQ的提升也很明显(Q4比Q1高约0.2-0.3分)。
说话人内部变异性分析(见图1):
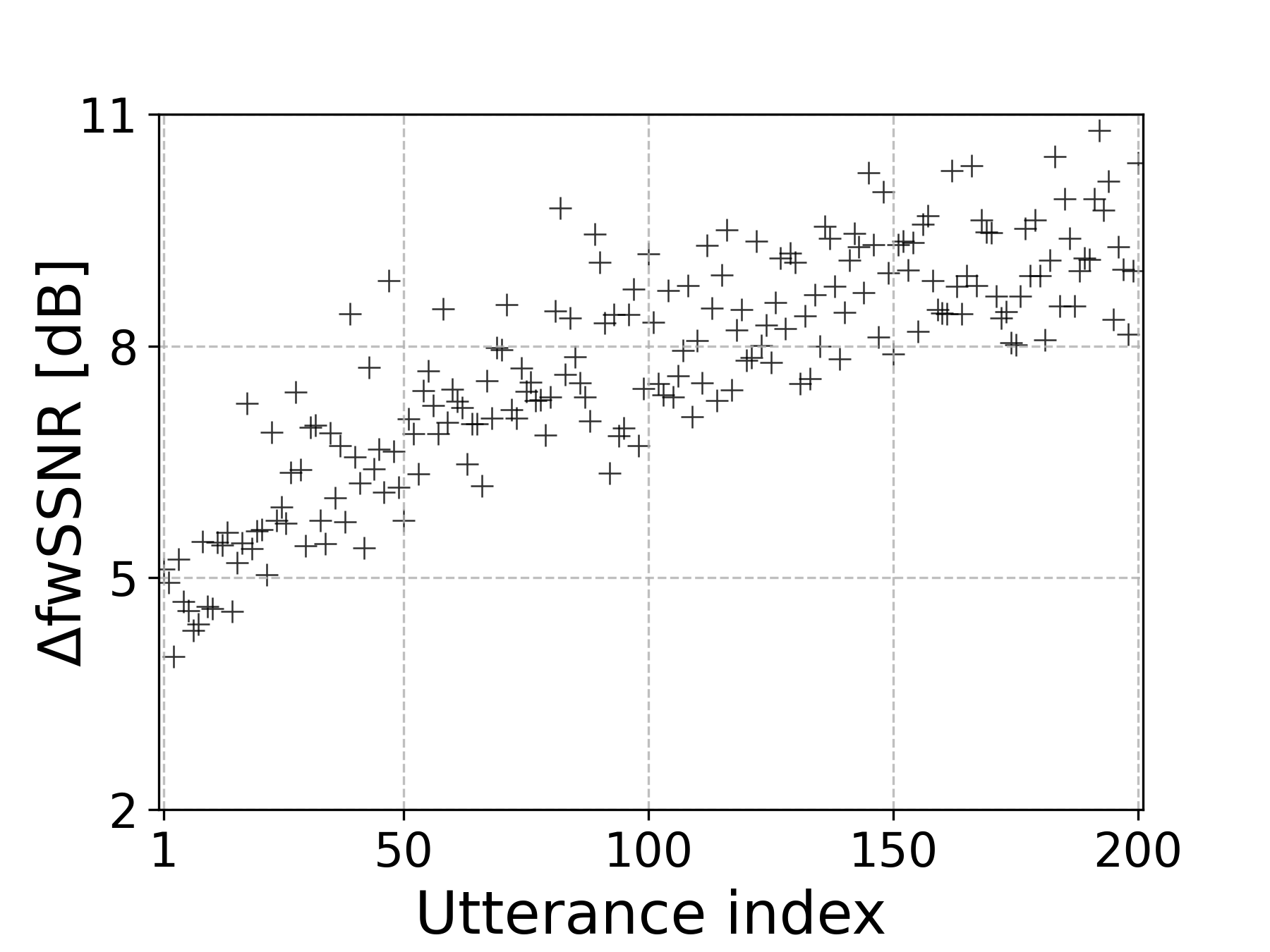
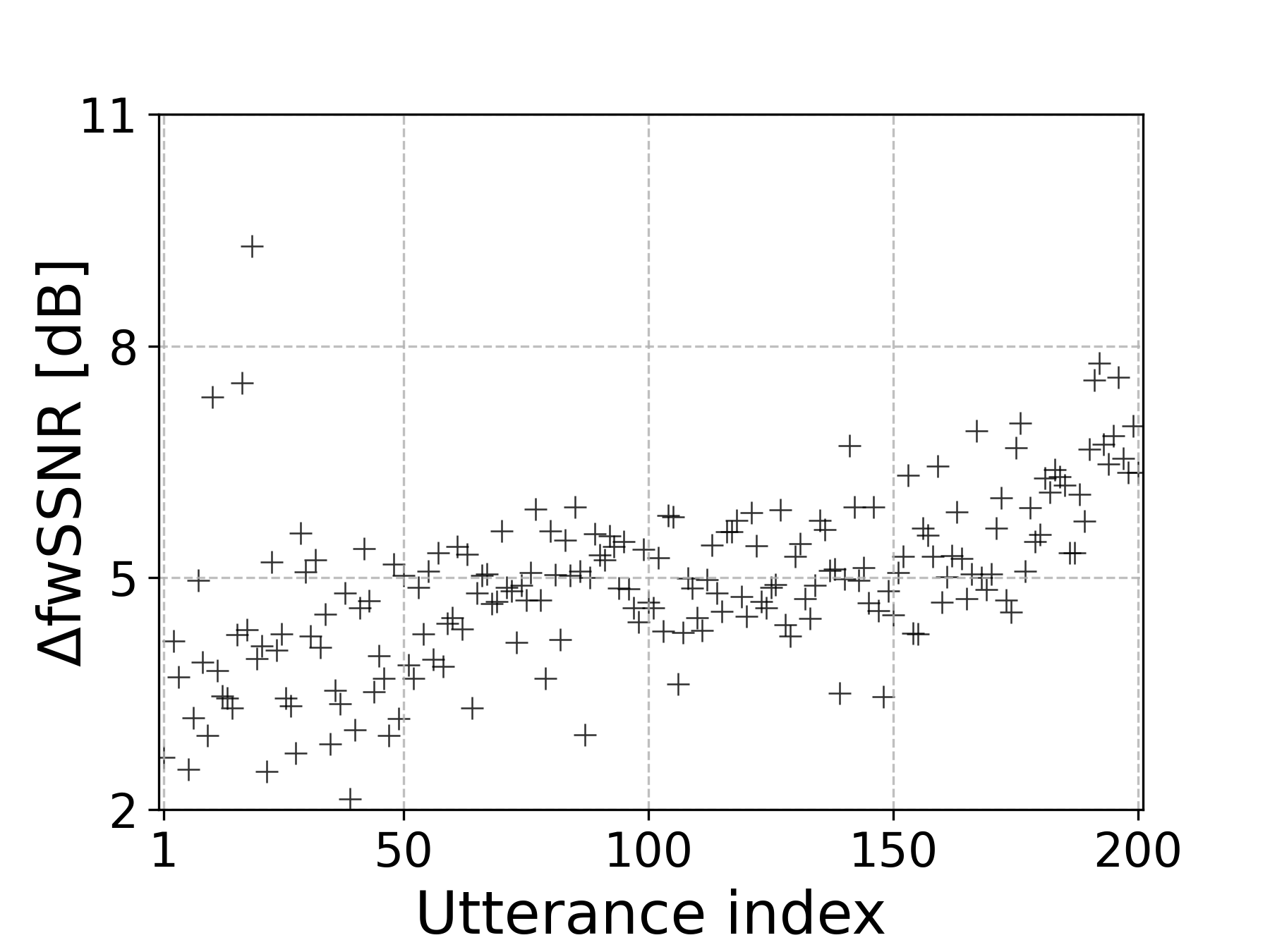
- 图1展示了SB模型在一位英语和一位西班牙语说话人所有话语上的ΔfwSSNR散点图(话语按F3均值升序排列)。
- 关键结论: 即使来自同一说话人,不同话语的ΔfwSSNR值也存在巨大波动(英语说话人范围约5-9 dB, 西班牙语说话人约4-7 dB),这直接证明了说话人内部声学变异性是影响SE性能的关键因素,而不仅仅是说话人间的差异。性能波动部分可由F3均值的变化解释。
⚖️ 评分理由
- 学术质量:6.0/7 - 本文在问题提出和研究视角上具有明确创新性;实验设计严谨,控制变量得当,相关性分析方法科学,结论有强数据支撑;技术路线正确,对多个SOTA模型的分析增强了结论的普适性。扣分点在于:这是一项以“分析”和“揭示现象”为主的研究,其本身并未提出解决该问题的模型或方法论,创新深度稍逊于提出新算法的工作。
- 选题价值:1.5/2 - 研究方向非常前沿且重要,直指当前SE系统评估和开发中的一个盲点。其发现对指导数据集构建、评估标准制定以及未来模型设计(如难度感知训练)具有明确的潜在影响和应用价值。与音频/语音处理领域的研究者高度相关。
- 开源与复现加成:0.3/1 - 论文详细提供了模型架构描述、训练超参数、数据集划分等关键信息,使用了公开数据集(WSJ0, CROWD, CHiME3)和开源工具(openSMILE),可复现性较高。但论文未提及是否公开代码、模型权重或预处理脚本,因此加成有限。