📄 Incremental Learning for Audio Classification with Hebbian Deep Neural Networks
#音频分类 #增量学习 #灾难性遗忘 #Hebbian学习 #稳定性-可塑性
✅ 7.5/10 | 前25% | #音频分类 | #增量学习 | #灾难性遗忘 #Hebbian学习
学术质量 7.0/7 | 选题价值 7.5/2 | 复现加成 8.0 | 置信度 高
👥 作者与机构
- 第一作者:Riccardo Casciotti (Tampere University, Signal Processing Research Centre)
- 通讯作者:未说明
- 作者列表:Riccardo Casciotti (Tampere University, Signal Processing Research Centre), Francesco De Santis (Politecnico di Milano, Department of Electronics, Information and Bioengineering), Alberto Antonietti (Politecnico di Milano, Department of Electronics, Information and Bioengineering), Annamaria Mesaros (Tampere University, Signal Processing Research Centre)
💡 毒舌点评
亮点:巧妙借用神经科学中的“多巴胺调节”概念,设计了一个简单而有效的核可塑性调制规则,在Hebbian学习框架下稳定了记忆,这是一个优雅的生物启发式工程实现。短板:所有验证仅基于一个规模和难度都有限的环境声数据集ESC-50,这使得“显著提升”和“生物合理性”的说法缺乏更有力的普适性证据,让人怀疑该方法在更大、更复杂的音频任务(如语音、音乐)或开放集增量学习中的真实效用。
🔗 开源详情
- 代码:是,论文提供了代码仓库链接
https://github.com/RiccardoCasciotti/Hebbian-TIL。 - 模型权重:论文中未提及公开的预训练模型权重。
- 数据集:使用的是公开的ESC-50数据集,论文未提及数据获取的特殊说明。
- Demo:论文中未提及在线演示。
- 复现材料:论文给出了关键超参数(top K, α, β, 监控间隔)、模型架构描述和评估指标公式。代码仓库应包含更多实现细节。
- 论文中引用的开源项目:提到了SoftHebb架构
[16](其基础代码可能已开源),并依赖于ESC-50[21]和 UrbanSound8K[26]数据集。
📌 核心摘要
- 要解决什么问题:深度学习模型在增量学习(持续学习新任务)时普遍遭遇“灾难性遗忘”,即学习新知识会导致对旧知识的严重遗忘。本文针对音频分类任务,旨在解决此问题。
- 方法核心是什么:提出一种基于Hebbian学习(生物启发式、无监督)深度神经网络的增量学习方法。其核心创新是“核可塑性”机制,通过监测卷积核在训练中的权重变化和激活值,识别并保护对当前任务重要的“核心核”,同时增强其他核的学习率(可塑性),以此调制网络的学习过程。
- 与已有方法相比新在哪里:据作者称,这是首次将Hebbian学习与增量学习相结合。与传统基于反向传播的增量学习方法(如EWC)不同,该方法在无监督的特征提取阶段就引入了生物启发的稳定性-可塑性平衡机制,而非仅在损失函数或权重更新上做约束。
- 主要实验结果如何:在ESC-50数据集的五步任务增量学习设置中,所提方法(带KP)的最终总体准确率为76.3%,显著高于不使用KP的基线(68.7%),并远优于EWC基线(33%)。同时,增量学习指标(FM, BWT)证实了该方法在保留旧任务知识方面的优势。
- 实际意义是什么:为音频智能系统(如持续识别新环境声音)提供了一种潜在的、计算更生物合理的增量学习范式,可能有助于构建更鲁棒、能持续演化的音频AI模型。
- 主要局限性是什么:验证数据集(ESC-50)规模小且任务简单;方法依赖任务标签(任务增量学习),未验证在更通用的类增量学习场景下的有效性;性能与同架构的联合学习相比并无优势,表明方法的增量学习能力提升是以牺牲部分模型容量或学习效率为代价的。
🏗️ 模型架构
模型架构(如图1所示)采用“特征提取器 + 任务专属分类头”的串行设计。
- 输入:Log-mel频谱图 (1×F×T)。
- 特征提取器:由5个连续的Hebbian卷积层构成。每个Hebbian层后接最大池化(前四层)或平均池化(第五层),并使用Batch Normalization和Triangle激活函数。各层卷积核尺寸和数量逐层递增(如Conv1: 5×5×48, Conv5: 3×3×12288),最后通过4×4平均池化和展平,输出一个30维的特征向量。关键:这些卷积层的权重更新不使用反向传播,而是基于SoftHebb算法的无监督Hebbian学习(前向传播一次完成训练)。
- 分类头:针对每个新任务(t),实例化一个独立的全连接层(Head_t,输出维度为该任务的类别数)。特征提取器输出的30维向量被送入当前任务的分类头,得到分类结果。分类头通过反向传播进行训练。
- 数据流与交互:对于每个新任务,先使用SoftHebb算法训练(或微调)特征提取器(此时冻结所有分类头),然后冻结特征提取器,用反向传播训练新任务的分类头。训练完成后,存储新分类头。推理时,根据已知的任务标签选择对应的分类头与共享特征提取器组合进行预测。
- 关键设计选择:采用任务增量学习设置(任务标签已知),使问题简化,专注于特征提取器的稳定性保护。Hebbian学习用于特征提取,旨在模拟生物大脑的无监督特征学习;反向传播仅用于训练轻量级的分类头。
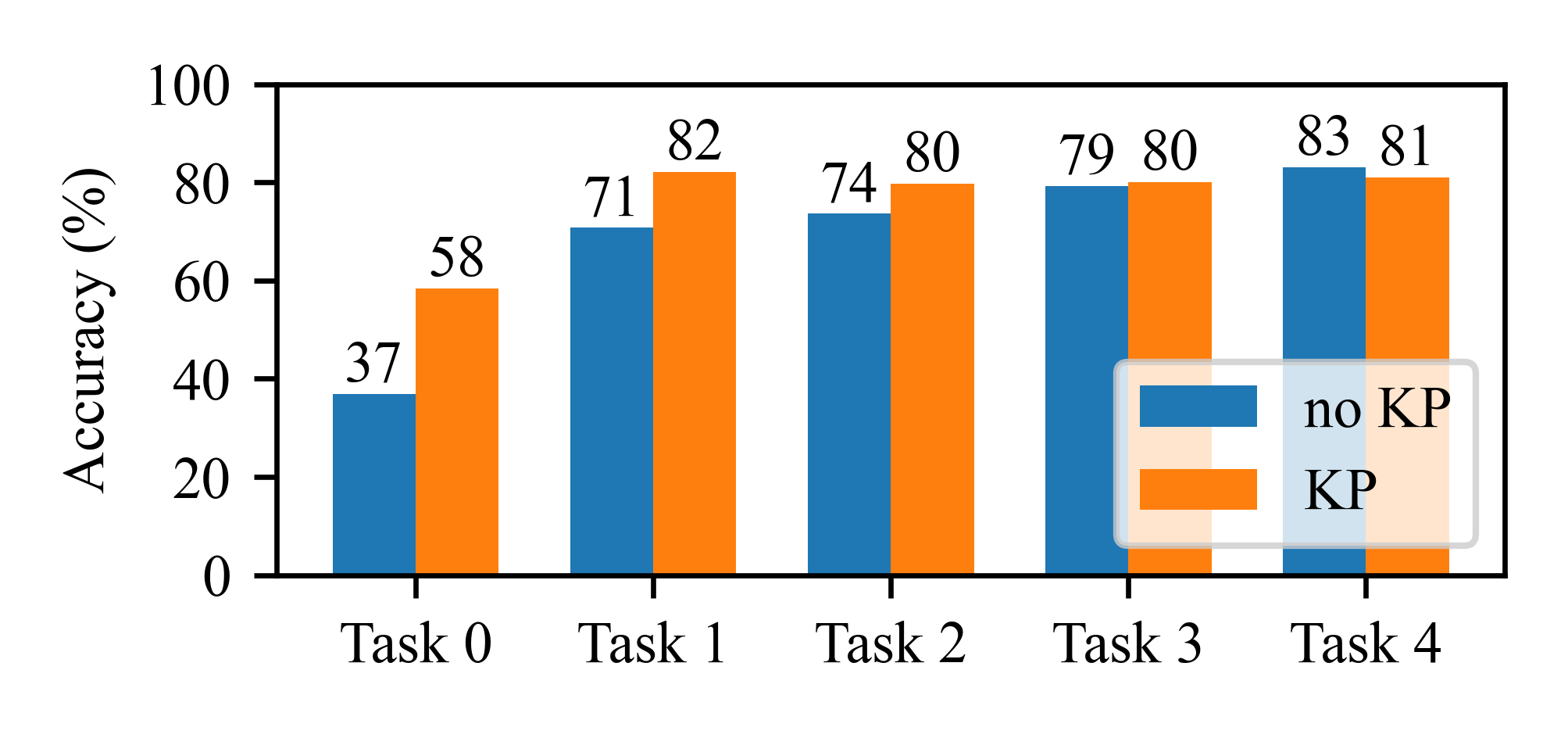 图1展示了所提出的Hebbian卷积网络与任务依赖分类头的架构。左侧为特征提取器,由5个Hebbian卷积层(Hebb Conv1-5)及相应的池化层(MaxPool, AvgPool)组成,最终展平为30维特征。右侧显示了针对不同任务(Task 0, Task t)的独立分类头(Head0, Headt)。
图1展示了所提出的Hebbian卷积网络与任务依赖分类头的架构。左侧为特征提取器,由5个Hebbian卷积层(Hebb Conv1-5)及相应的池化层(MaxPool, AvgPool)组成,最终展平为30维特征。右侧显示了针对不同任务(Task 0, Task t)的独立分类头(Head0, Headt)。
💡 核心创新点
- 将Hebbian学习应用于音频增量学习:这是首次将生物启发的、无监督的Hebbian学习机制引入音频分类的增量学习场景,探索了其作为反向传播替代方案的可能性。
- 提出的“核可塑性”调制机制:这是缓解灾难性遗忘的核心。通过监控每个卷积核的权重更新幅度和累积激活值,识别并保护对当前任务“重要”的核(top K核),同时增强“非重要”核的可塑性。这种选择性调制模拟了神经调节(如多巴胺)的作用,在学习新知识时稳定旧知识。
- 双组件保护策略:分别对存储通用特征表示的特征提取器和存储任务特定决策边界的分类头采取保护。特征提取器采用核可塑性调制,分类头则通过存储独立副本实现天然隔离。
🔬 细节详述
- 训练数据:
- 数据集:ESC-50(环境声分类)。
- 规模:2000个5秒音频片段,50个类别,每类40个样本。
- 划分:使用5折交叉验证,1折测试,1折验证,3折训练。
- 增量设置:划分为5个任务。任务0包含30个随机类别,任务1-4各包含5个随机类别(类别不重叠)。
- 预处理:输入为Log-mel频谱图。
- 损失函数:论文未明确说明分类头训练使用的具体损失函数(如交叉熵),但根据音频分类任务常规,推测为分类交叉熵损失。
- 训练策略:
- 特征提取器:使用SoftHebb算法进行无监督训练,仅进行一个epoch的前向传播。
- 分类头:使用反向传播训练,50个epoch(通过验证集确定)。
- 优化器、学习率:未说明。
- 关键超参数(来自核可塑性调制):
top K(受保护核比例):0.6α(非重要核的可塑性增强因子):0.15 (注意:文中α>1,但此处数值为0.15,可能描述有误或α定义不同)β(重要核的稳定性保护因子):0.9 (0<β<1)- 权重更新监控间隔:每5个batch计算一次。
- 训练硬件:论文提及使用CSC Finland的LUMI超级计算机,但具体GPU型号、数量和训练时长未提供。
- 推理细节:在任务增量学习设置下,推理时提供任务标签,选择对应的分类头与特征提取器组合进行预测。解码策略、温度等未说明。
- 正则化/稳定训练技巧:核心技巧即所提的“核可塑性”调制。此外,网络使用了Batch Normalization。
📊 实验结果
主要结果对比(表1)
| 方法 | 是否使用KP | Task 0 | Task 1 (总体, [旧任务准确率], 新任务准确率) | Task 2 | Task 3 | Task 4 | 总体准确率 |
|---|---|---|---|---|---|---|---|
| EWC Baseline | 否 | 9.5 | 54.5 | 63.5 | 82.5 | 70.5 | 33 |
| TIL (本文方法) | 否 | 60.4 | 70.9 (58.1, 83.7) | 72.7 (67.4, 83.4) | 71.2 (67.2, 83.3) | 68.7 (65.1, 83.0) | 68.7 |
| TIL (本文方法) | 是 | 60.0 | 71.4 (58.0, 84.7) | 74.6 (70.5, 82.6) | 75.8 (73.7, 82.3) | 76.3 (75.0, 81.0) | 76.3 |
| Joint learning | 否 | 60.4 | 57.9 | 57.4 | 57.2 | 58.4 | 58.4 |
| Joint learning | 是 | 60.0 | 58.5 | 56.8 | 54.9 | 54.7 | 54.7 |
| Common head | 否 | - | - | - | - | - | 53.3 |
表1:ESC-50数据集上不同方法的分类精度对比。TIL为任务增量学习。KP为核可塑性。
关键结论:
- 提出的带KP的TIL方法(76.3%)显著优于不带KP的TIL方法(68.7%)和EWC基线(33%)。
- 带KP的TIL方法在后续任务中,对旧任务的准确率保持得更好(如Task 1后对旧任务的准确率为58.0% vs 不带KP的58.0%,但到Task 4后,带KP模型在Task 0上的性能下降幅度远小于不带KP模型,见图2分析)。
- 与同架构的联合学习方法相比,增量学习方法的性能更高,这可能是因为网络架构针对增量学习进行了优化。
增量学习指标(表2)
| 指标 | 是否使用KP | Task 1 | Task 2 | Task 3 | Task 4 |
|---|---|---|---|---|---|
| BWT (后向转移, 越高越好) | 否 | -2.33 | -4.67 | -8.64 | -12.63 |
| 是 | -1.98 | -1.82 | -2.11 | -2.36 | |
| IM (不稳定性度量, 越低越好) | 否 | -25.85 | -25.91 | -26.11 | -24.61 |
| 是 | -26.22 | -25.83 | -27.36 | -26.33 | |
| FM (遗忘度量, 越低越好) | 否 | 2.33 | 1.15 | 1.22 | 1.04 |
| 是 | 1.98 | 0.88 | 0.90 | 0.56 |
表2:增量学习评估指标对比。
- FM (遗忘度量):带KP的模型在所有步骤上都更低,表明知识保留更好。
- BWT (后向转移):带KP的模型值更接近零,表明新任务对旧任务的干扰更小。
- IM (不稳定性度量):两者相近,表明KP在提升稳定性的同时没有显著牺牲学习新任务的能力(可塑性)。
图2(论文描述为Fig. 2)展示了在ESC-50上使用或不使用KP进行增量学习时,各任务(Task 0-4)在最终步骤的准确率对比。KP模型在所有任务(尤其是早期任务)上表现更稳定,而不带KP的模型在早期任务上性能下降显著,表明严重的灾难性遗忘。
⚖️ 评分理由
- 学术质量:7.0/7:论文提出了一个清晰、有生物启发性的技术方案来解决一个公认难题。方法设计有一定新意,实验设置合理,提供了多角度的定量分析。主要扣分点在于实验场景单一(仅ESC-50),且与更强的基线(如更先进的反向传播增量学习方法)对比不足,结论的普适性和优越性证据链有待加强。
- 选题价值:1.5/2:研究方向(音频增量学习)重要且实际。生物启发式路径新颖。但任务(环境声分类)相对垂直,且方法依赖于任务标签,限制了其潜在影响范围和与更广泛读者的相关性。
- 开源与复现加成:0.5/1:提供了代码链接是重大加分项。论文对实验设置和关键超参数有描述。但未提供训练好的模型权重、详细的运行环境配置和更深入的复现指南,扣分。