📄 InconVAD: A Two-Stage Dual-Tower Framework for Multimodal Emotion Inconsistency Detection
#语音情感识别 #多模态模型 #不确定性估计
✅ 7.5/10 | 前25% | #语音情感识别 | #多模态模型 | #不确定性估计
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Zongyi Li(南洋理工大学,跨学科研究生项目)
- 通讯作者:未说明
- 作者列表:Zongyi Li(南洋理工大学,跨学科研究生项目),Junchuan Zhao(新加坡国立大学,计算学院),Francis Bu Sung Lee(南洋理工大学,计算与数据科学学院),Andrew Zi Han Yee(南洋理工大学,Wee Kim Wee传播与信息学院)
💡 毒舌点评
亮点在于其“显式不一致性检测+选择性融合”的第二阶段设计非常精巧,直指当前多模态融合“无脑拼接”的痛点,并在实验上证明了其有效性。短板则是为了构建不一致样本,依赖了EmoV-DB数据集的人工语音-文本配对,这种合成数据构造的不一致性能否完全代表真实世界(如自然对话中的复杂讽刺、掩饰)中的不一致性,需要打一个问号。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及公开模型权重。
- 数据集:使用了公开数据集IEMOCAP、EmoBank、EmoV-DB和MUStARD,但未提供其构造的不一致性数据对的获取方式。
- Demo:未提及在线演示。
- 复现材料:论文给出了较详细的训练细节(如优化器、学习率、批大小、早停策略)、网络结构参数和损失函数设计,为复现提供了理论基础。
- 论文中引用的开源项目:主要依赖的预训练模型包括Wav2Vec2-base、RoBERTa-base。使用的工具/库包括Torchaudio(用于韵律特征提取)。
📌 核心摘要
- 问题:多模态情感分析中,语音与文本信号常包含不一致的情感线索(如讽刺),现有方法依赖不完整的情感表示(如离散标签)且默认模态一致进行无条件融合,导致性能下降。
- 方法核心:提出InconVAD,一个两阶段双塔框架。第一阶段(Phase A)训练两个独立的、具备不确定性感知的单模态塔(语音塔、文本塔),在共享的三维情感空间(VAD:效价-唤醒-支配)中预测情感值。第二阶段(Phase B)首先用一个分类器显式检测输入语音-文本对的情感不一致性,然后仅对被判定为“一致”的配对,通过一个门控Transformer融合模块整合两塔输出,进行最终的VAD预测。
- 新意:区别于以往工作,InconVAD显式地将“不一致性检测”作为中间任务,并利用不确定性估计在融合前进行质量评估,最后采用选择性融合策略,避免了不一致信息在融合时造成的表示混淆。
- 实验结果:在情感不一致性检测任务上,InconVAD分类器在IEMOCAP+EmoV-DB构建的测试集上达到92.3%的准确率和92.2%的F1分数,显著超越了SVM (85.7% Acc)和ATEI (83.4% Acc)等基线。在多模态情感建模任务上,其融合塔在IEMOCAP数据集上的平均CCC达到0.657,优于现有方法MFCNN14 (0.642)和W2v2-b+BERT-b+L (0.618)。消融实验证明了各组件(如韵律注入、Conformer块、门控融合)的有效性。
- 实际意义:该工作为构建更可靠、可解释的情感计算系统提供了新思路,尤其适用于需要精确理解用户真实情感意图的场景,如心理健康监测、智能客服、人机交互。
- 局限性:主要依赖于特定数据集(IEMOCAP, EmoBank, EmoV-DB)构建和评估,其在更广泛语种、文化背景下的泛化能力未验证。模型的计算开销和实时性未被分析,可能限制在资源受限设备上的部署。不一致样本的构造方式(基于数据集配对)可能无法完全覆盖现实世界中的复杂情况。
🏗️ 模型架构
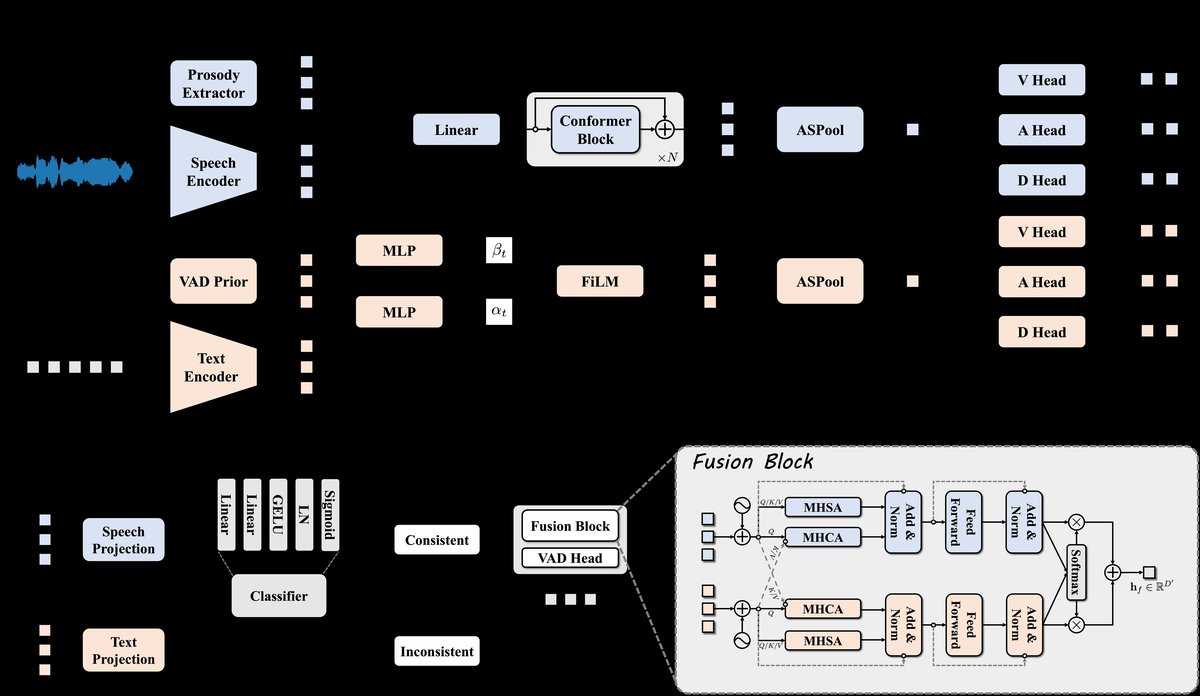 InconVAD是一个两阶段框架,整体架构如图1所示。
InconVAD是一个两阶段框架,整体架构如图1所示。
第一阶段(Phase A:单模态VAD预训练):
- 语音塔:输入原始语音波形。首先使用预训练的Wav2Vec2-base模型提取帧级声学嵌入(Hs)。同时,使用一个韵律提取器计算基频(F0)和能量(log-RMS)特征。将声学嵌入与韵律特征拼接并投影,形成融合输入(Hin)。接着,通过两个Conformer块(结合了自注意力与卷积,用于捕捉局部动态和长程依赖)处理该序列。最后,通过注意力统计池化(ASPool) 模块聚合为固定维度的句子级嵌入(hs)。最终的预测头输出VAD三维度的均值(μs)和对数方差(logσ²s),实现不确定性感知的单模态预测。
- 文本塔:输入文本标记序列。使用预训练的RoBERTa-base编码器(fTE(·))提取上下文嵌入(Ht)。为注入显式情感知识,使用NRC VAD词典v2(fPrior(·))为每个标记生成情感先验向量(pt)。通过FiLM层(一种条件归一化技术)将先验知识与编码器输出融合,得到门控表示(H′t)。同样经过ASPool聚合为句子级嵌入(ht),并由预测头输出μt和logσ²t。
- 设计动机:每个塔独立学习其模态在VAD空间中的特征,不确定性估计(输出方差)允许模型在后续阶段“知道”自身预测的可靠程度。
第二阶段(Phase B:不一致性检测与门控融合):
- 不一致性检测分类器:取第一阶段两个塔输出的中间表示(H′s, H′t),通过轻量级投影器(fSP, fTP)映射到共享潜在空间(˜Hs, ˜Ht)。将两个序列拼接后,送入一个由两个线性层、GELU激活、LayerNorm和Sigmoid输出组成的二元分类器(fC),预测不一致性分数(pinc ∈ [0,1])。
- 融合模块:该模块仅在分类器判定为“一致”(y=1)的语音-文本对上激活。它首先设计了一个Transformer块来建模模态内(MHSA)和模态间(MHCA)的依赖关系,生成模态特定的上下文化表示(fs, ft)。然后,通过一个门控多模态融合机制动态整合信息:为每个模态的表示计算一个可学习的权重向量,通过softmax得到时间步级别的门(gs, gt),最终融合表示(hf)是模态特征的加权和。
- 数据流:原始输入 -> 第一阶段得到单模态VAD预测和不确定性 -> 第二阶段:a) 分类器判断是否一致;b) 若一致,则融合两塔信息得到更优的VAD预测(yf);若不一致,可能仅使用更可靠模态的预测(论文未明确说明此时的输出策略)。
💡 核心创新点
- 不确定性感知的单模态VAD预测:首次在多模态情感分析中,为语音和文本塔引入异方差回归框架(输出预测方差),量化各模态预测自身的不确定性。这为后续的不一致性判断和选择性融合提供了可靠依据。
- 显式的跨模态不一致性检测与选择性融合:不同于将不一致性视为融合的副产品,本框架设计了一个专门的分类器来显式预测模态间是否一致,并仅在一致时激活复杂的融合模块。这有效防止了不一致信息在融合过程中造成表示“污染”。
- 共享三维VAD空间设计:所有组件(语音塔、文本塔、融合塔)都在连续的Valence-Arousal-Dominance空间进行预测和对齐。这比离散情感标签更细粒度、连续,且为不同模态提供了统一的、可比较的表示基础。
- 两阶段解耦训练与复合损失策略:第一阶段专注于单模态特征学习,第二阶段专注于不一致性判断和融合。第二阶段训练中,分类器使用BCE损失+边际损失(拉近一致对、推远不一致对);融合塔在有标签数据上用高斯NLL损失,在无标签数据上用一致性损失,实现了有效的半监督式训练。
🔬 细节详述
- 训练数据:
- Phase A语音塔:IEMOCAP数据集(VAD标注)。
- Phase A文本塔:EmoBank数据集(VAD标注)。
- Phase B不一致性分类器:使用IEMOCAP(配对的语音-文本作为一致对)和EmoV-DB(用中性文本与非中性语音配对构造不一致对)构建二分类数据。
- Phase B融合塔:仅使用一致对(来自IEMOCAP和EmoV-DB的中性语音-文本对)进行训练。
- 数据预处理:为对齐不同数据集的VAD标签分布,应用了基于Beta CDF的参数化分布对齐变换(公式10)。
- 损失函数:
- 单模态预测(Phase A & 融合塔有标签时):高斯负对数似然损失(Gaussian NLL)(公式3),同时优化均值和方差。
- 不一致性分类器:二元交叉熵损失(LBCE) + 边际损失(Lmargin)(公式6,7)。边际损失(margin m=0.9,权重λ=0.15)通过欧氏距离d = ||˜Hs - ˜Ht||₂,在潜在空间中拉开不一致对(y=0)、拉近一致对(y=1)。
- 融合塔无标签时:选择性一致性损失(Lagree)(公式8,9),鼓励融合预测与根据两塔预测(μs, σ²s; μt, σ²t)计算出的高斯共识目标(μagree, σ²agree)对齐。
- 训练策略:
- Phase A:AdamW优化器。语音/文本骨干网络学习率2e-5,预测头学习率1e-4。批大小16,最多50个epoch,早停耐心值5。使用余弦学习率调度和10%的warmup。权重衰减0.01。Gaussian NLL损失中设置最小方差为2e-3。
- Phase B分类器:冻结两个塔,仅训练分类器头。学习率1e-3,批大小32,最多50个epoch,早停耐心值5。
- Phase B融合塔:学习率1e-4,批大小16,余弦调度+warmup。
- 关键超参数:骨干网络为Wav2Vec2-base和RoBERTa-base(隐藏维度768)。投影层和ASPool后维度均为256。Conformer块数量为2。门控融合使用可学习权重矩阵Ws, Wt ∈ R^{D’×D’}。
- 训练硬件:论文中未提及具体的GPU/TPU型号、数量及训练时长。
- 推理细节:论文中未提及解码策略、温度、beam size等推理细节,因为本任务不涉及生成。对于分类任务,使用基于验证集最大化Youden’s J准则确定的固定阈值τ*。
- 正则化或稳定训练技巧:使用了LayerNorm、权重衰减、早停、warmup等标准技巧。ASPool本身也具有一定的特征选择正则化效果。
📊 实验结果
论文在两个主要任务上进行了评估:多模态情感不一致性检测和多模态情感建模(VAD预测)。
表1. 多模态情感建模(VAD预测)结果对比(指标:CCC)
| 方法 | V | A | D | Avg |
|---|---|---|---|---|
| Ours (Speech Tower) | 0.639 | 0.669 | 0.541 | 0.616 |
| Ours (Text Tower) | 0.784 | 0.419 | 0.443 | 0.549 |
| Dimensional MTL [23] | 0.446 | 0.594 | 0.485 | 0.508 |
| Two-stage SVM [24] | 0.595 | 0.601 | 0.499 | 0.565 |
| RL-MT [25] | 0.648 | 0.668 | 0.537 | 0.618 |
| MFCNN14 [26] | 0.714 | 0.639 | 0.575 | 0.642 |
| W2v2-b + BERT-b + L [27] | 0.625 | 0.661 | 0.570 | 0.618 |
| Ours (Fusion Tower) | 0.741 | 0.644 | 0.586 | 0.657 |
- 关键结论:InconVAD的融合塔在平均CCC上达到0.657,超越了所有对比的基线方法。单模态塔的性能也具竞争力,尤其在Valence维度上。这证明了其双塔设计和门控融合的有效性。
表2. 情感不一致性检测结果对比
| 方法 | Accuracy | F1-Score | Precision | Recall |
|---|---|---|---|---|
| SVM [28] | 85.7 | 86.4 | 80.3 | 93.6 |
| ATEI [2] | 83.4 | 83.6 | 82.2 | 85.0 |
| Ours (Classifier) | 92.3 | 92.2 | 93.6 | 90.9 |
- 关键结论:InconVAD分类器在准确率和F1分数上大幅领先现有方法(SVM和ATEI),达到了92%以上的水平,证明其能有效捕捉语音与文本间的不一致性。此外,在MUStARD数据集(包含自然讽刺)上的零样本和微调测试中,F1分数分别达到0.819和0.847,展示了良好的泛化能力。
表3. 消融实验结果(指标:CCC)
| 方法(移除组件) | V | A | D | Avg |
|---|---|---|---|---|
| 语音塔 | ||||
| w/o Prosody Injection | 0.608 | 0.634 | 0.514 | 0.585 |
| w/o Conformer Blocks | 0.592 | 0.661 | 0.499 | 0.584 |
| w/o Attentive Statistics Pooling | 0.627 | 0.654 | 0.556 | 0.612 |
| Ours (Speech Tower) | 0.639 | 0.669 | 0.541 | 0.616 |
| 文本塔 | ||||
| w/o Affect Prior Gating | 0.776 | 0.447 | 0.406 | 0.543 |
| w/o Attentive Statistics Pooling | 0.778 | 0.426 | 0.435 | 0.546 |
| Ours (Text Tower) | 0.784 | 0.419 | 0.443 | 0.549 |
| 融合塔 | ||||
| w/o Transformer Block | 0.706 | 0.664 | 0.554 | 0.641 |
| w/o Gated Multimodal Fusion | 0.720 | 0.622 | 0.534 | 0.625 |
| Ours (Fusion Tower) | 0.741 | 0.644 | 0.586 | 0.657 |
- 关键结论:消融实验表明,每个设计组件都有贡献。对于语音塔,Conformer块和韵律注入对提升性能最关键。对于文本塔,情感先验门控(FiLM层)提升了唤醒度和支配度的预测。对于融合塔,Transformer块和门控融合机制的移除均导致性能明显下降,验证了其建模跨模态交互和动态加权的重要性。
⚖️ 评分理由
- 学术质量:6.0/7:论文的创新点(显式不一致性建模、不确定性感知融合)设计精巧,技术实现正确且详尽。实验对比充分,包含主任务对比、跨数据集泛化测试(MUStARD)和大量消融研究,证据链完整、可信。扣分主要源于未探讨模型复杂度与推理效率,这对于评估其实际应用潜力至关重要。
- 选题价值:1.5/2:多模态情感不一致性检测是情感计算中一个具体但重要的子问题,对理解人类复杂情感表达(如讽刺、掩饰)有直接价值。该研究提供了系统性的解决方案,对相关领域(如心理健康AI、情感智能交互)有积极影响。应用空间明确但相对垂直。
- 开源与复现加成:0.0/1:论文详细描述了模型架构、超参数和训练策略,具有较高的理论可复现性。然而,未提供任何代码、预训练模型或数据集的获取链接,这极大地增加了社区复现的门槛,因此此项不加分。