📄 Improving Multimodal Brain Encoding Model with Dynamic Subject-Awareness Routing
#多模态模型 #脑信号编码 #混合专家 #动态路由 #跨被试泛化
🔥 8.0/10 | 前25% | #脑信号编码 | #混合专家 | #多模态模型 #动态路由
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 中
👥 作者与机构
- 第一作者:Xuanhua Yin(悉尼大学计算机科学学院)
- 通讯作者:Runkai Zhao(悉尼大学计算机科学学院)和 Weidong Cai(悉尼大学计算机科学学院)
- 作者列表:Xuanhua Yin(悉尼大学计算机科学学院)、Runkai Zhao(悉尼大学计算机科学学院)、Weidong Cai(悉尼大学计算机科学学院)
💡 毒舌点评
亮点:论文巧妙地将混合专家模型中的“门控”从单一输入驱动,改造为融合了稳定“被试先验”和动态“令牌上下文”的双路径路由,这一设计在解决跨被试异质性问题上既直观又有效,且实验验证了其相对于单一路由方式的优越性。短板:整个惊人的性能提升(如在ImageBind上r从0.131提升至0.221)完全建立在“Algonauts 2025”这一个基准和仅4名被试上,在未见数据集或更多被试上效果如何存在疑问,这削弱了其宣称的“通用性”和实际影响力。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及公开权重。
- 数据集:使用公开的Algonauts 2025数据集,但论文中未提供具体获取链接或说明。
- Demo:未提供在线演示。
- 复现材料:论文提供了一些训练细节(如优化器AdamW、调度器OneCycle、数据窗口设置),但缺失关键超参数(如学习率、批次大小、专家数量E和K值、隐藏维度D)和硬件信息,复现材料不充分。
- 引用的开源项目:论文引用了多个开源模型和框架作为骨干网络或基线,包括TRIBE [9]、ImageBind [10]、Qwen2.5-Omni [11] 和 MMoE [23]。
- 总体:论文中未提及任何开源计划。
📌 核心摘要
- 要解决的问题:在多模态(视、听、文)fMRI脑编码任务中,相同的刺激在不同被试中会引发系统性的神经响应差异(即跨被试变异性)。传统的群体级解码器难以捕捉这种个性化差异,导致泛化能力差。
- 方法核心:提出AFIRE(无关多模态fMRI响应编码框架)和MIND(混合专家集成解码器)。AFIRE作为一个标准化接口,将不同多模态编码器(如TRIBE, ImageBind)的输出转换为时间对齐的后融合令牌。MIND则是一个稀疏混合专家网络,其核心是SADGate(主题感知动态门控),该门控结合了基于当前令牌的动态路由和学习的被试特异性先验,并通过Top-K稀疏选择激活少数专家进行预测。
- 与已有方法相比新在哪里:1) 解耦设计:AFIRE将上游多模态融合与下游解码分离,使MIND解码器可以“即插即用”于不同编码器。2) 个性化路由:SADGate首次在脑编码中引入结合了稳定被试先验和动态令牌信息的稀疏路由机制,更精细地建模了被试间差异的“静态”和“动态”成分。
- 主要实验结果:在Algonauts 2025数据集上,使用三种不同骨干网络(TRIBE, ImageBind, Qwen2.5-Omni)进行评估。MIND解码器在所有指标上均优于强基线。具体性能提升如下表所示(均值,跨S1-S5被试):
| 骨干网络 | 方法 | Pearson r | Spearman ρ | R² | ISG |
|---|---|---|---|---|---|
| TRIBE | Baseline | 0.256 | 0.240 | 0.081 | 0.187 |
| w. MIND | 0.273 | 0.259 | 0.092 | 0.241 | |
| Δ (vs. Baseline) | +0.017 | +0.019 | +0.011 | +0.054 | |
| ImageBind | Baseline | 0.131 | 0.121 | 0.026 | 0.097 |
| w. MIND | 0.221 | 0.203 | 0.064 | 0.162 | |
| Δ (vs. Baseline) | +0.090 | +0.082 | +0.038 | +0.065 | |
| Qwen2.5-Omni | Baseline | 0.125 | 0.130 | 0.025 | 0.103 |
| w. MIND | 0.220 | 0.205 | 0.059 | 0.162 | |
| Δ (vs. Baseline) | +0.095 | +0.075 | +0.034 | +0.059 |
消融实验证明了“令牌路由器”和“先验路由器”结合的必要性,二者单独使用效果均不佳。 5. 实际意义:提供了一个模块化、可扩展的框架,使得可以快速集成新的多模态编码器来提升脑编码性能,并为理解大脑如何个性化处理多模态信息提供了计算模型和可解释的专家路由模式。 6. 主要局限性:1) 实验规模有限(仅一个数据集,4名被试),结论的普适性有待验证。2) 性能高度依赖上游编码器输出的“后融合令牌”质量。3) 引入混合专家模型增加了推理时的计算成本。
🏗️ 模型架构
本文的模型架构分为两大部分:AFIRE框架和MIND解码器,如图2所示。
- AFIRE:无关多模态fMRI响应编码框架
- 功能与目标:作为标准化接口,将来自不同多模态编码器(视频、音频、文本编码器)的异构特征,转换为统一的、时间对齐的令牌序列,供下游解码器使用。其核心价值在于“解耦”,使得下游解码器无需关心上游使用了何种融合方式。
- 内部结构与数据流:
- 输入:从多个编码器获取的、每层每模态的特征。
- 特征投影与融合:通过一个轻量级投影器将这些异构特征映射到一个共享的令牌空间。随后,使用一个融合操作符(具体未详述,如拼接、加权和等)将不同模态的特征合并为单个令牌流。
- 时间建模:应用一个带有位置编码和层归一化的时序MLP模块,捕捉相邻令牌(对应连续时间步TR)之间的短程依赖关系。
- 输出:标准化的后融合令牌序列
{zt}_{t=1}^{T},其中zt ∈ R^D,每个令牌对应一个fMRI采集时间点(TR)。
- 关键设计选择:引入位置编码和时序MLP,是为了在保持框架“无关性”(不依赖特定编码器结构)的同时,补偿从编码器的采样率(如2Hz)到fMRI采样率(TR)的聚合过程,并建模必要的时间动态。
- MIND:混合专家集成解码器
(同图2,参见上图b部分)
- 功能与目标:接收AFIRE输出的标准令牌
{zt},预测每个时间点t对应的全脑fMRI响应(即O个脑区的活动值,如1000个Schaefer分区)。 - 核心组件:
- 专家网络:包含
E个独立的多层感知机(MLP)专家fe: R^D → R^O。每个专家学习一种映射模式。 - SADGate:主题感知动态门控:这是MIND的核心创新,负责为每个令牌和每个被试计算专家混合权重。
- 令牌路由器:将当前令牌
zt与当前被试s的可学习嵌入esubj(s)相加,通过一个线性层和softmax,得到反映瞬时刺激上下文和时间线索的路由权重pt。 - 主题先验路由器:维护一个全局的专家logit向量
α和一个被试-专家偏差矩阵B。通过π(s) = softmax(α + B_{s,:})计算出反映该被试长期、稳定的专家偏好的先验权重。 - 稀疏路由:将
pt和π(s)进行逐元素相乘,然后应用 Top-K 选择(保留权重最大的K个专家),最后归一化,得到最终权重ŵt。这确保了每个令牌只激活少数专家(稀疏性),同时融合了动态和静态信息。
- 令牌路由器:将当前令牌
- 预测输出:根据公式
yt = Σ_{e=1}^{E} ŵt,e * fe(zt),将激活的专家输出进行加权求和,得到最终的全脑预测yt ∈ R^O。
- 专家网络:包含
组件交互:AFIRE的输出令牌 zt 被同时送入MIND的“专家网络”和“SADGate的令牌路由器”。SADGate结合了被试ID信息和令牌信息,生成稀疏的专家权重,用于调制专家网络的输出。整个流程(包括AFIRE投影器、路由器、专家网络)是端到端联合训练的。
💡 核心创新点
解耦的、无关融合的接口(AFIRE):
- 局限:以往方法通常将特定的多模态编码器(如TRIBE)与解码器紧密耦合,更换编码器需要重新设计或训练整个系统。
- 创新:AFIRE定义了一个标准化的“令牌”中间表示,使得任何多模态编码器只需将其输出适配为这个格式,即可与同一个强大的解码器MIND对接。
- 收益:实现了“即插即用”,显著提升了框架的通用性和可扩展性,降低了实验新编码器的门槛。
结合主题先验与动态令牌的稀疏路由(SADGate):
- 局限:传统的混合专家门控仅依赖输入(令牌)进行路由,忽略了被试间固有的、持久的差异;而简单的群体级模型或静态对齐方法又无法捕捉动态的个性化融合模式。
- 创新:SADGate将路由分解为“稳定先验” (
π(s)) 和“动态适应” (pt) 两部分,并通过稀疏Top-K将它们融合。先验捕获被试的基线专家偏好(如某些脑区组合对视觉更敏感),动态部分根据当前刺激内容微调。 - 收益:在表2的消融实验中,“两者结合”的路由方式在三个骨干网络上均取得最佳性能,证明了两种信息的互补性,实现了个性化与泛化的更好平衡。
面向跨被试泛化的评估与设计:
- 局限:许多脑编码模型仅优化被试内预测,忽略了对新被试的泛化能力。
- 创新:论文明确将“跨被试泛化”(ISG)作为核心评估指标之一,并在MIND的设计中(通过可学习的被试嵌入和偏差)直接对建模被试间差异进行优化。
- 收益:MIND在ISG指标上取得了最大幅度的提升(如在TRIBE上从0.187提升到0.241),表明该方法确实增强了模型对未见被试的预测能力。
🔬 细节详述
训练数据:
- 数据集:Algonauts 2025挑战赛数据集。包含多部电视剧片段作为刺激,同时采集被试观看时的视频、音频、文本(字幕)特征以及对应的fMRI响应。
- 规模与预处理:评估使用4名被试(S1, S2, S3, S5)。特征采样率为2Hz,fMRI为TR分辨率。将2Hz的特征在每个TR时间窗内进行平均,以实现时间对齐。fMRI信号使用Schaefer图谱分割为1000个脑区。
- 数据划分:采用按被试、按剧集分层的90%训练/10%验证划分。每个样本为一个连续的100个TR的窗口,窗口步长为50个TR。
- 数据增强:论文中未提及。
损失函数: 主要损失为均方误差(MSE)重建损失 (
Lrec),用于衡量预测fMRI响应与真实响应之间的差异。总损失 (L) 还包括两项正则化:- 负载均衡损失 (
Rlb):防止专家被过度使用或闲置,保持专家负载均衡。具体计算基于专家重要性(所有令牌分配给该专家的权重之和)和专家负载(有多少令牌被分配给了该专家)。 - L2正则化:对主题-专家偏差矩阵
B进行L2范数惩罚 (λ * ||B||^2),约束主题特异性偏移,防止过拟合。 公式:L = Lrec + β Rlb + λ ||B||^2。权重β和λ是标量超参数。
- 负载均衡损失 (
训练策略:
- 优化器:AdamW。
- 学习率调度:使用OneCycle调度器。峰值学习率和权重衰减通过验证集网格搜索确定。
- 其他:论文中未明确说明学习率具体数值、batch size、训练总步数或轮数。
关键超参数:
- 专家数量 (
E):论文中未明确说明。 - 每令牌激活专家数 (
K):论文中未明确说明。 - AFIRE令牌维度 (
D):论文中未明确说明。 - 输出脑区数量 (
O):1000(基于Schaefer图谱)。 - 主题嵌入维度:与AFIRE令牌维度
D相同。
- 专家数量 (
训练硬件:论文中未提及。
推理细节:
- 在验证时,模型使用训练好的权重进行前向传播,输出每个TR的预测fMRI响应向量。
- 对于跨被试泛化(ISG)评估,采用“留一法”,即在3名被试上训练,在第4名被试上测试。
- 论文中未提及是否使用了温度、beam size等解码策略,因为这是回归任务而非生成任务。
正则化或稳定训练技巧:
- 除了上述的负载均衡损失和L2正则化,还使用了稀疏Top-K路由,这本身就是一种正则化,鼓励模型学习稀疏且可解释的专家组合。
- 时序MLP中的层归一化也有助于稳定训练。
📊 实验结果
本文的实验在Algonauts 2025基准上,使用三个不同的多模态融合骨干网络进行。关键结果汇总在表1中。
主实验结果(表1):
| 方法 | Pearson r | Spearman ρ | R² | ISG |
|---|---|---|---|---|
| TRIBE | ||||
| TRIBE (Baseline) | 0.256 | 0.240 | 0.081 | 0.187 |
| w. MLP Decoder | 0.247 | 0.228 | 0.069 | 0.189 |
| w. MMoE Decoder | 0.267 | 0.252 | 0.087 | 0.198 |
| w. MIND | 0.273 | 0.259 | 0.092 | 0.241 |
| Δ (vs. Baseline) | +0.017 | +0.019 | +0.011 | +0.054 |
| ImageBind | ||||
| ImageBind (Baseline) | 0.131 | 0.121 | 0.026 | 0.097 |
| w. MLP Decoder | 0.139 | 0.120 | 0.027 | 0.139 |
| w. MMoE Decoder | 0.198 | 0.181 | 0.052 | 0.147 |
| w. MIND | 0.221 | 0.203 | 0.064 | 0.162 |
| Δ (vs. Baseline) | +0.090 | +0.082 | +0.038 | +0.065 |
| Qwen2.5-Omni | ||||
| Qwen2.5-Omni (Baseline) | 0.125 | 0.130 | 0.025 | 0.103 |
| w. MLP Decoder | 0.140 | 0.132 | 0.031 | 0.144 |
| w. MMoE Decoder | 0.201 | 0.183 | 0.049 | 0.144 |
| w. MIND | 0.220 | 0.205 | 0.059 | 0.162 |
| Δ (vs. Baseline) | +0.095 | +0.075 | +0.034 | +0.059 |
关键结论:
- MIND在所有骨干网络上均显著优于单路径的MLP解码器和输入驱动的MMoE解码器。
- 在性能较弱的骨干网络(ImageBind, Qwen2.5-Omni)上,MIND带来的绝对提升更大(如r提升0.09左右),而在较强的TRIBE上提升相对较小(r提升0.017),说明MIND作为通用解码器在“提升短板”方面效果显著。
- 跨被试泛化(ISG) 的提升是MIND最突出的贡献之一,尤其在TRIBE上提升达0.054,表明其有效建模了被试间差异。
消融实验(表2):
| Router Types | TRIBE | ImageBind | Qwen2.5-Omni |
|---|---|---|---|
| Only Token Router | 0.176 | 0.131 | 0.107 |
| Only Prior Router | 0.248 | 0.205 | 0.173 |
| Both | 0.273 | 0.221 | 0.220 |
关键结论:单独使用令牌路由器或先验路由器性能均远低于两者结合,证实了SADGate中双路径设计的必要性。
可视化分析:
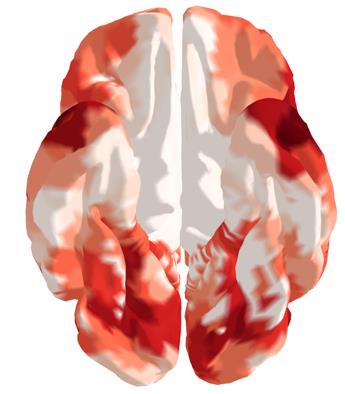 图3:不同骨干网络(TRIBE, ImageBind, Qwen2.5-Omni,均使用MIND解码)在同一剧集上的逐体素预测-测量相关性(Pearson r)图。三者显示出相似的空间模式和高相关区域重叠,支持了AFIRE框架的融合无关性和MIND解码器的即插即用性。
图3:不同骨干网络(TRIBE, ImageBind, Qwen2.5-Omni,均使用MIND解码)在同一剧集上的逐体素预测-测量相关性(Pearson r)图。三者显示出相似的空间模式和高相关区域重叠,支持了AFIRE框架的融合无关性和MIND解码器的即插即用性。
 图4:被试路由动态(前100个TR)。展示了同一剧集下,S1, S2, S3, S5四位被试的专家权重随时间变化的曲线。不同颜色代表不同专家。曲线差异表明MIND成功捕捉到了基于被试先验和当前令牌内容的个性化、动态的专家偏好模式。
图4:被试路由动态(前100个TR)。展示了同一剧集下,S1, S2, S3, S5四位被试的专家权重随时间变化的曲线。不同颜色代表不同专家。曲线差异表明MIND成功捕捉到了基于被试先验和当前令牌内容的个性化、动态的专家偏好模式。
⚖️ 评分理由
学术质量:6.5/7
- 创新性:提出AFIRE框架和SADGate门控机制,为解决多模态脑编码中的跨被试差异和编码器-解码器耦合问题提供了新颖且有效的方案。
- 技术正确性:方法原理清晰,模型构建合理,损失函数设计符合任务特点,并包含了必要的正则化手段。
- 实验充分性:在给定条件下,实验设计非常全面,包括了多个强基线对比、详细的消融研究、以及空间模式和路由动态的可视化分析,有力支撑了论文的论点。
- 证据可信度:实验设置透明(数据集、划分、指标),结果以具体数值呈现,且在三个不同骨干网络上得到一致结论,可信度较高。
选题价值:1.5/2
- 前沿性:处于多模态表征学习、神经编码和个性化AI模型的交叉前沿,研究问题具有科学挑战性。
- 潜在影响:为构建更准确、更泛化的脑-计算机接口模型奠定了基础,也促进了对大脑多模态信息整合机制的计算建模研究。
- 读者相关性:对于从事脑信号分析、跨模态学习和混合专家模型的研究者有直接参考价值。对于更广泛的语音/音频领域读者,其动态路由的思想具有启发性,但具体任务关联度一般。
开源与复现加成:0.0/1
- 论文未提供代码、预训练模型、数据集链接或完整的超参数配置列表,使得其他研究者难以复现其结果。因此,在此维度上无法获得加分。