📄 Improving Audio Event Recognition with Consistency Regularization
#音频事件检测 #数据增强 #自监督学习 #Transformer #低资源
✅ 7.0/10 | 前25% | #音频事件检测 | #数据增强 | #自监督学习 #Transformer
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Shanmuka Sadhu (Rutgers University, Dept. of Computer Science)
- 通讯作者:未明确标注,但从单位排序和邮箱推测,Weiran Wang可能为指导作者。
- 作者列表:Shanmuka Sadhu(Rutgers University, Dept. of Computer Science)、Weiran Wang(University of Iowa, Dept. of Computer Science)
💡 毒舌点评
亮点: 论文将一致性正则化从语音识别成功迁移到音频事件识别,并通过极其扎实的消融研究(针对不同数据集规模、不同增强策略、不同损失系数)系统地验证了方法的有效性和边界条件,实验部分工作量饱满,结论可靠。
短板: 核心方法(CR)并非原创,迁移痕迹较重,创新性主要体现在应用领域和实验验证的广度上,缺乏对“为何CR在音频事件识别上有效”的更深层机制探讨或理论分析。
🔗 开源详情
- 代码:是,论文明确提供了GitHub仓库链接:https://github.com/shanmukasadhu/ModifiedAudioMAE
- 模型权重:论文中未提及是否公开预训练或训练后的模型权重。
- 数据集:AudioSet为公开数据集,但论文中未提供获取或预处理脚本的具体链接。
- Demo:未提及。
- 复现材料:提供了代码仓库,但论文正文未详细说明复现所需的全部配置文件、超参数设置脚本或硬件要求。训练细节(如学习率、epoch)在论文中给出。
- 论文中引用的开源项目:引用了AudioMAE [11](其预训练检查点用作初始化),以及Kaldi-compatible fbank特征计算工具。
📌 核心摘要
问题: 音频事件识别(AER)任务中,如何进一步提升模型泛化能力,尤其是在标注数据有限(如20k样本)或半监督场景下。
方法核心: 将一致性正则化(Consistency Regularization, CR)引入AER。其核心是模型对同一输入音频的不同增强视图(Augmented Views)的预测应保持一致,通过最小化这些视图预测间的KL散度来实现。该方法可自然扩展至多个增强视图和半监督学习。
新意: 首次将CR-CTC的思路应用于基于音频谱图的多标签AER任务。新意在于方法的适配与扩展:1) 将CR与Mixup、SpecAugment、Random Erasing等音频/视觉增强组合;2) 探索了多于两个增强视图的CR;3) 将CR无缝扩展至半监督学习,对无标签数据也施加一致性约束。
主要结果: 在AudioSet数据集上,在20k小监督集设置下,所提方法将基线mAP从37.9提升至39.6(相对提升4.5%),半监督训练进一步提升至40.1。在1.8M大训练集设置下,将基线mAP从44.7提升至46.9(相对提升4.9%)。关键消融实验如下表所示:
实验设置 (AS-20k) 变化条件 最佳结果 (mAP) 增益 基础CR系数λ 从0增至2.0 35.8 +1.1 加入Mixup (μ=0.5) 在λ=2.0基础上 35.8 -> 35.8 +0.6 (相比无Mixup) 加入Random Erasing (p=0.25) 在λ=2.0, Mixup=0.5基础上 36.0 +0.2 增加增强视图数 (k=6) 在上述最佳基础上 36.2 +0.2 实际意义: 提供了一种简单、有效且可扩展的正则化技术,能稳定提升AER模型性能,尤其适用于标注数据稀缺的场景,具有实用价值。
局限性: 方法的创新主要在于应用和系统性验证,而非提出全新理论或架构。论文中部分超参数(如Random Erasing的参数)在2M数据集上无效,表明方法的普适性仍有边界,需要针对性调整。
🏗️ 模型架构
模型架构基于AudioMAE,核心是用于特征提取的编码器,以及引入的一致性正则化损失。
输入与特征提取:输入为10秒音频,通过Torchaudio计算得到Kaldi兼容的Fbank特征(谱图)。谱图被视为图像输入到Vision Transformer (ViT) 编码器。
编码器(ViT-B):采用12层的ViT-B Transformer模型,共88.9M参数。其权重初始化自AudioMAE在AudioSet 2M上的预训练检查点(以重建被遮蔽的音频块为目标)。训练时,随机丢弃20%的补丁(Patches),延续了MAE的训练范式。
输出与预测:ViT编码器输出全局表示后,通过平均池化得到音频的全局特征向量。在其上添加一个线性层,输出对应每个音频事件类别的逻辑值(Logits),经Sigmoid函数得到每个类别的预测概率,用于多标签分类。
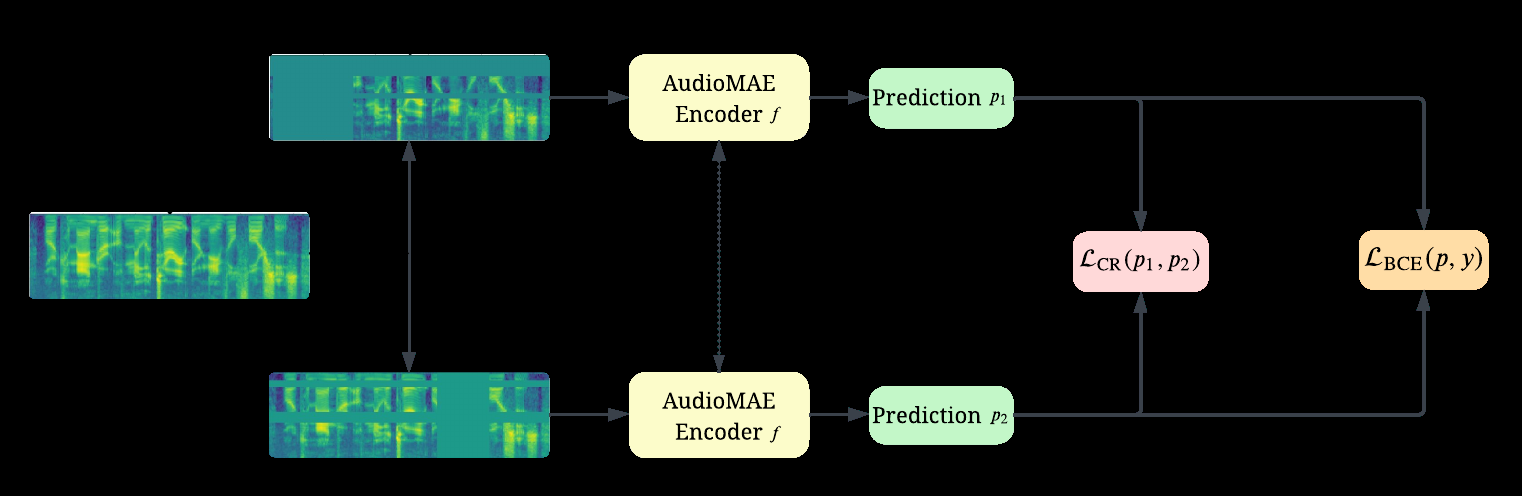
一致性正则化模块(图1):这是本文的核心创新模块。对于每个输入音频
x,通过数据增强管道生成k个增强视图{x_1, x_2, ..., x_k}。每个增强视图都通过同一个ViT编码器和分类头,得到预测概率分布{p_1, p_2, ..., p_k}。CR损失计算所有不同视图对(i != j)之间预测的交叉熵损失的平均值,要求它们相互一致。该损失与标准的监督损失(BCE Loss)加权求和,共同优化模型。 图1:整体方法架构示意图(以2个增强视图为例)。输入音频
图1:整体方法架构示意图(以2个增强视图为例)。输入音频x被增强为x_1和x_2,共享的模型(ViT编码器+分类头)对它们进行预测,得到p_1和p_2。损失函数由监督损失L_BCE(来自p_1和真实标签y)和一致性损失L_CR(来自p_1和p_2)组成。数据增强管道(图2):包括三种技术:
- Mixup:在谱图层面进行混合,增加样本多样性。
- SpecAugment:对频谱图进行时间掩蔽、频率掩蔽或两者结合。
- Random Erasing:随机擦除频谱图中的矩形区域,该技术源于计算机视觉,论文发现其对音频有效。
 图2:数据增强技术示例。(a) 原始频谱图,(b) 时间掩蔽,(c) 频率掩蔽,(d) 时间+频率掩蔽,(e) 随机擦除。
图2:数据增强技术示例。(a) 原始频谱图,(b) 时间掩蔽,(c) 频率掩蔽,(d) 时间+频率掩蔽,(e) 随机擦除。
💡 核心创新点
- 将一致性正则化迁移至音频事件识别:核心创新在于将CR-CTC(针对ASR)的思想,适配并应用于基于ViT架构和谱图输入的多标签AER任务,证明了该正则化方法的跨任务有效性。
- 探索增强视图数量对CR的影响:超越了原始CR仅使用两个视图的范式,通过实验发现增加视图数量(如k=6)在小数据集(20k)上能带来额外性能提升,为CR的应用提供了新视角。
- 将CR无缝扩展至半监督学习:利用CR损失不需要真实标签的特性,设计了半监督训练框架,对无标签的大规模数据(1.8M)也施加一致性约束,在标注数据稀缺的场景下进一步提升了模型性能。
🔬 细节详述
- 训练数据:
- 数据集:AudioSet。AS-20k:~20,550个平衡样本;AS-2M:~1,783,977个不平衡样本。
- 预处理:计算Kaldi兼容的Fbank特征作为输入。
- 数据增强:训练时使用Mixup、SpecAugment、Random Erasing。半监督学习中,无标签数据未使用Mixup和Random Erasing(见表3)。
- 损失函数:
- 监督损失:二元交叉熵损失
L_BCE(公式1),用于所有类别。 - 一致性损失:
L_CR(公式5),为所有不同增强视图预测之间交叉熵损失的平均值。 - 总损失:
L_total = L_BCE + λ * L_CR(公式6)。半监督总损失L_semi见公式(7),对标注和无标注数据分别应用CR。
- 监督损失:二元交叉熵损失
- 训练策略:
- AS-20k:Batch size 64, Adam优化器,学习率 1e-3,训练60 epochs。
- AS-2M:Batch size 512, Adam优化器,学习率 2e-4,训练60 epochs。
- 半监督:每个训练步使用4倍于有标签数据量的无标签数据。λ1和λ2需分别调优。
- 关键超参数:
- 模型:ViT-B/12, 88.9M参数。
- 增强视图数k:默认2,在小数据集上尝试更多。
- CR系数λ:关键调优参数,最佳值因数据集而异(20k为2.0, 2M为1.5)。
- Mixup比例μ:最佳值为0.5。
- Random Erasing概率p:最佳值为0.25(仅在20k有效)。
- 训练硬件:论文中未提供。
- 推理细节:论文中未说明,推测使用与训练相同的前向传播,直接输出Sigmoid概率。
- 正则化技巧:Dropout未在架构中明确提及;关键正则化手段即为本文提出的CR以及各种数据增强。
📊 实验结果
论文在AudioSet的AS-20k和AS-2M划分上进行了全面实验,评估指标为mAP(527类)。
主要对比实验(表4):
| 模型 | AS-20k (mAP) | AS-2M (mAP) |
|---|---|---|
| 相关工作 | ||
| PANNs [9] | 27.8 | 43.1 |
| AST [13] | 37.8 | 48.5 |
| AudioMAE [11] | 37.1 | 47.3 |
| 本文基线与方法(使用AudioMAE预训练) | ||
| Baseline (本文复现) | 37.9 | 44.7* |
| Ours, Supervised | 39.6 | 46.9* |
| Ours, Semi-Supervised | 40.1 | - |
| 本文基线与方法(无预训练) | ||
| Baseline | 17.2 | 30.9* |
| Ours, Supervised | 19.3 | 33.5* |
| Ours, Semi-Supervised | 19.9 | - |
*注:本文的AS-2M训练集规模为1.8M,与原始AS-2M不同。
关键消融实验(表1, 2, 3)已在“核心摘要”和“细节详述”中部分列出。 此处补充半监督学习关键结果(表3):
- 使用λ1=1.5, λ2=1.0时,半监督模型在AS-20k上达到36.6 mAP(dev set),相比最佳监督模型(λ=2.0时为35.8 mAP)有0.8 mAP提升。
- 对无标签数据应用Mixup或Random Erasing会损害性能。
 此图与图2相同,为数据增强的可视化示例,用于支持方法描述。
此图与图2相同,为数据增强的可视化示例,用于支持方法描述。
 此图在论文中未提供具体说明,可能为其他可视化内容,但对核心结论支持有限。
此图在论文中未提供具体说明,可能为其他可视化内容,但对核心结论支持有限。
 此图在论文中未提供具体说明,可能为其他可视化内容,但对核心结论支持有限。
此图在论文中未提供具体说明,可能为其他可视化内容,但对核心结论支持有限。
 此图在论文中未提供具体说明,可能为其他可视化内容,但对核心结论支持有限。
此图在论文中未提供具体说明,可能为其他可视化内容,但对核心结论支持有限。
结论:本文提出的监督CR方法在两个数据集规模上均显著超越了复现的基线(在20k上提升1.7 mAP, 在2M上提升2.1 mAP)。半监督方法在20k设置下进一步获得提升。与表4顶部的其他模型相比,本文方法在使用相同预训练初始化时,达到了与AST、SSLAM等模型有竞争力的性能(尽管AS-2M上基线较弱)。
⚖️ 评分理由
- 学术质量:5.0/7。创新性主要在于领域迁移和系统性实验验证,而非方法本身。技术实现正确无误,实验设计(多种设置、大量消融、不同规模数据集)非常充分且严谨,结论可靠。扣分点在于理论深度有限,未深入剖析CR在音频领域的作用机制。
- 选题价值:1.5/2。选择音频事件识别这一实用任务,并解决其中数据标注成本高的实际问题(通过半监督学习),具有明确的应用价值和前沿性(结合了自监督学习思想)。
- 开源与复现加成:+0.5/1。提供了明确的代码仓库链接,这是重大加分项。但缺乏预训练权重发布、详细硬件说明和一键式复现脚本,因此加成适中。