📄 Identifying Birdsong Syllables without Labelled Data
#生物声学 #无监督学习 #聚类 #信号处理
✅ 7.0/10 | 前50% | #生物声学 | #无监督学习 | #聚类 #信号处理
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Mélisande Teng (Mila - Quebec AI Institute, Université de Montréal) (共同第一作者)
- 通讯作者:未说明
- 作者列表:Mélisande Teng (Mila - Quebec AI Institute, Université de Montréal), Julien Boussard (Mila - Quebec AI Institute, McGill University) (共同第一作者), David Rolnick (Mila - Quebec AI Institute, McGill University), Hugo Larochelle (Mila - Quebec AI Institute, Université de Montréal)
💡 毒舌点评
亮点:该方法是首个完全无监督的鸟鸣音节分解算法,巧妙地将电生理信号处理中的spike sorting思想迁移到生物声学,避免了对大量标注数据的依赖,实用性强。短板:整个流水线(特别是匹配追求部分)对预设的音节检测阈值和模板质量非常敏感,论文在复杂噪声环境下的表现讨论不足,更像一个优雅的“工程流水线”而非一个可学习的、具有强泛化能力的模型。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:论文使用了两个公开数据集(Bengalese Finch [16], Great Tit [17]),但未说明是否提供经其处理后的数据或额外资源。
- Demo:未提及。
- 复现材料:论文给出了关键超参数(η, h, HDBSCAN参数)和方法伪代码描述,但完整的处理流程、细节(如零填充尺寸、PCA的具体实现)和迭代停止条件不够详尽。
- 论文中引用的开源项目:引用了scikit-maad [13] (用于对比方法)、HDBSCAN [19] (用于聚类)、以及引用了Perch [7] 作为嵌入基线。论文本身的方法未明确声称基于某个现有开源工具包。
📌 核心摘要
- 问题:研究鸟鸣音节序列对理解动物交流和个体识别至关重要,但现有机器学习方法严重依赖音节级别的标注数据,成本高且可扩展性差。
- 方法核心:提出一个完全无监督的流水线:首先基于振幅阈值检测“音节事件”(SEs),然后对SEs进行聚类并生成“音节模板”,最后使用匹配追求算法将完整录音分解为模板序列。
- 新颖之处:是首个无需任何标签的端到端鸟鸣音节分解算法。其创新在于将信号处理中的“匹配追求”与无监督聚类(HDBSCAN)相结合,并通过分裂-合并步骤精炼模板,实现跨个体共享模板。
- 主要实验结果:在Bengalese finch数据集上,多个体设置下平均检测精度0.82,微平均精度0.91(见下表)。在Great tit数据集上,方法提取的“音节袋”(BoS)表示能有效分离不同个体和歌曲类型(mAP=0.46, mAP@5=0.86),优于Perch嵌入。
- 表1(Bengalese finch关键指标摘录)
设置 个体ID 检测精度 检测召回率 微平均精度 单个体 平均 0.85 0.66 0.87 多个体 平均 0.82 0.57 0.91
- 表1(Bengalese finch关键指标摘录)
- 实际意义:为生物学家提供了一个快速探索和标注鸟鸣录音的工具,尤其适用于干净录音环境(如录音箱、焦点录音),能辅助个体识别和歌曲类型分析。
- 主要局限性:方法可能对结构化噪声(如重叠鸟鸣、环境杂音)不够鲁棒;性能依赖于初始检测阈值η和聚类参数h的选择;召回率相对较低,可能遗漏低频次音节。
🏗️ 模型架构
论文未提供单独的模型架构图。其方法是一个多阶段流水线,架构如下:
- 输入:原始鸟鸣音频波形。
- 预处理:将音频转换为频谱图。
- 音节事件(SE)检测:基于振幅阈值η在频谱图上检测连通区域,每个区域作为一个候选音节事件。对每个SE进行零填充,得到固定尺寸的图像块。
- 聚类与模板生成:
- 初始聚类:对所有SE图像进行PCA降维,取前3个主成分,然后使用HDBSCAN进行聚类。
- 分裂:对初始聚类的每个簇,再次进行PCA(取前2个主成分)并运行HDBSCAN,以分离簇内混合的SE。
- 合并:对每个分裂后的簇取中位数生成“模板”。计算所有模板对间的归一化L2距离
d(T1, T2) = ||T1 - T2||2 / max(||T1||2, ||T2||2)。基于此距离进行层次聚类(全连接),将距离低于阈值h的模板合并。最终输出一组唯一模板。
- 匹配追求与迭代精炼:
- 目标:将录音
V分解为检测到的SE集合,并为每个SE分配一个模板,以最小化残差D(T, t, f) = ||V - Σ STk(tk, fk)||^2。 - 过程:采用贪婪算法。计算所有模板在时间-频率上的匹配度,找到局部最大值作为新的SE检测点,并分配最佳模板。强制执行“隔离项”(对D做最大池化)以防止音节重叠。
- 迭代:将匹配追求改进后的SE检测结果反馈到步骤4(分裂-合并),重新优化模板,并再次进行匹配追求,迭代直至收敛。
- 目标:将录音
- 后处理:移除分配给模板但持续时间小于一个时间步的短时SE,以滤除噪声。
- 输出:时间上对齐的音节序列,每个音节被标记上一个模板ID。
💡 核心创新点
- 首个完全无监督的音节分解流水线:之前方法或需监督(Cohen et al.),或需大量人工超参数调优(Alexander et al.)。本文方法从头至尾无需任何标注,极大降低了使用门槛。
- 借鉴神经科学的匹配追求算法:将经典的匹配追求(常用于神经信号解码)创新性地应用于鸟鸣音节分割。该算法能迭代地优化音节检测和模板分配,是流程中的关键推理引擎。
- 跨个体的共享模板学习:在“多个人体”设置下,算法能从多个个体的混合录音中学习到共享的音节目板库,这有助于发现物种内的共性“词汇”以及个体间的差异性(通过不同的音节组合)。
- 两阶段的无监督聚类精炼(分裂-合并):先通过全局PCA+HDBSCAN粗聚类,再对每个簇内进行局部PCA+HDBSCAN细分裂,最后基于模板相似度合并。这种自上而下再精炼的策略,能更好地处理复杂的聚类结构。
🔬 细节详述
- 训练数据:
- Bengalese Finch数据集:来自文献[16],4个个体,每个1.75-3.5小时录音,已有人工标注。预处理遵循原论文。
- Great Tit数据集:来自文献[17],454个个体的109,963首歌,标注到歌曲类型和个体级别。预处理遵循原论文。
- 数据增强:未说明。
- 损失函数:无神经网络训练,故无损失函数。核心优化目标为匹配追求中的残差最小化(公式2)。
- 训练策略:非传统训练,而是优化过程。使用固定超参数:振幅阈值 η = 10dB,模板合并阈值 h = 0.33,HDBSCAN的最小簇大小=10,最大簇大小=200。这些参数在两个数据集上相同。
- 关键超参数:
- SE检测:阈值 η。
- PCA:全局降维至3维,簇内降维至2维。
- HDBSCAN:min_cluster_size=10, max_cluster_size=200。
- 模板合并:距离阈值 h=0.33。
- Great Tit额外设置:SE检测框大小为100时间步 x 100频率bins(对数尺度)。
- 训练硬件:未说明。
- 推理细节:匹配追求采用贪婪搜索,并应用最大池化实现“隔离项”防止重叠。迭代进行(论文中提到但未指定具体迭代次数)。
- 正则化技巧:模板生成使用中位数(而非均值)以增强鲁棒性;后处理移除过短SE。
📊 实验结果
主要实验与结果:
Bengalese Finch数据集:
设置:每个个体10分钟录音作为支持集(用于生成模板),其余作为查询集评估。比较“单个体”(模板来自自身)和“多个人体”(模板来自所有人混合)两种设置。
核心指标:检测精度/召回率,微平均/加权平均精度/召回率。
表1:Bengalese finch查询集结果(论文原始表格关键部分)
设置 个体ID 检测精度 检测召回率 微平均精度 加权平均精度 加权平均召回率 模板数 地面真实音节数 单个体 gr41rd51 0.84±0.04 0.66±0.03 0.71±0.06 0.43±0.11 0.47±0.07 8 26 单个体 bl26lb16 0.96±0.01 0.93±0.01 0.91±0.04 0.85±0.08 0.87±0.05 9 20 单个体 平均 0.85 0.66 0.87 0.63 0.60 10 20 多个人体 平均 0.82 0.57 0.91 0.63 0.69 26 20 关键发现:多设置下微平均精度更高(0.91 vs 0.87),表明共享模板能更好地区分音节类型。个体bl26lb16的表现最优。图3显示性能随支持集时长增加而提升,但收益递减,10分钟是合理权衡。图2展示了不同个体对共享模板的“偏好”,暗示可用于个体识别。
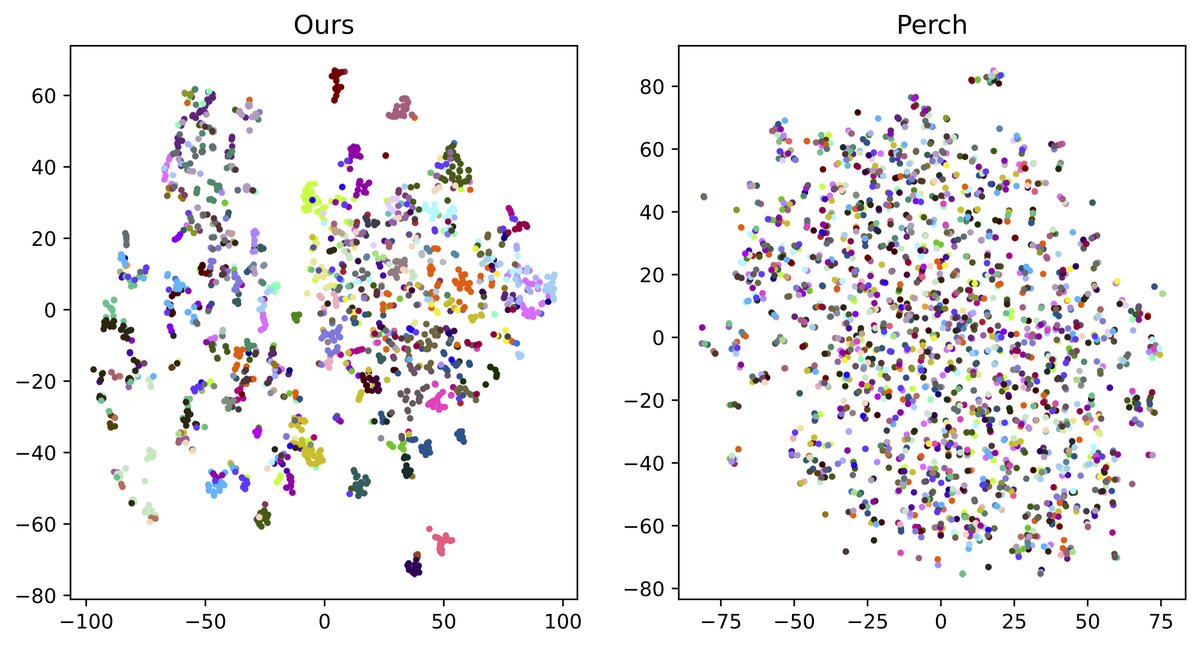 图3说明:展示了支持集从1分钟增加到40分钟时,四个个体的平均加权精度(蓝)和召回率(红)的变化,显示性能提升后趋于平缓。
图3说明:展示了支持集从1分钟增加到40分钟时,四个个体的平均加权精度(蓝)和召回率(红)的变化,显示性能提升后趋于平缓。
Great Tit数据集:
- 设置:随机选取25个个体的2000首歌,对整体运行算法。构建每首歌的“音节袋”(BoS)表示。
- 评估:通过t-SNE可视化BoS表示,并与Perch嵌入对比。使用K-means聚类计算mAP。
- 关键发现:BoS表示的t-SNE图(图5左)能清晰分离个体和歌曲类型,而Perch嵌入(图5右)则不能。定量上,BoS的mAP=0.46, mAP@5=0.86,远高于Perch的mAP=0.11, mAP@5=0.39。算法共发现58个模板,平均每个模板出现在5.93个个体中(占比>5%)。
 图5说明:左侧为本文BoS表示的2D t-SNE图,不同颜色代表不同个体/歌曲类型,聚类效果明显;右侧为Perch嵌入的相应图,聚类效果差。
图5说明:左侧为本文BoS表示的2D t-SNE图,不同颜色代表不同个体/歌曲类型,聚类效果明显;右侧为Perch嵌入的相应图,聚类效果差。
与其他方法对比:论文主要与自身基线(不同设置)对比,并与Perch嵌入进行非直接对比(用于个体区分任务)。未与最新的、针对音节分割的监督方法(如Tweetynet)进行直接性能对比。
⚖️ 评分理由
- 学术质量:5.5/7:创新性明确(无监督流水线、匹配追求应用),技术描述清晰,实验在两个不同数据集上验证了方法的有效性和实用性。主要扣分点在于:1)缺乏与当前SOTA监督方法的直接性能对比;2)实验仅展示了在理想录音环境下的结果,对现实复杂声景的鲁棒性未加验证。
- 选题价值:1.5/2:对于生物声学领域的研究者,这是一个非常实用的工具性贡献,能显著提高研究效率。问题本身具有前沿性(自动化生物声学分析)。但对于更广泛的音频/语音处理社区,其应用场景和影响力有限。
- 开源与复现加成:0.0/1:论文未提供代码、模型或任何开源计划,仅提供了部分超参数。这使得其他研究者难以复现和验证其结果,也无法直接将其应用于新数据集。根据要求,此项得0分。