📄 I-DCCRN-VAE: An Improved Deep Representation Learning Framework for Complex VAE-Based Single-Channel Speech Enhancement
#语音增强 #变分自编码器 #预训练 #鲁棒性
✅ 7.5/10 | 前25% | #语音增强 | #变分自编码器 | #预训练 #鲁棒性
学术质量 7.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Jiatong Li(Carl von Ossietzky Universität Oldenburg, 医学物理与声学系及 Hearing4all 卓越集群)
- 通讯作者:未说明(两位作者并列提供邮箱,未明确指定通讯作者)
- 作者列表:Jiatong Li(Carl von Ossietzky Universität Oldenburg, 医学物理与声学系及 Hearing4all 卓越集群)、Simon Doclo(Carl von Ossietzky Universität Oldenburg, 医学物理与声学系及 Hearing4all 卓越集群)
💡 毒舌点评
本文像一位严谨的工程师,将VAE语音增强系统的“后门”(跳跃连接)焊死,强迫其从潜在空间“真正学习”,并用β-VAE的旋钮精细调节学习内容,结果泛化能力显著提升。然而,改进更多是“修补”与“优化”现有架构,缺乏从根本上改变游戏规则的洞见,且未能与当前生成模型SOTA(如基于扩散模型的方法)同台竞技,使其影响力打了折扣。
🔗 开源详情
- 代码:提供了GitHub仓库链接:https://github.com/iris1997jiatong/I-DCCRN-VAE。
- 模型权重:论文中未提及公开预训练模型权重。
- 数据集:使用了公开数据集(DNS3, WSJ0-QUT, Voicebank-DEMAND),但论文中未提及是否提供生成带噪语音的预处理脚本。
- Demo:论文中未提及在线演示。
- 复现材料:论文提供了详细的网络结构、超参数(学习率、批大小、优化器、STFT参数、潜在维度等)和训练流程描述。但缺少具体的代码运行配置、依赖库版本、数据划分脚本等细节。
- 引用的开源项目:论文中未明确列出依赖的其他开源项目/模型。所用网络架构基于DCCRN [23],损失函数和训练方法也参考了相关工作。
📌 核心摘要
- 问题:单通道语音增强在复杂噪声场景下,现有基于深度复数卷积循环变分自编码器(DCCRN-VAE)的方法存在潜在表示信息量不足(因跳跃连接导致后验坍缩)和泛化能力有限的问题。
- 方法核心:提出改进版I-DCCRN-VAE,对基线DCCRN-VAE进行三项关键修改:1) 去除预训练的干净语音VAE(CVAE)和噪声VAE(NVAE)中的跳跃连接,迫使信息通过潜在瓶颈,生成更具信息量的表示;2) 在预训练中使用β-VAE,以更好平衡重建质量与潜在空间正则化;3) 噪声抑制VAE(NSVAE)的编码器同时生成语音和噪声的潜在表示,提供更完整的生成基础。
- 新意:系统性改进了基于VAE的语音增强框架,重点在于修复潜在表示学习的有效性,并简化了训练流程(证明经典微调与对抗训练效果相当)。
- 实验结果:
- 在匹配数据集(DNS3)上,I-DCCRN-VAE性能与基线DCCRN和DCCRN-VAE相当(例如,使用经典微调时SI-SDR为17.2 dB vs. DCCRN的16.6 dB)。
- 在不匹配数据集(WSJ0-QUT, Voicebank-DEMAND)上,I-DCCRN-VAE显著优于所有基线。例如,在WSJ0-QUT上,I-DCCRN-VAE (CF)的SI-SDR比DCCRN-VAE (ADV)高1.5 dB(8.7 vs. 7.2),在VB-DMD上高0.5 dB(18.0 vs. 17.5)。
- 消融实验表明,去除跳跃连接(β=0.01)和同时建模噪声表示(α=1)是性能提升的关键。
| 系统 | DNS3 SI-SDR (dB) | DNS3 PESQ | WSJ0-QUT SI-SDR (dB) | WSJ0-QUT PESQ | VB-DMD SI-SDR (dB) | VB-DMD PESQ |
|---|---|---|---|---|---|---|
| (1) DCCRN [基线] | 16.6 | 2.54 | 7.1 | 1.59 | 17.5 | 2.38 |
| (2) DCCRN-VAE (CF) | 16.8 | 2.38 | 6.8 | 1.49 | 17.1 | 2.36 |
| (3) DCCRN-VAE (ADV) [基线] | 17.8 | 2.50 | 7.2 | 1.54 | 17.5 | 2.37 |
| (4) I-DCCRN-VAE (CF) [本文] | 17.2 | 2.49 | 8.7 | 1.65 | 18.0 | 2.44 |
| (5) I-DCCRN-VAE (ADV) [本文] | 17.5 | 2.49 | 8.9 | 1.65 | 18.1 | 2.44 |
- 实际意义:该方法在保持匹配场景性能的同时,大幅提升了跨场景泛化能力,且无需复杂的对抗训练,简化了训练流程,更有利于实际部署。
- 主要局限性:改进基于对现有VAE架构的调整,未与近期的生成模型SOTA(如基于扩散的模型、自监督预训练的大模型)进行全面对比;论文未报告模型参数量、计算复杂度等效率指标。
🏗️ 模型架构
I-DCCRN-VAE系统(图1)是一个基于复数域VAE的单通道语音增强框架,整体架构分为预训练和微调两个阶段,包含三个核心模块:干净语音VAE(CVAE)、噪声VAE(NVAE) 和 噪声抑制VAE(NSVAE)。
输入输出流程:
- 输入:带噪语音的复数STFT表示
Y ∈ C^{N×F}。 - 输出:估计的干净语音复数STFT
X̂,通过X̂ = Y · M计算(M为CVAE解码器生成的复数掩码),最后经逆STFT和重叠相加法恢复时域信号。
- 输入:带噪语音的复数STFT表示
组件及内部结构:
- CVAE & NVAE(预训练阶段):
- 编码器:结构相同,包含6个二维复数卷积块(Conv2d)和一个复数LSTM层。卷积块的通道数为
[32, 64, 128, 128, 256, 256],核大小为(5,2),步长为(2,1)。LSTM层最终输出潜在分布的���数:均值向量μ、方差向量σ和关系向量δ(均为复数)。潜在表示维度L=128。 - 解码器:结构与编码器镜像对称。
- 关键设计:去除了跳跃连接,强制所有信息通过潜在瓶颈
z,旨在学习更丰富的潜在表示。预训练使用β-VAE损失(见公式2),平衡重建损失(复数谱与幅度谱的L2损失,见公式4)和KL散度正则化。
- 编码器:结构相同,包含6个二维复数卷积块(Conv2d)和一个复数LSTM层。卷积块的通道数为
- NSVAE(编码器训练阶段):
- 编码器:结构与CVAE编码器类似,但其LSTM层同时输出语音潜在分布的参数
(μ_{yx}, σ_{yx}, δ_{yx})和噪声潜在分布的参数(μ_{yv}, σ_{yv}, δ_{yv})。 - 训练目标:最小化NSVAE编码器输出的语音/噪声潜在分布与预训练CVAE/NVAE编码器在干净数据上输出的对应分布之间的KL散度(公式5),即
KL(q(z_x|Y)||q(z_x|X)) + αKL(q(z_v|Y)||q(z_v|V))。α为噪声潜在表示的权重因子。
- 编码器:结构与CVAE编码器类似,但其LSTM层同时输出语音潜在分布的参数
- CVAE解码器微调阶段:
- 将NSVAE编码器(已固定)从带噪语音中提取的语音潜在表示
z_x输入给CVAE解码器。此时,解码器被微调以生成复数掩码M,用于估计干净语音。微调使用SI-SDR损失(公式9)。
- 将NSVAE编码器(已固定)从带噪语音中提取的语音潜在表示
- CVAE & NVAE(预训练阶段):
数据流与交互:
- 预训练:CVAE和NVAE分别在干净语音
X和噪声V数据上独立预训练。 - NSVAE训练:将带噪语音
Y输入NSVAE编码器,输出z_x和z_v。损失函数迫使q(z_x|Y)逼近q(z_x|X),q(z_v|Y)逼近q(z_v|V)。此时CVAE和NVAE的参数被冻结。 - 微调:将带噪语音
Y输入NSVAE编码器得到z_x,再将z_x输入CVAE解码器,得到掩码M并估计干净语音X̂。仅微调CVAE解码器的参数。
- 预训练:CVAE和NVAE分别在干净语音
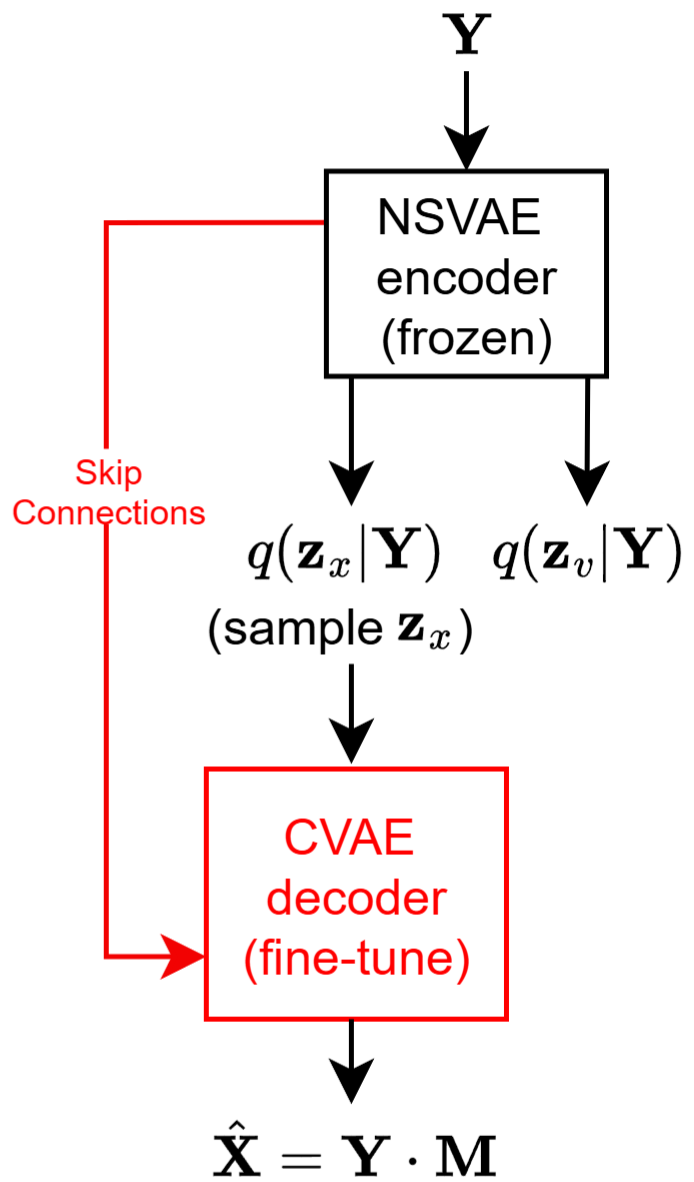 图1:I-DCCRN-VAE系统概览。分为(a) NSVAE编码器训练和(b) 解码器微调两个主要步骤,展示了包含CVAE、NVAE和NSVAE三个模块及其数据流向。
图1:I-DCCRN-VAE系统概览。分为(a) NSVAE编码器训练和(b) 解码器微调两个主要步骤,展示了包含CVAE、NVAE和NSVAE三个模块及其数据流向。
💡 核心创新点
去除预训练VAE中的跳跃连接:
- 之前局限:DCCRN-VAE基线在预训练VAE中使用跳跃连接,导致重建质量极高但KL损失接近零,发生“后验坍缩”,潜在表示变得不具信息性,NSVAE难以从中学习有用的分离信息。
- 如何起作用:强制信息必须通过低维的潜在瓶颈,迫使编码器学习更紧凑、更具信息量的潜在表示。
- 收益:实验表明(表1),去除跳跃连接显著提高了潜在表示的KL散度(从~0提高到67.3@β=0.01),证明了表示信息量的增强。这为后续NSVAE的提取提供了更好的基础。
在预训练中使用β-VAE:
- 之前局限:标准VAE预训练可能无法有效平衡重建精度与潜在空间的正则化程度。
- 如何起作用:通过调整KL散度的权重因子
β,显式地控制重建损失与潜在空间正则化之间的权衡。较小的β强调重建,较大的β强调正则化。 - 收益:通过实验(表1、表2)确定了最优
β=0.01。该值在保持较好潜在表示信息量的同时,也提供了足够的正则化,从而在下游增强任务中(尤其在不匹配数据集上)取得最佳性能。
NSVAE生成语音与噪声双潜在表示:
- 之前局限:DCCRN-VAE的NSVAE编码器仅生成语音潜在表示
z_x,忽略了对噪声分量的显式建模。 - 如何起作用:借鉴PVAE思想,让NSVAE编码器同时从带噪语音中估计语音和噪声的潜在表示
z_x和z_v,并在训练中通过KL散度分别对齐到预训练的CVAE和NVAE。这为生成模型提供了更完整的生成基(clean speech + noise)。 - 收益:消融实验(表3)显示,当
α=1(即同时建模噪声)时,所有数据集上的SI-SDR和PESQ均优于α=0(仅建模语音),证明了显式噪声建模有助于从混合信号中更好地提取语音信息。
- 之前局限:DCCRN-VAE的NSVAE编码器仅生成语音潜在表示
🔬 细节详述
- 训练数据:
- 来源与规模:使用DNS3挑战数据集。预训练使用30小时(50%说话人),NSVAE训练和微调使用20小时(40%说话人),验证集10小时(10%说话人)。干净语音仅使用朗读语音,噪声排除了DEMAND数据集。
- 预处理:通过DNS脚本生成不同SNR(-10dB至15dB)的带噪语音。
- 损失函数:
- 预训练损失(CVAE/NVAE):重建损失(公式4:复数谱与幅度谱的L2损失) + β * KL散度损失(公式2,使后验分布接近标准复高斯先验)。
- NSVAE训练损失:公式5,两项KL散度之和。
- CVAE解码器微调损失:SI-SDR损失(公式9),在时域计算。
- 训练策略:
- 优化器:Adam。
- 学习率:预训练阶段(CVAE, NVAE, NSVAE)为
3e-4;对抗训练中的判别器为8e-5。当验证损失3个epoch不下降时减半。 - 早停:最多1000 epoch,验证损失20个epoch不下降则停止。
- 批大小:15。
- 关键超参数:
- STFT参数:帧长400,重叠25%,FFT长度512。
- 潜在表示维度
L=128。 - β-VAE权重因子
β:通过实验(表2)选择最优值 0.01。 - NSVAE噪声权重因子
α:通过实验(表3)选择最优值 1。
- 训练硬件:论文中未说明。
- 推理细节:系统是因果的。推理时,带噪语音STFT输入NSVAE编码器得到
z_x,再输入CVAE解码器得到掩码M,计算X̂ = Y · M,最后逆STFT得到增强后时域语音。 - 正则化/稳定训练技巧:使用了β-VAE进行正则化。对于对抗训练,论文提及但本文主结果未采用。
📊 实验结果
主要实验在三个数据集上进行:匹配的DNS3测试集,以及两个不匹配数据集WSJ0-QUT和Voicebank-DEMAND (VB-DMD)。
- 超参数优化与消融实验(表1,2,3):
- 表1显示,去除跳跃连接(Without SC)时,重建SI-SDR低于有跳跃连接(With SC),但KL散度显著更高,表明潜在表示更具信息性。降低
β值会同时提高重建SI-SDR和KL散度。 - 表2表明,去除跳跃连接并配合
β=0.01能在所有数据集上获得最佳的SI-SDR和PESQ。有跳跃连接(With SC)的性能全面较差。 - 表3表明,当NSVAE同时建模语音和噪声(
α=1)时,性能优于仅建模语音(α=0)。
- 与基线系统的全面对比(表4):
- 核心结论:I-DCCRN-VAE(系统4,5)在不匹配数据集(WSJ0-QUT, VB-DMD)上一致优于所有基线(DCCRN, DCCRN-VAE),尤其在WSJ0-QUT上,使用经典微调(CF)的I-DCCRN-VAE比使用对抗训练(ADV)的DCCRN-VAE高出1.5 dB SI-SDR。在匹配的DNS3数据集上,性能与最强基线相当或略低。
- 训练方式对比:对于基线DCCRN-VAE,对抗训练(ADV)相比经典微调(CF)有巨大提升;但对于I-DCCRN-VAE,两者性能非常接近(系统4 vs. 5)。这表明I-DCCRN-VAE在微调前已能产生高质量语音,因此不需要对抗训练来修复。
- 主要基线对比表:已在“核心摘要”部分列出。
⚖️ 评分理由
- 学术质量:7.0/7:论文结构清晰,技术改进逻辑严密且每一步都有实验验证(消融实验)。实验设计全面,包含了匹配与不匹配场景评估,证据可信度高。创新点虽非颠覆性,但属于对现有技术的系统性优化,有效解决了具体问题(后验坍缩、泛化不足)。
- 选题价值:1.5/2:语音增强是音频处理的核心任务之一,提升模型在复杂场景下的泛化能力并简化训练,具有明确的实用价值和工业应用潜力,与领域读者高度相关。
- 开源与复现加成:0.5/1:论文提供了完整的代码仓库链接,并详细列出了大部分超参数、网络结构和训练策略,为复现提供了良好基础。扣分点在于未提供预训练模型权重,也未提供处理原始数据集(DNS3, WSJ0等)的具体脚本。