📄 Hybrid Pruning: In-Situ Compression of Self-Supervised Speech Models for Speaker Verification and Anti-Spoofing
#说话人验证 #语音伪造检测 #自监督学习 #结构化剪枝 #低资源
🔥 8.0/10 | 前25% | #说话人验证 | #自监督学习 | #语音伪造检测 #结构化剪枝
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Junyi Peng (Brno University of Technology, Speech@FIT)
- 通讯作者:未说明
- 作者列表:Junyi Peng¹, Lin Zhang², Jiangyu Han¹, Oldřich Plchot¹, Johan Rohdin¹, Themos Stafylakis³,⁴,⁵, Shuai Wang⁶, Jan Černocký¹ (1. Speech@FIT, Brno University of Technology, Czechia; 2. Johns Hopkins University, USA; 3. Athens University of Economics and Business; 4. Omilia; 5. Archimedes/Athena R.C., Greece; 6. Nanjing University, China)
💡 毒舌点评
亮点在于优雅地将模型剪枝与任务微调合并为单阶段训练,省去了复杂的多步流水线,且在多个基准上效果拔群,甚至能充当正则化提升泛化能力;短板在于对“为什么学出的剪枝模式是这样的”这一现象的理论解释稍显薄弱,更多是现象描述而非机理剖析。
🔗 开源详情
- 代码:论文中未提及官方代码仓库链接。
- 模型权重:提供了预训练和剪枝后模型权重的HuggingFace页面链接:
https://huggingface.co/JYP2024/Wedefense_ASV2025_WavLM_Base_Pruning。 - 数据集:使用了公开数据集(VoxCeleb, CN-Celeb, ASVspoof5, SpoofCeleb),但论文未提供其获取方式或额外处理脚本。
- Demo:论文中未提及在线演示。
- 复现材料:论文提供了部分关键实现细节(如损失函数、热身调度、MHFA模块配置),但未提供完整的训练配置文件、超参数列表或脚本。实验的硬件信息不完整。
- 引用的开源项目:论文主要依赖预训练的WavLM模型(来自[4]),并在实现中可能参考了L0正则化([23, 24])和Hard Concrete分布([25, 26])的相关工作。
📌 核心摘要
这篇论文旨在解决大规模自监督语音模型(如WavLM)因参数量巨大而难以在资源受限设备上部署的问题。其核心方法是提出一个名为“混合剪枝”(Hybrid Pruning, HP)的统一框架,该框架将结构化剪枝(移除整个注意力头、神经元等)与针对特定下游任务的微调过程集成在单个训练阶段中联合优化。与之前需要多阶段(如先预训练剪枝或后剪枝蒸馏)的方法相比,HP允许模型在针对特定任务(说话人验证或反欺骗)微调的同时,动态学习一个专门为该任务定制的紧凑架构。主要实验结果表明,该方法在VoxCeleb说话人验证基准上,能在参数量减少70%的情况下,EER几���无损(Vox1-O/E/H分别达到0.7%、0.8%、1.6%)。在ASVspoof5反欺骗挑战中,HP显著优于DP-HuBERT等基线,并在10%剪枝率下实现了3.7%的SOTA EER,同时发现中等程度的剪枝能有效缓解过拟合,提升低资源场景下的泛化能力。其实际意义在于为在边缘设备上高效部署高性能SSL模型提供了一条简洁、有效的路径。主要局限性包括缺乏与其他高效微调方法(如Adapter)的直接比较,以及对学习到的剪枝模式的理论分析不够深入。
🏗️ 模型架构
论文提出的“混合剪枝”(Hybrid Pruning, HP)框架,其核心是修改标准的SSL模型微调流程。整体架构和数据流如下:
- 输入:原始语音波形。
- 基础模型:使用预训练的SSL模型,如WavLM(Base或Large版本)。论文中提到,模型的CNN编码器和Transformer层参数在微调时是解冻的。
- 关键修改——随机门控:在SSL模型每个可剪枝的结构化组件(包括CNN卷积核、多头自注意力机制中的注意力头、前馈网络的神经元)上,插入一个可学习的随机门控变量
zj。这个zj从Hard Concrete分布中采样,其值在[0, 1]之间,决定了对应组件对模型输出的贡献程度。通过梯度下降,zj可以学习到精确的“0”,从而完全关闭或剪除该组件。 - 下游后端:SSL模型的输出特征被送入下游任务的后端模块。对于说话人验证任务,使用 MHFA(多头因子化注意力池化)模块,该模块与SSL模型在训练中联合优化。
- 输出与损失:后端模块输出任务特定的表征(如说话人嵌入),并计算任务损失(如AAM Softmax损失用于说话人验证,BCE损失用于反欺骗)。同时,模型还计算一个基于门控变量的剪枝正则化损失。
- 联合优化:训练的目标是同时最小化任务损失和剪枝正则化损失(见公式1)。剪枝正则化项(公式2)鼓励门控变量趋向于0(即稀疏),并通过增广拉格朗日乘子法强制模型达到预设的稀疏度目标。
- 推理时的确定性剪枝:训练完成后,所有随机门控被确定为0或1。所有对应门控为0的结构组件被永久移除,得到一个更小、更快的确定性模型用于推理。
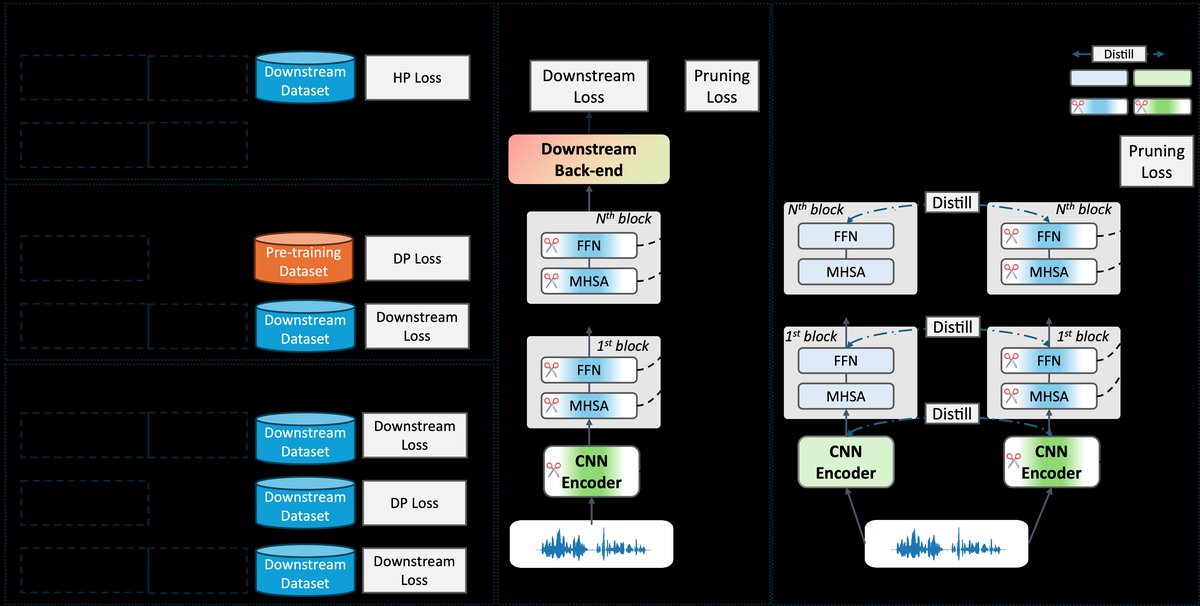 图1清晰地展示了HP框架(a)与先前方法(b, c)的对比。它强调了HP的单阶段特性,即同时使用下游后端(如说话人提取器后端)进行联合优化,并直接学习到一个剪枝后的架构。图中中心细节图也明确指出,HP不需要知识蒸馏中常见的教师-学生架构。
图1清晰地展示了HP框架(a)与先前方法(b, c)的对比。它强调了HP的单阶段特性,即同时使用下游后端(如说话人提取器后端)进行联合优化,并直接学习到一个剪枝后的架构。图中中心细节图也明确指出,HP不需要知识蒸馏中常见的教师-学生架构。
💡 核心创新点
- 单阶段联合优化框架:将结构化剪枝与下游任务微调集成在一个统一的训练过程中。这消除了传统多阶段方法(如预训练剪枝、后剪枝蒸馏)的复杂性,并允许剪枝过程直接受下游任务目标的引导,从而学习到任务最优的压缩架构。
- 基于Hard Concrete分布的可微分结构化门控:在模型的结构化组件(而非单个权重)上引入可学习的门控机制。通过使用Hard Concrete分布进行松弛,使得离散的剪枝决策变得可微分,从而可以通过梯度下降端到端优化,实现了“学习剪枝”。
- 无需知识蒸馏的自适应压缩:与DP-HuBERT等依赖冻结教师模型进行知识蒸馏的方法不同,HP让模型自己通过任务损失来学习如何压缩,避免了教师模型可能次优的限制,探索空间更自由。
- 发现剪枝的正则化效应与任务特异性:通过实验证明,中等程度的剪枝能起到正则化作用,缓解SSL模型在小数据集上的过拟合(U型曲线)。同时,揭示了不同任务(说话人验证 vs. 反欺骗)和不同数据域(VoxCeleb vs. CN-Celeb)会催生出截然不同的、非均匀的剪枝模式。
🔬 细节详述
- 训练数据:
- 说话人验证(SV):在VoxCeleb2开发集上进行训练。评估使用VoxCeleb1的O/E/H三个测试集。为测试泛化能力,还在CN-Celeb语料库上进行了评估。
- 反欺骗:在ASVspoof5和SpoofCeleb数据集上进行训练,并在其官方测试集上评估。
- 论文未提及具体的数据预处理或增强细节。
- 损失函数:
Ltask(任务损失):- SV任务:使用 AAM-Softmax损失,其设置的边际(margin)为0.2,缩放因子(scale)为32。
- 反欺骗任务:使用标准的二元交叉熵(BCE)损失。
Rprune(剪枝正则化损失):基于L0范数的变分近似,并采用增广拉格朗日控制器来精确引导模型达到预设稀疏度t(公式2)。λ1,λ2是可学习的拉格朗日乘子,通过梯度上升更新。
- 训练策略:
- 优化器:论文未明确提及优化器类型(如AdamW)。
- 学习率:未说明。
- Batch Size:未说明。
- 训练轮数/步数:未说明。
- 关键调度:为了稳定收敛,采用了稀疏度目标热身调度:在训练的前5个epoch中,将目标稀疏度
t从0线性增加到最终预设值。
- 关键超参数:
- 模型:使用WavLM Base(~94M参数)和WavLM Large(~316M参数)作为预训练模型。
- 后端:对于SV任务,使用MHFA模块,其拥有32个注意力头,总计约1.2M参数。
- 目标稀疏度:实验测试了10%, 30%, 50%, 60%, 70%, 80%等多个级别。
- 训练硬件:论文未提及训练使用的GPU型号、数量或训练时长。仅提到计算支持来自IT4I超级计算机和e-INFRA CZ。
- 推理细节:训练完成后,门控变为确定性0/1,模型直接进行推理,无需特殊稀疏计算库。论文报告了在AMD EPYC 7A53 CPU和AMD MI250 GPU上的推理加速比。
- 正则化/稳定训练技巧:除了上述的剪枝正则化和热身调度,未提及其他技巧(如Dropout、权重衰减)。
📊 实验结果
本文在说话人验证(SV)和反欺骗(Anti-Spoofing)两大任务上进行了全面评估,核心指标为等错误率(EER)和最小检测成本函数(minDCF)。主要结果如下:
表1:在ASVspoof5评估集上的EER结果对比(基于WavLM Base)
| 稀疏度 | 方法 | 参数量 | FLOPs (4s输入) | EER (%) | minDCF |
|---|---|---|---|---|---|
| 0% | WavLM Base (基线) | 95.6 M | 57.4 G | 4.56 | 0.116 |
| WavLM-SLIM (最佳单系统) | 5.16 | 0.149 | 未提供 | 未提供 | |
| 10% | DP-HUBERT | 86.2 M | 48.0 G | 5.13 | 0.139 |
| Structured Pruning | 86.7 M | 51.7 G | 5.57 | 0.154 | |
| Ours (HP) | 86.0 M | 51.9 G | 3.75 | 0.103 | |
| 30% | DP-HUBERT | 67.3 M | 36.4 G | 7.23 | 0.200 |
| Structured Pruning | 67.3 M | 36.7 G | 5.62 | 0.149 | |
| Ours (HP) | 67.3 M | 39.1 G | 5.14 | 0.143 | |
| 50% | DP-HUBERT | 48.5 M | 25.8 G | 11.73 | 0.321 |
| Structured Pruning | 48.4 M | 25.2 G | 10.22 | 0.269 | |
| Ours (HP) | 48.4 M | 26.9 G | 8.74 | 0.233 |
关键发现:在ASVspoof5上,HP方法在所有剪枝级别上均显著优于任务无关的DP-HuBERT和后剪枝方法。尤其在10%稀疏度时,HP不仅未损失性能,反而将EER从基线4.56%降至3.75%,证明了其作为正则化器的有效性。
表2:在VoxCeleb说话人验证数据集上的性能与效率权衡(基于WavLM Base+)
| 模型 | 稀疏度 | 参数量 | 推理加速 (CPU/GPU) | Vox1-EER (%) | ||
|---|---|---|---|---|---|---|
| O | E | H | ||||
| WavLM Base+ | 0% | 95.6 M | - / - | 0.70 | 0.69 | 1.40 |
| Ours (HP) | 60% | 38.9 M | 2.2× / 2.0× | 0.70 | 0.78 | 1.50 |
| 70% | 29.5 M | 2.9× / 2.6× | 0.73 | 0.84 | 1.61 | |
| 80% | 19.9 M | 3.8× / 3.4× | 0.92 | 1.02 | 1.91 |
关键发现:在VoxCeleb上,HP方法能在大幅减少参数和提升推理速度的同时,保持极高的准确率。在70%稀疏度时,参数减少近2/3,EER仅有轻微上升(例如Vox1-H从1.40%到1.61%)。
剪枝模式分析(图2,图3):
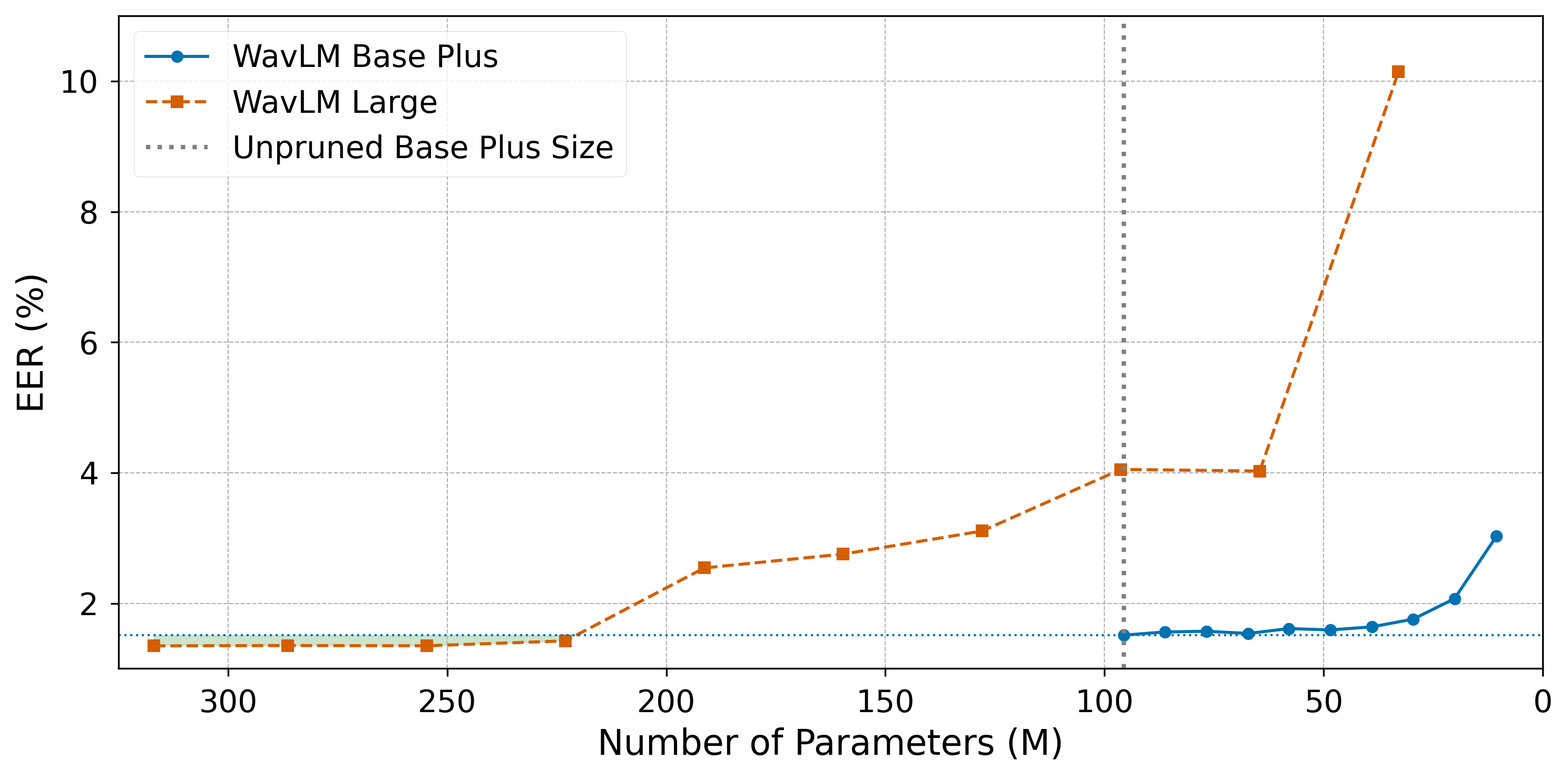 图2显示,在ASVspoof5数据集上剪枝至50%时,HP方法学习到的剪枝模式与基线方法(均匀剪枝)显著不同,表现为非均匀的、任务特定的结构。
图2显示,在ASVspoof5数据集上剪枝至50%时,HP方法学习到的剪枝模式与基线方法(均匀剪枝)显著不同,表现为非均匀的、任务特定的结构。
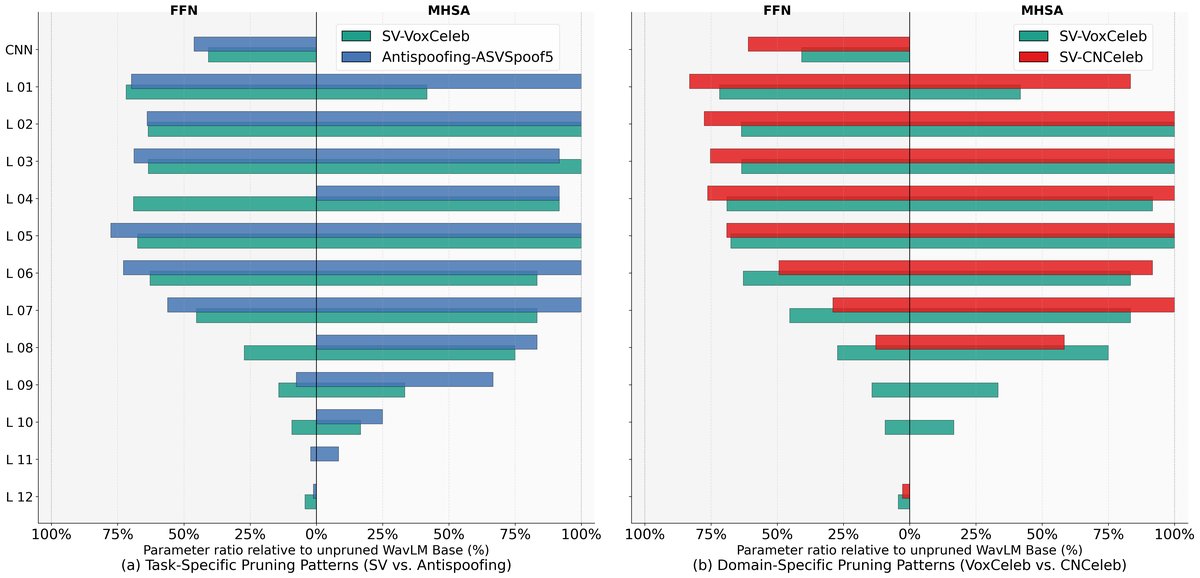 图3进一步揭示了这种特异性:(a) 对于反欺骗任务,模型更倾向于保留较低层的MHSA模块以检测细微声学伪影;而对于说话人验证任务,则更多保留中上层模块以捕获说话人身份信息。(b) 对于同一SV任务,在不同数据域(VoxCeleb vs. 更多样化的CN-Celeb)上训练,剪枝模式也不同,训练数据更多样化时,上层被剪枝得更激进。
图3进一步揭示了这种特异性:(a) 对于反欺骗任务,模型更倾向于保留较低层的MHSA模块以检测细微声学伪影;而对于说话人验证任务,则更多保留中上层模块以捕获说话人身份信息。(b) 对于同一SV任务,在不同数据域(VoxCeleb vs. 更多样化的CN-Celeb)上训练,剪枝模式也不同,训练数据更多样化时,上层被剪枝得更激进。
正则化效应(图4):
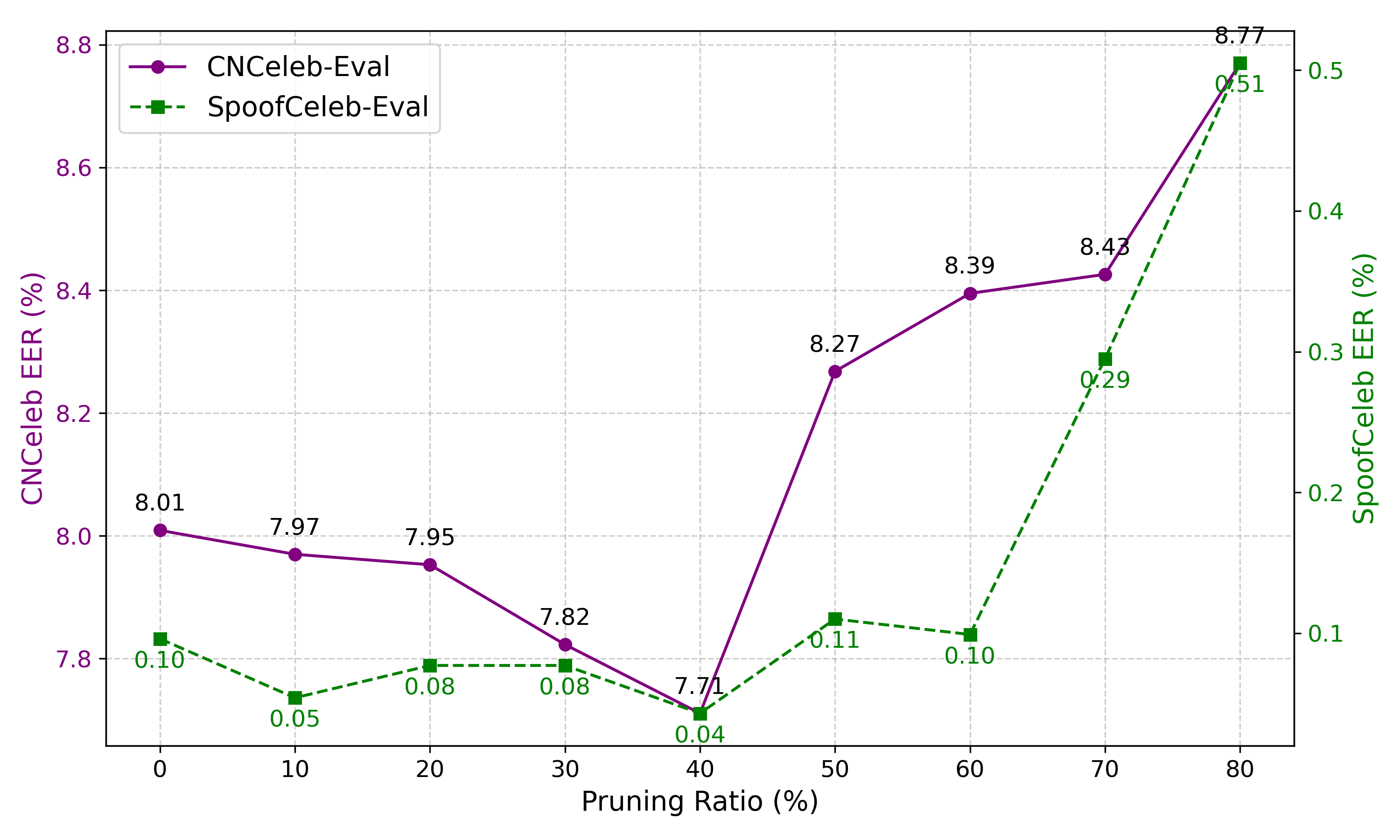 图4展示了在CN-Celeb和SpoofCeleb两个数据集上,模型性能随稀疏度变化呈“U型”曲线,表明中等程度的剪枝能起到正则化作用,提升模型泛化能力。
图4展示了在CN-Celeb和SpoofCeleb两个数据集上,模型性能随稀疏度变化呈“U型”曲线,表明中等程度的剪枝能起到正则化作用,提升模型泛化能力。
跨模型规模分析(图5):
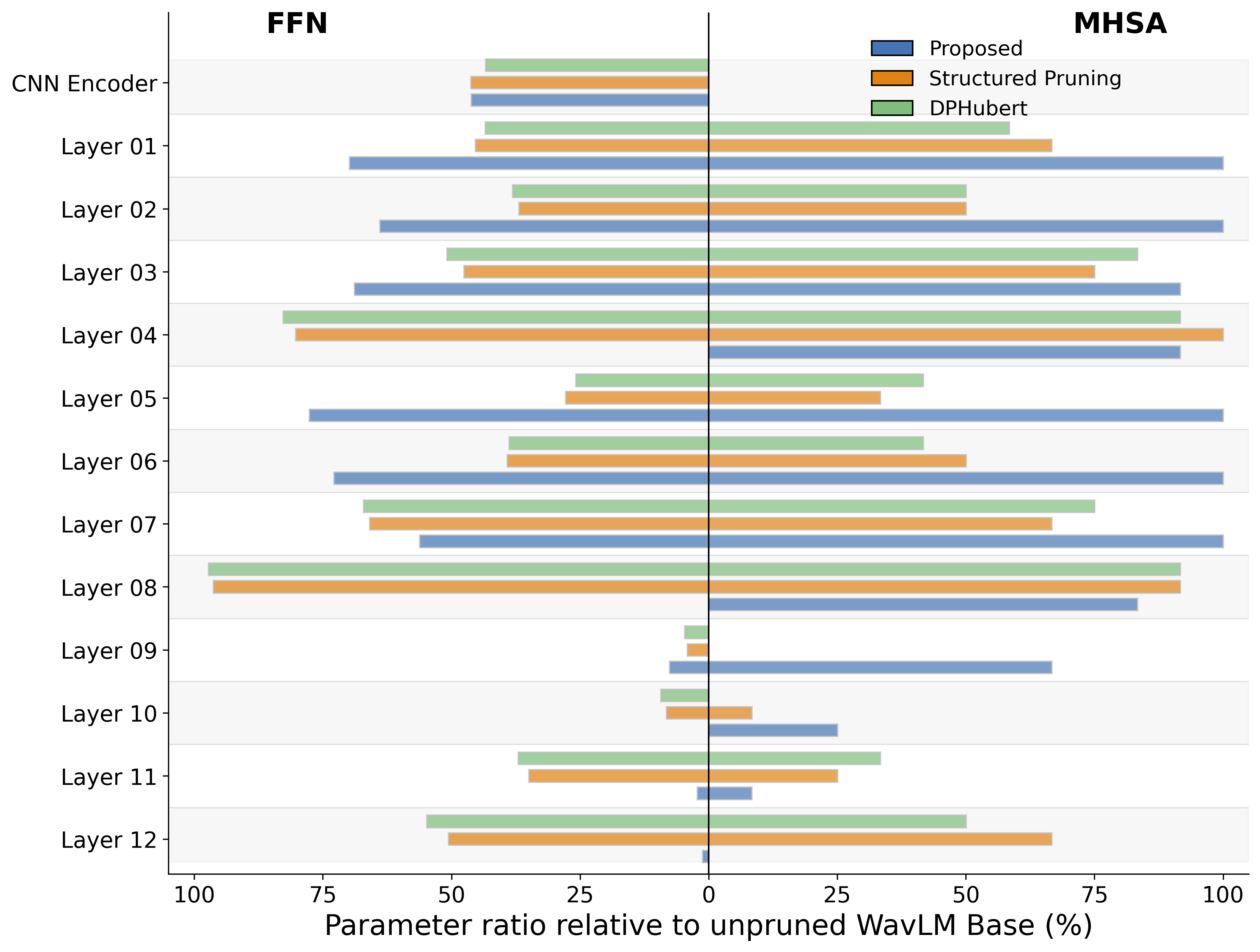 图5对比了在Vox1-H测试集上,剪枝WavLM Base+和WavLM Large模型的结果。令人惊讶的是,经过剪枝的Base模型在相同参数量级下性能优于剪枝后的Large模型,这表明选择合适的基础模型进行精细剪枝可能比直接压缩最大的模型更有效。
图5对比了在Vox1-H测试集上,剪枝WavLM Base+和WavLM Large模型的结果。令人惊讶的是,经过剪枝的Base模型在相同参数量级下性能优于剪枝后的Large模型,这表明选择合适的基础模型进行精细剪枝可能比直接压缩最大的模型更有效。
⚖️ 评分理由
- 学术质量:6.0/7
- 创新性:提出了一种新颖、简洁的单阶段剪枝-微调统一框架,具有明确的创新价值。
- 技术正确性:技术路线清晰,基于可微分门控和L0正则化的方法在理论上成熟,实验设计合理。
- 实验充分性:实验非常全面,覆盖了两个任务(SV, Anti-spoofing)、多个数据集(VoxCeleb, CN-Celeb, ASVspoof5, SpoofCeleb)、两个模型规模(Base, Large)和多个稀疏度级别,并提供了深入的模式分析。
- 证据可信度:结果与基线对比明显,消融分析(如剪枝模式可视化)有力地支持了结论。主要不足是部分训练细节(如优化器、学习率)未公开,略微影响完全复现的可信度。
- 选题价值:1.5/2
- 前沿性:模型压缩是当前大模型部署的热点问题,该工作将压缩与下游任务直接结合,符合前沿趋势。
- 潜在影响与应用空间:直接面向移动/边缘设备部署的实际需求,具有明确的应用价值,尤其对说话人验证等安全敏感场景。
- 读者相关性:对从事语音模型轻量化、部署优化以及相关任务研究的读者有较高参考价值。
- 开源与复现加成:0.5/1
- 论文提供了模型权重的HuggingFace链接(
https://huggingface.co/JYP2024/...),这极大地便利了结果验证和应用。 - 然而,未提供官方代码仓库链接,仅依赖权重文件进行复现仍有较高门槛,因此复现加成有限。
- 论文提供了模型权重的HuggingFace链接(