📄 How Far Do SSL Speech Models Listen for Tone? Temporal Focus of Tone Representation under Low-Resource Transfer
#语音识别 #自监督学习 #迁移学习 #多语言 #低资源
✅ 6.5/10 | 前50% | #语音识别 | #自监督学习 #迁移学习 | #自监督学习 #迁移学习
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 高
👥 作者与机构
- 第一作者:Minu Kim(KAIST电气工程学院)
- 通讯作者:未说明
- 作者列表:Minu Kim(KAIST电气工程学院)、Ji Sub Um(KAIST电气工程学院)、Hoirin Kim(KAIST电气工程学院)
💡 毒舌点评
这篇论文系统性地分析了四种复杂声调语言在SSL模型中的表示,并创新性地使用梯度敏感性分析来量化“听”的时间范围,这是其最大的方法学亮点。但其核心贡献更偏向于现象观察与分析,而非提出一个新的、可直接用于提升性能的模型或算法,且实验部分仅限于分析现有模型,缺乏提出新方法或在标准benchmark上与SOTA对比,因此影响力受限。
🔗 开源详情
- 代码:论文中仅提及并引用了一个用于缅甸语文本到音素转换的开源工具(burmese-G2P)。未提及本论文核心实验(模型微调、梯度分析等)的代码仓库链接。
- 模型权重:未提及是否公开微调后的SSL模型权重。
- 数据集:使用的FLEURS, CommonVoice, RAVDESS, LibriSpeech, VoxCeleb1均为公开数据集,论文给出了引用。
- Demo:未提及。
- 复现材料:未说明训练细节(如学习率、batch size)、硬件配置、完整的分析脚本或配置文件。仅提供了方法的大致描述和G2P工具链接。
- 论文中引用的开源项目:引用了 burmese-G2P(G2P工具)、Phonemizer [25](文本转音素工具)。
- 整体开源情况:论文未提及完整的开源计划。仅部分依赖于已有的开源工具,核心研究内容的复现需要大量额外工作。
📌 核心摘要
- 问题:自监督学习(SSL)语音模型在表示词汇声调方面的能力,尤其是在普通话以外的复杂声调语言中尚未得到充分研究,其在低资源条件下的迁移机制也不明确。
- 方法核心:首先利用声学特征(log-Mel)和逻辑回归建立各语言声调识别所需的最佳时间跨度基线;然后,提出一种基于梯度的层间探测方法,通过分析SSL模型(如XLS-R)在微调后对声调分类的梯度能量分布,来量化模型对声调信息的时间关注范围(中心半径
r_com)。 - 新意:研究拓展了普通话以外的声调语言(缅甸语、泰语、老挝语、越南语),并首次系统分析了SSL模型对声调的“时间分辨率”以及不同微调任务(ASR、情绪识别、性别分类等)如何塑造这种分辨率。
- 主要实验结果:声学基线显示,缅甸语/泰语声调需约100ms时间窗口,老挝语/越南语需约180ms。梯度分析表明,在目标语言ASR微调后,SSL模型的梯度能量分布与这些语言特定的时间基线最为匹配(见图3,图5)。相比之下,基于语音韵律或说话人属性的微调任务导致模型关注的时间跨度过长,偏离声调本质。具体宏F1分数图表见图4,但论文未给出所有对比的精确数值。
- 实际意义:为低资源声调语言的语音技术(如ASR)提供了选择预训练模型和微调策略的指导,强调了微调任务与语言声调特性对齐的重要性。
- 主要局限性:研究仅限于分析现有模型,并未提出新的模型架构或训练目标;结论主要基于声调分类的探测任务,对实际ASR或TTS性能的提升效果未直接验证;所分析的模型和任务组合虽全面,但未与其他旨在提升声调表示的特定方法进行对比。
🏗️ 模型架构
本文并未提出新的模型架构,而是对现有的自监督语音表征模型进行分析。论文中分析的模型主要包括:
- wav2vec 2.0 Large: 基础自监督语音编码器。
- XLS-R 300M: wav2vec 2.0的多语言扩展。
- MMS 300M: Meta推出的多语言多任务SSL模型。
- mHuBERT-147: 一个紧凑的多语言HuBERT变体。
这些模型的架构细节(如Transformer编码器、量化模块等)在论文中未详细说明,因为它们都是已发表模型。论文的核心是分析这些模型在处理声调信息时内部表征的特性,而非模型本身。分析流程如图所示:
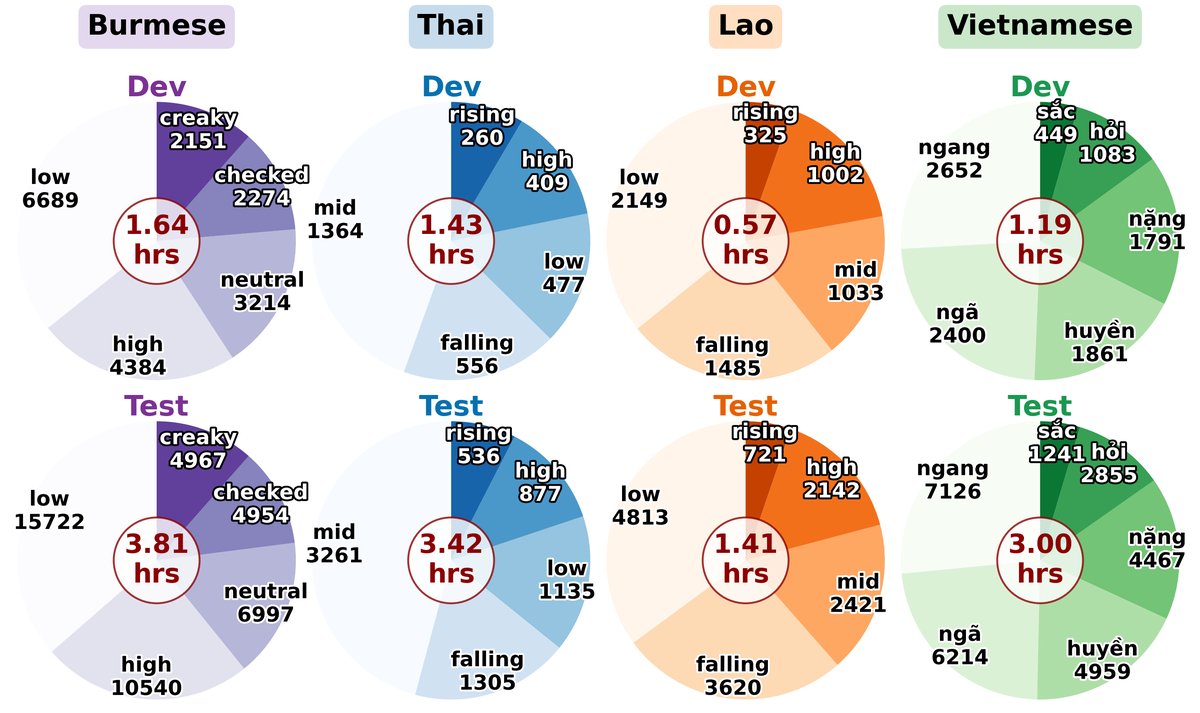 图1:展示了四种目标语言的声调分布和数据集规模,说明了研究问题的背景和数据的低资源特性。
图1:展示了四种目标语言的声调分布和数据集规模,说明了研究问题的背景和数据的低资源特性。
论文没有提供针对本研究的完整架构图,分析是针对上述现有模型的内部表示进行的。
💡 核心创新点
- 跨语言声调时间跨度的系统量化:首次系统性地通过实验方法(log-Mel特征+逻辑回归)估算了四种复杂声调语言(缅甸语、泰语、老挝语、越南语)声调识别所需的声学时间跨度,建立了分析SSL模型表示的“地面真值”基线。
- 基于梯度的声调时间敏感性分析方法:提出了一种新的分析工具——层间梯度能量分布分析。通过计算SSL模型各层在预测声调类别时对输入的梯度,并分析其在时间维度上的能量集中度(以中心半径
r_com度量),从而量化模型对声调信息的“听觉焦点”有多宽。 - 揭示任务驱动的声调表示迁移规律:通过对比不同下游微调任务(目标语言ASR、跨语言ASR、情绪/性别识别等),发现只有声调识别任务(ASR)能有效引导SSL模型的时间关注范围与语言本身的声调跨度对齐,而其他任务则会产生偏差,从而证实了声调表示的可迁移性高度依赖于微调任务的性质。
- 扩展研究范围至低资源复杂声调语言:将声调分析的研究视野从主要关注的普通话扩展到声调系统更为复杂、在语音技术中相对低资源的东南亚语言,填补了研究空白。
🔬 细节详述
- 训练数据:使用 FLEURS 语料库,包含缅甸语、泰语、老挝语和越南语数据。ASR模型在训练集上微调,声调探测分类器在开发集上训练并在测试集上评估,确保无数据泄露。
- 损失函数:论文未详细说明SSL模型微调所使用的损失函数(通常为ASR的CTC损失)。分析部分(梯度计算)基于已微调模型对声调标签的分类交叉熵损失。
- 训练策略:论文未提供SSL模型微调的具体学习率、batch size、优化器等超参数。仅说明了微调的数据集(如FLEURS, CommonVoice v22.0)。
- 关键超参数:分析中使用的主要模型架构大小已列出(如XLS-R 300M)。关键分析参数是时间窗口(20-300ms)和梯度能量分析的时间偏移量(Δt)。
- 训练硬件:未说明。
- 推理细节:不适用。分析是在微调后的模型上进行的,不涉及特定解码策略。
- 正则化或稳定训练技巧:未说明。
- 音高对齐方法:使用语言特定的G2P工具(缅甸语:burmese-G2P;其他:espeak)获取音素和声调标签,然后利用基于CTC的强制对齐(使用同一语料库微调的wav2vec 2.0模型)获取时间对齐的声调单元。
📊 实验结果
论文的核心实验结果主要通过图表展示:
基线时间跨度分析 (图2)
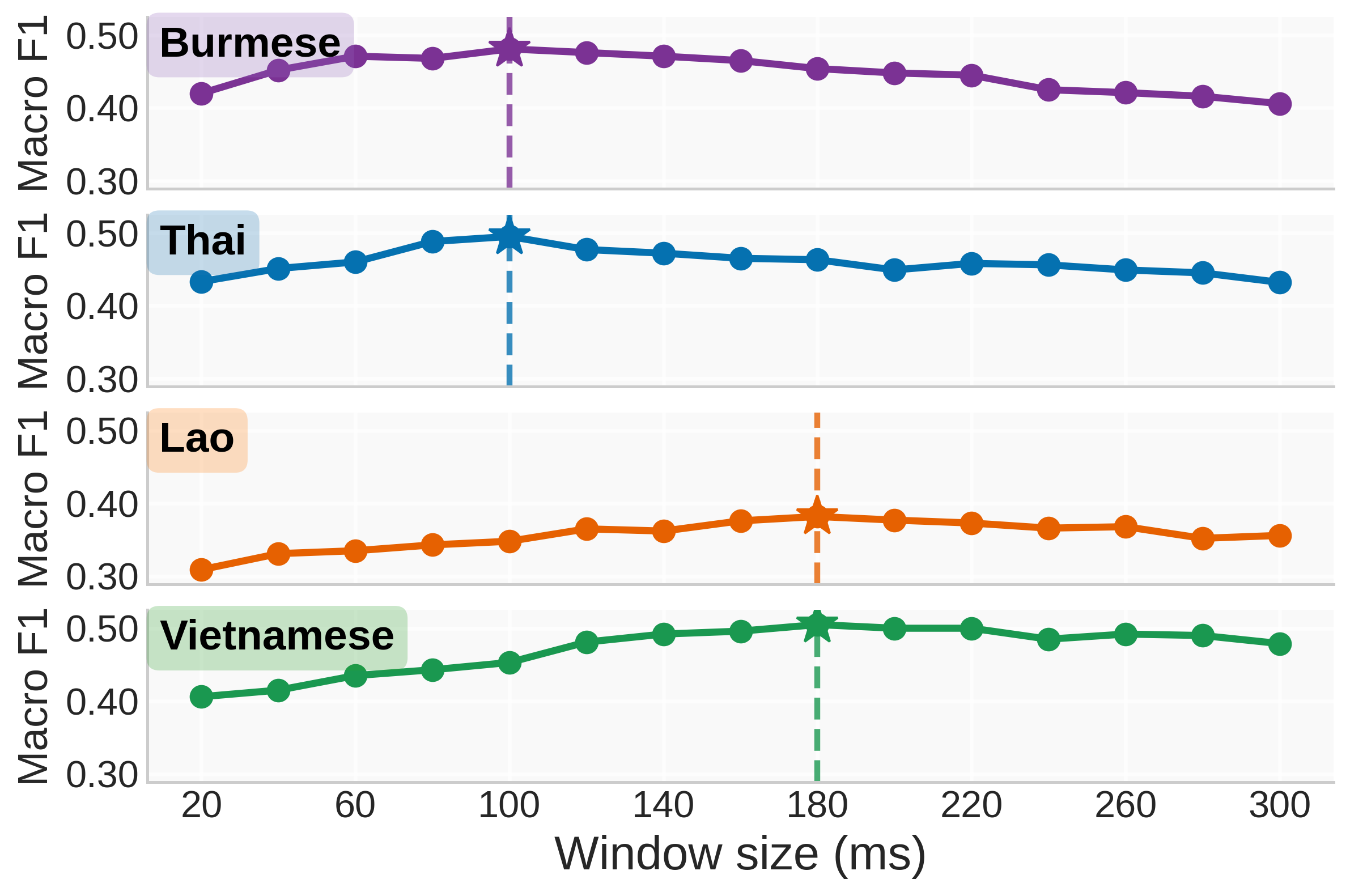 图2:显示不同窗口长度(20-300ms)下逻辑回归分类器的宏F1分数。缅甸语和泰语在100ms左右达到峰值,而老挝语和越南语在180ms左右达到峰值,超过此范围性能下降。这确立了语言特定的声调时间跨度基线。
图2:显示不同窗口长度(20-300ms)下逻辑回归分类器的宏F1分数。缅甸语和泰语在100ms左右达到峰值,而老挝语和越南语在180ms左右达到峰值,超过此范围性能下降。这确立了语言特定的声调时间跨度基线。基于梯度的时间敏感性分析 (图3)
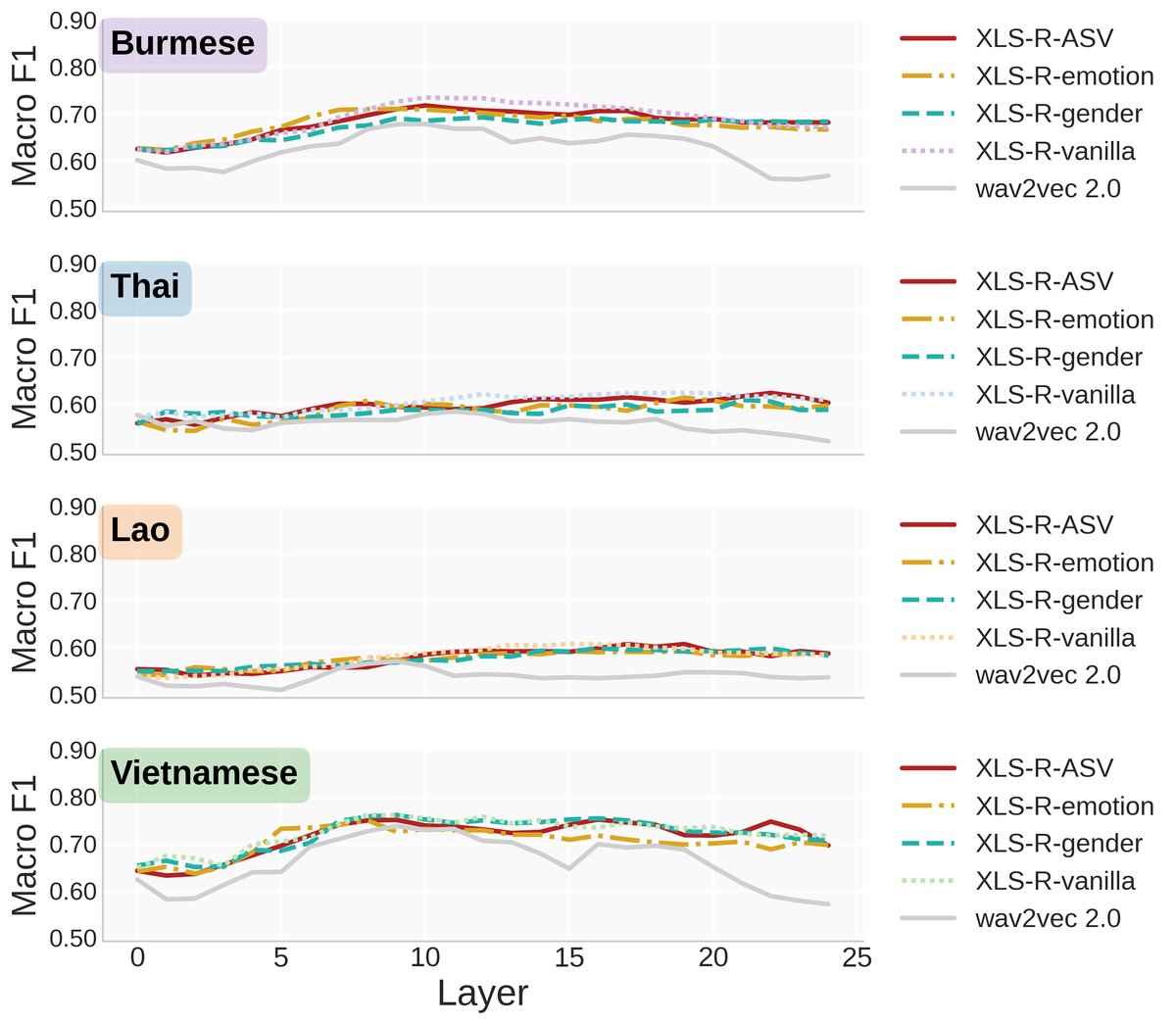 图3:展示了XLS-R模型在为目标语言ASR微调后,各层梯度能量在时间偏移量上的归一化分布。缅甸语/泰语的梯度能量紧密集中在声调中心附近(窄范围),而老挝语/越南语的梯度能量分布更宽,这与图2的声学基线高度一致。
图3:展示了XLS-R模型在为目标语言ASR微调后,各层梯度能量在时间偏移量上的归一化分布。缅甸语/泰语的梯度能量紧密集中在声调中心附近(窄范围),而老挝语/越南语的梯度能量分布更宽,这与图2的声学基线高度一致。不同微调任务的层间探测性能 (图4)
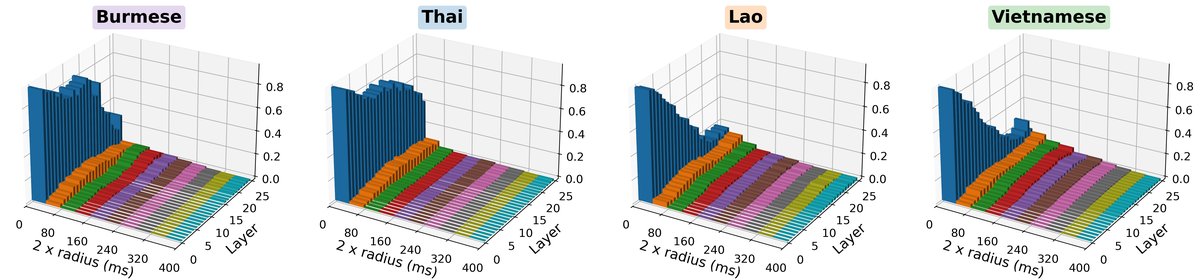 图4:展示了多种SSL模型和微调设置下,各层对声调分类的宏F1分数。关键发现:a) 性能峰值通常出现在中高层(12-24层)。b) 目标语言ASR微调(XLS-R-target)在所有语言上均获得最佳性能,显著高于基线模型。c) 跨语言ASR微调中,普通话(含声调)优于英语。d) 韵律/说话人任务微调(情绪、性别、ASV)的性能与未微调模型(vanilla)几乎无差别。
图4:展示了多种SSL模型和微调设置下,各层对声调分类的宏F1分数。关键发现:a) 性能峰值通常出现在中高层(12-24层)。b) 目标语言ASR微调(XLS-R-target)在所有语言上均获得最佳性能,显著高于基线模型。c) 跨语言ASR微调中,普通话(含声调)优于英语。d) 韵律/说话人任务微调(情绪、性别、ASV)的性能与未微调模型(vanilla)几乎无差别。不同微调任务下的有效时间跨度 (图5, 6, 7)
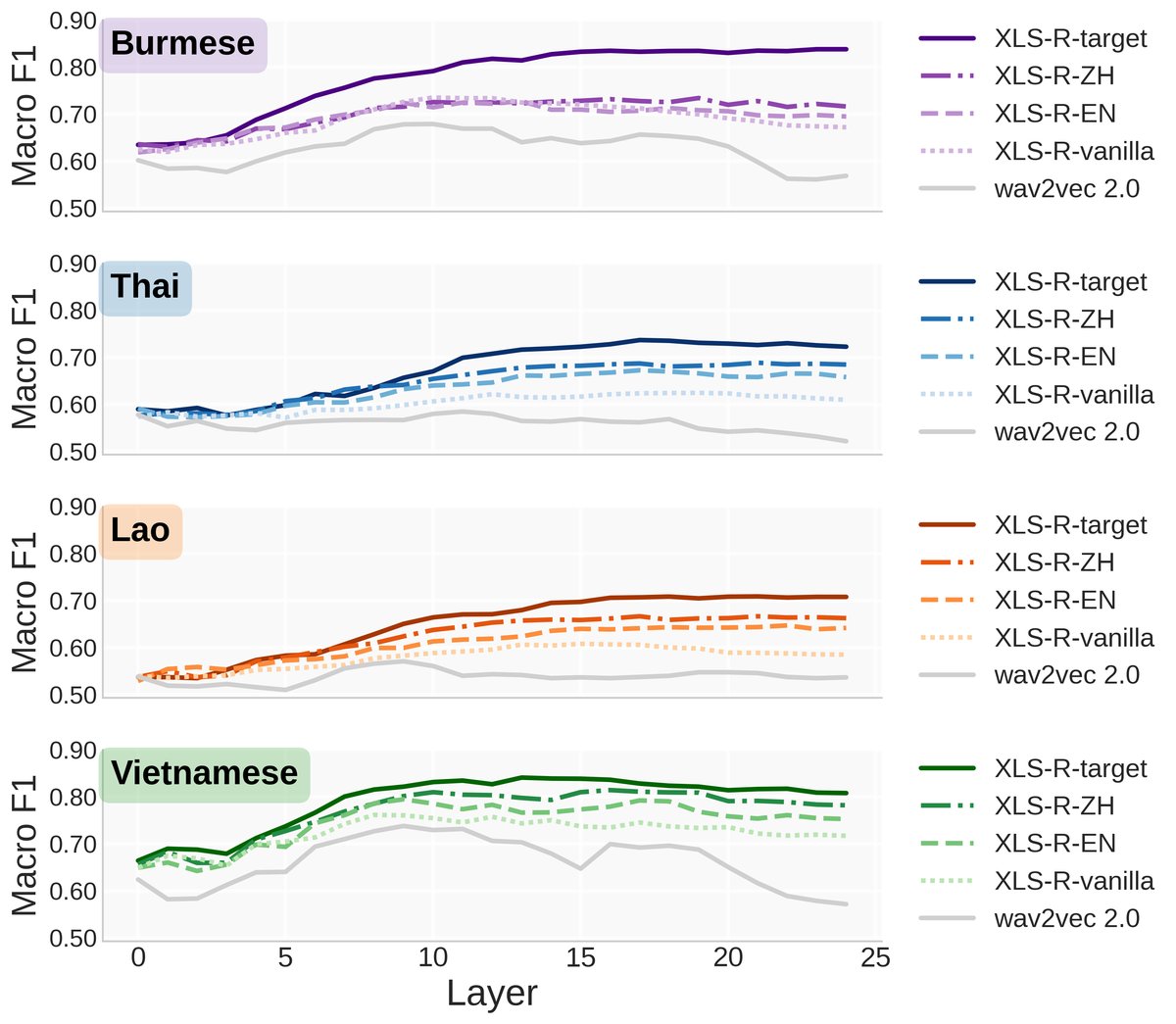 图5:XLS-R模型在不同微调任务下,高层(12-24)和低层(0-11)梯度有效跨度(2r_com)的箱线图。红色线为图2的声学基线。只有目标语言ASR微调的跨度与基线高度吻合。其他任务,尤其是韵律/说话人任务,导致跨度显著过长。*
图5:XLS-R模型在不同微调任务下,高层(12-24)和低层(0-11)梯度有效跨度(2r_com)的箱线图。红色线为图2的声学基线。只有目标语言ASR微调的跨度与基线高度吻合。其他任务,尤其是韵律/说话人任务,导致跨度显著过长。*
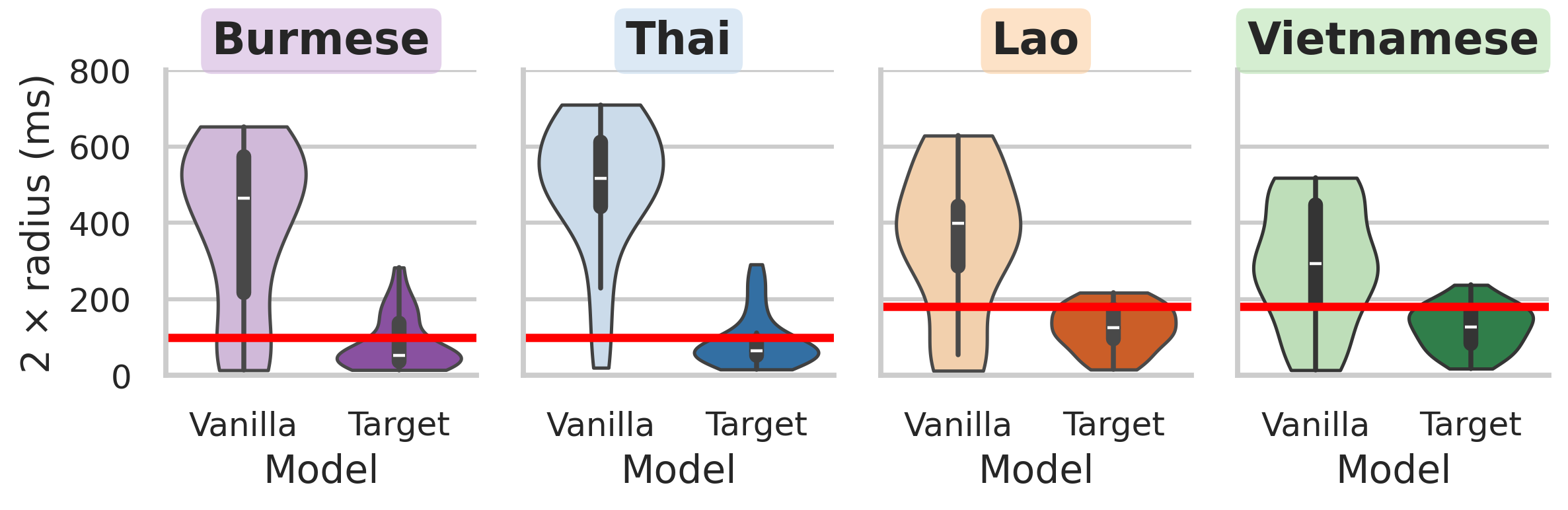 图6:MMS模型的有效时间跨度分布。同样,目标语言ASR微调实现了最佳的跨度对齐。
图6:MMS模型的有效时间跨度分布。同样,目标语言ASR微调实现了最佳的跨度对齐。
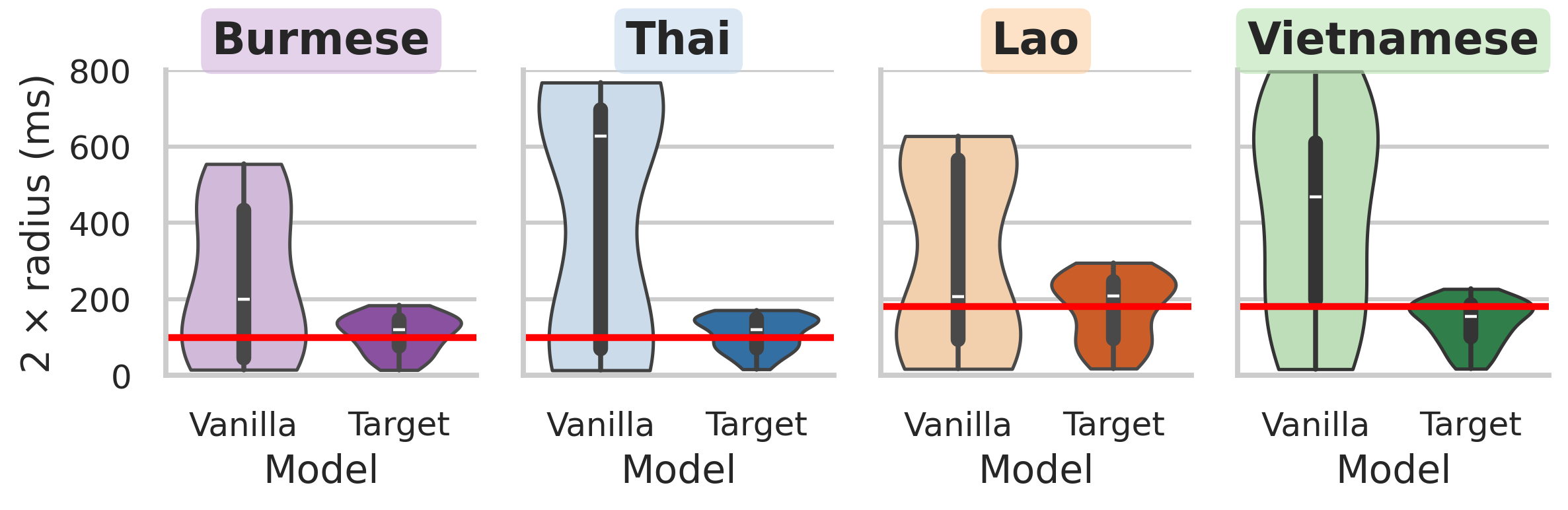 图7:mHuBERT-147模型的有效时间跨度分布。模式与XLS-R和MMS一致。
图7:mHuBERT-147模型的有效时间跨度分布。模式与XLS-R和MMS一致。
关键数值结论:论文未以表格形式给出所有对比的精确F1数值,但通过图表和文字明确指出:目标语言ASR微调是使SSL模型声调表示质量(以探测F1和时间跨度对齐度衡量)最优的关键;普通话ASR微调次之;英语ASR微调优于未微调模型;而情绪、性别、说话人验证等任务的微调对声调表示几乎没有帮助甚至有害。
⚖️ 评分理由
- 学术质量:5.5/7:论文提出了有价值的科学问题(SSL模型对声调的时间感知),并设计了一套合理的分析方法(声学基线+梯度探测)来研究它。实验设计较为全面,涵盖了多种模型、语言和微调策略,结果具有启发性。然而,创新性主要体现在分析方法和问题视角上,而非提出一个新的、具有突破性性能提升的模型或算法。所有结论都基于分析现有模型,缺乏“从0到1”的贡献,因此分数中等。
- 选题价值:1.5/2:研究了一个重要但相对垂直的领域(非普通话声调建模),对于推动多语言语音技术,尤其是低资源声调语言的语音识别和合成有实际指导意义。与纯文本NLP或通用语音任务相比,其受众和直接应用范围相对狭窄,故未给满分。
- 开源与复现加成:-0.5/1:论文提供了缅甸语G2P工具的GitHub链接(https://github.com/kyaw-yethu/burmese-G2P),这是有利的。但核心的实验代码、微调后的SSL模型权重、完整的数据预处理和分析脚本均未提供。论文中也缺少关键训练超参数和硬件细节,严重限制了工作的可复现性。因此给予负分。