📄 HiFi-HARP: A High-Fidelity 7th-Order Ambisonic Room Impulse Response Dataset
#数据集 #混合仿真 #麦克风阵列 #空间音频 #声源定位
✅ 7.5/10 | 前25% | #数据集 | #混合仿真 | #麦克风阵列 #空间音频
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Shivam Saini(Leibniz University Hannover, Institut für Kommunikationstechnik)
- 通讯作者:未说明
- 作者列表:Shivam Saini(Leibniz University Hannover, Institut für Kommunikationstechnik)、Jürgen Peissig(Leibniz University Hannover, Institut für Kommunikationstechnik)
💡 毒舌点评
亮点:论文的亮点在于其“集大成”的工程实现——将高阶Ambisonics(7阶)、混合声学仿真(低频波导+高频射线追踪)以及来自3D-FRONT的复杂室内场景这三个关键要素成功融合并规模化,形成了一个在技术规格上超越以往同类数据集(如HARP、GWA)的资源。短板:主要短板在于其“高保真”声称部分依赖于文本语义的材料映射(图2,图3),这引入了一个与真实世界材料属性不确定性的间隙,使得数据集的保真度上限可能受限于该映射方法的精度,而非物理仿真本身的极限。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及。
- 数据集:公开提供。论文明确指出数据可在HuggingFace上获取:
https://huggingface.co/datasets/whojavumusic/hifi_harp。 - Demo:论文中未提及在线演示。
- 复现材料:论文详细描述了数据生成流水线,包括使用的场景库(3D-FRONT)、仿真工具(pffdtd, G-Sound)、麦克风阵列设计等,这为复现提供了重要信息。但未提供完整的配置文件、脚本或预处理步骤。
- 论文中引用的开源项目:
pffdtd: FDTD声学仿真软件(https://github.com/bsxfun/pffdtd)。G-Sound: 交互式声音传播库。3D-FRONT: 3D室内场景数据集。SentenceFormer: 用于文本嵌入的模型。Fliege-Maier grid: 用于球形麦克风阵列设计的网格点生成方法。
📌 核心摘要
- 解决的问题:为了解决现有大规模房间脉冲响应(RIR)数据集要么Ambisonic阶数低(如FOA),要么声学仿真方法单一(仅几何声学或仅波导),要么房间场景过于简单(鞋盒模型)的问题,本论文旨在创建一个结合了高阶、高保真仿真和复杂真实场景的大规模RIR数据集。
- 方法核心:方法核心是构建一个混合声学仿真流水线:对900 Hz以下的低频采用基于有限差分时域(FDTD)的波导仿真,以准确模拟衍射等波动现象;对900 Hz以上的高频采用射线追踪方法进行高效仿真。数据基于3D-FRONT数据库中复杂、带家具的室内场景,并通过基于语义标签的文本分类方法为物体表面分配频率相关的声学吸收系数。最终将原始RIR编码为AmbiX格式(ACN)的7阶Ambisonic表示。
- 相比已有方法新在哪里:HiFi-HARP是首个将7阶高阶Ambisonics与混合波导-几何声学仿真相结合,并应用于大规模复杂室内场景的数据集。相比仅用图像源法(ISM)的HARP数据集,它引入了更精确的低频波动效应;相比仅用几何仿真的SoundSpaces,它提供了更高的Ambisonic阶数和低频精度;相比单通道的GWA数据集,它提供了完整的高阶空间信息。
- 主要实验结果:
- 数据集规模与特性:包含超过10万个7阶RIR,场景覆盖约2000个复杂室内空间,RT60主要分布在0.2-0.8秒,中频吸收系数在0.2-0.9之间。
- 下游任务验证:
- T60估计(表II):使用HiFi-HARP数据对测量数据增强训练后,模型在真实测试集上的性能显著提升,Pearson相关系数(ρ)从0.85提高到0.92,MSE从0.018降至0.012。
- DOA估计(表III):训练数据的Ambisonic阶数越高,DOA估计模型在真实BRIR测试集上的性能越好。使用7阶数据训练的模型达到最低MSE(1.93)和最高的Pearson相关系数(0.90)。
- 仿真验证:与商业仿真软件Treble及实验室测量对比(图2,图3),显示在不同频带存在一定误差,主要归因于材料属性映射的不精确。
- 实际意义:为声场录制、空间音频渲染(VR/AR)、声源定位、去混响、房间声学参数估计等领域的数据驱动算法研究和基准测试提供了前所未有的高质量、大规模、多样化的训练和评估资源。
- 主要局限性:局限性包括:1)材料属性通过文本语义映射获取,与真实测量存在偏差;2)所有场景和声源均为静态,不包含动态变化;3)64通道球形麦克风阵列是一个物理近似,在900 Hz以上存在空间混叠;4)未建模家具的细微结构和房间内人员的存在。
🏗️ 模型架构
本文的核心贡献是一个数据生成流水线(Pipeline),而非一个用于推理的端到端模型。该流水线的主要架构和流程如下:
场景与材料准备:
- 输入:3D-FRONT数据集中的复杂室内3D模型(带家具、布局和语义标签)。
- 处理:为每个表面(墙、地板、家具)分配频率相关的声学吸收系数。这是通过一个基于SentenceFormer的文本分类器,将语义标签(如“木地板”、“瓷砖墙”)映射到公开的测量吸收光谱查找表来完成的。这确保了材料属性的现实性。
麦克风阵列设计:
- 低频仿真:采用一个64通道虚拟球形麦克风阵列,半径为42厘米(与商用Eigenmike EM64一致),使用Fliege-Maier网格近均匀布置。设计动机是避免波形冗余并控制计算成本。
- 高频仿真:采用无需显式阵列的方法。射线追踪过程直接在球谐域存储方向性数据,允许直接生成最高9阶的Ambisonic信号,简化了高频仿真流程。
混合声学仿真:
- 低频路径(≤900 Hz):使用基于FDTD的波导求解器(pffdtd)[21]。以约2厘米的网格分辨率模拟波动现象,并应用基于材料属性的阻抗边界条件。
- 高频路径(>900 Hz):使用射线追踪求解器(G-Sound库)[19], [20]。该方法高效处理镜面反射和散射。
- 融合:低频的FDTD输出被转换到球谐域,然后与高频的射线追踪结果使用加权交叉策略[3]进行平滑合并,确保在900 Hz交叉点处的连续性,得到完整的宽带RIR。
编码与输出:
- 生成的原始RIR直接编码为AmbiX格式(ACN通道排序)的7阶Ambisonic RIR。
- 为提高效率,开发了定制流水线:将64个麦克风位置分为10组进行批量仿真,将每个房间的计算量从3200次减少到10次,加速了320倍。
输出:
- 输入:3D室内模型、语义标签。
- 输出:超过10万个7阶Ambisonic RIR文件,每个对应一个房间中多个源-接收器组合。
💡 核心创新点
- 首个大规模高阶HOA与混合仿真的结合:这是论文最核心的创新。此前工作要么阶数低(如SoundSpaces的FOA),要么仿真简单(如HARP的ISM),要么非空间音频(如GWA)。HiFi-HARP首次实现了将7阶高精度空间信息(HOA)与更准确的混合物理仿真(波导+射线追踪)在数万级复杂场景中规模化生成。
- 优化的混合仿真流水线与高效并行化:不仅采用了混合仿真,还通过巧妙的麦克风阵列分组设计(将64麦克风位置打包进10个复合仿真任务),极大地降低了计算复杂度,使得大规模生成高阶HOA RIR在工程上变得可行。
- 基于语义的材料属性自动映射:使用SentenceFormer模型,将3D场景中丰富的语义标签(如“木门”、“沙发”)自动关联到实际测量的声学吸收光谱。这解决了为大规模复杂场景中成千上万个物体手动指定声学属性的巨大难题,是数据集规模化的重要支撑技术。
🔬 细节详述
- 训练数据:数据集本身即为数据生成过程。基础场景来自3D-FRONT数据集,这是一个包含18,968个专业设计的带家具室内场景的集合。论文从中选取了一个广泛的子集。
- 损失函数:不适用。本论文工作是数据生成,而非训练一个神经网络模型。
- 训练策略:不适用。下游任务评估中(T60估计、DOA估计)的训练细节已说明:T60估计模型基于先前工作[34], [35];DOA估计使用了3层CNN,在10,000个样本上训练。但论文未给出具体的学习率、优化器等超参数。
- 关键超参数:
- Ambisonic阶数:7阶。
- 球形麦克风阵列:64通道,半径42厘米,采用Fliege-Maier网格。
- 混合仿真分界点:900 Hz。
- FDTD网格分辨率:约2厘米(对应900 Hz波长)。
- 数据集规模:>100,000 RIRs。
- 场景规模:约2,000个复杂室内空间。
- 训练硬件:论文中未具体说明生成数据集所使用的计算资源。
- 推理细节:不适用。对于下游任务的推理,T60估计是端到端预测;DOA估计是CNN从双耳音频预测方位角,论文未说明推理时的具体策略。
- 正则化或稳定训练技巧:不适用(对于数据生成)。下游任务训练细节未提及。
📊 实验结果
论文主要通过数据集统计特性和下游任务来验证其价值。
表I: 与现有HOA/Ambisonic RIR数据集的比较
| 数据集 | 阶数 | RIR数量 | 场景/变化性 | 仿真方法 |
|---|---|---|---|---|
| BUT-ReverbDB | 0阶 | 1300 | 11个真实房间 | 实测 |
| MESH-RIR | 0阶 | 4400 | 1个房间,2D网格 | 实测 |
| GWA | 0阶 | 2M | ≈6000个真实室内场景 | 混合(波导+射线) |
| dEchorate | 线性阵列 | 1800 | 可变声学条件 | 实测 |
| AIR | 双耳 | 200+ | 4个房间 | 实测 |
| OpenAIR | 1阶 | 50 | 50个极端真实房间 | 实测 |
| C4DM | 1阶 | 700 | 3个房间,多个位置 | 实测 |
| TAU-SRIR | 1阶 | 114 | 9个房间,多个位置 | 实测 |
| SoundSpaces | 1阶 | 17.6M | ≈100个真实室内场景 | 几何(射线追踪) |
| PAN-AR | 2阶 | 21 | 4个真实房间,包含环境噪声/图像 | 实测HOA |
| MOTUS | 3阶 | 3320 | 1个房间,830种家具布置 | 实测 |
| ARNI-SRIR | 4阶 | – | 5种可变声学条件,6自由度 | 实测 |
| HOMULA-RIR | 高阶麦克风+ULA | 25 | 1个研讨室,多个位置 | 实测 |
| HARP | 7阶 | 100K+ | 多样化的合成鞋盒房间 | 图像源法(ISM) |
| HiFi-HARP (本文) | 7阶 | 100K+ | ≈2000个复杂室内场景 | 混合(波导+射线) |
表II: 使用HiFi-HARP数据集增强前后,T60估计模型性能对比
| 训练数据 | Pearson相关系数(ρ) ↑ | MSE ↓ | 偏差 ↓ |
|---|---|---|---|
| 仅实测BRIR | 0.85 | 0.018 | 0.01 |
| 实测BRIR + HiFi-HARP | 0.92 | 0.012 | 0.01 |
表III: 不同Ambisonic阶数训练数据对DOA估计性能的影响(在真实BRIR测试集上评估)
| 训练数据 | MSE ↓ | Pearson相关系数(ρ) ↑ |
|---|---|---|
| 1阶ARIR | 2.34 | 0.85 |
| 3阶ARIR | 2.32 | 0.89 |
| 5阶ARIR | 2.26 | 0.90 |
| 7阶ARIR | 1.93 | 0.90 |
实验结果图表:
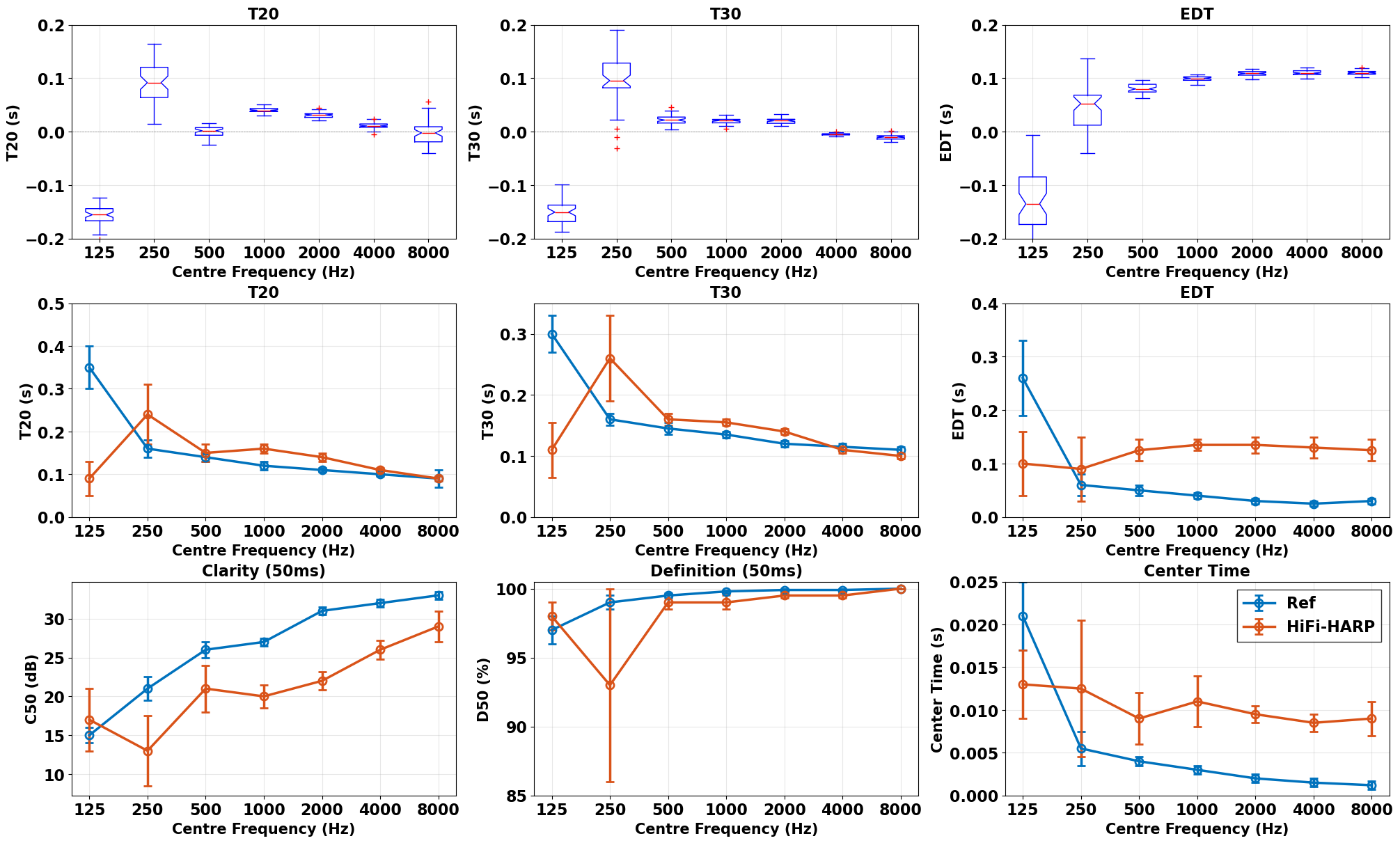 图2显示了本文方法与商业仿真模型Treble在再现GENDA Challenge RIR时的误差。宽带和八度频带的T20 MAPE、EDF MSE以及DRR MSE均被报告。结论是:本文方法与Treble和测量值存在差异,主要原因是本文的材料估计基于语义标签,而非Treble使用的实测吸收和散射系数,后者物理精度更高。
图2显示了本文方法与商业仿真模型Treble在再现GENDA Challenge RIR时的误差。宽带和八度频带的T20 MAPE、EDF MSE以及DRR MSE均被报告。结论是:本文方法与Treble和测量值存在差异,主要原因是本文的材料估计基于语义标签,而非Treble使用的实测吸收和散射系数,后者物理精度更高。
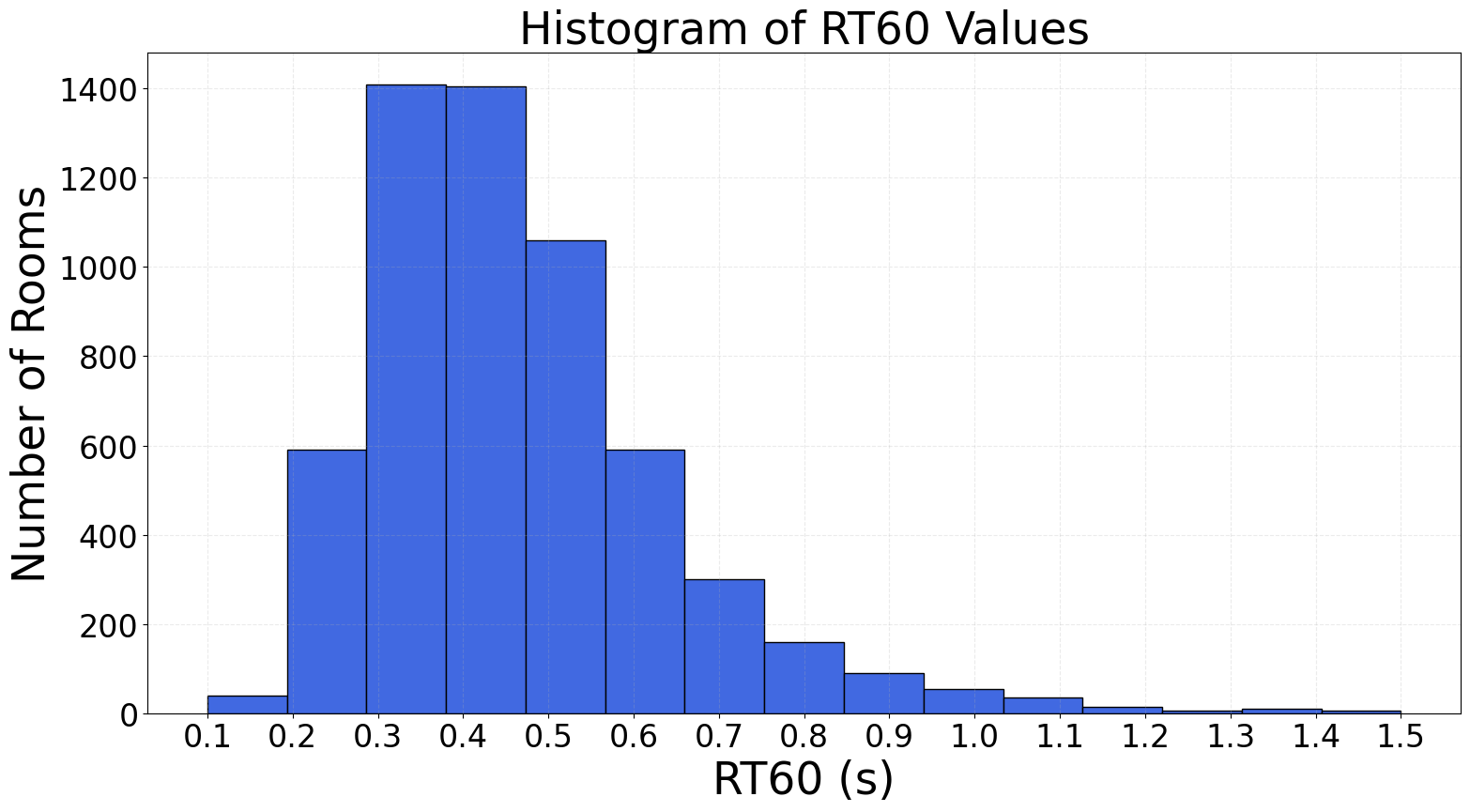 图3对比了使用商用Eigenmike EM32进行真实测量和本文方法提取的声学参数(箱线图)。结论是:两者存在微小误差,可能源于几何简化。材料属性从有效声学分布中采样,可能与特定房间不完全匹配,导致在250 Hz处方差较高。未来工作可通过多模态方法改进保真度。
图3对比了使用商用Eigenmike EM32进行真实测量和本文方法提取的声学参数(箱线图)。结论是:两者存在微小误差,可能源于几何简化。材料属性从有效声学分布中采样,可能与特定房间不完全匹配,导致在250 Hz处方差较高。未来工作可通过多模态方法改进保真度。
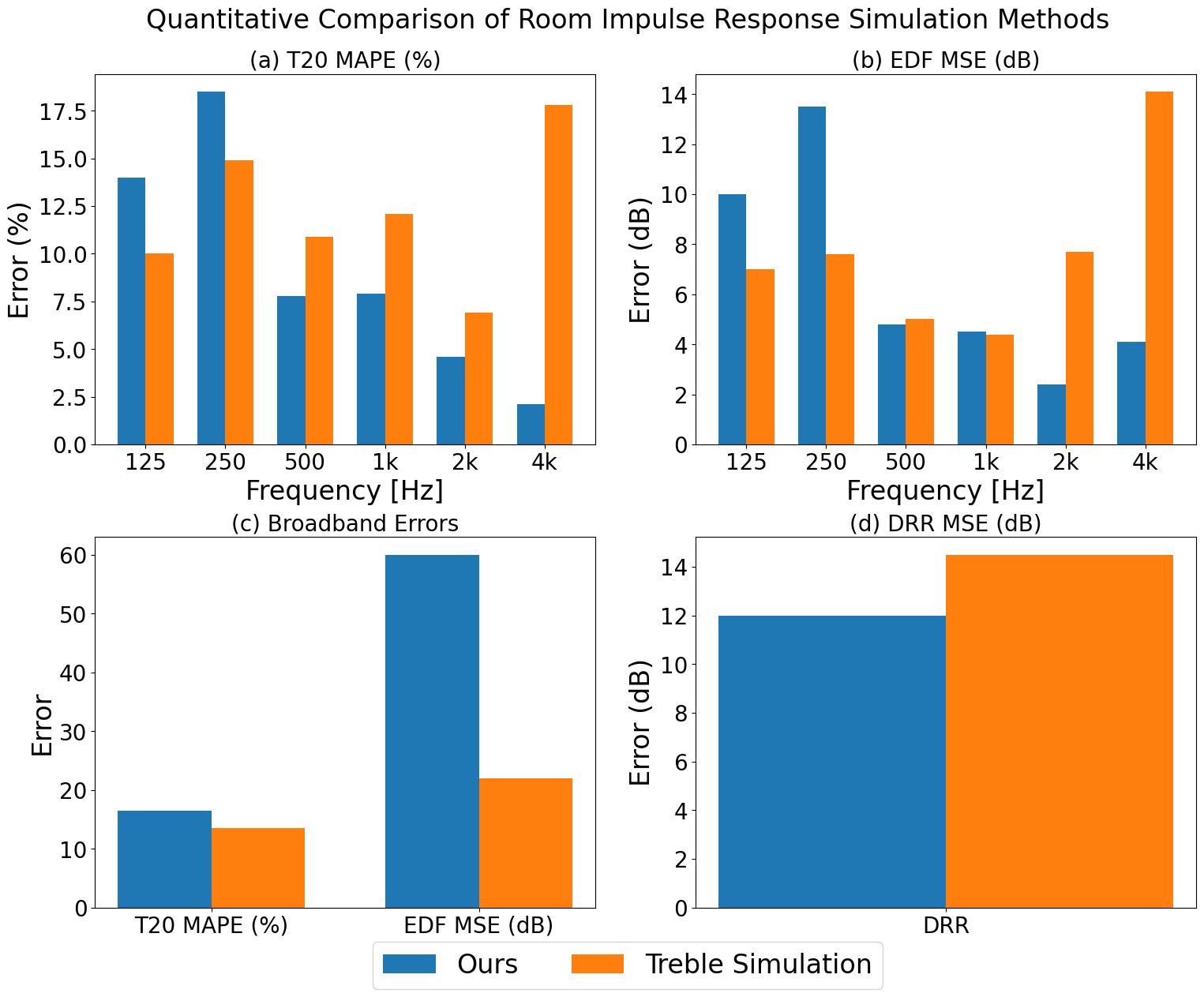 图4展示了HiFi-HARP数据集中RIR的RT60(混响时间)分布。RT60被集中在0.2-0.8秒范围内,覆盖了典型的室内场景,与参考文献[4]的分布相似。
图4展示了HiFi-HARP数据集中RIR的RT60(混响时间)分布。RT60被集中在0.2-0.8秒范围内,覆盖了典型的室内场景,与参考文献[4]的分布相似。
⚖️ 评分理由
- 学术质量:5.5/7。论文的贡献是系统性和工程性的,而非提出一种新的算法理论。其核心创新点(高阶HOA与混合仿真结合)清晰、合理且填补了领域空白。技术实现细节丰富,流程描述完整。下游任务的实验设计合理,结果(表II, III)提供了令人信服的证据,表明该数据集能有效提升���型性能。主要扣分项在于:1)核心创新更多是“集成”与“规模化”,突破性略逊于提出全新的模型或理论;2)虽然提供了下游任务验证,但对生成的RIR本身在声学保真度上的全面、客观量化评估(如与大量真实RIR在各种声学指标上的统计比较)仍显不足,部分验证依赖于对现有商业工具和有限测量的对比。
- 选题价值:1.5/2。空间音频是下一代人机交互和媒体体验的关键技术。高质量、大规模、多样化的合成数据是加速该领域AI算法发展的瓶颈之一。本文直接针对这一瓶颈,工作具有明确的实用价值和行业影响力。1.5分是因为相对于一些更宽泛的音频处理任务,该研究方向的受众和应用场景相对聚焦。
- 开源与复现加成:+0.5。论文最大的亮点之一是明确提供了数据集的公开下载地址(HuggingFace),这极大地降低了研究门槛,促进了该领域的工作,是极强的复现和扩展支持。仅因未开源完整生成代码和下游模型权重,未给满分。