📄 Hierarchical Tokenization of Multimodal Music Data for Generative Music Retrieval
#音乐检索 #大语言模型 #多模态模型 #工业应用 #生成模型
✅ 7.0/10 | 前25% | #音乐检索 | #大语言模型 | #多模态模型 #工业应用
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 中
👥 作者与机构
- 第一作者:Wo Jae Lee(Amazon Music, San Francisco, USA)
- 通讯作者:未说明
- 作者列表:Wo Jae Lee(Amazon Music)、Rifat Joyee(Amazon Music)、Zhonghao Luo(Amazon Music)、Sudev Mukherjee(Amazon Music)、Emanuele Coviello(Amazon Music)
💡 毒舌点评
亮点: 论文提出的多模态分层tokenization框架思路清晰,将复杂的音乐元数据系统地转化为LLM可处理的离散序列,并在工业规模的数据集上验证了其有效性,为构建统一的多模态音乐推荐系统提供了一个不错的工程范例。 短板: 核心的RQ-VAE应用和LLM微调部分创新有限,更偏向于系统集成;而实验完全建立在无法公开的私有数据之上,如同“自说自话”,极大削弱了其学术价值和可复现性,使得其性能提升难以被外部独立验证。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开权重。
- 数据集:实验使用的
Dc(160万歌曲元数据)、Dqt和Dr均为专有数据集,未公开。 - Demo:未提及在线演示。
- 复现材料:给出了部分模型架构细节(如RQ-VAE编码器/解码器为4层FFN)、训练超参数(学习率、batch size、epoch数、GPU数量),但未提供完整的训练脚本、配置文件或检查点。对于关键组件(如九种模态的具体编码器网络结构、每个模态RQ-VAE的码本大小
K_mod,l的精确值)描述不够详细。 - 论文中引用的开源项目:引用了Qwen2.5-1.5B-Instruct [23]作为基座LLM,Sentence-BERT [29]用于模态预测模型,CLAP [25]用于音频编码。但未说明是否基于这些项目的官方实现进行修改。
- 总结:论文中未提及开源计划。
📌 核心摘要
本文针对生成式音乐检索任务中如何让大语言模型(LLM)有效表示和理解多模态音乐数据的问题,提出了一种名为3MToken的多模态音乐分层离散化方法。该方法将音频、语义标签、艺术家传记等九种模态的音乐数据,通过模态特定的残差量化变分自编码器(RQ-VAE)转化为层次化的离散token序列。基于此,进一步提出了3MTokenRec,一个经过指令微调的LLM,它能够根据查询意图自适应地加权不同模态,并生成对应的3MToken序列来检索音乐。实验表明,3MToken在内容检索(CBR)任务上,Hit@5分别比最强多模态基线(K-means)高27%(CP数据集)和32%(CO数据集);在文本到音乐检索(T2MR)任务上,3MTokenRec(带模态选择)的平均Precision@K比不带模态选择的版本高10.8%。该研究为工业级音乐推荐系统提供了新的技术路径,但其主要局限在于所有实验均在未公开的专有数据集上进行,且未开源代码与模型,可复现性差。
🏗️ 模型架构
整个系统分为两个主要部分:多模态音乐token(3MToken)的生成和基于此的生成式音乐推荐(3MTokenRec)。

3MToken生成流程:
- 输入: 音乐的多模态原始数据,被分为九个类别:艺术家合作(AC)、基础元数据(BM)、语义标签(ST)、声音特征(SC)、音乐特征(MC)、发布信息(RI)、歌曲事实(SF)、艺术家传记(AB)、曲目消费模式(TC)。
- 数据向量化(Music Data Vectorization): 为每个模态使用专用的编码器将原始数据映射为嵌入向量。例如,文本数据使用预训练文本编码器(4096维),音频使用CLAP-like模型(128维),分类元数据(如日期、节拍)通过分箱/one-hot编码处理,消费数据使用基于会话的协同过滤嵌入模型。
- 分层离散化(Multimodal Music Token Formation): 为每个模态训练一个独立的RQ-VAE模型。RQ-VAE包含一个编码器、L个串行的残差量化码本和一个解码器。输入嵌入
x被编码为潜在表示ze,然后经过L级残差量化。在每一级l,量化器从当前残差rl-1中减去与其最接近的码本向量ekl,并更新残差。最终,量化后的表示ˆzq是所有被选码本向量的和,解码器从ˆzq重构原始嵌入。训练完成后,每个模态的嵌入被转化为一个离散索引序列(k_mod,1, k_mod,2, ..., k_mod,L),并映射为格式为<{模态}{级别}-{索引}>的token字符串。 - 输出: 对于一首歌曲,将所有九个模态的token序列按固定顺序拼接,形成一个完整的多模态音乐token序列。
3MTokenRec检索流程:
- LLM适配: 在一个预训练的LLM(Qwen2.5-1.5B-Instruct)的词表
Voriginal中,加入所有3MToken和边界token(如<begin 3MToken>),形成新词表Vnew。LLM的嵌入矩阵尺寸随之调整。 - 指令微调: 使用“查询-3MToken序列”对数据集
Dqt,对LLM进行指令微调。训练目标是让LLM学会根据自然语言查询,自回归地生成正确的3MToken序列。生成过程被约束为按预定义模态顺序和内部层级顺序进行。 - 模态重要性预测: 使用一个微调的BERT模型,根据输入查询文本,为九个模态输出一个0到10的相关性分数。
- 检索: 推理时,LLM生成一个3MToken序列。然后,在预计算的歌曲token数据库中进行层次化匹配:先匹配Level-1的token,再匹配Level-2,最后匹配Level-3,最终返回Top-k匹配的歌曲。
- LLM适配: 在一个预训练的LLM(Qwen2.5-1.5B-Instruct)的词表
💡 核心创新点
- 多模态分层离散化(3MToken): 将音乐数据系统地划分为九个语义明确的模态类别,并利用RQ-VAE为每个模态独立学习具有粗到细层次结构的离散token表示。相比单一码本的VQ-VAE或直接聚类(K-means),这种层次化表示能更精细地捕捉数据结构,实验显示其在CBR任务上显著优于这两种基线。
- 基于查询意图的自适应模态加权检索: 在生成检索阶段,引入一个独立的模态重要性预测模型,使3MTokenRec能够根据用户查询的语义(如“90年代摇滚”更依赖时代和流派信息,“快节奏电子乐”更依赖音乐特征)动态调整对不同模态token的关注度。消融实验表明,加入该模块使T2MR任务的平均Precision@K提升了10.8%。
- 将LLM作为生成式检索器: 将LLM的词表扩展为包含结构化音乐token,并通过指令微调使其能够直接生成这些token来“说出”推荐曲目。这统一了理解(解析查询)和生成(产生推荐标识符)的过程,避免了基于自由文本生成曲名带来的歧义和延迟问题。
- 统一的多模态表示与检索框架: 提出了一个端到端的流程,从处理异构的多模态原始数据,到训练统一的tokenizer,再到微调LLM进行检索,形成了一个完整的系统。实验证明该多模态框架在两项检索任务上均优于所有单模态变体。
🔬 细节详述
- 训练数据:
Dc: 用于训练RQ-VAE的音乐数据集,包含约160万首歌曲的多模态元数据,来源为公开数据库、自动标注和专家审核。Dqt: 用于指令微调LLM的合成查询-曲目对数据集,由另一个LLM根据歌曲和艺术家元数据生成。Dr: 用于训练模态重要性预测模型的数据集,同样由LLM分析Dqt中的查询,为每个模态分配0-10的相关性分数。
- 损失函数:
- RQ-VAE损失 (
L_RQ-VAE): 由重构损失、码本损失和承诺损失组成:∥x − ˆx∥^2_2 + Σ_l( ∥sg[rl−1] − ekl∥^2_2 + β∥rl−1 − sg[ekl]∥^2_2 )。sg[·]是停止梯度算子,β是承诺损失权重。 - LLM微调损失:因果语言建模目标,预测下一个token。
- 模态预测模型损失:回归损失(论文中未具体说明损失函数名称)。
- RQ-VAE损失 (
- 训练策略:
- RQ-VAE: 使用AdamW优化器,学习率1e-4,batch size 512,训练150个epoch。
- LLM微调:使用AdamW优化器,初始学习率1e-4,采用余弦学习率调度(带10%线性warmup),训练10个epoch。使用分布式数据并行,在16块NVIDIA A100 GPU上训练。
- 模态预测模型:论文未说明训练轮数、优化器等细节。
- 关键超参数:
- RQ-VAE量化级数
L=3。 - 每个模态的RQ-VAE码本大小
K_mod,l未具体说明,但提到基线(K-means,VQ-VAE)使用1024个聚类,是RQ-VAE的4.6倍,可推算RQ-VAE每个码本约224个条目。 - 原始LLM(Qwen2.5-1.5B-Instruct)词表大小151,646,新增音乐token后词表大小
V_new=153,664。嵌入维度1,536。 - 模态预测模型为BERT-based,回归头输出9个维度的分数。
- RQ-VAE量化级数
- 训练硬件: 16块NVIDIA A100 GPU(用于LLM微调)。RQ-VAE训练硬件未说明。
- 推理细节:
- LLM生成采用自回归方式,生成顺序受预定义模态和层级顺序约束。
- 检索采用层次化匹配:依次匹配Level 1, 2, 3的token索引。
- 论文未提及具体的解码策略(如温度、beam size等)。
- 正则化或稳定训练技巧: RQ-VAE中使用了停止梯度算子
sg[·]来控制梯度流。LLM微调中使用了因果注意力掩码和学习率warmup。
📊 实验结果
主要任务与数据集:
- 内容检索(CBR): 使用两个数据集:1.5万条策划播放列表(CP)和3万条从听歌会话推导的共现对(CO)。指标为Hit@k。
- 文本到音乐检索(T2MR): 使用人工标注的查询-曲目对。指标为Precision@k。
关键结果对比:
表1:内容检索(CBR)任务的Hit@k性能
| 方法 | k=5 (CP/CO) | k=10 (CP/CO) | k=20 (CP/CO) | k=50 (CP/CO) |
|---|---|---|---|---|
| 多模态方法 | ||||
| 3MToken (本文) | .284 / .300 | .352 / .375 | .418 / .433 | .513 / .510 |
| K-means | .225 / .228 | .293 / .309 | .386 / .387 | .495 / .495 |
| VQ-VAE | .184 / .178 | .258 / .247 | .332 / .322 | .443 / .430 |
| 单模态方法 (Top-7) | ||||
| TC (曲目消费) | .099 / .165 | .151 / .239 | .216 / .322 | .307 / .426 |
| ST (语义标签) | .073 / .091 | .112 / .132 | .158 / .183 | .233 / .269 |
| SC (声音特征) | .055 / .078 | .100 / .123 | .154 / .179 | .230 / .260 |
| … | … | … | … | … |
| 相对提升 | vs. Multi. +27%/+32% | vs. Multi. +20%/+21% | vs. Multi. +8%/+12% | vs. Multi. +4%/+3% |
结论: 3MToken在所有k值和数据集上均显著优于基线(K-means, VQ-VAE),在k=5时提升最大(超过20%)。同时,其性能远超所有单模态模型,证明了多模态融合的有效性。
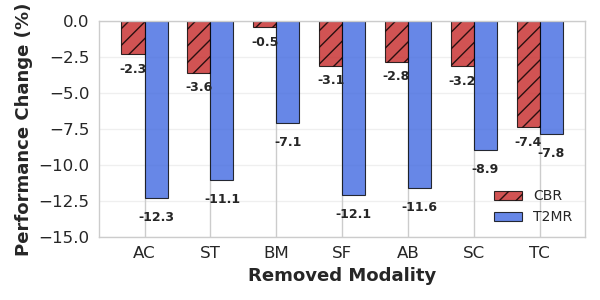
图2(a) 基线对比分析(T2MR):
- 3MTokenRec (本文): 在所有k值上表现最佳且稳定,平均Precision最高。
- ArtistTrackName (生成曲名基线): 在k=1时表现尚可,但随着k增大性能急剧下降,表明自由文本生成在扩展候选集时鲁棒性差。
- KmeansRec: 性能介于3MTokenRec和ArtistTrackName之间。
- 单模态变体: 性能普遍低于完整的多模态模型。
图2(b) 消融实验分析:
- 移除任一模态都会导致性能下降(CBR平均-3.26%, T2MR平均-10.13%)。
- 对于CBR,曲目消费模式(TC)是最关键的模态;对于T2MR,艺术家合作信息(AC)最关键。
- 结论: 多模态信息的整合对于处理复杂查询和提高检索准确性至关重要。
⚖️ 评分理由
- 学术质量:5.5/7:论文技术路线清晰、完整,实验结果在私有数据集上达到了声称的改进。主要扣分点在于:(1) 核心技术(RQ-VAE, LLM微调)属于现有方法的组合与应用,原创性有限;(2) 实验对比缺乏与外部公开领域的SOTA方法的直接较量;(3) 所有数据私有,无法进行第三方验证,结论的普适性存疑。
- 选题价值:1.5/2:解决的问题(多模态音乐的生成式表示与检索)是音乐AI和推荐系统的前沿方向,具有明确的工业应用前景和学术价值。
- 开源与复现加成:-0.5/1:这是最大的短板。论文未提供代码、模型权重、公开数据集或可运行的复现包,且关键训练配置(如每个模态RQ-VAE的具体码本大小、模态预测模型的详细训练设置)描述不足,使得复现工作极为困难,严重降低了论文的实用价值和可信度。