📄 HD-PPT: Hierarchical Decoding of Content- and Prompt-Preference Tokens for Instruction-Based TTS
#语音合成 #大语言模型 #自回归模型 #对比学习 #模型评估
🔥 8.0/10 | 前25% | #语音合成 | #大语言模型 | #自回归模型 #对比学习
学术质量 5.5/7 | 选题价值 1.8/2 | 复现加成 0.5 | 置信度 中
👥 作者与机构
- 第一作者:Sihang Nie(华南理工大学)
- 通讯作者:Xiaofen Xing(华南理工大学)
- 作者列表:Sihang Nie(华南理工大学)、Xiaofen Xing(华南理工大学)、Jingyuan Xing(华南理工大学)、Baiji Liu(华南理工大学,广州趣玩网络科技有限公司)、Xiangmin Xu(佛山大学,华南理工大学)
💡 毒舌点评
亮点: 论文将“精细控制”这个模糊的目标,拆解为可操作的、由两个专用token监督的分层生成步骤,这种“结构化解耦”的思路非常清晰且有效,实验数据也确实支撑了其优越性。 短板: 训练过程描述不够细致,例如文本指令的预处理、训练时的正则化细节(如何概率性地掩码隐藏状态和提示token)不够明确,且代码未开源,使得复现其“精妙”的工程实现颇具挑战。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开权重。
- 数据集:实验使用了公开数据集TextrolSpeech和EmoVoice-DB,但论文未提供获取方式的额外信息。
- Demo:提供了音频样本的在线演示(https://xxh333.github.io/)。
- 复现材料:提供了一些关键训练细节(如GPU型号、学习率、epoch数、模型层数等),但缺乏数据预处理、代码框架、超参数搜索过程等完整复现所需的关键信息。
- 论文中引用的开源项目:CosyVoice/2(语音tokenizer和声码器)、Whisper-Small(ASR)、RoBERTa-base(文本嵌入)、Qwen2.5-0.5B(LLM主干)。
- 总结:论文中未提及开源计划,复现主要依赖公开的第三方模型和论文中提供的部分配置信息。
📌 核心摘要
- 问题: 现有基于大语言模型的指令TTS(Instruct-TTS)方法,试图将单层的文本指令直接映射到多层的语音token上,导致精细控制能力不足,存在“层级不匹配”问题。
- 方法核心: 提出HD-PPT框架,包含两个核心创新:a) 设计一个新的语音编解码器(Speech Token Codec),通过ASR和CLAP两个监督目标,将语音token解耦为“内容偏好token”(语义)和“提示偏好token”(风格);b) 设计分层解码策略,引导LLM按“内容基础 -> 风格渲染 -> 完整声学表征”的顺序生成token。
- 新意: 相比于直接建模单一语音token序列的方法,本文首次将语音token在生成过程中显式地结构化解耦,并分别用语义和风格目标进行监督,实现了从“隐式映射”到“显式分层生成”的范式转变。
- 主要结果: 在TextrolSpeech和EmoVoice-DB两个数据集上,HD-PPT在主观自然度(MOS-N)、风格一致性(MOS-S)和情感相似度(EMO-SIM)指标上均取得了最佳成绩(见表1)。消融实验证明,移除任一偏好token或改变解码策略都会导致性能下降。
- 实际意义: 为实现高保真、高可控的语音合成提供了有效框架,提升了LLM在语音生成任务中的指令遵循能力,对智能语音助手、有声内容创作等应用有推动作用。
- 主要局限: 多组件架构增加了模型复杂度和部署难度;训练细节部分缺失,不利于完全复现;论文中承认对低资源语言的适应性是一个挑战。
表1:在测试集上的主观与客观对比结果
| 模型 | MOS-N ↑ | MOS-S ↑ | DNSMOS ↑ | EMO-SIM ↑ | WER ↓ |
|---|---|---|---|---|---|
| PromptStyle | 2.674 ± 0.145 | 2.420 ± 0.147 | 3.68 | 0.529 | 17.92% |
| PromptTTS | 2.920 ± 0.137 | 2.601 ± 0.148 | 3.65 | 0.588 | 4.38% |
| CosyVoice | 3.240 ± 0.138 | 3.028 ± 0.149 | 3.77 | 0.635 | 6.10% |
| CosyVoice2 | 3.920 ± 0.112 | 3.885 ± 0.116 | 3.83 | 0.714 | 5.71% |
| EmoVoice-PP | 3.694 ± 0.123 | 3.594 ± 0.128 | 3.87 | 0.613 | 8.56% |
| HD-PPT (Ours) | 4.108 ± 0.105 | 4.167 ± 0.103 | 3.84 | 0.753 | 5.18% |
🏗️ 模型架构
HD-PPT框架由三个主要组件构成,其目标是将语音合成从预测一个单一的声学序列,转变为一个结构化的分层生成过程。
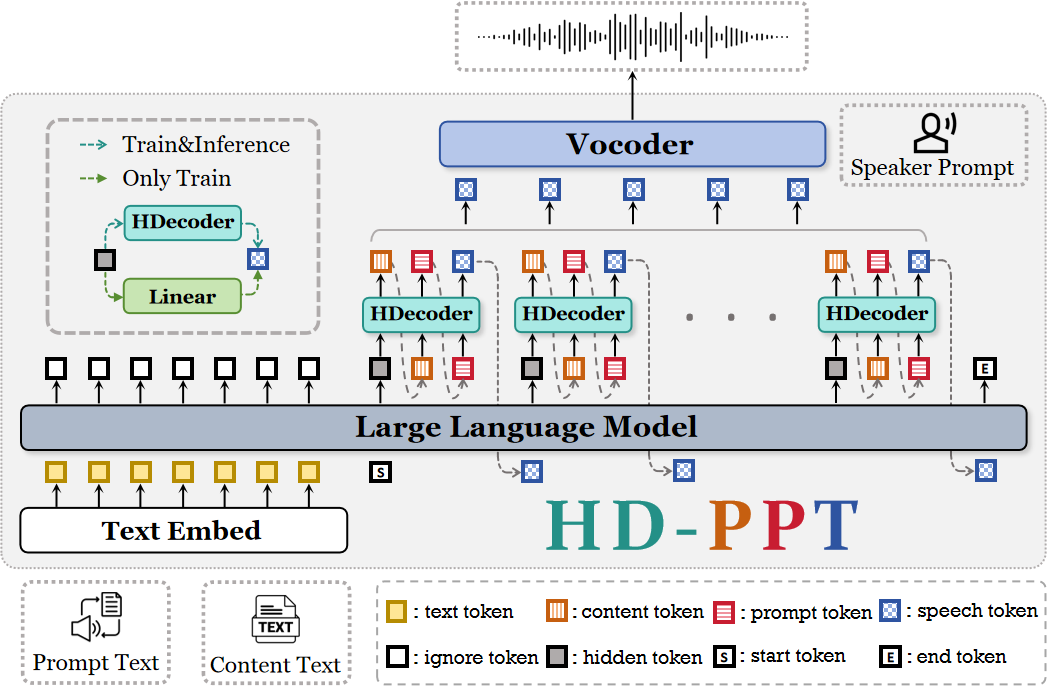
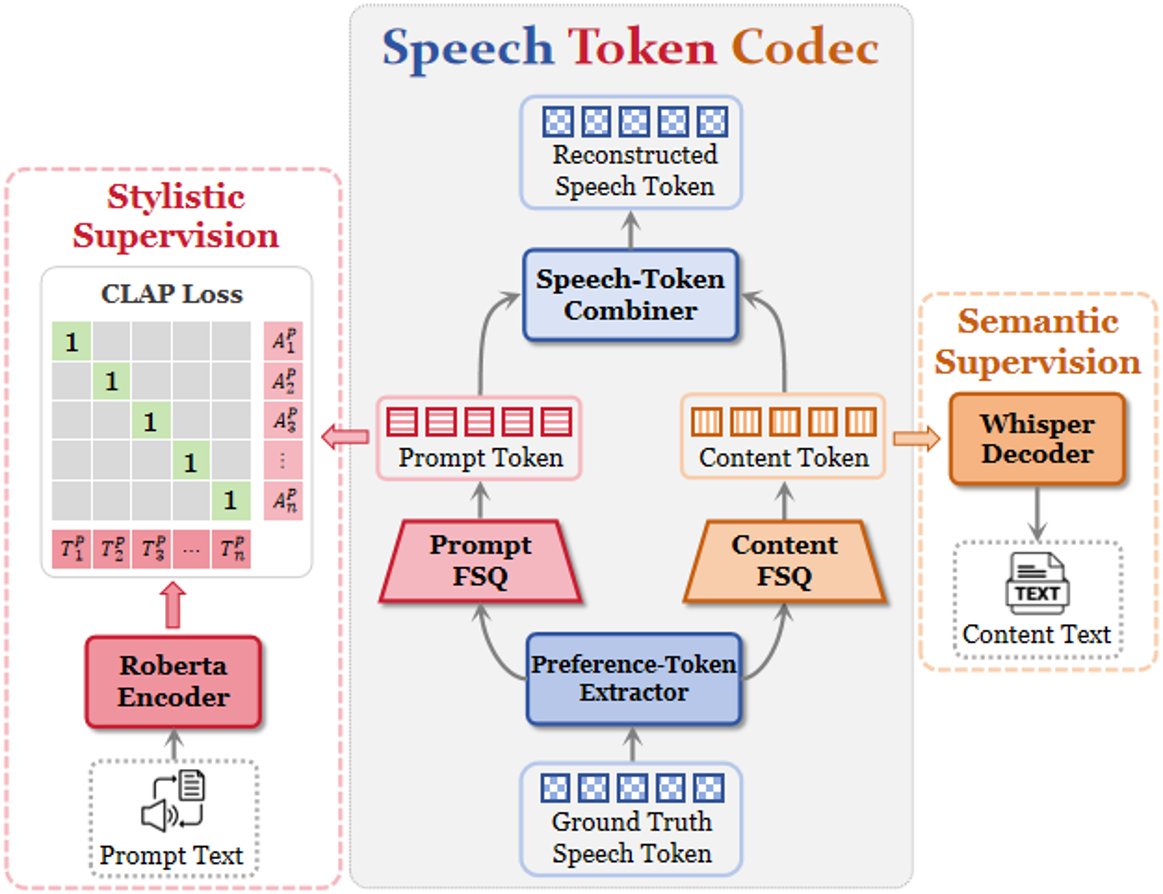
语音编解码器(Speech Token Codec):其作用是从预训练的语音tokenizer(如CosyVoice2)输出的原始语音token中,提取出两种具有不同偏好的离散token。
- 输入:原始语音token序列。
- 内部流程:首先,一个基于5层Conformer的“偏好token提取器”将输入token编码为连续表示Z。随后,Z被送入两个独立的有限标量量化(FSQ)模块,分别量化为“内容偏好token”(
Tc, 负责语义)和“提示偏好token”(Tp, 负责风格)。接着,一个基于因果Transformer的“语音token组合器”将这两种偏好token融合,以重构原始语音token。这种因果结构确保了时间对齐。 - 监督机制:内容偏好token由一个ASR任务(使用Whisper-Small解码器)监督,以注入语义信息;提示偏好token由一个基于CLAP的对比损失监督,使其与相应的文本描述在嵌入空间中对齐,从而捕获风格信息。
分层大语言模型(Hierarchical LLM):这是框架的核心生成器,负责根据输入文本指令生成所有token。
- 主干:采用Qwen2.5-0.5B作为基座LLM。
- 分层解码器:一个轻量级的2层自回归Transformer,固定输出长度为3。
- 生成流程(分三步):
- 内容基础:LLM根据输入文本
Tt生成隐藏状态Th,j,解码器基于Th,j预测内容偏好tokenTc,j。 - 风格渲染:解码器基于
Th,j和刚刚生成的Tc,j,预测提示偏好tokenTp,j。 - 最终token生成:解码器融合
Th,j,Tc,j和Tp,j的信息,预测最终的语音tokenTs,j。 - 生成的
Ts,j被反馈给LLM,用于生成下一个时间步的隐藏状态Th,j+1。
- 内容基础:LLM根据输入文本
- 正则化:训练时对隐藏状态和提示token进行概率性掩码;添加一个辅助线性层将LLM隐藏状态直接投影到语音token空间,以保持声学信息接地。
声码器(Vocoder):使用CosyVoice2官方预训练的声码器(结合了流匹配模型和HiFi-GAN),将LLM生成的最终语音token序列和说话人嵌入合成为最终波形。
💡 核心创新点
- 内容与提示偏好token解耦的语音编解码器:这是本文最核心的贡献之一。之前的方法通常将语音建模为单一的、不加区分的token序列。本文通过引入ASR和CLAP双重监督,强制编码器将语义信息(内容)和风格信息(提示)分离到不同的离散token中,为下游的分层生成提供了精细化、结构化的中间表示目标。
- 分层解码策略:与以往LLM并行或直接预测最终语音token的方式不同,本文设计了“内容->风格->声学”的顺序生成策略。这种设计显式地建模了信息依赖关系(风格需要基于语义),与语音信号的固有层级结构(语言学、副语言学、外语言学)对齐,显著提升了对复杂指令的遵循精度。
- 联合监督的训练框架:将语音编解码器的训练(重建+ASR+CLAP)与LLM的分层解码训练有机结合,使得整个系统从表示学习到序列生成都围绕着“解耦”和“分层”的核心思想进行优化,形成了一个完整的闭环。
🔬 细节详述
- 训练数据:使用了两个公开数据集:TextrolSpeech(用于细粒度风格控制)和EmoVoice-DB(用于情感控制),所有音频重采样为24kHz。数据集具体规模未说明。
- 损失函数:
- 语音编解码器总损失:
Ltotal = Lrec + λasrLasr + λclapLclap。其中Lrec是重建交叉熵损失,Lasr是ASR损失(权重λasr=2.0),Lclap是CLAP对比损失(权重λclap=0.8)。 - LLM训练损失:论文中未明确说明,推测为自回归交叉熵损失。
- 语音编解码器总损失:
- 训练策略:
- 编解码器:在4块NVIDIA 4090 GPU上训练50个epoch,使用AdamW优化器,学习率为1e-4。
- LLM:使用Qwen2.5-0.5B,在同样硬件上训练16个epoch,使用AdamW优化器,学习率为1e-5。轻量级解码器随机初始化。
- 关键超参数:
- 编解码器:5层Conformer提取器,4层因果Transformer组合器。FSQ码本大小:提示偏好token为64,内容偏好token为1296,工作频率均为25Hz。
- LLM解码器:2层Transformer,固定长度3。
- 训练硬件:4块NVIDIA 4090 GPU(训练时长未说明)。
- 推理细节:自回归解码。在NVIDIA 4090上,实时因子(RTF)从单步解码的0.711增加到本文方法的0.952。
- 正则化技巧:在训练LLM分层解码器时,采用概率性掩码隐藏状态和提示token;将token logits与token embedding拼接作为解码器输入;添加辅助线性层直接预测语音token。
📊 实验结果
论文在两个数据集(TextrolSpeech和EmoVoice-DB)的组合测试集上,与五种基线方法进行了全面比较。
表1已在“核心摘要”中列出。 关键结果:
- HD-PPT在主观指标MOS-N(4.108)和MOS-S(4.167)上均为最高,证明了其卓越的自然度和风格一致性。
- 在客观指标情感相似度EMO-SIM(0.753)上也达到最佳,验证了其精细的可控性。
- 在感知质量DNSMOS(3.84)上与最强基线CosyVoice2(3.83)持平,在词错误率WER(5.18%)上仅次于CosyVoice2(5.71%),表明生成语音清晰可懂。
消融实验验证了各组件的有效性:
表2:偏好token消融实验
| 模型 | DNSMOS ↑ | EMO-SIM ↑ | WER ↓ |
|---|---|---|---|
| w/o Content-Pref. | 3.76 | 0.742 | 8.04% |
| w/o Prompt-Pref. | 3.76 | 0.728 | 5.49% |
| w/o Dual-Pref. | 3.73 | 0.716 | 10.10% |
| w/o Instruct Text | 3.78 | 0.605 | 5.44% |
| Proposed | 3.84 | 0.753 | 5.18% |
- 移除内容偏好token(w/o Content-Pref.)导致WER从5.18%显著上升至8.04%,证明了其对语义完整性的关键作用。
- 移除提示偏好token(w/o Prompt-Pref.)导致EMO-SIM从0.753下降至0.728,表明其对风格细粒度控制的必要性。
- 移除所有偏好token(w/o Dual-Pref.)导致所有指标下降,特别是WER飙升至10.10%,证实了结构化中间表示的重要性。
表3:分层解码策略消融实验
| 模型 | DNSMOS ↑ | EMO-SIM ↑ | WER ↓ |
|---|---|---|---|
| Parallel | 3.76 | 0.736 | 5.99% |
| Single-step | 3.80 | 0.713 | 5.93% |
| Hierarchical | 3.84 | 0.753 | 5.18% |
- 本文的分层(Hierarchical)解码策略在所有指标上均优于并行(Parallel) 和 单步(Single-step) 解码策略,特别是EMO-SIM(0.753 vs 0.736/0.713)和WER(5.18% vs 5.99%/5.93%),充分证明了顺序生成策略在精细控制上的优势。
⚖️ 评分理由
- 学术质量:5.5/7
- 创新性(2.5/3):提出的“内容-偏好token解耦+分层生成”范式是对现有LLM-TTS方法的实质性改进,思路新颖且具有启发性。创新点聚焦且自成体系。
- 技术正确性(1.5/2):方法设计合理,实验验证了其有效性。训练策略、损失函数设计有据可依。但部分训练细节未完全公开。
- 实验充分性(1.5/2):包含主观/客观评估、与多个类别基线的对比、详细的消融实验(针对token和解码策略),证据链较为完整。实验在两个数据集上进行,增加了说服力。
- 选题价值:1.8/2
- 前沿性(0.9/1):直接针对当前TTS领域最受关注的“可控生成”问题,属于热点方向。
- 潜在影响(0.9/1):提出的分层框架为解决LLM在语音生成中的“模态对齐”问题提供了新思路,可能影响后续可控语音生成模型的设计。应用于语音助手、内容创作等场景的价值明确。
- 开源与复现加成:0.5/1
- 论文提供了演示音频的链接,有助于直观评估。但未提供代码、模型、数据集或完整的复现指南,限制了社区的直接应用和验证。