📄 HCGAN: Harmonic-Coupled Generative Adversarial Network for Speech Super-Resolution in Low-Bandwidth Scenarios
#语音增强 #生成模型 #端到端 #低资源
🔥 8.0/10 | 前50% | #语音增强 | #生成模型 | #端到端 #低资源
学术质量 5.5/7 | 选题价值 2.0/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Xin Wang(河海大学信息科学与工程学院)
- 通讯作者:Yibin Tang(河海大学信息科学与工程学院)
- 作者列表:Xin Wang(河海大学信息科学与工程学院)、Yuan Gao(河海大学信息科学与工程学院)、Xiaotong Wang(河海大学信息科学与工程学院)、Yibin Tang(河海大学信息科学与工程学院)、Aimin Jiang(河海大学信息科学与工程学院)、Ying Chen(常州大学微电子与控制工程学院)
💡 毒舌点评
亮点:该工作的双分支设计思路清晰,将语音的谱特征与谐波结构显式解耦并分别建模,对于解决4kHz这类谐波严重丢失的极窄带问题确有针对性,消融实验也证明了谐波分支的贡献。短板:作为2026年发表在ICASSP的工作,其网络架构(U-Net + GAN + Mamba)的集成缺乏更深入的原理性创新,更像是一个工程上的有效组合;且Mamba模块在消融实验中对核心指标PESQ的提升并不显著,其必要性有待更强论证。
🔗 开源详情
- 代码:论文提供了代码仓库链接:https://github.com/BiolabHHU/HCGAN。
- 模型权重:论文中未提及是否公开预训练模型权重。
- 数据集:使用VCTK公开数据集,论文中说明了数据集来源和处理方式,但未说明是否提供处理后的数据。
- Demo:论文中未提及在线演示。
- 复现材料:提供了模型架构图、关键超参数(如损失权重、学习率、批次大小)、评估指标。代码仓库可能包含更多细节,但论文正文未说明。
- 引用的开源项目:在模型中引用了Mamba([18])和MelGAN([19])的判别器结构。
- 总结:论文中提及了代码仓库链接,但未说明开源计划的其他细节(如权重、详细配置文件)。
📌 核心摘要
- 问题:在低带宽场景(如采样率4kHz)下进行语音超分辨率时,输入信号的谐波信息严重丢失,现有方法难以恢复出自然清晰的高质量语音。
- 方法核心:提出谐波耦合生成对抗网络(HCGAN)。生成器采用双分支架构:谱分支通过U-Net和Mamba模块处理频谱图;谐波分支通过时谐模块从低频谐波矩阵估计高频谐波矩阵。两分支输出融合后生成最终频谱。
- 创新点:1)显式引入并建模语音的谐波结构,通过矩阵形式实现谐波从低频到高频的迁移;2)设计双分支架构,分别学习谱平滑性和谐波连续性,并进行特征融合;3)在U-Net瓶颈处集成轻量Mamba模块以降低计算复杂度。
- 主要结果:在8kHz->16kHz任务上,HCGAN的PESQ达到3.64,超越所有对比方法(最高为TUNet的3.50)。在更困难的4kHz->16kHz任务上,其PESQ为2.50,也优于AFiLM、NVSR等传统方法。消融实验证实了多尺度特征损失、Mamba模块和谐波提取(HE)模块的有效性。
- 表1:16 kHz高分辨率语音从8 kHz语音恢复对比
方法 LSD PESQ SNR (dB) Params (M) AFiLM [20] 0.74 3.02 20.0 134.7 NVSR [21] 0.78 3.09 17.4 99.0 TFiLM [12] 0.78 2.51 19.8 68.2 AERO [17] 0.77 3.01 22.5 36.3 Tramba [16] 0.82 3.23 23.2 5.2 TUNet [13] 1.36 3.50 17.4 2.9 HCGAN 0.78 3.64 19.8 4.7 - 表2:16 kHz高分辨率语音从4 kHz语音恢复对比
方法 LSD PESQ SNR (dB) Params (M) AFiLM [20] 1.00 1.88 15.4 134.7 NVSR [21] 0.95 2.03 11.7 99.0 TFiLM [12] 1.17 2.08 15.0 68.2 TFNet [11] 1.27 1.73 17.5 55.8 HCGAN 0.96 2.50 14.3 4.7
- 表1:16 kHz高分辨率语音从8 kHz语音恢复对比
- 实际意义:HCGAN以仅4.7M的参数量,在关键的感知质量指标PESQ上表现优异,尤其适用于卫星通信、物联网等对模型大小敏感且带宽极度受限的语音通信增强场景。
- 局限性:当输入语音基频较高(>300Hz)时,低频谐波矩阵包含的信息不足,导致谐波分支的性能提升有限。此外,实验部分未提供语音增强后的MOS评分或主观听感测试,客观指标与主观感受的关联性有待进一步验证。
🏗️ 模型架构
HCGAN是一个在GAN框架下的双分支生成器模型,其整体架构如图1所示。其核心思想是分别建模语音的频谱特征和谐波结构,然后进行融合。
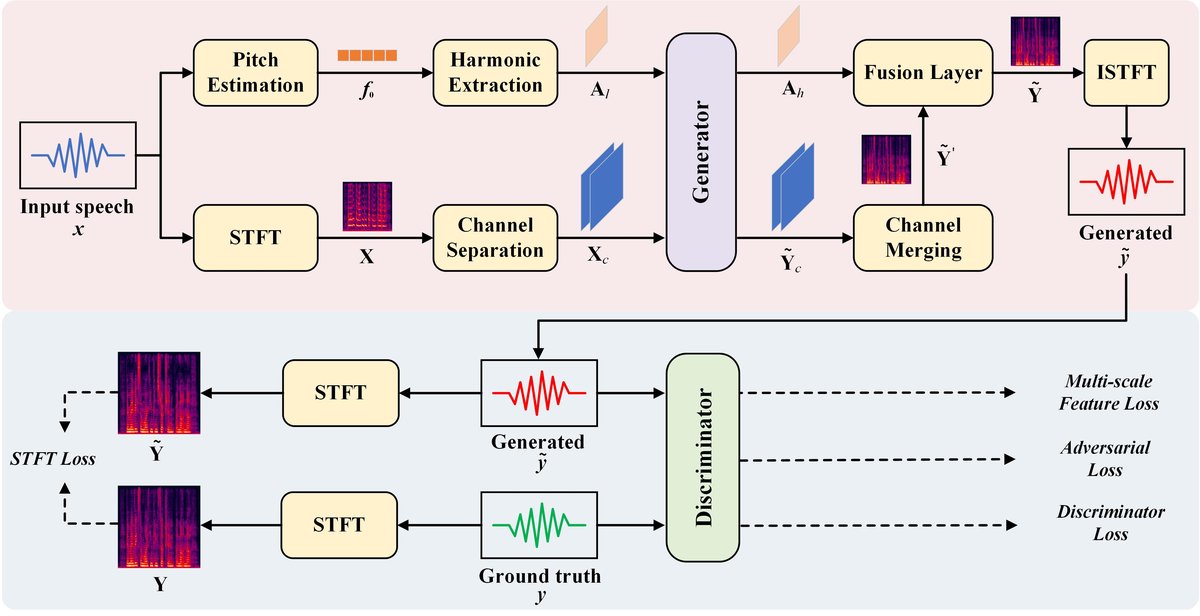 图1:HCGAN的整体架构。生成器包含谱分支和谐波分支,两者输出融合后生成高分辨率频谱,再经iSTFT得到波形。判别器评估生成语音的真实性。
图1:HCGAN的整体架构。生成器包含谱分支和谐波分支,两者输出融合后生成高分辨率频谱,再经iSTFT得到波形。判别器评估生成语音的真实性。
- 输入:窄带语音
x(4kHz或8kHz采样)。 - 预处理:对
x进行STFT得到频谱Xc,并通过基频分析得到低频谐波矩阵Al(前20个谐波幅度)。 - 生成器双分支:
- 谱分支:以
Xc为输入,采用U-Net编码器-解码器结构提取多尺度谱特征。在U-Net的瓶颈层,引入Mamba模块替代传统的自注意力,以更低的计算复杂度捕获序列依赖关系,增强特征选择能力。该分支输出候选高分辨率频谱˜Yc。 - 谐波分支:以
Al为输入,目标是预测高频谐波矩阵Ah(对应于目标16kHz语音中超过8kHz奈奎斯特频率的谐波)。该分支由一系列时谐(TH)残差块构成,每个块包含用于建模时序和频谐关系的结构,并辅以SE(挤压-激励)块进行通道注意力。分支末端包含谐波提取(HE)块,它从谱分支的输出˜Yc中提取谐波信息,用于监督和增强谐波分支的学习。
- 谱分支:以
- 特征融合:将谱分支输出的
˜Yc与谐波分支预测的Ah在融合层进行融合,得到最终的高分辨率频谱˜Y’。 - 波形合成:对
˜Y’进行逆STFT(iSTFT)得到生成的16kHz语音波形˜y。 - 判别器:采用多尺度判别器(源自MelGAN),在不同时间分辨率下评估生成语音
˜y和真实语音y的真实性,引导生成器提升输出的自然度。
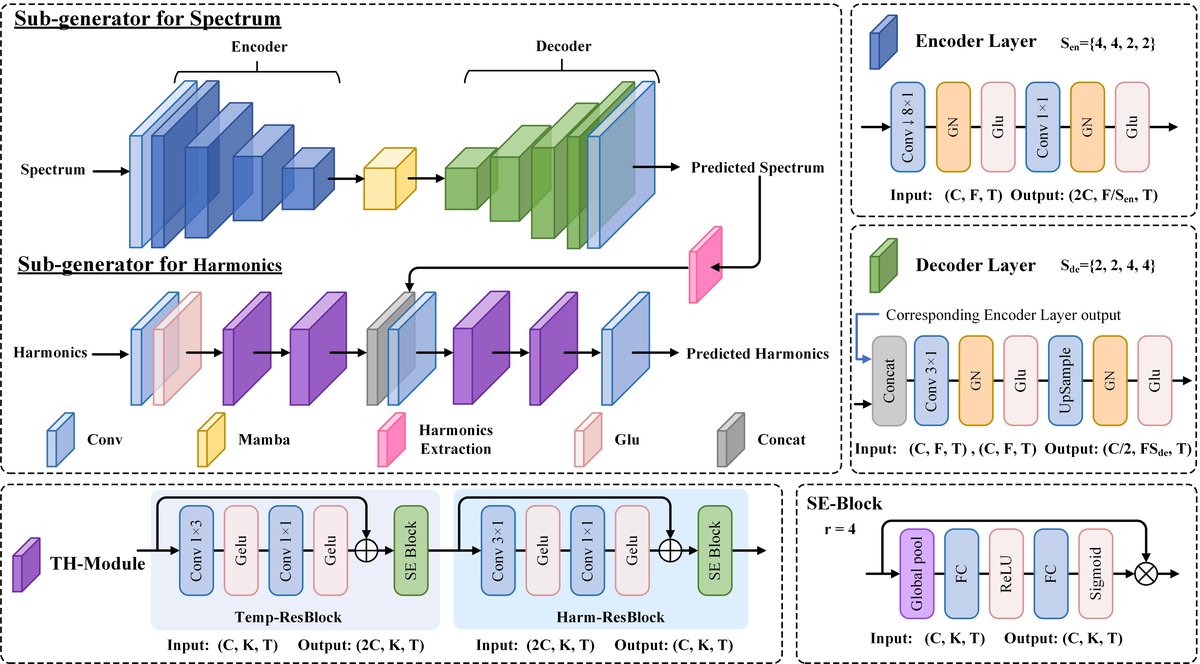 图2:HCGAN生成器两个分支的详细结构。展示了谱分支(左)的U-Net-Mamba结构和谐波分支(右)的TH模块堆叠结构,以及输入输出维度。
图2:HCGAN生成器两个分支的详细结构。展示了谱分支(左)的U-Net-Mamba结构和谐波分支(右)的TH模块堆叠结构,以及输入输出维度。
💡 核心创新点
- 显式谐波矩阵建模与迁移:这是本文最核心的创新。不同于以往方法将语音视为一个整体频谱进行处理,HCGAN将语音的谐波结构解耦出来,用矩阵
Al和Ah显式表示。通过神经网络学习从Al到Ah的映射,直接实现了谐波信息从低频到高频的“接力”,这理论上更能保证恢复语音的谐波连续性,是提升感知自然度的关键。 - 谱-谐波双分支融合架构:谱分支负责重建平滑且能量正确的整体频谱,谐波分支负责精准恢复结构性的谐波成分。两者互补,最终通过融合层结合,使得生成的语音既具有准确的整体能量分布,又具有清晰的谐波细节,从而在PESQ等感知指标上取得优势。
- 轻量化Mamba模块集成:在保持模型总参数量仅为4.7M(与TUNet的2.9M同属轻量级,远低于AFiLM等模型的>30M)的前提下,通过在U-Net瓶颈引入线性复杂度的Mamba模块,替代了计算昂贵的自注意力,实现了效率与性能的平衡。
🔬 细节详述
- 训练数据:使用VCTK语料库,包含109位英语母语者录音。原始48kHz音频被下采样至4kHz、8kHz和16kHz,模拟不同带宽场景。
- 预处理:对于16kHz语音,帧长512样本,帧移64。对4kHz和8kHz语音,帧长分别为128和256样本,但统一进行512点STFT分析。
- 损失函数:总损失
L_total为四项加权和:L_STFT:对数幅度谱损失,公式为|log(Y) - log(˜Y)|。L_D:判别器损失,标准GAN损失。L_adv:对抗损失,优化生成器欺骗判别器。L_F:多尺度特征匹配损失,最小化生成语音与真实语音在判别器各层特征的差异。- 权重:
λ1=λ2=λ3=1,λ4=0.5。
- 训练策略:优化器为Adam,学习率0.0005。训练30个epochs,批次大小32。
- 关键超参数:生成器参数总量4.7M。谐波矩阵中谐波数量K=20。
- 训练硬件:论文中未提及。
- 推理细节:论文中未提及解码策略、温度等。根据描述,模型输入为语音片段,直接输出16kHz波形。
- 正则化/稳定技巧:使用了多尺度特征损失
L_F来稳定训练并提升语义一致性。
📊 实验结果
实验在VCTK测试集上进行,评估4kHz->16kHz和8kHz->16kHz两种场景。
- 主要对比实验结果:
- 表1 (8kHz->16kHz):HCGAN在PESQ上取得了最高分3.64,显著优于轻量级的Tramba (3.23) 和TUNet (3.50),也超过了参数量大得多的AFiLM (3.02)。其LSD和SNR与其它方法相当。
- 表2 (4kHz->16kHz):HCGAN在更具挑战性的4kHz输入上,PESQ达到2.50,远超TUNet和AERO(表格未列出,但文中提到其无法直接应用此场景),也优于AFiLM (1.88) 和NVSR (2.03)。SNR (14.3 dB) 略低于TFNet (17.5 dB),但LSD (0.96) 和 PESQ 更优。
- 频谱分析与可视化:
- 图3 (4kHz->16kHz示例):展示了输入4kHz语音、HCGAN恢复的16kHz语音以及真实16kHz语音的频谱图。从频谱图中可以直观看出,HCGAN比“无谐波分支”的变体更好地恢复了高频谐波成分,使得频谱结构更接近真实语音。
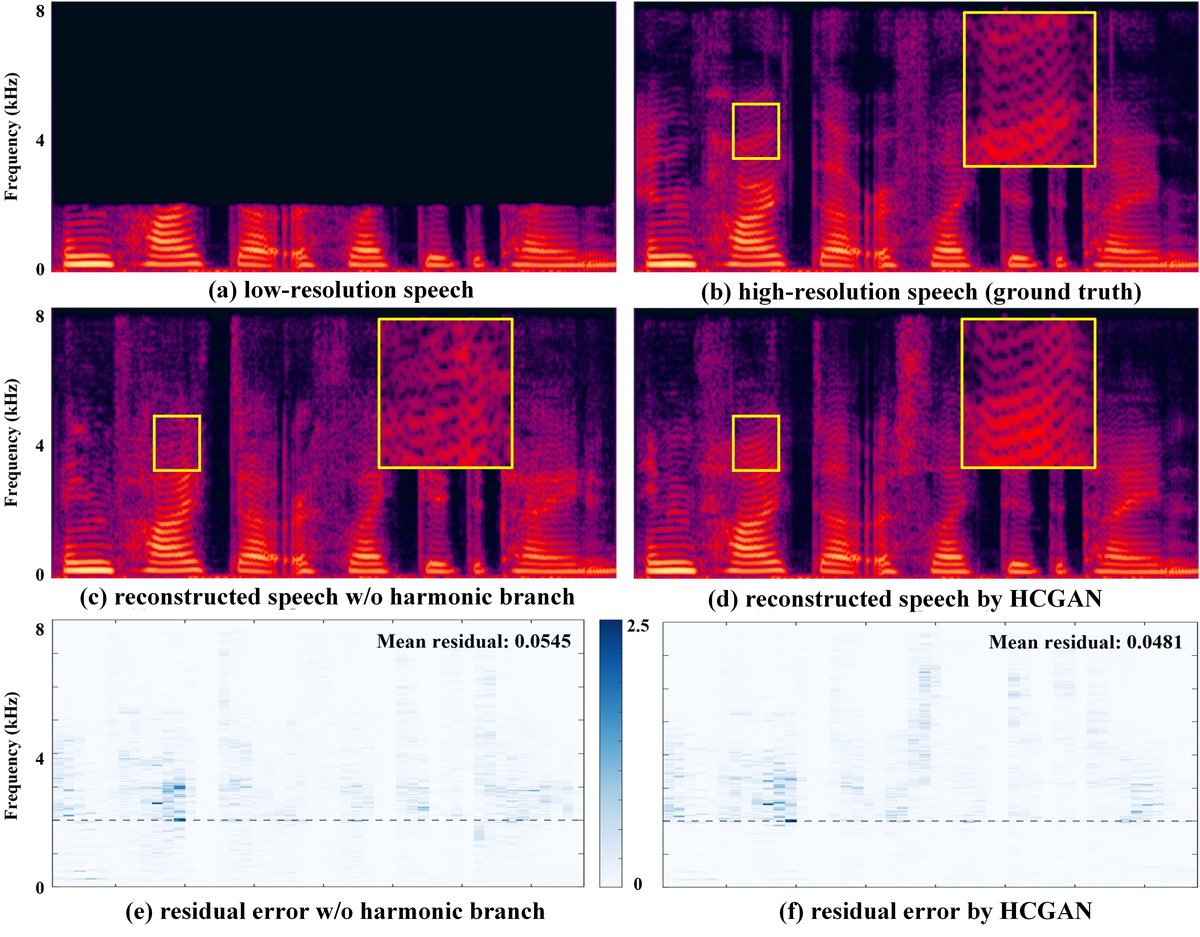 图3:语音频谱示例。对比输入、HCGAN输出(w/o和w/谐波分支)以及真实值的频谱。
图3:语音频谱示例。对比输入、HCGAN输出(w/o和w/谐波分支)以及真实值的频谱。 - 图4 (谐波误差统计分析):统计了不同基频下,HCGAN与无谐波分支变体在恢复高频谐波时的误差。结果表明,在基频低于300Hz时,HCGAN的误差明显更小,验证了其在主流基频范围内的有效性。但在基频>300Hz时,优势不明显,这是因为低频谐波矩阵包含的信息有限。
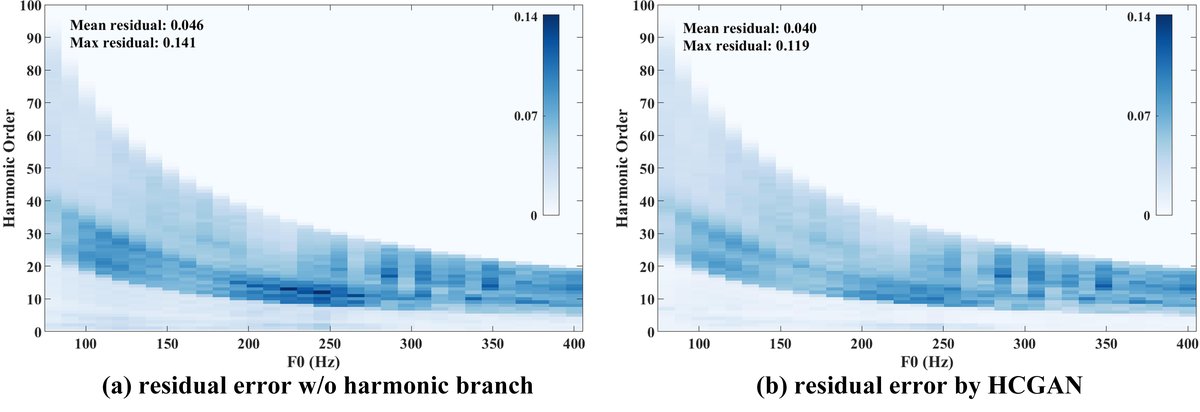 图4:谐波误差统计。横轴为基频,纵轴为误差,HCGAN(红线)在大部分基频区间误差低于变体(蓝线)。
图4:谐波误差统计。横轴为基频,纵轴为误差,HCGAN(红线)在大部分基频区间误差低于变体(蓝线)。
- 消融实验(表3):
- 表3:HCGAN及其变体的消融实验结果
变体 4 kHz →16 kHz 8 kHz →16 kHz LSD PESQ SNR (dB) LSD PESQ SNR (dB) w/o LF 1.19 1.68 12.3 0.89 2.90 18.1 w/o Ladv 1.12 1.70 12.2 0.88 3.12 18.3 w/o Mamba 0.96 2.46 14.3 0.79 3.64 19.3 w/o HE 0.98 2.48 14.3 0.78 3.62 19.3 HCGAN 0.96 2.50 14.3 0.78 3.64 19.8 - 关键发现:移除多尺度特征损失
L_F(w/o LF)导致PESQ急剧下降,说明该损失对语音质量至关重要。移除对抗损失L_adv影响相对较小。移除Mamba模块和HE模块会导致PESQ轻微下降,说明这些模块有正向贡献,但影响幅度小于L_F。
⚖️ 评分理由
- 学术质量:5.5/7:论文工作完整,针对明确问题提出了结构化的解决方案,双分支和谐波建模的设计具有一定创新性。实验部分对比了当前SOTA方法,进行了充分的消融研究,数据可信。主要扣分点在于创新属于“有效组合”而非“原理突破”,且Mamba模块的实际贡献在消融实验中并非最显著。
- 选题价值:2.0/2:低带宽语音超分辨率是通信和物联网领域的实际痛点,论文聚焦于更具挑战性的4kHz输入,选题精准,应用前景明确。
- 开源与复现加成:0.5/1:提供了代码仓库链接和关键训练参数,极大地促进了复现。但缺乏预训练模型权重、详细的硬件配置和训练时间信息,使得完全复现存在一定门槛。