📄 HAVT-IVD: Heterogeneity-Aware Cross-Modal Network for Audio-Visual Surveillance: Idling Vehicles Detection with Multichannel Audio and Multiscale Visual Cues
#音频事件检测 #多模态模型 #端到端 #麦克风阵列
🔥 8.0/10 | 前25% | #音频事件检测 | #多模态模型 | #端到端 #麦克风阵列
学术质量 6.5/7 | 选题价值 1.0/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Xiwen Li(Scientific Computing and Imaging Institute, University of Utah)
- 通讯作者:Tolga Tasdizen(Scientific Computing and Imaging Institute, University of Utah; Department of Electrical and Computer Engineering, University of Utah)
- 作者列表:Xiwen Li(Scientific Computing and Imaging Institute, University of Utah)、Xiaoya Tang(Scientific Computing and Imaging Institute, University of Utah)、Tolga Tasdizen(Scientific Computing and Imaging Institute, University of Utah; Department of Electrical and Computer Engineering, University of Utah)
💡 毒舌点评
这篇论文的亮点在于其问题导向的系统设计,针对异质性模态融合、多尺度检测和训练不稳定这三个具体痛点,分别用Transformer、特征金字塔和解耦头给出了清晰的解决方案,实验增益显著。然而,其短板在于创新点的“组合”色彩较重,每个组件(如Transformer用于融合、FPN、解耦头)在其他视觉任务中已有广泛应用,论文的核心贡献更多是巧妙地将这些成熟模块应用于特定任务,而非提出根本性的新机制。
🔗 开源详情
- 代码:论文中明确提供了代码仓库链接:
https://github.com/lix4/AVIVDNet。 - 模型权重:未提及是否提供预训练模型权重。
- 数据集:未提及AVIVD或MAVD数据集是否公开或如何获取。
- Demo:未提及在线演示。
- 复现材料:提供了部分训练细节:输入尺寸(224x224,16帧;音频128x469)、优化器(未说明)、学习率(1e-3)、Batch size(16)、训练轮数(100 epochs with early stopping patience 50)、损失权重(λconf=1, λcls=1, λreg=5)、训练硬件(NVIDIA A6000)。但未提供完整的配置文件、检查点或更详细的附录。
- 引用的开源项目:论文未明确列出依赖的外部开源工具或模型,但编码器部分使用了MobileNetV3等标准架构。
📌 核心摘要
- 要解决什么问题:论文研究音频-视觉监控下的怠速车辆检测(IVD)任务,即结合视频和多通道音频,定位并分类车辆状态为移动、怠速或熄火。主要挑战包括:视觉与音频模态间的异质性(空间分布不匹配)、车辆尺度变化大、以及联合检测头的梯度冲突。
- 方法核心是什么:提出HAVT-IVD网络。其核心是:a) 使用自注意力机制对视觉和音频的patch进行全局对齐,以灵活处理模态异质性;b) 利用视觉特征金字塔融合多尺度视觉特征;c) 采用解耦的检测头分别处理分类和回归任务,缓解梯度冲突。
- 与已有方法相比新在哪里:相比之前的E2E模型AVIVDNet(使用简单的CBAM注意力),HAVT-IVD不强制将音频特征对齐到视觉空间,而是保持原始patch表示,通过自注意力进行内容自适应路由。此外,它引入了特征金字塔和解耦头,这两点在原方法中未被采用。
- 主要实验结果如何:在AVIVD数据集上,HAVT-IVD达到88.63 mAP@0.5,相比AVIVDNet基线(79.21)提升9.42,相比三阶段的Real-Time IVD(80.97)提升7.66,尤其在“怠速”类别上AP提升显著(83.41 vs 68.93)。消融研究证实了多尺度融合、解耦头和6通道麦克风的有效性。在MAVD数据集上也取得了最佳性能(69.86 mAP@Avg)。
- 实际意义是什么:该研究为使用低成本、易部署的音频-视觉传感器进行车辆状态监控提供了高效的端到端解决方案,有助于减少车辆怠速排放和资源浪费,在城市管理和环保监控中有实际应用潜力。
- 主要局限性是什么:模型偶尔会产生误报,例如将环境声音(如割草机)误判为发动机噪声。未来工作计划将问题重新定义为纯分类任务以简化流程。
🏗️ 模型架构
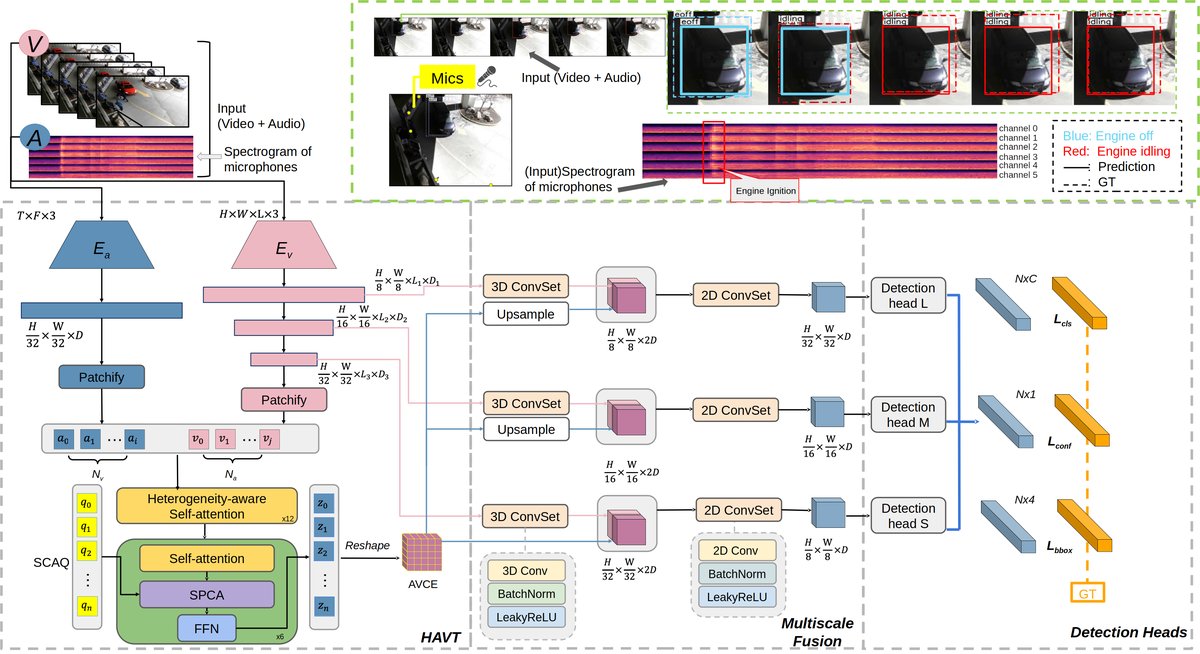
HAVT-IVD是一个端到端的音频-视觉融合网络,其整体架构如图1所示。流程如下:
- 输入:视频片段
V ∈ R^{D×C×H×W}(D=16帧,空间尺寸224x224)和6通道音频的频谱图A ∈ R^{M×T×F}(M=6,5秒片段,mel频谱图128x469)。 - 编码:
- 视觉编码器 (E_v):一个3D CNN(如MobileNetV3),输出三个尺度的特征图:大尺度(H/8 × W/8)、中尺度(H/16 × W/16)、小尺度(H/32 × W/32)。
- 音频编码器 (E_a):一个3D CNN,输出下采样的音频特征图(R^{D× T/32 × F/32}),然后被划分为
N_a个音频patch。每个音频patch编码了跨通道的能量信息,有助于定位引擎声音。
- 异质性感知对齐 (HAVT模块):这是核心创新。将视觉编码器最末层(小尺度)输出的
N_v个视觉patch和N_a个音频patch拼接,输入一个12层的自注意力编码器 (fsa)。自注意力允许所有patch(无论模态)相互交换信息,实现灵活的、内容自适应的全局对齐,从而缓解模态异质性。输出称为音频-视觉上下文编码 (AVCE)。 - 空间聚合:随后,通过空间拉取交叉注意力 (SPCA) 层,使用网格对齐的可学习查询槽(SCAQ,49个,对应7x7网格),从全局的AVCE记忆中选择和聚合信息,输出一个空间对齐的7x7×D的AVCE特征图(图1中紫色部分)。
- 多尺度融合与检测:
- 将7x7的AVCE特征图上采样,分别与视觉编码器的三个尺度(大、中、小)的特征图在通道维度拼接,再通过1x1卷积统一通道数。
- 对每个融合后的金字塔层级,连接一个解耦的检测头。每个头包含两个3x3卷积分支:一个用于预测C类(3类)的分类logits,另一个用于预测边界框参数和置信度。
- 输出:每个层级预测多个边界框及其类别和置信度,最终通过NMS得到检测结果。
💡 核心创新点
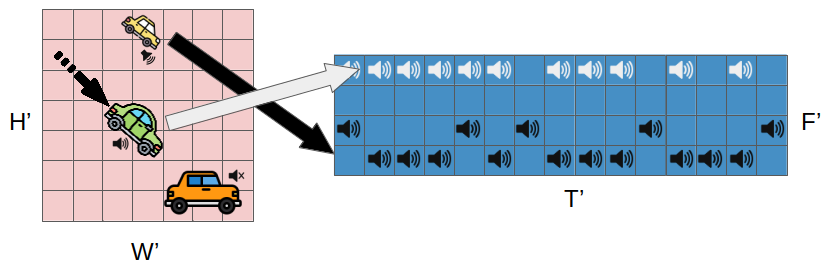
- 异质性感知的音频-视觉Transformer融合:针对音频与视觉模态在空间分布和语义上的固有差异(如图2所示),模型不强行将音频特征转换为视觉空间,而是直接对齐原始的视觉和音频patch。通过12层自注意力网络进行全局路由,使不同模态的patch能够根据内容相互查询和融合,从而更有效地处理跨模态异质性。
- 基于特征金字塔的多尺度融合:为应对监控场景中车辆尺度变化大的问题,模型将经过全局对齐的AVCE特征图与视觉编码器输出的三个不同空间分辨率(大、中、小)的特征图进行融合。这使得模型能够同时利用高分辨率的空间细节和高语义的低分辨率信息,提升了对远距离小目标和近距离大目标的检测能力。
- 解耦的检测头:为解决分类任务(预测车辆状态)和定位任务(预测边界框)在联合训练时的梯度冲突问题,采用了YOLO风格的解耦头。每个检测头将分类和回归任务分离到两个独立的卷积分支中,实验表明这显著提升了整体性能和怠速车辆的检测精度(AP(I)提升7.00)。
🔬 细节详述
- 训练数据:使用AVIVD数据集,包含76,490个训练视频-音频对,标注了每辆车的边界框和类别(M/I/Eoff)。测试集为8,431个对,独立划分。数据来自医院候客区,使用远程监控摄像头和6个均匀分布的无线麦克风采集。
- 损失函数:采用YOLOv5的多任务损失:
L_total = λ_conf L_conf + λ_cls L_cls + λ_reg * L_bbox。权重设置为λ_conf=1,λ_cls=1,λ_reg=5。L_conf和L_cls为二元交叉熵损失,L_bbox为CIoU损失。 - 训练策略:在NVIDIA A6000 GPU上训练,batch size为16,初始学习率1e-3,训练最多100个epoch,早停耐心为50。使用PyTorch框架。优化器未明确说明,推测为Adam或SGD。
- 关键超参数:输入帧数D=16,音频为5秒6通道片段。视觉编码器输出三个尺度,最终检测网格为28x28, 14x14, 7x7。自注意力编码器为12层。SCAQ查询数为49(7x7网格)。模型复杂度为4.43 GMACs,30.7M参数。
- 推理细节:未详细说明解码策略,但标准做法是使用NMS进行后处理,IoU阈值为0.5。
- 正则化技巧:未明确提及使用Dropout或权重衰减等,但早停是主要的防止过拟合手段。
📊 实验结果
论文在AVIVD和MAVD两个数据集上进行了评估,主要指标为mAP@0.5和各类别的AP。
表1:AVIVD数据集上的对比实验
| 方法 | E2E | 音频骨干 | mAP | AP(M) | AP(I) | AP(Eoff) |
|---|---|---|---|---|---|---|
| (A) AVIVD方法 | ||||||
| Real-Time IVD [5] | ✗ | R50 (frozen) | 80.97 | 92.45 | 68.93 | 81.55 |
| Feature Concat. | ✓ | MNv3 | 77.45 | 93.97 | 60.35 | 78.02 |
| AVIVDNet | ✓ | MNv3 | 78.89 | 90.77 | 66.81 | 79.10 |
| HAVT-only | ✓ | MNv3 | 80.95 | 85.25 | 73.19 | 84.41 |
| HAVT-IVD (Ours) | ✓ | MNv3 | 88.63 | 94.35 | 83.41 | 88.12 |
| (B) AVSBench模型 | ||||||
| TPAVI [7] | ✓ | MNv3 | 23.27 | 38.66 | 4.21 | 26.94 |
| AVSegFormer [8] | ✓ | MNv3 | 14.65 | 31.12 | 0.07 | 12.77 |
| HAVT-IVD (Ours) | ✓ | MNv3 | 88.63 | 93.45 | 83.41 | 88.12 |
关键结论:HAVT-IVD在AVIVD上达到了88.63 mAP,显著超越所有基线。特别是将怠速车辆的AP从Real-Time IVD的68.93提升至83.41。AVSBench的通用音视频分割模型在适配到此检测任务后性能大幅落后。
表2:AVIVD数据集上的消融研究
| 研究内容 | 设置 | mAP | AP(M) | AP(I) | AP(Eoff) |
|---|---|---|---|---|---|
| (A) 多尺度视觉融合 | 7×7 | 85.28 | 88.14 | 80.19 | 87.51 |
| 7×7, 14×14 | 82.40 | 88.10 | 67.29 | 91.81 | |
| 7×7, 14×14, 28×28 | 88.63 | 94.35 | 83.41 | 88.12 | |
| (B) SCAQ/AVCE分辨率 | NSCAQ=49 (7×7) | 88.63 | 94.35 | 83.41 | 88.12 |
| NSCAQ=196 (14×14) | 85.06 | 96.37 | 73.61 | 85.19 | |
| (C) 检测头 | 耦合 | 80.95 | 85.25 | 73.19 | 84.41 |
| 解耦 | 85.28 | 88.14 | 80.19 | 87.51 | |
| (D) 麦克风数量 | 1 | 67.98 | 82.96 | 51.78 | 69.20 |
| 3 | 80.98 | 87.08 | 72.96 | 82.91 | |
| 6 | 80.95 | 85.25 | 73.19 | 84.41 |
关键结论:
- 多尺度融合:完整的三尺度融合(7x7, 14x14, 28x28)效果最佳(mAP 88.63),比单尺度提升3.35。
- SCAQ分辨率:49个查询(7x7网格)在整体性能和泛化能力上优于更高密度的设置(196或784个查询)。
- 检测头:解耦头相比耦合头,在所有指标上均有提升,mAP提升4.33,AP(I)提升7.00。
- 麦克风数量:从6个减少到3个,性能仅轻微下降(AP(I)降0.23),表明模型对麦克风数量鲁棒;但单通道性能大幅下滑。
表3:MAVD数据集上的性能对比
| 方法 | 知识蒸馏 | mAP@Avg | mAP@0.5 | mAP@0.75 |
|---|---|---|---|---|
| AVD Loss [17] | ✓ | 58.39 | 78.91 | 56.29 |
| AVIVDNet [1] | ✗ | 35.75 | 55.41 | 16.08 |
| HAVT-IVD (Ours) | ✗ | 69.86 | 84.03 | 55.69 |
关键结论:在MAVD数据集上,HAVT-IVD(无知识蒸馏)的性能大幅超越AVIVDNet,并在mAP@Avg和mAP@0.5上优于所有使用了知识蒸馏的先前方法,证明了模型良好的泛化能力。
⚖️ 评分理由
- 学术质量(6.5/7):论文的技术路线清晰,针对明确的问题设计了有效的解决方案(异质性融合、多尺度、解耦头)。实验设计严谨,包含与多个基线(包括通用AVS模型)的对比、充分的消融研究、以及跨数据集验证,数字证据有力地支撑了结论。主要不足在于创新更多是成熟技术的巧妙组合与应用,而非提出全新的理论或架构。
- 选题价值(1.0/2):研究聚焦于“怠速车辆检测”这一具体的、有实际环保需求的应用场景���成果对特定领域的工程师和研究者有价值。但对于更广泛的音频处理社区(如语音识别、音乐生成)而言,任务的普适性和启发性相对有限。
- 开源与复现加成(0.5/1):论文提供了明确的代码链接(GitHub),并详细给出了训练超参数、损失权重、输入格式等关键信息,极大地便利了复现。但未提供预训练模型权重、数据集获取方式或完整的训练配置文件,因此未获得满分加成。