📄 Hanui: Harnessing Distributional Discrepancies for Singing Voice Deepfake Detection
#音频深度伪造检测 #生成模型 #自监督学习 #音频分类 #鲁棒性
🔥 8.0/10 | 前10% | #音频深度伪造检测 | #生成模型 | #自监督学习 #音频分类
学术质量 5.8/7 | 选题价值 1.5/2 | 复现加成 0.7 | 置信度 高
👥 作者与机构
- 第一作者:未说明(论文标题后并列列出三位作者,无明确标注)
- 通讯作者:未说明
- 作者列表:Seyun Um(延世大学电气电子工程系)、Doyeon Kim(延世大学电气电子工程系)、Hong-Goo Kang(延世大学电气电子工程系)
💡 毒舌点评
亮点:将自编码器在异常检测中的“分布差异”思想巧妙地迁移到深度伪造检测,通过一个简单而深刻的假设(真实声音比伪造声音更难被自编码器准确重建)驱动整个模型设计,思路清晰且有效,泛化性能突出。 短板:整个框架依赖一个精心设计且训练好的自编码器,其计算和训练开销可能高于一些单阶段的判别模型;此外,方法对“伪造声音分布更简单”这一假设的有效性,可能依赖于当前主流伪造技术的水平,面对未来更复杂、更接近真实分布的伪造方法,其优势是否会减弱尚待验证。
🔗 开源详情
- 代码:是,论文明确提供了GitHub代码仓库链接:https://github.com/sam-0927/Hanui
- 模型权重:论文中未提及是否公开预训练模型权重。
- 数据集:论文使用的SingFake和CtrSVDD数据集是公开的,但作者说明因版权限制无法直接分发其重新下载的数据,建议读者自行从YouTube和Bilibili下载原始歌曲。
- Demo:未提及。
- 复现材料:论文提供了相当详细的训练细节,包括优化器设置、学习率、训练轮次、batch size、损失函数权重等,以及完整的模型架构描述,有助于复现。
- 论文中引用的开源项目:论文提到了多个作为基线的开源工作或模型,如LFCC+ResNet [3], AASIST [12], wav2vec2 [15], wav2vec2+AASIST [14],以及用于音频压缩的Descript Audio Codec [27]。
📌 核心摘要
- 要解决什么问题:现有歌唱语音深度伪造检测(SVDD)方法在面对未见过的歌手、音乐风格和语言时,泛化能力不足,性能下降明显。
- 方法核心是什么:提出名为Hanui的新框架,其核心思想源自异常检测:利用自编码器(AE)重建输入信号,然后通过判别器提取特征图来衡量原始信号与重建信号之间的分布差异。核心假设是:真实歌声的分布更复杂,因此其原始-重建差异大于伪造歌声的差异。
- 与已有方法相比新在哪里:不同于以往直接学习分类特征的方法,Hanui显式地建模并利用了真实与伪造信号在“可重建性”上的分布差异。具体创新包括:1)提出基于分布差异的SVDD新范式;2)采用两阶段训练(先训练仅用真实数据的自编码器,再训练用真实+伪造数据的检测器);3)设计了基于多频段判别器中间特征图的检测器融合策略。
- 主要实验结果如何:在SingFake和CtrSVDD数据集上,Hanui取得了最优的等错误率(EER)。例如,在最挑战的未见条件T04(未见歌手、语言、风格)上,Hanui的EER为21.36%,相比最强基线wav2vec2+AASIST(34.18%)绝对降低了12.82个百分点,相对降低约37.5%。消融实验证实了分布差异假设(图2)和中间层融合策略的有效性。
- 实际意义是什么:该方法显著提升了在真实、复杂场景下(歌手、语言、风格均未知)检测伪造歌声的鲁棒性,对于构建可靠的内容安全系统具有直接应用价值。
- 主要局限性是什么:1)模型训练分为两个阶段,且需要训练多个判别器和检测器模块,整体计算成本可能较高;2)对“伪造声音分布更简单”这一核心假设的验证,依赖于当前生成模型的特性,其长期有效性有待观察;3)论文中未提及模型权重是否开源,且因版权限制无法分发训练数据,这限制了完全的复现。
🏗️ 模型架构
Hanui的整体架构如图1所示,主要由两个阶段、两大模块构成:自编码器(含判别器)和深度伪造检测器。
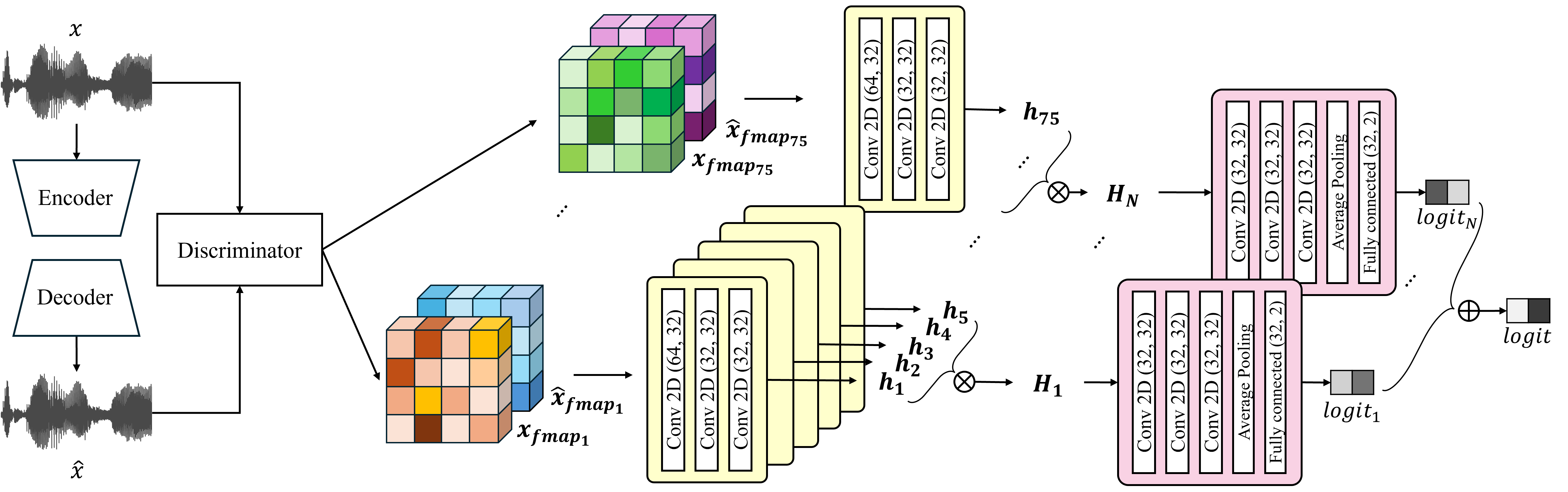
自编码器(Autoencoder)阶段:
- 目的:学习真实歌声的分布,并为检测器提供富含分布差异信息的特征图。
- 编码器(Encoder):由6层1D卷积层组成,卷积核大小为7,步长配置为[5, 4, 2, 2, 2, 2],总下采样率为256。通道数从64逐层增加到1024,将输入波形压缩为紧凑的潜在表示。
- 解码器(Decoder):与编码器对称,由6层转置卷积层组成,通道数从1024对称地减少回1,并使用残差连接以保留波形细节。
- 判别器(Discriminator):用于对抗训练,包含5个多周期判别器(MPD,处理时域波形)和3个多分辨率判别器(MRD,处理频谱图)。MRD将频谱图分为5个子频带进行处理。判别器的作用是区分原始波形和自编码器重建的波形,其训练目标是让重建波形更逼真,而自编码器的目标是“欺骗”判别器。
- 训练:仅使用真实(bona fide)歌声训练自编码器。损失函数(式4)是多种损失的加权和:频谱图距离损失(Lstft, Lmel)、波形重建损失(Lwave)、对抗损失(Lgan)和特征匹配损失(Lfm)。
深度伪造检测器(Detector)阶段:
- 输入:判别器(特指MRD)在处理原始输入和重建输入时提取的中间层特征图(fmap)。对于真实样本,输入对是(x_b, fmap_b, ˆx_b, fmap_b);对于伪造样本,输入对是(x_s, fmap_s, ˆx_s, fmap_s)。
- 设计:检测器由多个并行的小型CNN块组成(论文中N=15,对应5个子频带 × 3个MRD分辨率)。每个检测器块处理一组特定的特征图。
- 单个检测器块结构:
- 第一CNN块(Conv.1):接收5个特征图(对应一个子频带下的5层MRD输出),将其拼接后通过卷积层进行中层融合,输出1个融合后的特征图(Hi)。
- 第二CNN块(Conv.2):对Hi进行进一步卷积处理。
- 分类头:经过平均池化(Pool)和全连接层(FC)输出一个logit。
- 最终决策:所有15个检测器块的logit相加,得到最终的logit值,用于二分类(真实/伪造)。训练时使用OC-Softmax损失。
数据流:波形输入 → 自编码器重建 → 判别器(MRD)提取原始与重建信号的特征图 → 特征图对输入并行检测器 → 每个检测器输出logit → 求和得到最终判断。
💡 核心创新点
- 基于分布差异的SVDD新框架:首次将异常检测中“正常数据易重建,异常数据难重建”的思想,明确转化为“伪造歌声易重建,真实歌声难重建”的假设,并以此为核心设计检测模型。这跳出了传统SOTA方法(如AASIST, wav2vec2+AASIST)依赖预训练SSL模型进行端到端特征学习的思路。
- 两阶段对抗训练范式:第一阶段训练自编码器专注于学习真实歌声的分布(使用对抗损失);第二阶段冻结自编码器,训练检测器利用判别器的“副产品”——特征图——来量化分布差异。这种设计使两个阶段的目标更纯粹、更高效。
- 基于判别器中间特征的检测器设计:不直接使用自编码器的重建误差作为特征,而是巧妙地利用对抗训练中判别器为了“鉴别真伪”而提取的、对分布差异敏感的中间特征图作为检测器的输入。论文实验证明,多分辨率判别器(MRD)的特征比多周期判别器(MPD)的特征更有效。
🔬 细节详述
- 训练数据:使用SingFake数据集,包含约29小时的真实与伪造歌声,涵盖5种语言、40位歌手。训练、验证、测试集划分已给定。注意:由于版权限制,作者重新从YouTube和Bilibili下载了歌曲,而非直接使用官方数据。排除了用DEMUCS分离的歌声。评测时还使用了CtrSVDD测试集(仅用于评估)。
- 损失函数:自编码器总损失为加权和(式4):
Ltotal = Lstft + λmel Lmel + Lwave + Lgan + λfm Lfm。其中λmel=15,λfm=2。检测器使用OC-Softmax损失(一种单类分类损失,适合此类问题)。 - 训练策略:使用AdamW优化器(β1=0.8, β2=0.99, ϵ=1e-9)。Batch size为32。初始学习率为2e-4。自编码器训练400 epochs,检测器训练500 epochs。
- 关键超参数:编码器/解码器均为6层1D卷积;下采样率256;通道数范围64-1024;MRD使用5个子频带;每个检测器块使用两个CNN块,第二块卷积核通道数为32。
- 训练硬件:单块NVIDIA RTX 3090 GPU。
- 推理细节:未明确提及温度或beam search等参数,检测器输出logit求和后直接用于计算EER等指标。
- 正则化技巧:自编码器部分通过对抗训练和特征匹配损失(Lfm)隐式正则化;检测器使用中间层融合策略,可视为一种特征正则化。
📊 实验结果
主要定量结果(EER %): 论文在SingFake数据集的验证集(Valid)、四个测试集(T01-T04)以及CtrSVDD数据集的开发集(Dev)和测试集(Test)上进行了评估。关键结果如下表所示:
| 模型 | SingFake Valid ↓ | SingFake T01 ↓ | SingFake T02 ↓ | SingFake T03 | SingFake T04 ↓ | SingFake Average ↓ | CtrSVDD Dev ↓ | CtrSVDD Test ↓ |
|---|---|---|---|---|---|---|---|---|
| LFCC+ResNet | 32.4 | 22.93 | 36.87 | 34.84 | 38.85 | 33.17 | 42.07 | 44.4 |
| Spectrogram+ResNet | 38.85 | 56.14 | 44.48 | 45.23 | 48.68 | 46.57 | 54.33 | 51.19 |
| AASIST | 14.11 | 9.77 | 15.11 | 16.77 | 30.35 | 17.22 | 38.66 | 37.18 |
| wav2vec2+AASIST | 14.95 | 5.85 | 16.75 | 19.02 | 34.18 | 18.15 | 38.42 | 40.2 |
| Hanui (Proposed) | 6.28 | 7.65 | 11.2 | 13.23 | 21.36 | 11.94 | 35.91 | 32.23 |
| Hanui-l (Proposed) | 7.51 | 8.2 | 11.68 | 16.88 | 23.73 | 13.6 | 36.69 | 28.2 |
关键结论:
- Hanui在几乎所有测试集(除了用于训练歌手匹配的T01)上均取得了最低的EER,平均EER(11.94%)远低于最强基线wav2vec2+AASIST(18.15%)。
- 在最具挑战性的未见条件(T04:未见歌手、语言、风格) 和 CtrSVDD(未见数据集) 上,Hanui优势尤为明显。在T04上EER为21.36%,比wav2vec2+AASIST的34.18%降低了约37.5%(相对值)。在CtrSVDD Test集上,EER从40.2%降至32.23%。
- 消融实验证实了分布差异假设。图2显示,真实样本(bona fide)在判别器上的重建损失(特征图损失)持续高于伪造样本(spoofed),验证了原始假设。
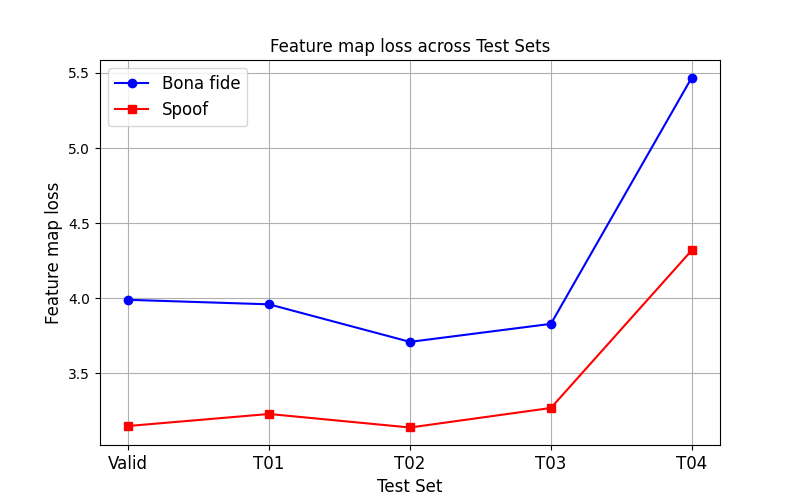 (图2说明:该图展示了在SingFake数据集上,使用MRD特征计算的真实样本与伪造样本的重建损失对比。真实样本的损失值(蓝色曲线)系统地高于伪造样本(橙色曲线),为“真实歌声更难重建”的假设提供了直接证据。)
(图2说明:该图展示了在SingFake数据集上,使用MRD特征计算的真实样本与伪造样本的重建损失对比。真实样本的损失值(蓝色曲线)系统地高于伪造样本(橙色曲线),为“真实歌声更难重建”的假设提供了直接证据。)
- 关于融合策略的消融实验表明,提出的中层融合策略(Hanui) 优于晚期融合策略(Hanui-l),尤其是在泛化条件T04上(21.36% vs 23.73%)。
⚖️ 评分理由
- 学术质量:5.8/7:创新性强,提出了一个理论清晰、模型新颖的SVDD框架。技术实现严谨,从损失函数设计到网络结构均有据可依。实验非常充分,对比了多个强劲基线,在多个数据集和多种泛化场景下验证了方法的有效性,并进行了关键的消融实验。证据链完整,可信度高。
- 选题价值:1.5/2:选题紧扣当前AI伦理与安全的热点——深度伪造检测,且聚焦于更具挑战性的歌唱语音场景。论文明确指出了现有技术在泛化性上的瓶颈,并提出有效解决方案,对学术界和工业界(如音乐流媒体平台、版权保护)均有明确价值。
- 开源与复现加成:0.7/1:论文提供了详细的架构描述、训练配置、损失函数公式,并给出了明确的代码仓库链接,极大地便利了复现。然而,未提及公开预训练模型权重,且因数据版权限制无法提供原始数据集,这略微增加了完全复现的门槛。