📄 H-nnPBFDAF: Hierarchical Neural Network Partitioned Block Frequency Domain Adaptive Filter with Novel Block Activation Probability
#语音增强 #信号处理 #时频分析 #实时处理 #低资源
✅ 7.5/10 | 前25% | #语音增强 | #信号处理 | #时频分析 #实时处理
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Jitao Ma(浙江大华技术股份有限公司)(论文标注为共同第一贡献)
- 通讯作者:Ruidong Fang(浙江大华技术股份有限公司)
- 作者列表:Jitao Ma(浙江大华技术股份有限公司),Jingbiao Huang(浙江大华技术股份有限公司),Ruidong Fang(浙江大华技术股份有限公司),Jucai Lin(浙江大华技术股份有限公司),Han Xue(浙江大华技术股份有限公司),Yapeng Mao(浙江大华技术股份有限公司),Jun Yin(浙江大华技术股份有限公司)
💡 毒舌点评
本文亮点在于提出了“块激活概率”这一巧妙机制,用一个紧凑的神经网络同时解决了传统自适应滤波器步长选择和滤波器长度固定两大痛点,且计算开销极低。然而,纯线性框架可能在处理设备扬声器严重非线性失真时存在天花板,而论文中的对比实验(如与Deep Adaptive AEC的比较)也显示在复杂场景下其性能仍不及更重的混合方法,且代码未开源限制了复现价值。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开权重。
- 数据集:论文中使用的LibriSpeech、DNS Challenge、SLR28、Aachen Impulse Response、AEC Challenge数据集均为公开可获取的。
- Demo:未提及在线演示。
- 复现材料:论文提供了模型架构概述、关键公式和部分训练数据设置,但缺乏详细的训练超参数(优化器、学习率、batch size等)、训练硬件信息以及最终模型的具体配置,复现难度较高。
- 论文中引用的开源项目:
- 数据集:LibriSpeech [17], DNS Challenge [18], SLR28 [19], Aachen Impulse Response [20], AEC Challenge Dataset [21]。
- 工具:AECMOS评估工具包 [23]。
- 对比方法:公开的NKF Demo [12], Deep Adaptive AEC [10]。
- 开源计划:论文中未提及开源计划。
📌 核心摘要
- 问题:在低成本消费设备上部署声学回声消除(AEC)时,传统自适应滤波器(如PBFDAF)面临步长选择困难、滤波器长度需手动固定以适应不同回声路径、以及现有神经网络混合方法计算成本过高的挑战。
- 方法核心:提出神经网络分块频域自适应滤波器(nnPBFDAF)。核心是一个轻量神经网络,它同时估计频域步长向量(用于替代固定步长)和块激活概率向量(每个分块一个概率值)。块激活概率向量的和可用于间接控制有效滤波器长度,实现自动适应。进一步提出两阶段层次结构(H-nnPBFDAF),第一阶段估计的回声作为第二阶段的参考信号,以提升鲁棒性。
- 创新点:a) 将神经网络步长估计与PBFDAF深度融合;b) 引入块激活概率向量,首次解决了固定分块数PBFDAF无法自适应不同回声路径长度的难题;c) 设计两阶段级联架构(H-nnPBFDAF),以粗到精的方式提升回声估计精度。
- 实验结果:在三个测试集上进行评估。如表1所示,在模拟短回声路径(Subset 1)上,H-nnPBFDAF的PESQ为3.12,ERLE为34.57 dB,优于传统PBFDKF(PESQ 2.93, ERLE 25.77 dB)。在AEC Challenge盲测集(Subset 2)上,H-nnPBFDAF在双讲回声评价(DT-E)得分为3.40,略低于Deep Adaptive AEC(4.40),但计算复杂度仅为其约1/26。在真实消费设备数据(Subset 3)上,H-nnPBFDAF的ERLE为21.47 dB,显著优于NKF(7.29 dB)。消融实验(表2)证实,采用块激活概率的nnPBFDAF在不同回声路径长度下的平均PESQ(2.87)优于所有固定分块数模型。
- 实际意义:该方法在极低计算开销(仅占ARM Cortex-A35单核<9%资源)下实现了高性能AEC,并能自动适应回声路径变化,非常适合资源受限的消费类电子产品(如智能音箱、会议设备)部署,且模型已实际部署。
- 主要局限性:作为线性AEC框架,对高度非线性失真的回声消除能力可能有限;神经网络部分的具体结构和训练策略细节(如优化器、学习率)未完全公开;代码未开源。
🏗️ 模型架构
模型的核心是nnPBFDAF模块,其整体流程和内部结构如下图所示:
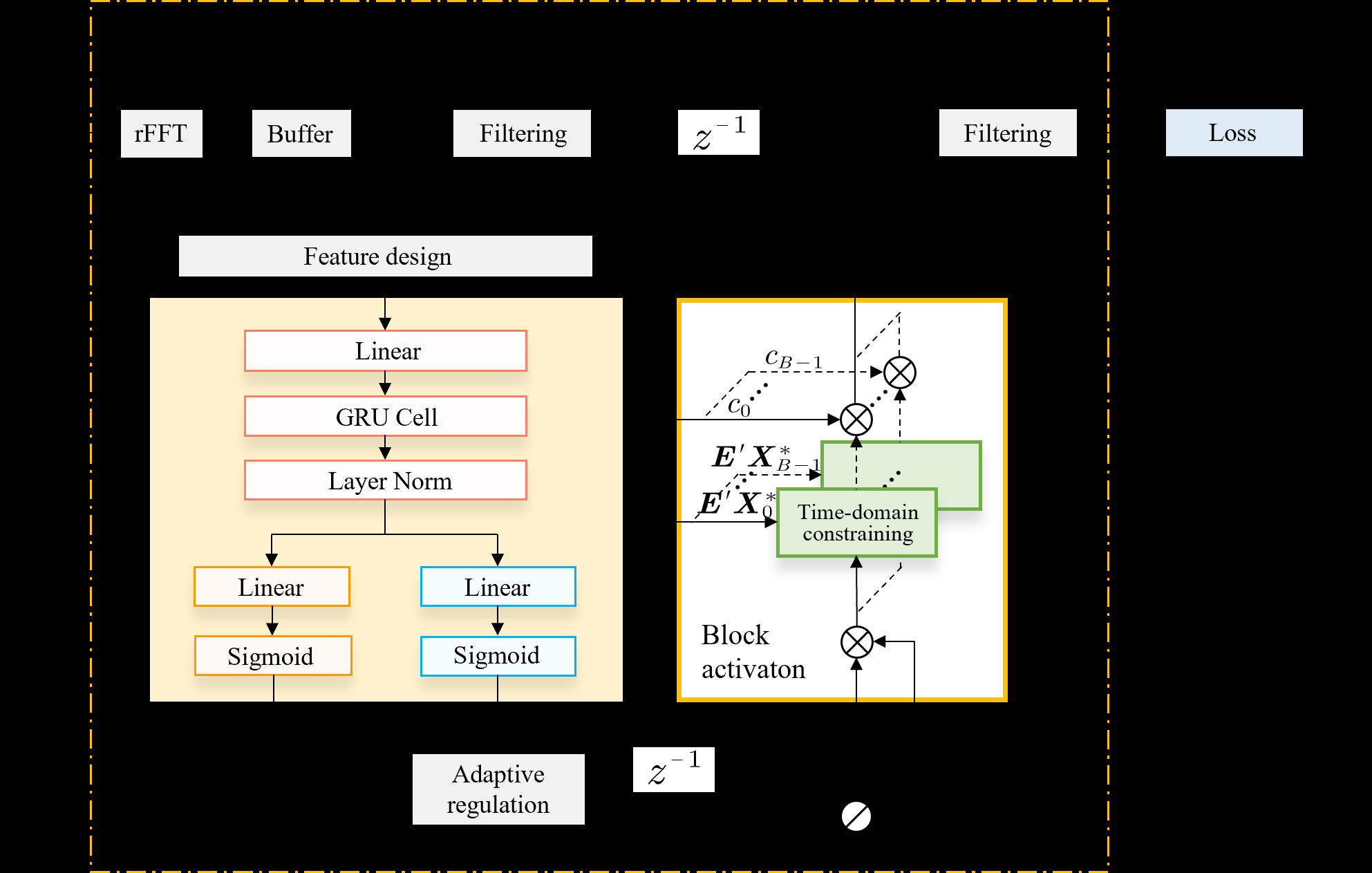
- 输入输出:输入为参考信号
x(n)和麦克风信号d(n)。输出为估计的回声e(m)。 - PBFDAF基础:信号被分块并变换到频域。滤波器权重
H(m)在频域被分割成B个块。回声估计通过对所有块的频域乘积求和并变换回时域得到(公式6)。 - nnPBFDAF核心改进(图1a):
- 神经网络步长估计器:输入为当前帧参考信号第0块的幅度谱
|X0(m)|和误差信号的幅度谱|E'(m)|(公式15)。网络结构包含两层全连接(FC)、一个门控循环单元(GRU)和一个层归一化(LN)层(公式16),最终输出两个向量:频域步长向量µnn(m)和块激活概率向量c(m)(公式17)。 - 块激活概率机制:向量
c(m)中的每个元素cb(m)是一个0到1的概率值,用于加权对应滤波器块Hb(m)的更新幅度(公式14)。更重要的是,c(m)的元素和Bnn(m)被用作有效滤波器块数的估计,用于自适应调整频率域自正交化因子A(m)(公式13),从而间接控制整个滤波器的有效长度。
- 神经网络步长估计器:输入为当前帧参考信号第0块的幅度谱
- H-nnPBFDAF层次结构(图1b):
- 第一级nnPBFDAF:接收原始的
x(m)和d(m),输出初步回声估计e1(m)。 - 第二级nnPBFDAF:以
x(m)和第一级的误差e1(m)作为输入(论文中“refined reference signal”指e1(m)被用作新的参考信号进行第二次滤波),输出最终的回声估计e(m)。两级网络结构相同但独立训练。
- 第一级nnPBFDAF:接收原始的
💡 核心创新点
- 神经网络与PBFDAF的深度融合:并非简单用NN做前端或后端处理,而是让紧凑的NN直接估计并输出频域步长向量,用于逐块、逐频带地精细化控制自适应滤波器的更新过程,比传统全局标量步长更灵活。
- 块激活概率实现自适应滤波器长度:这是论文最核心的创新。传统PBFDAF的分块数
B需预先固定,无法匹配变化的回声路径。c(m)向量通过给每个块分配一个“激活”概率,使网络能够动态地决定哪些块应该被更新、哪些应该被抑制,其和Bnn(m)自然成为了有效滤波器长度的估计器,无需手动调整B。 - 两阶段级联架构(H-nnPBFDAF):采用“粗到精”的策略。第一级nnPBFDAF作为回声路径的初步估计器和参考信号生成器,其输出为第二级提供了更“纯净”的特征和参考信号,有助于在恶劣条件(如双讲、非线性失真)下提升最终回声估计的精度。
- 极低复杂度设计:整个NN步长估计器参数量极小(0.058M),计算量(5.91 M MACs/sec)与传统PBFDKF(8.1% ARM核)相当,远低于Deep Adaptive AEC(312.67 M MACs/sec)。这使其能在资源受限的实时系统中部署。
🔬 细节详述
- 训练数据:
- Subset 1:训练数据来自LibriSpeech train-clean-100的远端/近端信号,噪声来自DNS Challenge,房间脉冲响应(RIR)来自SLR28。场景设置为20%远讲(FST)、30%近讲(NST)、50%双讲(DT)。测试数据来自train-clean-360和Aachen Impulse Response数据集。
- Subset 2:使用AEC Challenge数据集。训练集由合成数据和真实录制数据(仅FST)混合而成。
- Subset 3:从真实消费设备收集的数据,谐波失真>20%,存在严重削波。训练/测试比9:1。
- 数据增强:回声通过非线性函数([16])处理并与RIR卷积生成,然后与噪声、近讲信号以不同SER(-20
5dB)和SNR(515dB)混合。
- 损失函数:
- 回声感知损失
Lecho:基于估计信号和目标信号谱的损失(论文未给出具体公式,引用自[7])。 - 块激活概率的二值交叉熵损失
LBCE:见公式18,用于监督每个块激活概率cb趋向0或1。yb是块是否活跃的标签(可能基于真实回声路径长度生成)。 - 总损失:
Loss = Lecho + 0.1 * LBCE。LBCE的权重为0.1。
- 回声感知损失
- 训练策略:论文中未明确说明优化器、学习率、warmup策略、batch size、训练步数/轮数等关键细节。
- 关键超参数:
- 音频采样率:16 kHz。
- FFT点数:320,帧移:50%。
- NN隐藏层大小:64。
- 最大分块数
B:32(但可通过Bnn自适应)。 - PBFDAF遗忘因子
β:0.9。
- 训练硬件:论文中未说明。
- 推理细节:采用ARM NEON优化以实现实时运行。模型已部署到消费设备。
- 正则化技巧:使用
LBCE损失对块激活概率进行正则化,引导其学习离散的激活模式。
📊 实验结果
表1:不同测试集上的模型性能对比
| 方法 | 参数量(M) | MACs(M/sec) | Subset 1 (短回声路径) | Subset 2 (AEC Challenge) | Subset 3 (消费设备) |
|---|---|---|---|---|---|
| PESQ | ERLE | FST-E | |||
| raw | 0 | 0 | 0.7 | 0 | 2.01 |
| PBFDKF | - | - | 2.93 | 25.77 | 2.63 |
| nnPBFDAF | 0.058 | 5.91 | 3.12 | 30.70 | 3.23 |
| H-nnPBFDAF | 0.116 | 11.83 | 3.12 | 34.57 | 3.44 |
| NKF320 | 0.005 | 160.99 | 1.87 | 16.45 | 3.25 |
| NKF1024 | 0.005 | 319.96 | 2.89 | 26.59 | 3.30 |
| Deep Adaptive AEC | 3.08 | 312.67 | 2.37 | 51.50 | 4.57 |
- 关键结论:
- 性能 vs. 传统方法:在所有子集上,nnPBFDAF和H-nnPBFDAF在ERLE或PESQ指标上显著优于传统PBFDKF和NKF(尤其是Subset 3消费设备数据)。
- 性能 vs. 其他混合方法:在Subset 2(AEC Challenge)上,H-nnPBFDAF的DT-E得分(3.40)低于Deep Adaptive AEC(4.40),表明在复杂失真下其线性框架仍有差距。但在Subset 1和3上表现良好。
- 复杂度优势:nnPBFDAF的计算量(5.91 MACs/sec)仅为Deep Adaptive AEC(312.67 MACs/sec)的约1.9%,甚至与NKF320(160.99 MACs/sec)相比也有显著优势,实现了极高的计算效率。
- 层次结构增益:H-nnPBFDAF在大多数指标上优于单级nnPBFDAF(如Subset 1 ERLE从30.70提升至34.57 dB,Subset 3 ERLE从17.75提升至21.47 dB),验证了级联设计的有效性。
表2:固定分块数 vs. 自适应分块数(块激活概率)的效果对比
| Block Num | 800 (5B) | 1600 (10B) | 3200 (20B) | 10000 (30B) | 平均 |
|---|---|---|---|---|---|
| PESQ | ERLE | PESQ | ERLE | PESQ | |
| B=5 | 3.16 | 31.35 | 2.82 | 27.86 | 2.25 |
| B=10 | 2.97 | 30.94 | 2.98 | 30.54 | 2.62 |
| B=20 | 2.74 | 27.34 | 2.91 | 26.98 | 2.76 |
| B=30 | 2.52 | 23.61 | 2.77 | 23.44 | 2.70 |
| Bnn (自适应) | 3.12 | 30.70 | 3.00 | 30.14 | 2.93 |
- 关键结论:使用固定分块数
B的模型,只有当B与实际回声路径长度匹配时才能达到较好效果,不匹配时性能急剧下降(如B=5模型处理10000点回声时PESQ仅1.71)。而采用块激活概率(Bnn)的nnPBFDAF在几乎所有长度组别上都取得了最佳或接近最佳的PESQ和ERLE,其平均PESQ(2.87)也高于所有固定B的模型。这直接证明了块激活概率机制在兼容不同回声路径长度上的成功。
⚖️ 评分理由
- 学术质量:6.0/7 - 创新点明确且有实际价值(块激活概率解决自适应长度问题),技术方案合理,实验设计充分(多个数据集、对比传统与混合方法、消融实验)。扣分点在于:1)创新更多是工程上的巧妙组合,而非基础理论突破;2)在复杂场景(如AEC Challenge)的性能仍落后于更复杂的混合方法;3)训练部分细节(如优化器)缺失。
- 选题价值:1.5/2 - 声学回声消除是语音通信和智能设备的核心基础问题,具有明确的工程应用价值。本文聚焦于“低复杂度”和“自适应长度”这两个实际部署中的痛点,方向明确,对工业界(尤其是消费电子)有较强吸引力。选题虽不前沿但扎实有用。
- 开源与复现加成:0.0/1 - 论文未提供代码、预训练模型权重或详细的训练配置(如优化器、学习率)。仅提及模型已部署,这大大降低了可复现性。文中引用的工具均为公开数据集,但自身未贡献新开源资源。