📄 Group-Sparse Gaussian Process Regression for Inhomogeneous Sound Field Estimation
#声场估计 #高斯过程回归 #麦克风阵列 #稀疏优化
✅ 7.5/10 | 前25% | #声场估计 | #高斯过程回归 | #麦克风阵列 #稀疏优化
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0 | 置信度 中
👥 作者与机构
- 第一作者:Ryo Matsuda(京都大学工学部)
- 通讯作者:Makoto Otani(京都大学工学部)
- 作者列表:Ryo Matsuda(京都大学工学部)、Makoto Otani(京都大学工学部)
💡 毒舌点评
这篇论文在传统声场估计框架下做出了扎实的改进,亮点在于巧妙地将群稀疏约束引入高斯过程回归核权重优化,摆脱了对先验声源位置的依赖,并在仿真中取得了显著的性能提升。然而,其短板在于实验部分过于理想化(无回声、二维平面),缺乏对实际复杂声学环境(如混响、三维空间)的验证,且未提供任何开源代码,这使得其提出的方法在实际应用中的鲁棒性和可复现性存疑。
🔗 开源详情
- 代码:论文中未提及代码链接或开源仓库。
- 模型权重:未提及。
- 数据集:实验为数值仿真生成,未提供生成代码或具体数据。
- Demo:未提供在线演示。
- 复现材料:论文给出了部分实验设置(如麦克风数量、区域大小、频率范围、噪声模型、部分超参数范围),但关键训练细节(如优化器停止准则、ν_tr的具体计算公式、ζ的最终取值)不充分,难以完全复现。
- 论文中引用的开源项目:论文引用的文献中,[18] (Koyama & Daudet, 2019) 的算法被用于基线实现,但未说明是否使用其开源代码。论文本身未明确列出依赖的开源工具。
结论:论文中未提及开源计划。
📌 核心摘要
- 要解决什么问题:传统稀疏点源分解(PSD)方法估计包含声源的非均匀声场时,依赖预设的潜在声源位置网格,若与实际位置不匹配会导致估计精度下降。另一类基于高斯过程回归(GPR)和连续核函数的方法虽然更准确,但需要先验的声源位置信息进行贪婪优化,这在实际中往往不可用。
- 方法核心是什么:本文提出一种基于群稀疏(group sparsity)的核权重优化方法。在GPR框架下,将声场建模为多个“源区域”(SR)核函数的加权和。核心假设是:(i) 声源空间分布是稀疏的;(ii) 该分布在所有频率上是相同的。利用这两个假设,将核权重矩阵的优化问题转化为一个带群稀疏正则化(L1,2范数)的负对数边缘似然最小化问题,并通过近端梯度法求解。
- 与已有方法相比新在哪里:新在无需任何先验声源位置信息。通过群稀疏约束自动学习一个跨频率共享的、稀疏的核权重集合,从而识别出与观测数据最相关的少数几个SR核。这比依赖先验位置贪婪选择二进制权重的旧方法更灵活、更优化。
- 主要实验结果如何:在无回声、二维圆形区域(半径1.0m)的数值仿真中,与单极子PSD和多极子PSD方法相比,所提方法在几乎所有频率上实现了最低的归一化均方误差(NMSE)。例如,在125 Hz附近,NMSE降低了超过15 dB;在4 kHz附近,降低了超过5 dB。图2(pdf-image-page4-idx1)直观显示,该方法能更准确地重建2 kHz的声场,误差分布(图3,论文未提供图3的URL,故无法展示)更小。
- 实际意义是什么:为在未知声源位置情况下,利用麦克风阵列数据准确估计包含声源的复杂声场提供了一种更有效、更自动化的方法,可提升后续声场重现、噪声控制等应用的性能。
- 主要局限性是什么:实验局限在理想的无回声条件和二维平面;假设声源分布跨频率不变可能在某些动态场景下不成立;对计算复杂度和参数(如平衡参数ζ)的选择敏感性未深入讨论。
🏗️ 模型架构
该方法并非一个神经网络架构,而是基于概率模型(高斯过程回归)的优化框架。其核心组件和流程如下:
- 输入:M个麦克风在F个频率点上的复声压观测值矩阵 Y ∈ ℂ^{M×F}。
- 核函数模型(MSR Kernel):将目标区域 Ω 离散为S个子区域(SR),每个SR对应一个核函数 κ_f^{(s)}(r_i, r_j),其形式是自由场格林函数的加权相关(式13)。整个声场的核矩阵 K_f 是这些子区域核矩阵的加权和:K_f = ∑{s=1}^S γ{s,f} K_f^{(s)},其中 γ_{s,f} ≥0 是待优化的权重。
- 高斯过程回归(GPR):在复数域零均值GPR下,给定观测 y_f,位置r处的声场预测均值为 ĉu(r) = κ_f(r) (K_f + σ²_ε I)⁻¹ y_f(式15)。
- 优化目标:优化核权重矩阵 Γ ∈ ℝ^{S×F},以最小化所有频率的负对数边缘似然之和,并加入群稀疏正则项(式17):min_{Γ} ∑{f=1}^F L_f(γ_f) + ζ J{1,2}(Γ),其中 L_f 是负对数边缘似然(式16),J_{1,2}(Γ) = ∑_{s=1}^S ||γ_s||_2 是组(按SR分组)L1范数。
- 求解算法:采用近端梯度法迭代求解(式20)。梯度计算涉及核矩阵的导数(式21)。近端算子对应一个非负的群软阈值操作(式24),它利用声源分布跨频率不变的假设,对权重矩阵的每一行(对应一个SR在所有频率的权重)进行联合稀疏化。
整个流程的数据流为:观测数据 → 构建每个频率的字典核矩阵 K_f^{(s)} → 通过迭代优化学习稀疏权重 Γ → 得到最终的核矩阵 K_f 和预测模型。
💡 核心创新点
无需先验声源位置的核权重优化:摆脱了先前基于连续核的声场估计方法对已知或近似声源位置的依赖。通过数据驱动的群稀疏优化,自动确定哪些“源区域”对声场有贡献。
- 之前局限:参考文献[22]的方法需要通过贪婪搜索选择核权重,且依赖先验位置信息,计算量大且非最优。
- 如何起作用:将核权重视为待学习的参数,利用观测数据本身在GPR框架内进行联合估计。
- 收益:提高了方法的实用性和鲁棒性,使其能应用于更一般的未知声源场景。
基于声源分布特性的群稀疏正则化:明确利用了“声源空间稀疏”和“声源分布跨频率不变”两个物理假设来约束核权重优化。
- 之前局限:传统PSD方法也利用稀疏性,但仅在单一频率上独立优化,且依赖预设网格点。
- 如何起作用:J_{1,2}正则化惩罚了每个SR权重向量(跨频率)的L2范数,从而倾向于使整个向量变为零。这意味着,如果一个SR在某一频率不重要,它在所有频率上都可能被抑制,从而发现一个跨频率一致的稀疏声源模式。
- 收益:增强了估计的稳定性,减少了需要估计的参数数量,并确保了物理一致性(声源位置不随频率改变)。
连续源分布建模优于离散点源:核心模型仍然是基于连续源分布的MSR核,这比将声场表示为有限个离散点源的PSD方法更灵活,能更好地匹配真实的、可能具有延展性的声源分布。
- 之前局限:PSD方法在声源位置与网格不匹配时性能急剧下降。
- 如何起作用:每个SR核代表一个小区域内的连续分布贡献,通过加权组合来近似整个声源分布。
- 收益:对声源位置失配具有更强的鲁棒性,理论上能达到更高的估计精度(如图1所示)。
🔬 细节详述
- 训练数据:数值仿真生成。在无回声条件下,目标区域为半径1.0m的圆形。16个麦克风均匀放置在边界上。两个单极点声源位于指定坐标。声压通过公式(2)计算得到。测量噪声为信噪比30dB的零均值复高斯噪声。频率范围125 Hz - 4 kHz,间隔125 Hz。进行20次独立实验取平均。
- 损失函数:主要损失是GPR的负对数边缘似然 L_f(式16)。正则项是群稀疏正则 ζ J_{1,2}(Γ)。两者通过平衡参数 ζ 结合。
- 训练策略:采用加速近端梯度法求解。步长 η = 10⁻⁴。最大迭代次数未明确,但基线PSD方法设定为2000次。平衡参数 ζ 从 {10^l | l ∈ ℤ, -3 ≤ l ≤ 2} 中选择,使得在3 kHz时的NMSE最小。
- 关键超参数:
- SR数量 S = N(与PSD方法网格点数相同,分别为197和795)。
- SR半径 ρ = δ/√2,δ为网格间距。
- 权重函数参数 σ = ρ/3。
- 噪声方差 σ²_ε = 10⁻³。
- 群稀疏参数 p=1, q=2。
- SR核的球谐函数展开最大阶数 ν_tr 根据频率和ρ确定(未详细给出公式)。
- 训练硬件:论文中未提及。
- 推理细节:优化完成后,对于任意新位置r,声场预测直接使用式(15)计算。无需迭代。
- 正则化/稳定技巧:群稀疏正则化本身起到防止过拟合的作用。权重非负约束(γ_{s,f} ≥0)保证了物理意义。近端算子中的软阈值操作提供了稳健的稀疏化。
📊 实验结果
论文主要提供了一张定量比较图(图1)和一张定性声场图(图2)。
定量结果(图1): 论文未给出表格形式的具体数值,但描述了关键结论:
- 在几乎所有频率上,所提方法(Proposed)的归一化均方误差(NMSE,dB)均低于单极子PSD和多极子PSD(MP-PSD)方法。
- 与相同网格间隔(δ)的基线方法相比,在低频(125 Hz附近),Proposed的NMSE降低了超过15 dB。
- 在高频(4 kHz附近),Proposed的NMSE降低了超过5 dB。
- MP-PSD仅在较高频率且使用更密网格(δ=0.05m)时表现出对PSD的明显优势,而在低频时两者性能相同(因为都选择了 ν_tr=0)。
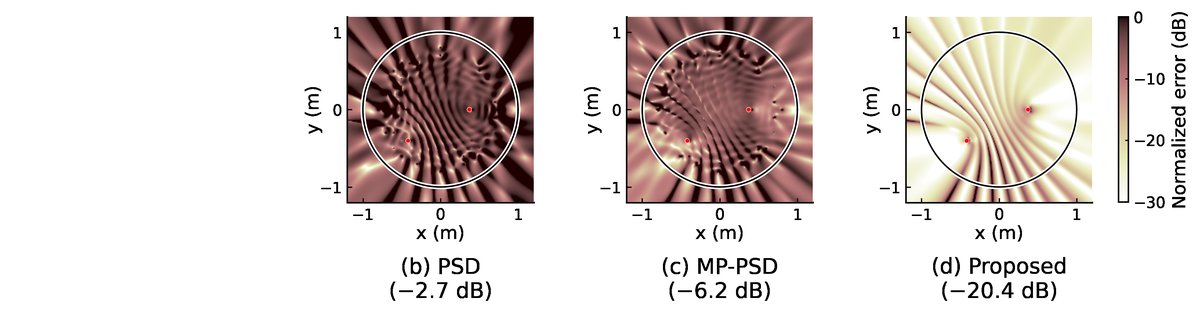
定性结果(图2 & 描述中的图3):
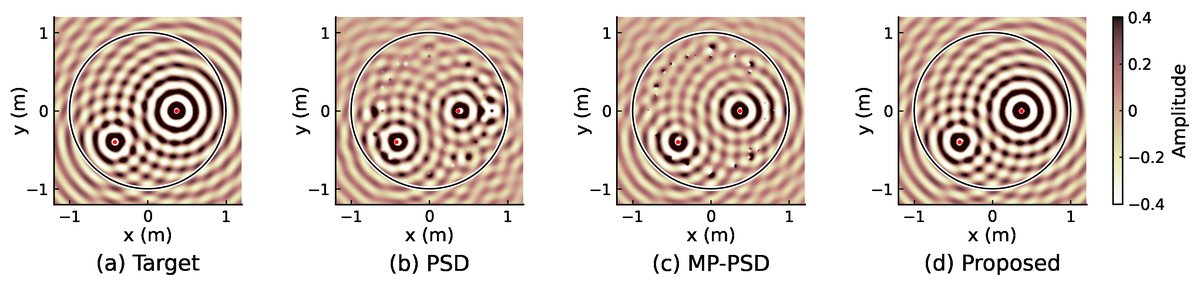
- 图2(pdf-image-page4-idx1)直观展示了Proposed方法在2 kHz时能更准确地重建声场。PSD和MP-PSD由于激活了错误或多余的网格点,导致整个声场重建出现误差。
- 论文提及的图3(未提供URL)展示了归一化误差分布,Proposed方法的误差在整个评估区域都更低。
关键对比:论文的主要对比基线是组稀疏PSD(式6)和组稀疏多极子PSD(式10),后者在高频使用更高阶模态。Proposed方法通过连续核和群稀疏优化,在性能上全面超越了这两类离散点源分解方法。
⚖️ 评分理由
- 学术质量:6.0/7:论文问题定义清晰,技术路线合理(GPR+连续核+群稀疏),推导严谨。实验设计能有效验证假设,并与强基线进行比较,结果具有说服力。扣分点在于:创新属于渐进式改进而非范式变革;实验环境理想,缺乏对实际复杂声学场景的验证;部分参数选择(如ζ)依赖特定频率的调优,可能影响泛化性。
- 选题价值:1.5/2:声场估计是阵列信号处理和声学的基础问题。本文解决的是该领域中一个具体但重要的挑战(未知声源位置的非均匀声场估计),对声场重现、有源噪声控制等下游应用有直接价值。研究问题前沿且有明确应用动机。
- 开源与复现加成:0/1:论文中未提及代码、模型或数据集的任何开源计划。仅提供了部分超参数范围,但未给出最终选定的精确值(如ζ),也未提供实现细节(如停止准则)。这严重影响了工作的可复现性和影响力。