📄 Group Relative Policy Optimization for Text-to-Speech with Large Language Models
#语音合成 #强化学习 #多语言 #零样本 #语音大模型
🔥 8.0/10 | 前25% | #语音合成 | #强化学习 | #多语言 #零样本
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 1.0 | 置信度 高
👥 作者与机构
- 第一作者:Chang Liu(中国科学技术大学,国家语音及语言信息处理工程技术研究中心)
- 通讯作者:Zhen-Hua Ling(中国科学技术大学,国家语音及语言信息处理工程技术研究中心)
- 作者列表:Chang Liu(中国科学技术大学),Ya-Jun Hu(科大讯飞研究院),Ying-Ying Gao(九天人工智能研究院),Shi-Lei Zhang(九天人工智能研究院),Zhen-Hua Ling(中国科学技术大学)
💡 毒舌点评
亮点在于巧妙地将源自数学推理的GRPO算法“移植”到语音合成领域,并用一个现成的ASR模型构建了简单有效的复合奖励,实现了训练复杂度的显著降低和性能的稳定提升。短板则在于对“自然度提升”的深层机理探讨不足,仅通过MOS分数和少量示例论证,缺乏更系统的声学或韵律学分析,且Llasa-1B上的主观评估结果不佳也未得到充分解释。
🔗 开源详情
- 代码:提供了GitHub仓库链接:https://ryuclc.github.io/LLM-TTS-GRPO。
- 模型权重:论文提及公开了微调后的模型权重(通过上述链接获取)。
- 数据集:使用了公开的Emilia(微调)、seed-tts-eval和Common Voice(评估)数据集。
- Demo:提供了在线音频演示(通过上述链接访问)。
- 复现材料:提供了训练代码、详细的超参数设置(如β, G, 学习率)和实验配置。
- 引用的开源项目:
- 基线TTS模型:CosyVoice2 [4], Llasa-1B [6]。
- ASR模型:Whisper-large-v3 [20]。
- 评估工具:Paraformer-zh (来自FunASR[22]) 用于中文CER,WavLM[23]用于说话人嵌入提取。
- 算法参考:GRPO [19] (源自DeepSeekMath)。
📌 核心摘要
- 问题:现有基于大语言模型(LLM)的文本到语音(TTS)模型在使用强化学习(RL)进行微调时,面临训练流程复杂(如PPO需要维护价值模型)、或依赖昂贵的偏好数据(如DPO)等问题。
- 方法核心:提出一种基于分组相对策略优化(GRPO)的微调方法。该方法利用一个现成的自动语音识别(ASR)模型,从生成的语音波形中计算字符错误率(CER)和负对数似然(NLL),并通过调和平均融合为一个复合奖励信号。该奖励用于计算组内相对优势,从而微调预训练的LLM-TTS模型。
- 创新点:首次将GRPO算法应用于LLM-based TTS的微调;设计了一种无需额外训练模型、结合客观可懂度(CER)与模型置信度(NLL)的复合奖励函数。
- 主要实验结果:在CosyVoice2和Llasa-1B两个开源基线模型上,GRPO微调显著提升了零样本合成的可懂度(CER/WER降低)和自然度(MOS提升)。例如,对CosyVoice2,中文CER从1.41降至1.07,英文WER从2.46降至2.30;主观平均意见得分(MOS)在四种语言上均有统计显著提升(如中文从4.42提升至4.58)。消融实验证明,结合CER与NLL的复合奖励优于单一奖励。
- 实际意义:该方法简化了LLM-TTS模型的RL训练管线,使其更稳定、易于实施,并有效提升了合成语音的质量和鲁棒性。
- 主要局限性:方法依赖于一个高质量的ASR模型作为奖励提供者;论文未深入分析NLL奖励如何具体改善语音自然度的机理;在Llasa-1B模型上,RL微调未能带来主观自然度的显著提升,原因未充分探究。
🏗️ 模型架构
本文的核心贡献是提出一种基于GRPO的微调流程,而非一个全新的TTS生成架构。其流程如图2所示,适用于两类主流的LLM-based TTS模型。
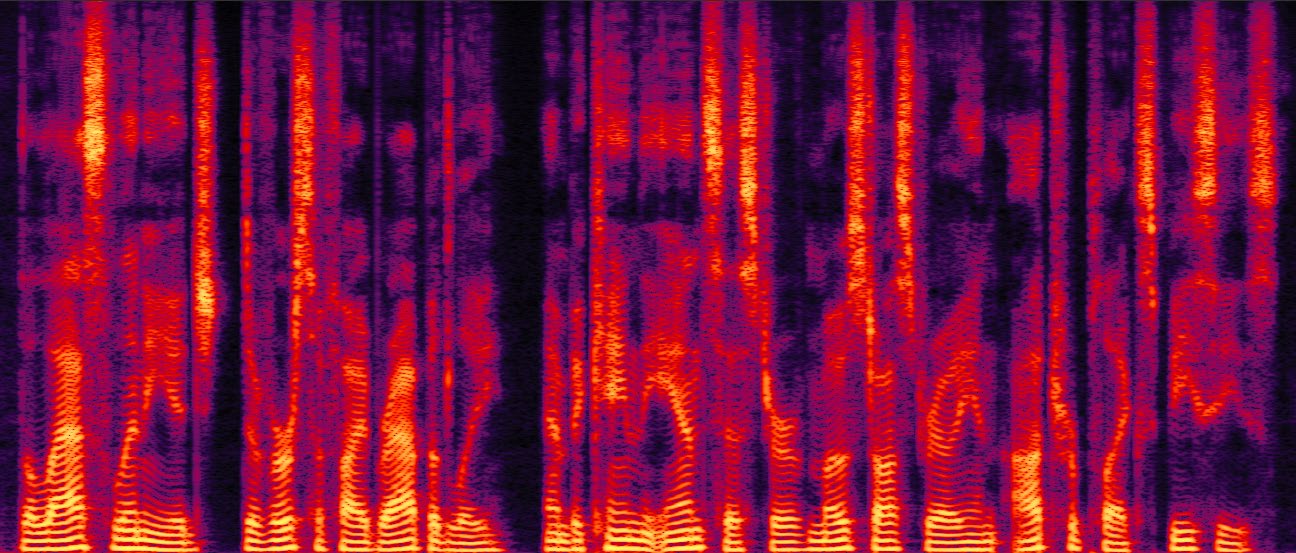 图2:GRPO微调流程。灰色模块表示冻结。预训练的语音Token LLM作为策略模型πθ,同时初始化参考模型πref(冻结)。对于输入文本y,策略模型进行G次采样得到一组输出语音token O。这些token经解码器(如Codec解码器或流匹配+声码器)转换为波形X。随后,使用一个现成的ASR模型(如Whisper)对X进行识别,并计算复合奖励R。根据奖励计算组内相对优势A,最后通过最大化GRPO目标函数(公式7)更新策略模型参数。
图2:GRPO微调流程。灰色模块表示冻结。预训练的语音Token LLM作为策略模型πθ,同时初始化参考模型πref(冻结)。对于输入文本y,策略模型进行G次采样得到一组输出语音token O。这些token经解码器(如Codec解码器或流匹配+声码器)转换为波形X。随后,使用一个现成的ASR模型(如Whisper)对X进行识别,并计算复合奖励R。根据奖励计算组内相对优势A,最后通过最大化GRPO目标函数(公式7)更新策略模型参数。
完整流程与组件交互:
- 输入:文本
y。 - 策略模型采样:预训练的LLM-TTS模型(策略模型
πθ)对文本y自回归采样G次(G=8),生成一组语音token序列O = {o1, o2, ..., oG}。 - 波形合成:每个token序列
oi被送入相应的语音编解码器或流匹配模型+声码器,转换为实际的语音波形xi。此处体现了对两类TTS模型(声学token模型 vs. 语义token模型)的兼容性。 - 奖励计算:将所有生成的语音波形
X = {x1, ..., xG}送入一个离线ASR模型(论文使用Whisper-large-v3)。ASR模型输出转录文本,并计算两个关键指标:- CER:生成语音转录文本与原始文本
y的字符错误率,衡量可懂度。 - NLL:ASR模型对原始文本
y的负对数似然,衡量ASR模型对生成语音的信心和对齐质量(如图1所示)。
- CER:生成语音转录文本与原始文本
- 复合奖励融合:通过公式(2)-(4)将CER和NLL映射并融合为一个标量奖励
Ri。公式(4)采用调和平均,对表现差的指标更敏感。 - 优势计算与策略更新:计算每个样本的优势
Ai(公式6,组内归一化),并通过最大化目标函数J_GRPO(公式7)更新策略模型πθ的参数。该目标包含策略优势项和KL散度惩罚项,后者防止模型偏离参考模型πref太远。
关键设计选择:
- 使用GRPO替代PPO:消除了价值模型,降低了内存和计算开销,简化了训练。
- 使用离线ASR模型计算奖励:避免了为TTS训练专门的奖励模型(如DiffRO中的token-to-text模型)。
- 复合奖励设计:CER提供明确的“对错”信号,NLL提供连续、细粒度的置信度信号,两者互补,如图3散点图所示,它们的相关性很弱(r=0.3371),结合使用信息更丰富。
💡 核心创新点
- 首次将GRPO应用于LLM-based TTS:将原本用于语言模型数学推理的GRPO算法成功迁移到语音生成领域,证明了其在TTS任务上的有效性和稳定性。
- 基于现成ASR的复合奖励函数设计:创新性地结合了CER(可懂度)和NLL(模型信心)作为奖励,无需额外训练奖励模型,且能提供更全面、稳定的优化信号。调和平均的应用是另一个细致的设计。
- 简化且通用的训练框架:所提方法可无缝应用于不同架构(声学token与语义token)的LLM-TTS模型,大幅降低了使用强化学习提升TTS模型性能的技术门槛和资源消耗。
- 实证验证了奖励组件的互补性:通过严格的消融实验(表1和表2),定量证明了CER-NLL复合奖励优于单一奖励,尤其是在自然度(MOS)提升上。
🔬 细节详述
- 训练数据:
- GRPO微调数据:从Emilia数据集中随机采样4000句,覆盖中、英、日、韩四种语言。其中,中英文约占90%。CosyVoice2使用全部4000句微调,Llasa-1B仅使用中英文子集微调。
- 评估数据:使用开源评测集seed-tts-eval(中文2020条,英文1088条)和Common Voice数据集(日语、韩语各1000条)。主观评测集每种语言约100个高表现力样本。
- 损失函数:核心是GRPO目标函数(公式7),包含两项:
- 策略优势项:
πθ(oi,t|y, oi,<t) / πθ_old(oi,t|y, oi,<t) * Ai,鼓励增大优势高的动作概率。 - KL散度惩罚项:
β * D_KL[πθ || πref],约束新策略不偏离初始参考模型太远。
- 策略优势项:
- 训练策略与关键超参数:
- 优化器/学习率:固定学习率
1 × 10⁻⁵。 - 每组采样数
G:8。 - KL惩罚系数
β:0.1。 - 奖励函数参数:
αc=3,αn=3,λc=0.6,λn=0.4。 - 训练步数/轮数:未说明。
- 优化器/学习率:固定学习率
- 训练硬件:未说明。
- 推理细节:评估时采用零样本合成。用于奖励计算的ASR模型是冻结的Whisper-large-v3。
- 正则化/稳定技巧:GRPO本身通过组内相对优势归一化和KL惩罚来稳定训练。奖励函数使用
tanh和exp进行归一化,将其映射到[0,1]范围。
📊 实验结果
实验在两类模型(CosyVoice2、Llasa-1B)���验证了方法的有效性。
表1:零样本TTS客观评估结果(内容一致性CER/WER↓,说话人相似度SIM↑)
| 模型 | 中文CER↓ | 中文SIM↑ | 英文WER↓ | 英文SIM↑ | 日文CER↓ | 日文SIM↑ | 韩文CER↓ | 韩文SIM↑ |
|---|---|---|---|---|---|---|---|---|
| Human | 1.33 | 0.755 | 2.10 | 0.734 | 8.53 | 0.708 | 7.43 | 0.716 |
| Llasa-1B | 7.73 | 0.636 | 4.95 | 0.578 | - | - | - | - |
| + GRPO-CER | 1.72 | 0.672 | 2.61 | 0.580 | - | - | - | - |
| + GRPO-NLL | 1.05 | 0.674 | 2.49 | 0.581 | - | - | - | - |
| + GRPO-CER-NLL | 1.30 | 0.669 | 2.17 | 0.580 | - | - | - | - |
| CosyVoice2 | 1.41 | 0.753 | 2.46 | 0.655 | 12.45 | 0.635 | 8.58 | 0.670 |
| + GRPO-CER | 1.34 | 0.751 | 2.43 | 0.655 | 10.05 | 0.645 | 6.37 | 0.677 |
| + GRPO-NLL | 0.98 | 0.753 | 2.36 | 0.659 | 9.36 | 0.662 | 6.59 | 0.682 |
| + GRPO-CER-NLL | 1.07 | 0.753 | 2.30 | 0.659 | 9.09 | 0.656 | 6.16 | 0.680 |
关键结论:GRPO微调普遍且显著降低了两种模型的CER/WER(提高可懂度),尤其是对原本错误率较高的Llasa-1B效果拔群。说话人相似度(SIM)保持稳定或略有提升。
表2:CosyVoice2主观MOS评估结果(自然度,1-5分,95%置信区间)
| 模型 | 中文 | 英文 | 日文 | 韩文 |
|---|---|---|---|---|
| CosyVoice2 | 4.42 ± 0.05 | 4.22 ± 0.06 | 4.10 ± 0.08 | 4.18 ± 0.08 |
| + GRPO-CER | 4.44 ± 0.06 | 4.26 ± 0.07 | 4.15 ± 0.08 | 4.23 ± 0.08 |
| + GRPO-NLL | 4.52 ± 0.05 | 4.31 ± 0.06 | 4.21 ± 0.08 | 4.24 ± 0.08 |
| + GRPO-CER-NLL | 4.58 ± 0.05 | 4.43 ± 0.06 | 4.29 ± 0.08 | 4.30 ± 0.08 |
关键结论:复合奖励(GRPO-CER-NLL)在所有语言上均取得了最高的自然度MOS分数,且与基线差异显著(p < 0.05)。NLL奖励(GRPO-NLL)对自然度的提升普遍优于仅使用CER奖励。
分析实验图表:
- 图3(散点图):显示RCER与RNLL的相关性很弱,证明了两者提供互补信息。
- 图4 & 图5(频谱图对比):
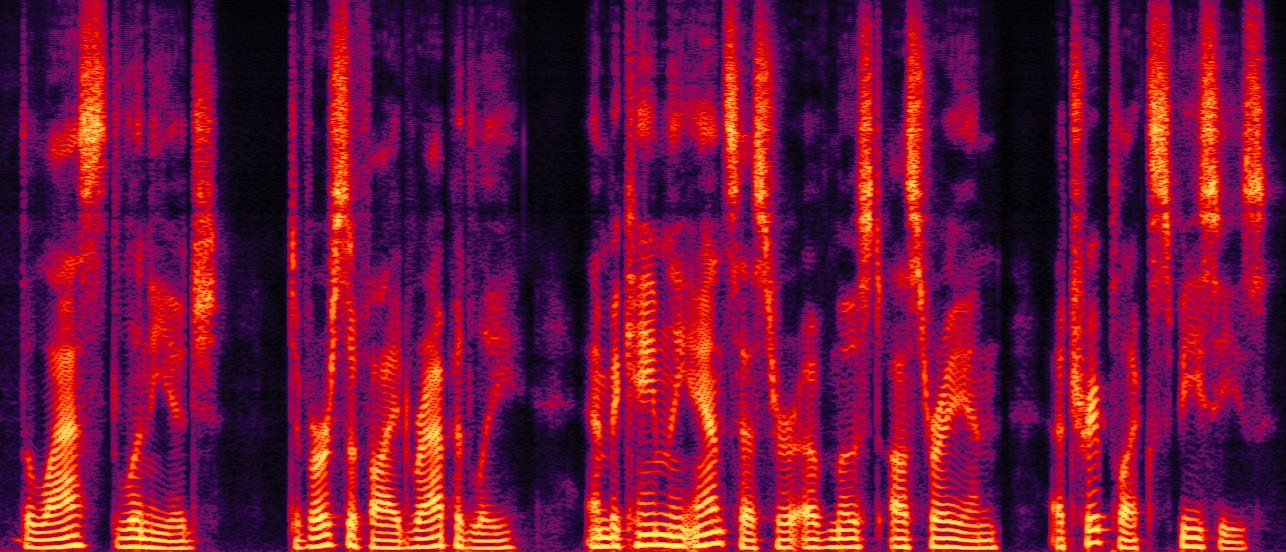 图4:中文示例频谱图。基线模型(a, b)存在漏字(“差距”)和发音错误(“于”),而GRPO-NLL(c)和GRPO-CER-NLL(d)修正了这些错误,且韵律停顿更自然。
图4:中文示例频谱图。基线模型(a, b)存在漏字(“差距”)和发音错误(“于”),而GRPO-NLL(c)和GRPO-CER-NLL(d)修正了这些错误,且韵律停顿更自然。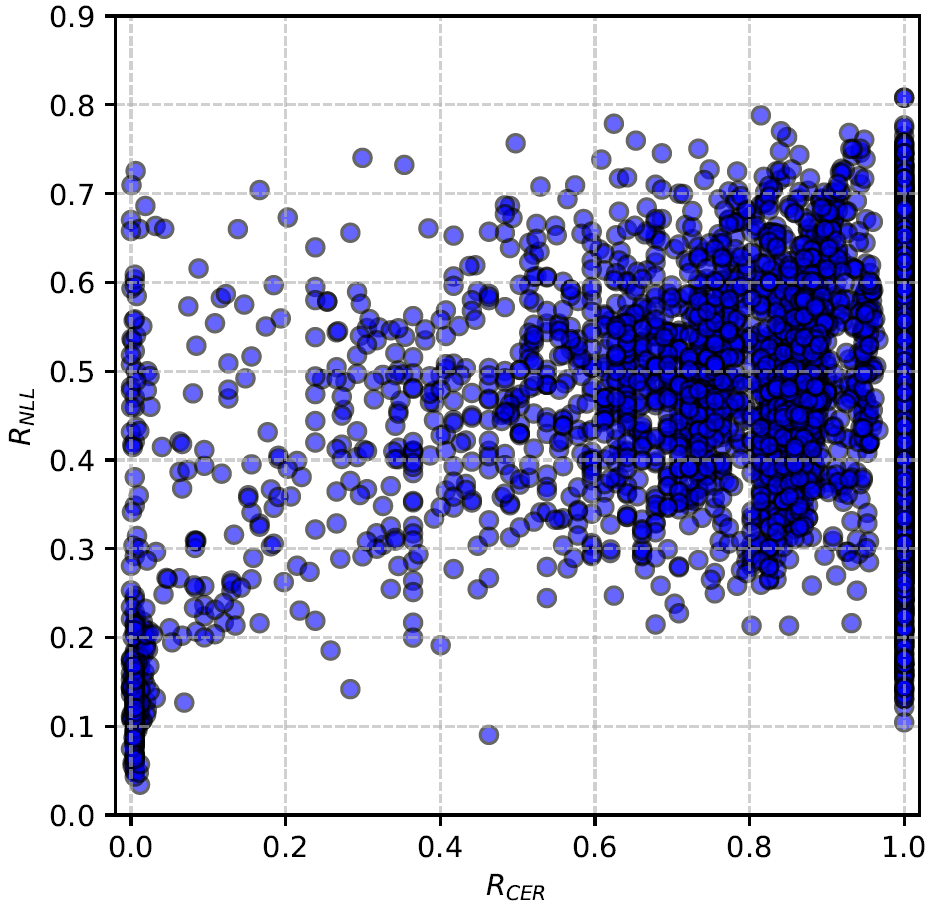 图5:英文示例频谱图。与图4类似,GRPO微调后的模型(c, d)修正了基线模型(a, b)的转录错误(如“at” vs “a”),生成了更准确的语音。
这些直观示例佐证了定量指标的改善。
图5:英文示例频谱图。与图4类似,GRPO微调后的模型(c, d)修正了基线模型(a, b)的转录错误(如“at” vs “a”),生成了更准确的语音。
这些直观示例佐证了定量指标的改善。
⚖️ 评分理由
- 学术质量:6.5/7。创新点清晰且具有实践价值(方法迁移与奖励设计);技术路线正确,实验设计全面,覆盖不同模型、语言、主客观指标及消融分析;结果可靠,有统计检验。扣分点在于对GRPO在TTS中生效的深层原理分析不足,以及Llasa-1B主观评估缺失原因未深究。
- 选题价值:1.5/2。研究处于LLM-TTS与强化学习交叉的热点领域,提出的简化方案对降低研究门槛、促进应用有直接意义,对语音合成社区有较高价值。
- 开源与复现加成:1.0/1。论文提供了代码、模型、演示和详细文档,复现门槛低,对社区贡献大。