📄 GRNet: Graph Reconstruction Network for Robust Multimodal Sentiment Analysis
#多模态情感分析 #图神经网络 #鲁棒性 #缺失模态学习 #多任务学习
✅ 7.5/10 | 前25% | #多模态情感分析 | #图神经网络 | #鲁棒性 #缺失模态学习
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Zhaopan Xu (哈尔滨工业大学)
- 通讯作者:Hongxun Yao (哈尔滨工业大学)
- 作者列表:Zhaopan Xu(哈尔滨工业大学)、Lulu Tian(未提供具体机构,邮箱为个人邮箱)、Panpan Zhang(新加坡国立大学 NUS)、Xiaojiang Peng(深圳技术大学)、Hongxun Yao(哈尔滨工业大学)
💡 毒舌点评
本文清晰地指出了现有多模态情感分析方法在“重建”缺失信息时忽略了数据内在的时序与跨模态对齐关系,并针对性地提出了两个基于图的模块(TGN/NGN),逻辑自洽且在实验中取得了全面的SOTA,证明其思路有效。不足之处在于,其“图重建”方法仍依赖于启发式设计的图结构(时序边、邻域窗口),这种强假设在更复杂、动态的真实场景下是否依然稳健有待验证,且模型整体框架虽优雅但并未带来根本性的范式变革。
📌 核心摘要
- 问题:现实世界中的多模态情感分析常面临模态数据不完整(如文本、音频、视觉信息缺失)的挑战,而现有方法在重建缺失特征时未能充分利用数据固有的时间关系和跨模态对齐关系。
- 方法核心:提出图重建网络(GRNet),利用两个基于关系图卷积网络(R-GCN)的模块进行重建:(1) 时间图神经网络(TGN) 将多模态序列拼接后建模时间依赖关系;(2) 邻居图神经网络(NGN) 将每个模态在每个时间步作为独立节点,建模固定窗口内的跨模态邻居对齐关系。同时,采用多路径分类策略,联合优化单模态分类器和最终分类器以增强鲁棒性。
- 新意:与先前独立重建各模态特征的方法不同,GRNet显式地利用图结构对多模态序列的时序上下文和跨模态同步关系进行联合建模与重建,从而获得更符合数据内在规律的恢复特征。
- 主要结果:在三个基准数据集(MOSI、MOSEI、SIMS)上,GRNet在二分类准确率(Acc-2)、F1分数、平均绝对误差(MAE)和相关性(Corr)等指标上全面超越了包括P-RMF、LNLN在内的最新方法。例如,在MOSI数据集上,GRNet的Acc-2为73.45%,F1为73.68%,MAE为1.026,均优于次优方法P-RMF的72.81%、72.93%、1.038。消融实验证明移除TGN或NGN均会导致性能下降。
- 实际意义:为处理现实世界中不可避免的数据缺失问题提供了一种更鲁棒的解决方案,增强了多模态情感分析系统在噪声和干扰下的可靠性,推动了MSA技术向实际应用落地。
- 主要局限性:邻居图神经网络(NGN)依赖于预设的固定窗口大小
w,这可能限制了其适应不同场景下动态跨模态对齐关系的能力;论文未探讨该方法在更极端或非随机缺失模式下的表现。
🏗️ 模型架构
模型(GRNet)的整体流程如图2所示,包含三个主要阶段:
特征提取与不完整数据模拟:
- 输入:视频片段。
- 流程:使用BERT提取文本特征
Ut,Librosa提取音频特征Ua,OpenFace提取视觉特征Uv。通过随机删除信息(文本用[UNK]替换,音视频特征零填充)模拟缺失数据,得到不完整特征U't,U'a,U'v。 - 统一维度:每个模态特征先通过线性层,再输入Transformer编码器,得到统一维度
d的表示Hm(完整)和H'm(不完整)。
图重建模块(Graph Reconstruction):这是核心部分,包含两个GNN。
- 时间图神经网络 (Temporal GNN, TGN):
- 目标:从融合的多模态时间序列中重建单模态特征。
- 节点:将同一时间步的三个模态特征拼接
H'c = Concat([H't, H'a, H'v])作为一个节点。节点数为T。 - 边:边被赋予时间类型标识符
α ∈ {past, present, future},表示节点间的相对时间位置关系,从而建模时间依赖。 - 操作:使用R-GCN聚合信息,为每个模态生成重建特征。例如,视觉模态重建特征
Hc'vt的计算如公式(4)所示。
- 邻居图神经网络 (Neighbor GNN, NGN):
- 目标:利用跨模态邻居关系重建缺失信息。
- 节点:将每个模态在每个时间步作为独立节点,构成节点集
H'n = [H't, H'a, H'v],节点总数为3T。 - 边:边被赋予模态类型标识符
β ∈ {(t→a), (t→v), (a→t), (a→v), (v→t), (v→a)},表示不同模态间的对齐关系。为了建模局部性,节点交互被限制在固定时间窗口w内。 - 操作:同样使用R-GCN进行特征聚合,得到重建特征
Hn'vt等,如公式(6)所示。
- 重建监督:两个GNN的重建特征均通过L2损失(公式(7))与原始完整特征
Hm进行对比优化。
- 时间图神经网络 (Temporal GNN, TGN):
多路径分类 (Multi-path Classification):
- 将TGN和NGN的重建特征拼接。
- 为每个模态(t, a, v)设置一个独立的单模态分类器,计算其分类损失
Lm_cls。 - 将所有单模态分类器的输出特征拼接后,输入一个最终分类器进行情感预测,计算最终损失
Lf_cls。 - 所有分类损失加权平均得到总分类损失
Lcls(公式(9))。
总体目标:最终损失函数
L = γ Lrec + (1-γ) Lcls,通过端到端训练联合优化重建任务和分类任务。
 图2展示了GRNet的三个核心部分:(a)特征提取与数据模拟;(b)基于TGN和NGN的图重建模块;(c)多路径分类策略。TGN和NGN通过不同的图结构建模时间和邻居关系,其重建特征共同用于最终的多路径分类。
图2展示了GRNet的三个核心部分:(a)特征提取与数据模拟;(b)基于TGN和NGN的图重建模块;(c)多路径分类策略。TGN和NGN通过不同的图结构建模时间和邻居关系,其重建特征共同用于最终的多路径分类。
💡 核心创新点
基于图神经网络的跨模态信息重建范式:
- 之前局限:先前方法(如TFR-Net)主要利用Transformer在独立模态内进行特征重建,或简单地拼接特征(如NIAT),忽略了多模态数据序列固有的时间相关性和跨模态同步性。
- 如何起作用:GRNet将多模态数据构建为图结构,其中TGN显式地建模时间序列上的依赖关系(如“过去”的文本如何影响“现在”的音频),NGN显式地建模同一时间点不同模态间的对齐关系(如文本与语音的对应)。
- 收益:实验表明,移除TGN或NGN(表2 #2, #3)性能显著下降,验证了这种结构化建模对于准确重建缺失信息的重要性。
TGN与NGN的双模块协同设计:
- 之前局限:单一重建机制难以同时捕捉全局时间趋势和局部跨模态精细对齐。
- 如何起作用:TGN关注“时间维度”,从融合的多模态序列中聚合信息;NGN关注“模态维度”,在固定窗口内聚合来自其他模态的邻居信息。两者从互补的角度进行重建。
- 收益:消融实验(表2 #4)显示同时移除两者性能下降最大,证明了双模块协同的有效性。图4(a-b)的t-SNE可视化直观展示了GRNet重建的特征比不使用该模块时更接近原始特征。
面向鲁棒性的多路径分类策略:
- 之前局限:单一融合分类器可能受主导模态或噪声的过度影响,在模态缺失时不稳定。
- 如何起作用:为每个模态训练独立的分类器,迫使模型学习模态特异性的情感特征,最后再融合决策。这种设计类似集成学习,提高了对单模态噪声和缺失的容忍度。
- 收益:消融实验(表2 #5)显示去掉多路径分类,所有指标均下降,证明其对鲁棒分类至关重要。
🔬 细节详述
- 训练数据:使用了三个公开的多模态情感分析基准数据集:MOSI、MOSEI、SIMS。论文未提供具体数据规模,但说明训练/验证/测试划分与LNLN一致。数据增强通过模拟不同缺失率(0%~100%)来实现。
- 损失函数:
- 重建损失
Lrec:L2损失,计算重建特征Hc'mt,Hn'mt与原始完整特征Hmt之间的均方误差(公式7)。 - 分类损失
Lcls:包含三个单模态分类损失La_cls,Lt_cls,Lv_cls和一个最终融合分类损失Lf_cls,均为预测标签与真实标签的L2损失(公式8),最终取四者的平均(公式9)。 总损失L:γ Lrec + (1-γ) * Lcls,平衡重建任务与分类任务。
- 重建损失
- 训练策略:
- 优化器:未在正文中明确说明,但实现细节部分提到超参数遵循LNLN,而LNLN使用AdamW。
- 学习率/调度:未在正文中明确说明。
- Batch size:未在正文中明确说明。
- 训练轮数/步数:未在正文中明确说明。
- 超参数:损失权重
γ默认0.4,NGN窗口大小w默认4(通过图4c, d分析确定)。Transformer编码器的细节未详细说明。
- 关键超参数:特征维度
d未明确给出。模型总参数量为120.6M(表3)。 - 训练硬件:NVIDIA Tesla A100 GPU (CUDA 11.7, PyTorch 1.13.1)。每个实验重复3次取平均。
- 推理细节:论文未详细说明推理时的具体策略(如缺失数据处理)。
- 正则化/稳定技巧:未明确提及。
📊 实验结果
主要对比实验结果(表1): 在MOSI、MOSEI、SIMS三个数据集上,GRNet与多种常规MSA方法和专门处理缺失模态的方法进行了对比,平均性能在缺失率0-90%上评估。GRNet在几乎所有指标上均取得了最优或次优结果。
| 方法 | MOSI | MOSEI | SIMS | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc-2↑ | F1↑ | MAE↓ | Corr↑ | Acc-2↑ | F1↑ | MAE↓ | Corr↑ | Acc-2↑ | F1↑ | MAE↓ | Corr↑ | |
| P-RMF | 72.81 | 72.93 | 1.038 | 0.525 | 78.14 | 79.33 | 0.658 | 0.589 | 73.64 | 74.65 | 0.500 | 0.414 |
| LNLN | 72.55 | 72.73 | 1.046 | 0.527 | 76.30 | 77.77 | 0.692 | 0.530 | 72.73 | 79.43 | 0.514 | 0.397 |
| GRNet | 73.45 | 73.68 | 1.026 | 0.526 | 78.61 | 77.86 | 0.640 | 0.565 | 74.67 | 76.51 | 0.488 | 0.425 |
消融实验结果(表2,在MOSI数据集上): 验证了TGN、NGN和多路径分类策略的有效性。
| # | 方法 | Acc-2↑ | F1↑ | MAE↓ | Corr↑ |
|---|---|---|---|---|---|
| 1 | GRNet | 73.45 | 73.68 | 1.026 | 0.526 |
| 2 | w/o TGN | 72.76 | 72.88 | 1.075 | 0.518 |
| 3 | w/o NGN | 72.97 | 73.38 | 1.043 | 0.520 |
| 4 | w/o TGN & NGN | 72.57 | 72.64 | 1.080 | 0.513 |
| 5 | w/o Multi-path Cls | 73.01 | 73.36 | 1.066 | 0.522 |
不同缺失率下的性能曲线(图3): 展示了GRNet与基线方法在MOSI数据集上随着缺失率增加,F1和MAE的变化。GRNet曲线始终位于更优位置(更高F1,更低MAE),证明其鲁棒性。
 图3显示,随着缺失率从0增加到0.9,GRNet(蓝线)的F1分数(a)始终保持最高,MAE(b)始终最低,表明其在不同噪声水平下均优于对比方法。
图3显示,随着缺失率从0增加到0.9,GRNet(蓝线)的F1分数(a)始终保持最高,MAE(b)始终最低,表明其在不同噪声水平下均优于对比方法。
重建特征可视化(图4a-b): 通过t-SNE可视化了在50%缺失率下,有无GRNet时重建特征与原始特征的分布。
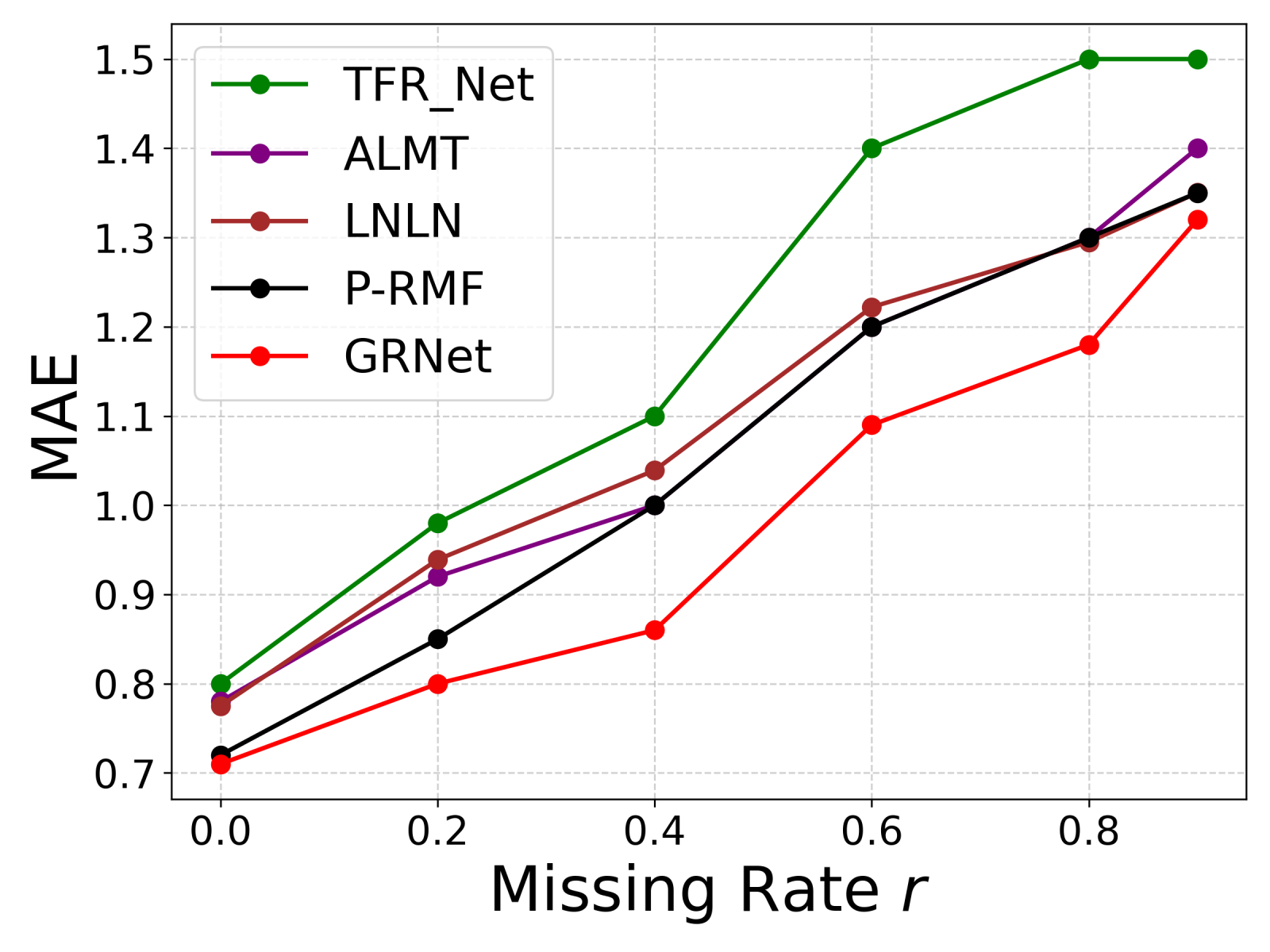 图4(a)显示,没有GRNet时,重建特征(蓝色)与原始特征(红色)分布差异较大;(b)显示,使用GRNet后,两者分布高度重叠,表明重建效果显著。
图4(a)显示,没有GRNet时,重建特征(蓝色)与原始特征(红色)分布差异较大;(b)显示,使用GRNet后,两者分布高度重叠,表明重建效果显著。
计算开销分析(表3):
| 模型 | 参数量 | 时间/Epoch |
|---|---|---|
| LNLN | 116.0 M | 21s |
| P-RMF | 117.3 M | 16s |
| GRNet | 120.6 M | 19s |
| GRNet的参数量和训练时间与现有方法相当,说明其效率可行。 |
⚖️ 评分理由
- 学术质量:6.5/7:创新性良好,提出了结合时序与跨模态邻居关系的GNN重建框架,逻辑清晰。技术实现基于成熟的R-GCN,正确性高。实验非常充分,包含全面的跨数据集对比、消融实验、参数分析和可视化,证据链完整,可信度高。主要扣分点在于其创新属于在特定框架(R-GCN)下的应用组合,而非提出新的核心算子或理论。
- 选题价值:1.5/2:研究多模态情感分析中的缺失模态鲁棒性问题,直接针对实际应用痛点,前沿且重���。音频和视觉模态的处理是本文重点,与语音/音频领域读者高度相关,应用空间明确。未给满分是因为该问题已是MSA领域的经典子问题,并非全新的前沿方向。
- 开源与复现加成:0.0/1:论文未提供代码、模型权重或数据集,尽管描述了部分实现细节,但完整的复现依赖作者的进一步开源,因此此项不加分。