📄 Graph-Biased EEG Transformers for Silent Speech Decoding
#语音生物标志物 #预训练 #图神经网络 #脑机接口 #小样本学习
✅ 6.5/10 | 前25% | #语音生物标志物 | #预训练 | #图神经网络 #脑机接口
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 -1.0 | 置信度 中
👥 作者与机构
- 第一作者:Saravanakumar Duraisamy(University of Luxembourg)
- 通讯作者:Luis A. Leiva(University of Luxembourg)
- 作者列表:Saravanakumar Duraisamy(University of Luxembourg), Eug´enie J. M. Delaunay(University of Luxembourg), Luis A. Leiva(University of Luxembourg)
💡 毒舌点评
亮点:论文精准地指出了当前EEG Transformer在静默语音解码任务上“水土不服”的关键原因——缺乏对EEG电极物理布局和频段特异性的先验建模,并提出了一个即插即用的图偏置模块(Graphormer++)来优雅地解决这个问题,思路清晰且有神经科学依据。短板:受试者内解码准确率仅从20%的瞎猜水平提升至约29%,绝对值仍较低;更致命的是,该方法完全无法解决跨受试者泛化的难题(仍为20%),且论文未开源代码,极大限制了其作为可复现基准的价值。
🔗 开源详情
论文中未提及任何开源计划,具体包括:
- 代码:论文中未提及代码链接。
- 模型权重:论文中未提及公开的模型权重。
- 数据集:论文使用了两个公开数据集(BCI Competition 2020 Dataset [19] 和 Overt/Covert Speech Dataset [20]),但未提供获取方式或统一数据加载代码。
- Demo:论文中未提及在线演示。
- 复现材料:论文提供了算法伪代码(Algorithm 1)、详细的超参数表(Table 1)和数据集描述,为复现提供了文本依据。
- 引用的开源项目:论文未明确列出依赖的开源工具或模型代码库,仅引用了作为对比的预训练模型名称(EEGPT, LaBraM, NeuroLM)。
📌 核心摘要
- 要解决什么问题:预训练的EEG Transformer(如EEGPT, LaBraM)在应用于静默语音解码任务时,即使经过微调,性能也接近随机猜测(~20%)。根本原因是模型分词方式无法保持电极身份和跨电极关系,导致表示不匹配。
- 方法核心是什么:提出Graphormer++,一个可插入任何预训练EEG Transformer编码器的模块。它首先将编码器的patch token按电极进行池化对齐,然后构建一个偏置张量,包含基于电极空间邻近度和四个频段(θ, α, β, γ)的相位锁定值(PLV)的先验知识。该偏置被用于调整Graphormer层中注意力头的得分,引导模型关注具有生理合理性的电极交互。
- 与已有方法相比新在哪里:不同于直接微调或简单添加分类头,该方法显式地将EEG的拓扑结构(空间)和功能连接(频段同步性)作为归纳偏置注入Transformer的注意力机制,实现了对预训练模型的结构化适配。
- 主要实验结果如何:在两个公开的静默语音数据集上,Graphormer++在受试者内设置下,将基于EEGPT骨干的平均分类准确率从微调后的约22%提升至约29.4%。在受试者间设置下,所有方法性能均停留在随机水平(~20%)。注意力图分析显示,该方法使模型更关注与语音相关的额叶、中央和颞区。关键实验结果表格如下:
表2. Graphormer++在不同骨干和设置下的准确率(%)
| 骨干模型 | 数据集1 (SS) | 数据集1 (SI) | 数据集2 (SS) | 数据集2 (SI) |
|---|---|---|---|---|
| EEGPT | 29.38 ± 2.67 | 20.1 ± 0.4 | 27.94 ± 3.84 | 20.0 ± 0.5 |
| NeuroLM | 25.63 ± 2.52 | 19.9 ± 0.5 | 26.17 ± 2.48 | 20.2 ± 0.4 |
| LaBraM | 24.22 ± 3.47 | 20.3 ± 0.4 | 23.38 ± 3.05 | 19.9 ± 0.5 |
表3. 仅微调Transformer编码器(无Graphormer++)的受试者内准确率(%)
| 骨干模型 | 数据集1 | 数据集2 |
|---|---|---|
| EEGPT | 22.14 ± 3.20 | 22.62 ± 2.76 |
| NeuroLM | 22.38 ± 2.55 | 21.93 ± 3.19 |
| LaBraM | 20.86 ± 2.43 | 19.56 ± 3.51 |
- 实际意义是什么:证明了为通用EEG基础模型注入领域特定的生理学先验,是提升其在特定下游任务(如静默语音解码)性能的有效途径,为构建更实用的静默语音脑机接口提供了方法学参考。
- 主要局限性是什么:a) 解码性能绝对值较低(~29%),距离实际应用有差距;b) 完全无法实现跨受试者泛化,这是BCI实用化的关键瓶颈;c) 实验仅在小词汇量(5类)数据集上进行;d) 论文未开源代码,可复现性存疑。
🏗️ 模型架构
Graphormer++的整体流程如下:
- 输入:一个EEG试验数据
X(64通道,2秒窗口)和一个预训练的EEG Transformer编码器E(如EEGPT)。 - 骨干编码器微调:首先在目标数据集上微调预训练编码器
E。 - 特征提取与电极对齐:冻结编码器
E,提取每个试验的patch tokenT = E(X)。关键步骤是将这些patch token根据其来源电极进行分组和平均,得到每个电极一个特征向量的张量H ∈ R^(C×D),其中C=64为电极数,D为特征维度。这步强制实现了不同蒙太导联之间的对齐。 - 计算先验张量:从原始EEG信号计算先验知识:
- 空间邻近度矩阵
P:基于电极在10-10系统中的三维坐标,计算归一化的欧氏距离倒数,反映电极间的物理距离远近。 - 频段相位锁定值矩阵
PLV:通过Hilbert变换提取瞬时相位,分别计算θ、α、β、γ四个频段内每对电极间的PLV,反映功能连接强度。这些矩阵在训练集上按受试者平均并归一化。 - 将上述5个矩阵(1个空间 + 4个频段)堆叠成先验张量
B ∈ R^(K×C×C), K=5。
- 空间邻近度矩阵
- Graphormer分类器:在电极特征
H前拼接一个可学习的[CLS]token。将H和B输入由L层组成的Graphormer。其核心是偏置注意力计算(公式3):对于第h个头,注意力得分不仅包含标准的Q·K/√d项,还加上一个由先验张量B线性组合而成的偏置项Σ wh,k * B(k)_ij。其中wh,k是每个头每个先验通道的可学习权重,α是全局缩放因子。 - 输出与分类:从最后一层Graphormer的输出中取出
[CLS]token的表示,通过一个分类头预测静默语音的单词类别(5类)。
 (注:根据论文描述,此图应为Graphormer++的流程图或架构图,展示了从EEG输入到电极池化、先验计算、Graphormer层和最终分类的完整数据流。)
(注:根据论文描述,此图应为Graphormer++的流程图或架构图,展示了从EEG输入到电极池化、先验计算、Graphormer层和最终分类的完整数据流。)
💡 核心创新点
- 即插即用的图偏置模块(Graphormer++):创新性地将图神经网络中编码结构先验的思路,转化为一个可附加到任意预训练EEG Transformer编码器后的轻量级模块。这解决了不同预训练模型内部表示不统一、无法直接整合空间先验的问题。
- 电极级token对齐:通过将patch token池化为电极级token,强制模型在不同蒙太导联和采样率的输入之间建立统一的、具有电极身份意义的表示基础,为注入空间先验铺平了道路。
- 多通道生理学偏置张量:将空间邻近度(结构连接)和多频段相位锁定值(功能连接)整合到一个偏置张量中,让注意力头可以自适应地学习如何结合不同的生理学先验来引导关注。这比单一的邻接矩阵或简单的距离衰减更丰富。
- 分阶段优化与稳定性正则化:训练时先固定骨干只训练分类头,再整体微调,提升了训练稳定性。同时引入了一个正则化项
R(公式4),惩罚注意力分布过于均匀的情况,鼓励模型在存在先验偏置时形成明确的关注模式。
🔬 细节详述
- 训练数据:
- 数据集1:BCI Competition 2020 Dataset。15名受试者,5个想象单词(hello, help me, stop, thank you, yes),每类80次重复,共400试验/人。64通道,500Hz,10-10导联。
- 数据集2:Overt/Covert Speech Dataset。15名受试者,5个命令词(LEFT, RIGHT, UP, PICK, PUSH),仅使用隐蔽(想象)语音阶段,每类80次,共400试验/人。64通道,500Hz,10-10导联。
- 预处理:50Hz陷波滤波 -> 0.5-80Hz线性相位FIR带通滤波 -> ICA去除眼电、肌电伪迹 -> 截取2秒想象语音片段 -> 用刺激前100ms基线校正。
损失函数:加权交叉熵损失,结合稳定性正则化项
R = λ (1/H) Σ_h |(1/C^2) Σ_ij A(h)_ij|,其中λ = 10^-3,A(h)_ij是注意力权重。类别权重采用频率倒数归一化。
- 训练策略:
- 优化器:AdamW,学习率
1×10^-4,权重衰减1×10^-2。 - 调度:ReduceLROnPlateplate(耐心值=5)。
- 梯度裁剪:最大范数1.0。
- 批大小:16。
- 分阶段训练:先训练Graphormer分类器头几个epoch,然后解冻所有Graphormer层一起训练。
- 优化器:AdamW,学习率
- 关键超参数(见表1):
- Graphormer层数
L=6,注意力头数H=8,维度D≈256。 - Dropout率
0.2。 - 偏置通道
K=5(1空间 + 4频段PLV)。 - 正则化系数
λ=1×10^-3。
- Graphormer层数
- 训练硬件:论文中未提及具体的GPU型号、数量及训练时长。
- 推理细节:未提及特殊推理策略,应为标准的前向传播和argmax分类。
- 正则化技巧:除Dropout和权重衰减外,主要依靠上述的稳定性正则化项
R和分阶段训练策略来防止注意力塌缩或训练不稳定。
📊 实验结果
论文主要评估了在5个类别上进行单词级分类的准确率。
- 主要结果:见上文核心摘要中的表2和表3。关键结论是:a) Graphormer++在受试者内(SS)设置下显著提升了所有骨干模型的性能,其中EEGPT骨干表现最好(数据集1: 29.38%,数据集2: 27.94%)。b) 所有方法在受试者间(SI)设置下性能均与随机猜测(20%)无异。c) 与仅微调编码器的基线(表3)相比,Graphormer++带来了约5-8%的绝对提升。
- 消融/对比分析:
- 基线对比:除了与自身骨干的微调版本对比,论文还提到传统EEG模型(EEGNet, CNN-BiLSTM, ST-GCN)的准确率仅在20-22%之间,Graphormer++显著优于这些传统方法(Wilcoxon检验 p<0.05)。
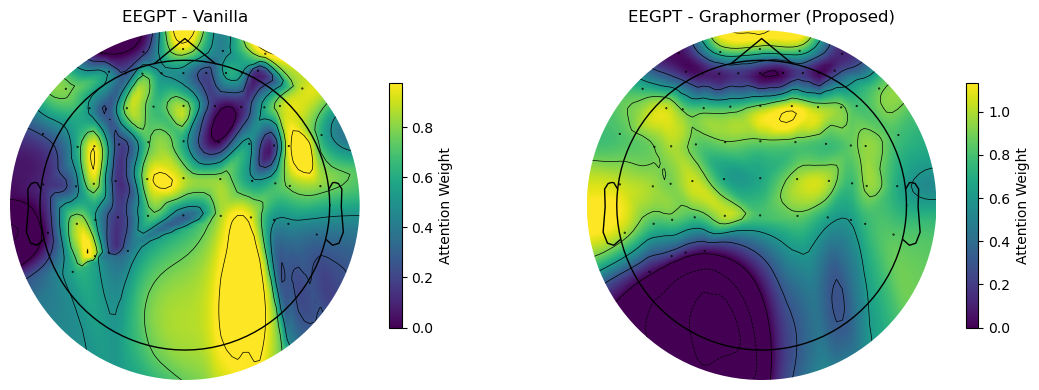
- 注意力图分析:论文展示了图1,对比了微调后的EEGPT( vanilla)和附加Graphormer++后的EEGPT的通道级注意力图。结果显示,vanilla注意力分布弥散,而Graphormer++的注意力集中在额叶、中央和颞区(与语音运动规划和隐性发音相关的脑区),枕叶活动较低,这与任务的神经生理学预期一致,提供了可解释性证据。
- 局限性分析:论文坦诚讨论了受试者间泛化失败的可能原因(个体间EEG的显著差异),并指出当前词汇量和试次数较小,是未来工作的方向。
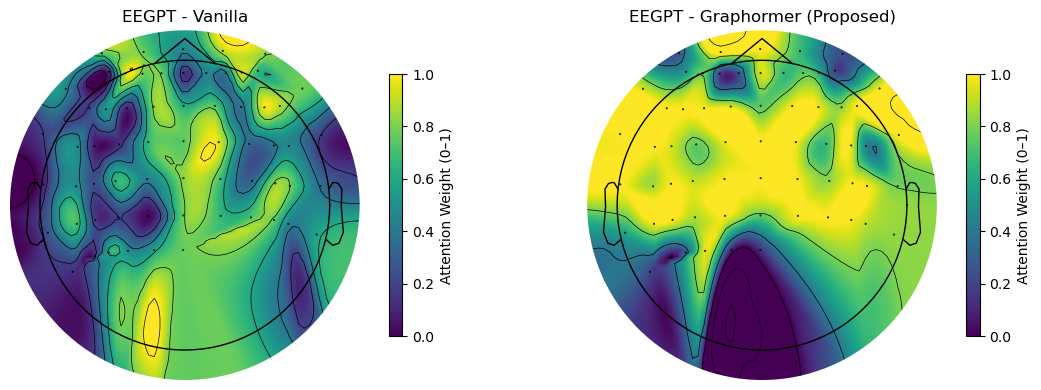 (注:根据论文描述,此图应为图1,展示了两个不同数据集受试者上的通道级注意力地形图对比,左侧为vanilla EEGPT,右侧为Graphormer++,清晰地显示了注意力分布从弥散到集中的变化,且集中区域符合语音相关脑区定位。)
(注:根据论文描述,此图应为图1,展示了两个不同数据集受试者上的通道级注意力地形图对比,左侧为vanilla EEGPT,右侧为Graphormer++,清晰地显示了注意力分布从弥散到集中的变化,且集中区域符合语音相关脑区定位。)
⚖️ 评分理由
- 学术质量:6.0/7:创新性良好,将图先验注入EEG Transformer是合理且新颖的思路。技术实现细节丰富,实验设计较为全面,包含了不同骨干、不同设置和可解释性分析。然而,性能提升的绝对值有限,且完全无法解���跨受试者泛化这一核心难题,这限制了其学术影响力。
- 选题价值:1.5/2:选题聚焦于前沿且极具挑战性的静默语音解码任务,针对通用EEG基础模型的适应性问题提出解决方案,具有重要的探索价值。但由于任务本身的专属性极强,与更广泛的语音处理社区关联度不高。
- 开源与复现加成:-1.0/1:论文提供了非常详尽的算法描述、超参数表格和数据集信息,在文本层面可复现性较高。然而,完全未提供代码、模型或训练脚本的链接,这在当今的机器学习研究中是一个明显的短板,严重降低了工作的可验证性和影响力,因此给予扣分。