📄 Graph-based Modality Alignment for Robustness in Conversational Emotion Recognition
#多模态模型 #语音情感识别 #对比学习 #鲁棒性
🔥 8.0/10 | 前25% | #语音情感识别 | #多模态模型 | #对比学习 #鲁棒性
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.3 | 置信度 高
👥 作者与机构
- 第一作者:Dae Hyeon Kim(光云大学电子通信工程系)
- 通讯作者:Young-Seok Choi*(光云大学电子通信工程系)
- 作者列表:Dae Hyeon Kim(光云大学电子通信工程系), Young-Seok Choi(光云大学电子通信工程系)
💡 毒舌点评
亮点:该论文最大的贡献在于将对话上下文、说话者关系和多模态信息统一建模在一个异构图中,并通过一种无增强的跨模态图对比学习,显式地将不同模态的嵌入对齐到共享的情感空间,这在理论上优雅地解决了传统堆叠模型的信息瓶颈和模态崩溃问题。短板:论文的实验部分虽然全面,但其鲁棒性验证主要局限于单一模态缺失的极端情况,对于现实场景中更常见的模态质量退化(如音频噪声、视频模糊)或部分缺失的鲁棒性探讨不足。此外,代码未开源,这对于一篇依赖复杂图结构和对齐目标的工作而言,无疑是可复现性上的一个显著扣分项。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开预训练模型或检查点。
- 数据集:使用的IEMOCAP和MELD是公开的标准学术数据集。
- Demo:未提及在线演示。
- 复现材料:论文中提供了非常详细的超参数设置、优化器配置、训练硬件和轮数等关键信息。
- 论文中引用的开源项目:openSMILE [13](音频特征提取)、Sentence-BERT [14](文本特征提取)、DenseNet [15](视觉特征提取)、AdamW优化器 [23]。
📌 核心摘要
- 解决的问题:多模态会话情感识别(MERC)中,传统堆叠式模型容易产生信息瓶颈和冲突的归纳偏见,且缺乏显式的模态对齐,导致模型在推理时遇到某些模态缺失(即“缺失模态问题”)时鲁棒性差。
- 方法核心:提出了一个名为EmotionHeart的统一框架。其核心是一个异构图Transformer,它将对话(作为节点集合)和其中的关系(说话者内、说话者间、模态间)构建为一个单一的图进行联合建模。同时,引入了一种无增强的跨模态图对比学习(GCL) 训练目标,强制对齐不同模态(音频、文本、视觉)的嵌入表示。
- 创新之处:1)与以往“序列+图”的堆叠架构不同,采用统一的异构图结构同时编码所有信息源,避免了信息瓶颈。2)提出了跨模态图对比学习,直接对齐单个模态的特征,而非早期融合后的特征,从而更好地解决模态崩溃和缺失模态问题。
- 主要实验结果:在IEMOCAP和MELD两个基准数据集上达到了新的SOTA。具体而言,在IEMOCAP上加权F1(w.F1)达到73.1%,在MELD上达到69.0%,均显著优于之前的最佳模型(p<0.001)。消融实验证明了异构性和跨模态GCL组件的有效性。关键实验数据如下:
| 方法 | 年份 | 架构 | IEMOCAP (w.F1 %) | MELD (w.F1 %) |
|---|---|---|---|---|
| BIG-FUSION | 2025 | 混合 | 72.9 | 67.2 |
| EmotionHeart | – | 统一 | 73.1 | 69.0 |
表2(消融实验)显示,从标准Transformer(68.99%)到完整模型(73.13%),每一步添加核心组件都带来了性能提升和稳定性改善(标准差从4.73降至1.09)。
- 实际意义:该工作为构建更健壮、可靠的多模态情感AI系统提供了有效方案,尤其是在模态信息可能不完整的实际应用场景中(如网络通话中视频卡顿、音频中断)。
- 主要局限性:1) 代码未开源,限制了社区的快速验证与应用。2) 模型的复杂度和训练开销可能较高(需在3块RTX 3090上训练)。3) 鲁棒性分析主要针对单一模态完全缺失的情况,对于多模态质量不均或部分缺失的复杂场景模拟不足。
🏗️ 模型架构
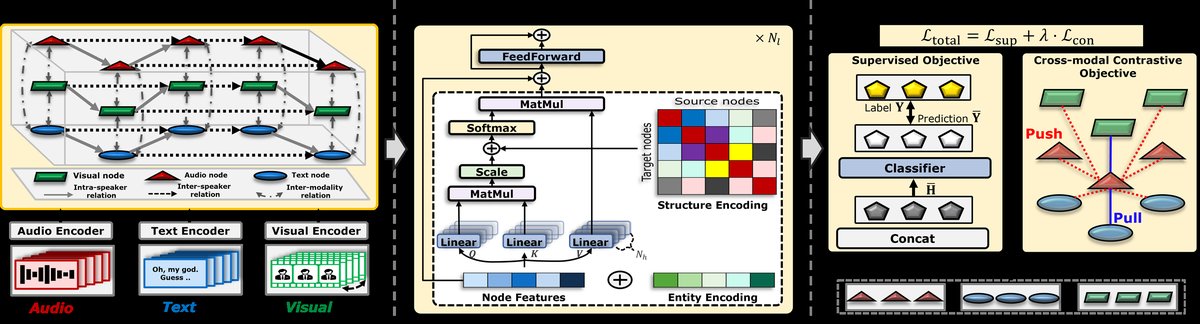 整体架构:EmotionHeart是一个端到端框架,输入为一段对话,输出为每个话轮的情感预测。其流程可分为三个阶段:
整体架构:EmotionHeart是一个端到端框架,输入为一段对话,输出为每个话轮的情感预测。其流程可分为三个阶段:
- 图构建与特征初始化:将一段对话建模为一个异构图 G=(V, E, R)。节点集合V包含所有话轮(Nu个)的三种模态:音频(Va)、文本(Vt)和视觉(Vv),因此总节点数 Nv = 3 × Nu。边集合E包含三种关系类型(R):同说话者内(rintra)、跨说话者间(rinter)、跨模态间(rmodal)。每个节点的初始特征由预训练模型提取:音频用openSMILE,文本用Sentence-BERT,视觉用DenseNet。
- 异构图Transformer编码:这是模型的核心,负责在单一图结构上联合学习所有信息。
- Transformer骨干网络:将初始化特征X视为序列,通过标准Transformer层(包含多头自注意力)进行初步编码,产生模态无关的节点嵌入H。
- 实体编码(Entity Encoding):为每个节点注入四种位置/属性编码:位置编码(zpos, 话轮顺序)、说话者编码(zspk, 标识说话人)、模态编码(zmod, 区分音频/文本/视觉)、度数编码(zdeg, 节点中心性)。这些编码通过可学习的查找表获取,并与初始特征相加,得到富化的输入X’,替代原始X送入Transformer。
- 结构编码(Structure Encoding):在Transformer的注意力计算中注入图的结构先验。1)空间编码:基于节点间最短路径长度(限制在Nt跳内)添加一个可学习的标量偏置bϕ,捕捉节点间的结构邻近性。2)属性编码:沿着最短路径,聚合各边的关系类型嵌入,计算得到一个向量偏置ci,j,捕捉路径上的关系语义。最终的注意力分数A’由原始注意力分数A加上这两个偏置得到。
- 跨模态对齐与分类:图Transformer输出最终的节点嵌入H。这些嵌入被重新划分回三个模态专属的表示(Ha, Hv, Ht)。1)对比学习目标(Lcon):对每一对模态(如音频-文本),将同一话轮的表示作为正样本对,其他话轮的表示作为负样本,通过InfoNCE损失进行对比学习,强制它们对齐到共享空间。2)监督目标(Lsup):将三个模态的表示拼接后,送入一个两层的线性分类器,与真实标签计算交叉熵损失。总损失为两者的加权和:Ltotal = Lsup + λLcon。
关键设计选择及动机:
- 统一异构图 vs. 堆叠网络:动机是避免多阶段流水线中信息丢失和不同网络归纳偏见冲突。
- 显式的实体与结构编码:动机是让纯Transformer架构能感知图特有的异构性和拓扑结构,增强其对会话动态的建模能力。
- 跨模态图对比学习:动机是解决早期融合对比学习无法对齐单模态表示的问题,从而直接增强每个模态表示的鲁棒性和语义一致性。
💡 核心创新点
- 统一的异构图Transformer框架:首次在MERC中将对话上下文、说话者关系和多模态信息共同建模在一个异构图中,并使用单一的Transformer进行端到端处理,打破了传统“序列-图”或“模态-融合”的堆叠范式。 局限*:传统方法如堆叠RNN和GNN,信息需经过多级传递和转换,易失真且优化困难。 如何起作用*:通过将话轮及其多模态表现和各种关系定义为图节点和边,并利用Transformer强大的序列建模能力和精心设计的图编码,一次性学习所有交互。 收益*:消除了信息瓶颈,在表1和表2中表现为更高的性能和更低的训练方差。
- 无增强的跨模态图对比学习(GCL):提出了一种直接针对单模态表示的对比学习目标,通过最大化不同模态同一话轮表示间的互信息,实现显式对齐。 局限*:已有GCL(如用于早期融合表示的GRACE)无法在推理时处理模态缺失,因为融合后的表示已被污染。 如何起作用*:公式(4-6)定义了InfoNCE损失,迫使不同模态的嵌入在共享情感空间中靠近,同时远离其他话轮的嵌入。 收益*:产生了模态一致且具判别性的嵌入(图2(c)),显著提升了模型对缺失模态的鲁棒性(表3)。
- 对缺失模态问题的有效鲁棒性:通过上述架构和训练目标的结合,模型能够学习到模态间互补的语义,使得即使某些模态在测试时缺失,剩余模态的表示依然有效。 局限*:现有方法在单模态训练下尚可,但全模态训练后单模态推理时性能下降严重(表3)。 如何起作用*:跨模态GCL保证了每个模态都编码了共享的情感语义,因此单独使用任一模态都能进行合理预测。 收益*:在表3中,当从全模态(ATV)训练切换到单模态(如T)测试时,EmotionHeart的性能不降反升(例如MELD上从67.40%升至68.99%),表现出极强的韧性。
🔬 细节详述
- 训练数据:
- 数据集:IEMOCAP(双人对话,7433句话轮,6类情感)和MELD(多人对话,13708句话轮,7类情感,排除了Fear和Disgust类)。
- 预处理:使用预训练模型(openSMILE, Sentence-BERT, DenseNet)提取特征。
- 数据增强:论文中未提及使用任何数据增强方法,对比学习部分也特别说明是“augmentation-free”。
- 损失函数:
- 监督损失(Lsup):标准的交叉熵损失,用于话轮级情感分类。
- 对比损失(Lcon):公式(4)所示的InfoNCE损失,温度参数τ。总损失为两者加权:Ltotal = Lsup + λLcon,其中λ是正则化系数。
- 训练策略:
- 优化器:AdamW。
- 学习率调度:论文未明确提及使用学习率预热(warmup)或衰减策略,仅给出了初始学习率。
- 批大小:IEMOCAP为12, MELD为64。
- 训练轮数:IEMOCAP为50轮, MELD为150轮。
- 训练步数:未明确给出总步数。
- 关键超参数(以IEMOCAP为例):
- 模型隐藏维度 dmodel = 384。
- Transformer头数 Nh = 6,层数 Nl = 2(MELD为4)。
- 结构编码中最短路径阈值 Nt = L = 51。
- 对比损失温度 τ = 0.7。
- 损失权重 λ = 0.3。
- 权重衰减 WD = 1e-5。
- 训练硬件:3块NVIDIA RTX 3090 GPU。
- 推理细节:论文未提及特殊的解码策略或流式设置,属于标准的前向传播分类任务。
- 正则化技巧:使用了权重衰减(Weight Decay),并在对比学习中引入了温度参数τ以控制分布的尖锐度。
📊 实验结果
主要Benchmark性能: 表1展示了EmotionHeart与多种先进方法在IEMOCAP和MELD数据集上的性能对比。
| 方法 | 年份 | 架构 | IEMOCAP (w.F1 %) | MELD (w.F1 %) |
|---|---|---|---|---|
| MVN | 2022 | 序列 | 65.4 | 59.0 |
| DIMMN | 2023 | 序列 | 64.1 | 58.6 |
| MKE-IGN | 2024 | 图 | 71.9 | 66.6 |
| AdaIGN | 2024 | 图 | 70.7 | 66.8 |
| DGODE | 2025 | 混合 | 72.8 | 67.2 |
| DER-GCN | 2025 | 混合 | 69.4 | 66.1 |
| BIG-FUSION | 2025 | 混合 | 72.9 | 67.2 |
| EmotionHeart | – | 统一 | 73.1 | 69.0 |
注:星号表示与次优结果相比p<0.001。 结论:EmotionHeart在两个数据集上均取得了最优的加权F1分数,尤其在MELD上优势明显(+1.8%),并在多个单项情感类别上取得了最佳或接近最佳的F1值。
消融实验: 表2分析了关键组件对性能和稳定性的影响。
| 模型配置 | IEMOCAP (w.F1 ± STD %) | MELD (w.F1 ± STD %) |
|---|---|---|
| Transformer | 68.99 ± 4.73 | 66.75 ± 4.63 |
| + 异构性 | 72.01 ± 2.08 | 67.89 ± 3.11 |
| + 跨模态GCL | 71.71 ± 1.92 | 67.35 ± 2.93 |
| 两者结合(完整模型) | 73.13 ± 1.09 | 68.99 ± 2.42 |
结论:单独加入异构性编码或跨模态GCL都能提升性能并降低标准差。两者结合后,性能和稳定性达到最佳,证明了二者的协同效应。
模态对齐可视化:
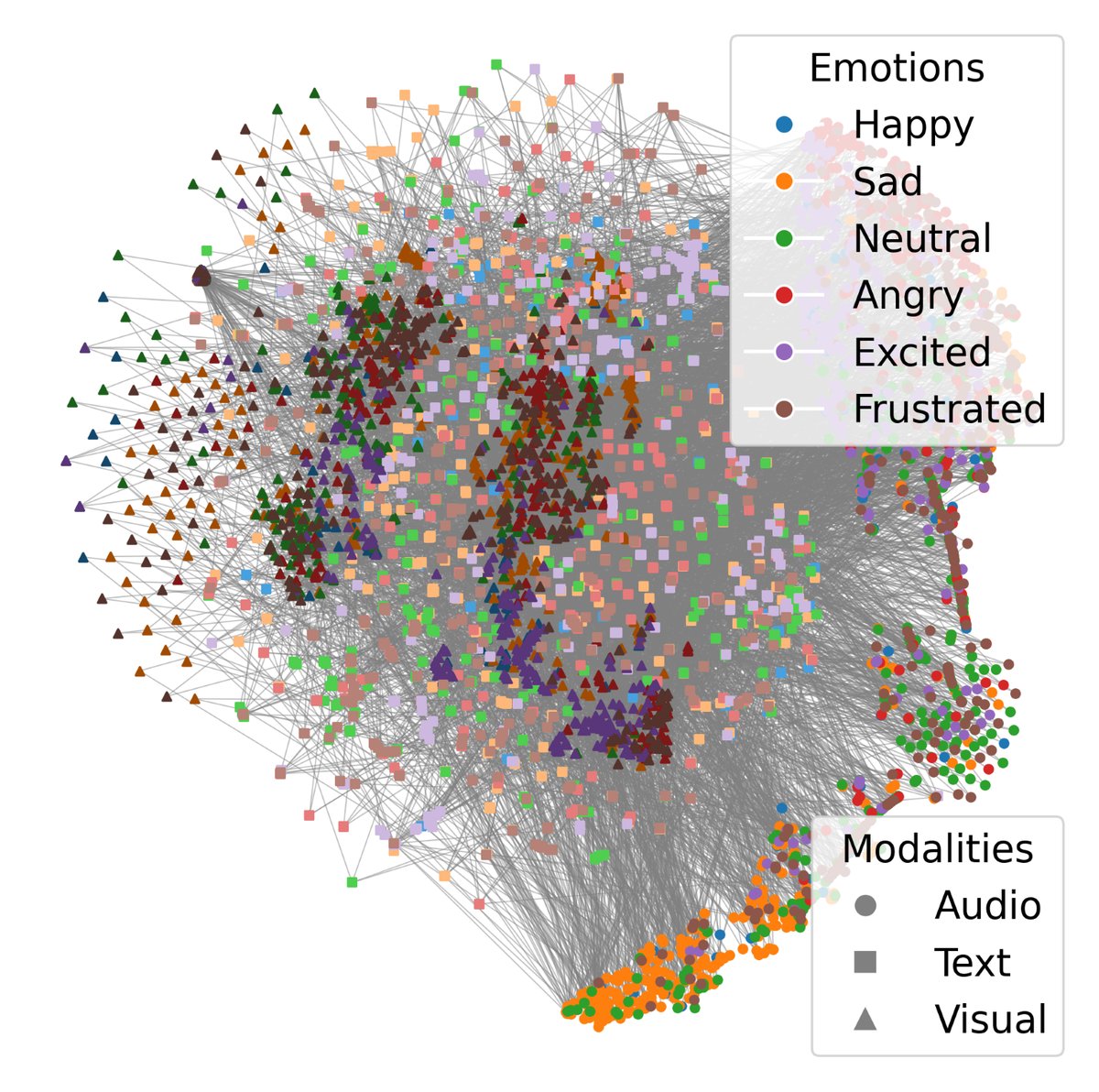 (a) 初始嵌入空间,各类情感和模态混杂。
(a) 初始嵌入空间,各类情感和模态混杂。
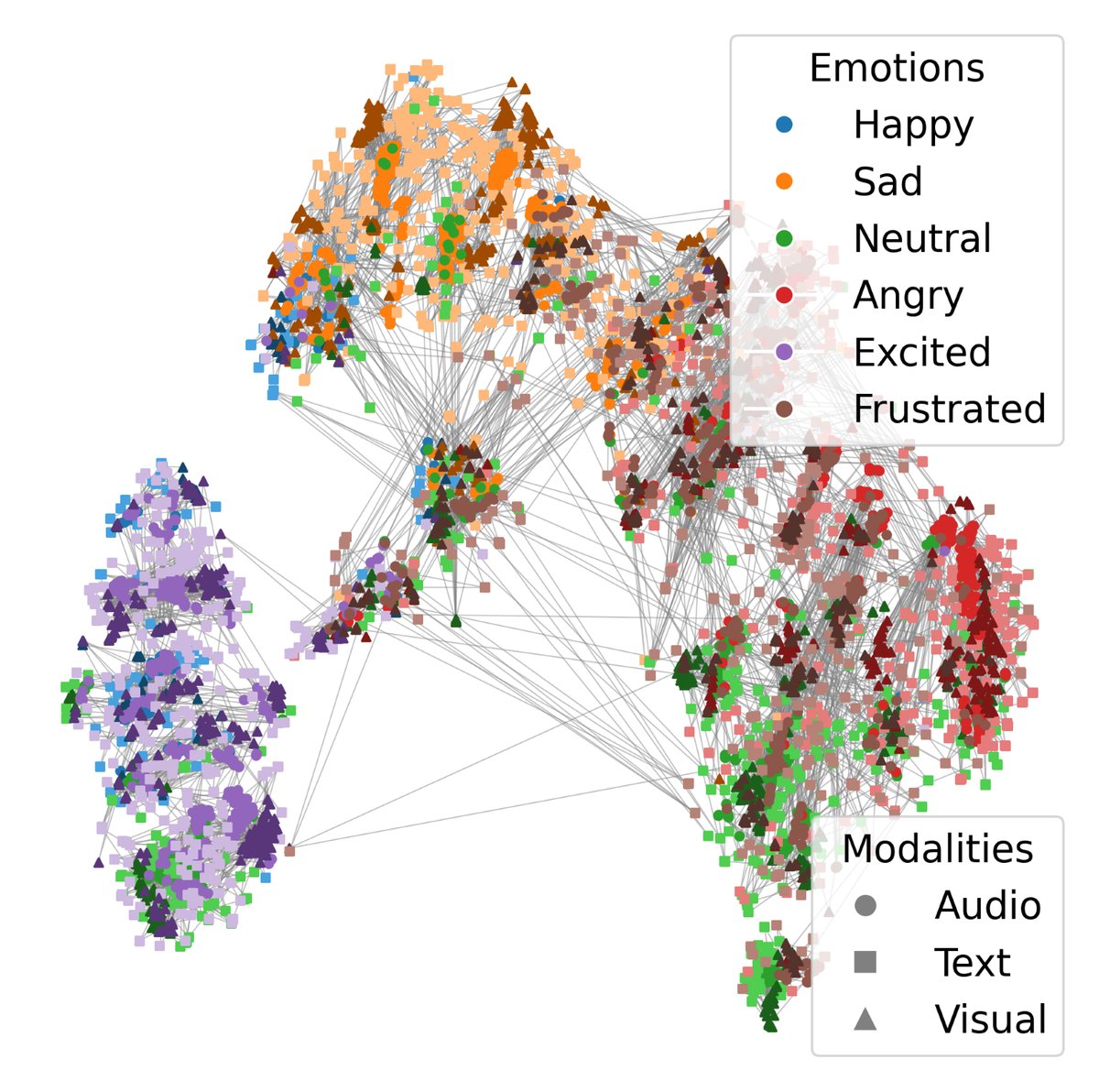 (b) 无跨模态GCL的嵌入空间,情感类分离较好,但同一话轮的不同模态表示(用线连接)较为分散。
(b) 无跨模态GCL的嵌入空间,情感类分离较好,但同一话轮的不同模态表示(用线连接)较为分散。
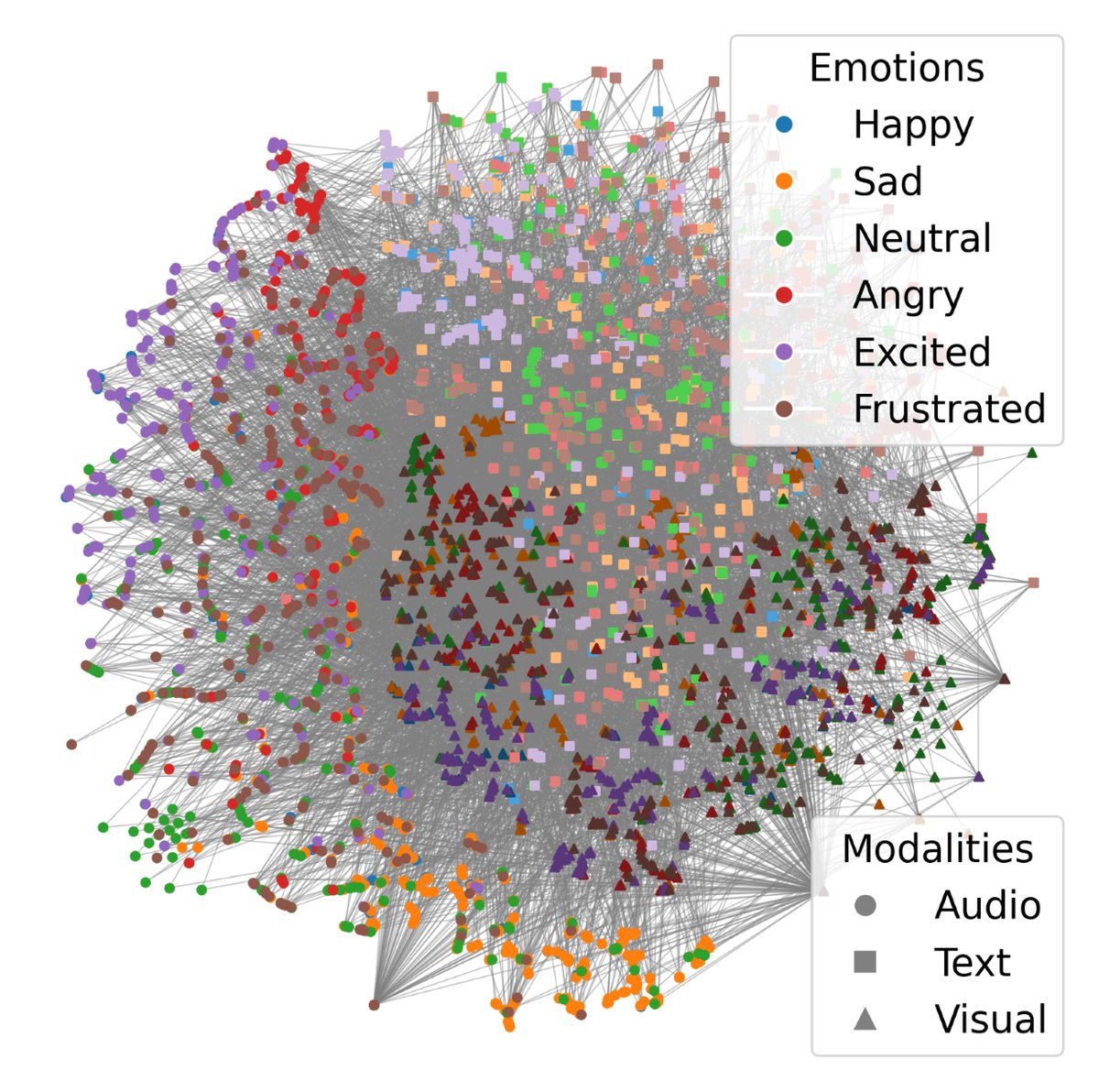 (c) EmotionHeart(完整模型)的嵌入空间,同一话轮的模态表示紧密聚集,同时不同类簇分离良好。
结论:可视化直观地证实了跨模态GCL确实能实现紧密的模态对齐,形成“模态一致且判别性强”的表示。
(c) EmotionHeart(完整模型)的嵌入空间,同一话轮的模态表示紧密聚集,同时不同类簇分离良好。
结论:可视化直观地证实了跨模态GCL确实能实现紧密的模态对齐,形成“模态一致且判别性强”的表示。
缺失模态鲁棒性分析: 表3比较了EmotionHeart与基线(GRACE,一种基于增强的早期融合GCL方法)在单模态训练和“全模态训练-单模态测试”场景下的表现。
| 模态 | IEMOCAP (w.F1 %) | MELD (w.F1 %) |
|---|---|---|
| 模式 | GRACE | EmotionHeart |
| A (仅音频) | 59.13 | 57.70 |
| A/ATV | 54.09 (↓5.04) | 60.26 (↑2.56) |
| T (仅文本) | 66.37 | 63.75 |
| T/ATV | 62.98 (↓3.39) | 66.55 (↑2.80) |
| V (仅视觉) | 56.30 | 53.28 |
| V/ATV | 52.68 (↓3.62) | 55.17 (↑1.89) |
注:“X/ATV”表示用全部模态训练,仅用X模态测试。括号内箭头表示与单模态训练相比的性能变化。 结论:GRACE在从全模态切换到单模态测试时性能大幅下降,表明其模态对齐不足。EmotionHeart则在此场景下性能不降反升(在所有情况下),证明其跨模态对齐策略成功地学习到了互补的模态语义,实现了卓越的鲁棒性。
⚖️ 评分理由
- 学术质量(6.5/7):创新性强,提出了统一的异构图Transformer和无增强的跨模态GCL,从模型架构和训练目标两方面系统性地解决了MERC的痛点。技术实现正确,方法细节清晰,损失函数设计有理论依据。实验非常充分,在两大权威数据集上进行了全面对比、详细的消融研究和深入的鲁棒性分析,并报告了统计显著性。证据可信,可视化结果与定量分析相互印证。扣分点在于对更复杂现实场景(如多模态噪声)的讨论有限,且未提供代码。
- 选题价值(1.5/2):选题前沿且重要,多模态情感识别是人机交互的关键技术,缺失模态鲁棒性是实际部署的刚性需求。潜在影响较大,为构建可靠的会话AI提供了新思路。应用空间明确,直接服务于智能客服、陪伴机器人等领域。与语音/多模态读者高度相关。
- 开源与复现加成(0.3/1):论文提供了极其详细的训练超参数、硬件配置和实验设置,使得复现门槛在理论上较低。然而,最关键的是未提供代码仓库链接和预训练模型,这极大地增加了实际复现的难度和时间成本,因此加成有限。