📄 Graph-Based Emotion Consensus Perception Learning for Multimodal Emotion Recognition in Conversation
#多模态情感识别 #图神经网络 #对比学习 #会话理解 #情感计算
✅ 7.5/10 | 前25% | #多模态情感识别 | #图神经网络 | #对比学习 #会话理解
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Huan Zhao (论文中作者列表首位,但未明确标注“第一作者”,因此按惯例推断)
- 通讯作者:Yingxue Gao (论文明确标注“*Corresponding authors: Y. Gao”)
- 作者列表:Huan Zhao (湖南大学计算机科学与电子工程学院)、Gong Chen (湖南大学计算机科学与电子工程学院)、Zhijie Yu (湖南大学计算机科学与电子工程学院)、Yingxue Gao* (湖南大学计算机科学与电子工程学院)
💡 毒舌点评
该论文的亮点在于其“共识感知学习模块”设计得相当精巧,通过原型学习和说话人对比损失双管齐下,直击多模态情感识别中“模态冲突”这一核心痛点,理论动机清晰且有效。短板在于其创新更多是增量式的改进而非范式突破,且“共识原型”的学习本质上还是依赖于有监督的类别标签,对于完全未知的、细粒度的或混合情感表达,其泛化能力有待进一步验证。
🔗 开源详情
- 代码:是。论文提供了GitHub代码仓库链接:
https://github.com/Clancyy/ConGraNet。 - 模型权重:未提及。论文未说明是否公开预训练模型权重。
- 数据集:未提及。论文使用的是公开数据集(IEMOCAP, MELD),但未说明是否提供处理后的数据或额外资源。
- Demo:未提及。论文未提供在线演示链接。
- 复现材料:提供了部分复现材料,包括:
- 关键的超参数配置表(表1)。
- 模型架构描述和公式。
- 代码仓库(假设包含实现)。
- 但未提供:训练日志、最终检查点、详细的环境配置文档。
- 论文中引用的开源项目:论文在参考文献中引用了多个开源数据集(如IEMOCAP [17], MELD [18])和基线模型代码(如DialogueRNN [19], DialogueGCN [21]等)。
📌 核心摘要
- 要解决的问题:现有对话多模态情感识别(MERC)方法常忽略同一情感类别在不同模态(如声音、语言、表情)下所体现的“情感共识”,导致模态间冲突信号影响识别精度,且难以处理类别混淆和样本不均衡问题。
- 方法核心:提出图基情感共识感知(GECP)框架。其核心是共识感知学习(CAL)模块,包含两阶段:1) 构建多模态传播图以捕获跨模态共享信号与特有差异;2) 通过情感共识学习单元将各模态信号与共同的“情感原型”对齐,提炼类别本质特征。
- 与已有方法相比新在何处:不同于以往主要关注上下文依赖或简单融合的方法,GECP显式地建模并学习了类别级的情感共识原型,并通过引入说话人引导的对比学习损失,在对齐跨模态语义的同时,保留了个体表达的多样性。
- 主要实验结果:在IEMOCAP和MELD数据集上,GECP均取得了最佳性能。
- IEMOCAP:Weighted-F1 72.85%, Accuracy 72.91%, 较之前最优模型(Frame-SCN)分别提升约1.85%和1.93%。
- MELD:Weighted-F1 66.96%, Accuracy 68.08%, 较之前最优模型(FrameERC)分别提升约0.33%和0.46%。消融实验证明,移除CA单元或任一损失函数(Lc, LSpk)都会导致性能下降,其中移除CA单元下降最明显。
- 实际意义:提升了机器在复杂对话场景中理解人类情感的能力,尤其在处理情感类别易混淆和样本分布不平衡的情况下更为有效,可直接应用于提升智能客服、社交机器人等系统的交互体验。
- 主要局限性:论文中未深入讨论。潜在局限可能包括:对动态演变的情感共识建模不足(未来工作已提及)、模型复杂度较高、以及在跨文化、跨语言场景下的泛化能力未被验证。
🏗️ 模型架构
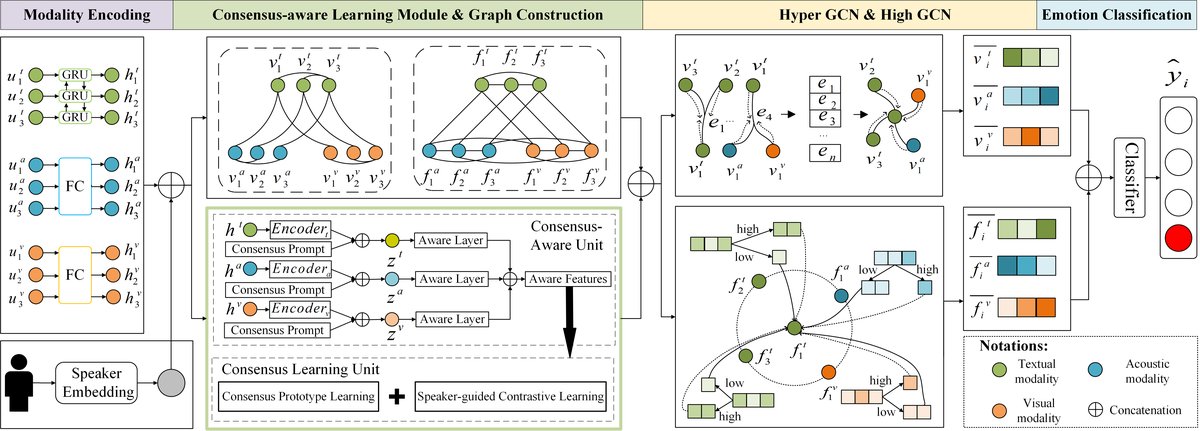 图1展示了GECP的总体架构,其处理流程如下:
图1展示了GECP的总体架构,其处理流程如下:
- 模态编码(Modality Encoding):将每个话语的文本、音频、视觉三种模态数据分别编码。文本使用双向GRU,音频和视觉使用单层MLP。之后,为每个说话者学习一个嵌入向量,并将其加到各模态特征中,得到具有说话者和上下文感知的单模态表示。
- 共识感知学习模块(CAL Module):这是框架的核心创新部分,包含两个单元:
- 共识感知单元(CA Unit):接收各模态特征,通过Transformer层和线性层,建模模态内和跨模态的情感共性,生成融合了丰富情感上下文的“共识感知特征”。
- 共识学习单元(CL Unit):基于CA单元的输出,通过一个类内损失(使特征向对应类别原型聚拢)和一个类间损失(使不同类别原型相互远离)来学习情感共识原型。同时,引入一个说话人引导的对比学习损失,将同一说话者、同一情感的不同模态样本视为正对,以进一步对齐跨模态特征。
- 图构建(Graph Construction):构建两种图结构:
- 超图 H:包含两种超边。一种是“上下文超边”,连接同一模态跨不同话语的节点;另一种是“多模态超边”,连接同一话语内不同模态的节点。用于捕获高阶依赖关系。
- 多频率图 G:一个普通图,节点与超图相同。边连接同一模态跨话语的节点以及同一话语内跨模态的节点。其归一化拉普拉斯矩阵用于后续的多频率滤波。
- 特征传播(Feature Propagation):在图结构上进行卷积传播。
- 超图卷积(Hyper GCN):通过节点卷积和超边卷积的交替操作,在超图上传播高阶信息,得到传播后的特征。
- 多频率图卷积(High GCN):利用图傅里叶变换理论,设计低通和高通滤波器。通过一个可学习的门控机制自适应地融合低频(全局趋势)和高频(局部细节)信息,得到多频率表示。
- 情感分类(Emotion Classification):将经过超图传播和多频率传播后的所有模态特征拼接起来,经过ReLU激活和全连接层,通过softmax输出属于各个情感类别的概率分布。
💡 核心创新点
- 提出“情感共识”概念并设计CAL模块进行显式建模:是什么:认为同一情感在不同模态下表现虽异,但存在共同的“情感原型”。CAL模块旨在学习这些原型。局限:以往方法多隐式学习跨模态表征,缺乏对这一共识的显式建模。如何起作用:通过CA单元融合信息,CL单元通过原型损失和对比损失学习并利用这些共识。收益:增强了模型对模态冲突的鲁棒性,提升了分类准确性,尤其在类别混淆时。
- 设计说话人引导的对比学习损失(LSpk):是什么:一种监督对比损失,正样本对定义为同一说话者、同一情感的不同模态样本。局限:常规对比学习可能只考虑单模态或简单跨模态配对,未充分利用说话人身份这一重要上下文。如何起作用:强制同一说话者表达同一情感时,其不同模态的表征在嵌入空间中靠近。收益:更精准地对齐跨模态特征,同时保留因说话者个体差异导致的表征多样性。
- 构建双图结构进行多视角特征传播:是什么:同时构建超图(捕获高阶关系)和多频率图(捕获多尺度频率信息)。局限:单一图结构可能无法全面刻画复杂的对话动态。如何起作用:超图卷积聚合高阶信息;多频率图卷积通过可学习滤波器分离并融合不同频率的信号。收益:从不同角度和粒度丰富了话语的特征表示,更好地捕捉对话中的情感流动和依赖关系。
🔬 细节详述
- 训练数据:
- 数据集:IEMOCAP(约7433个话语,10位说话者,6类情感,标准训练/测试划分);MELD(约13708个话语,来自《老友记》,7类情感,标准训练/验证/测试划分)。
- 预处理/增强:论文中未具体说明预处理步骤和数据增强策略。
- 损失函数:
- Lc = Lintra + Linter:用于情感原型学习。Lintra使特征向原型聚拢,Linter使不同原型分开。
- LSpk:说话人引导的对比学习损失,温度参数τ。
- 总损失:论文未明确说明最终总损失函数是否为 Lc + LSpk 或有其他加权,论文中未提及具体总损失公式及权重。
- 训练策略:
- 优化器:Adam。
- 学习率:1e-4。
- 批大小(Batch Size):16(两个数据集相同)。
- 训练轮数/步数:论文未明确说明。
- 调度策略:论文未提及学习率调度策略。
- 关键超参数:见表1。
数据集 批大小 优化器 隐藏维度 Dh 超图卷积层数 L 多频率图卷积层数 K Dropout IEMOCAP 16 Adam (lr=1e-4) 512 5 2 0.2 MELD 16 Adam (lr=1e-4) 512 3 3 0.4 - 训练硬件:NVIDIA GeForce RTX 2080 Ti GPU,CUDA 12.0,Ubuntu 20.04.4系统。
- 推理细节:论文未提及推理时的特殊策略(如温度调节、解码方式)。
- 正则化技巧:使用了Dropout(如表1所示)。
📊 实验结果
表2:在IEMOCAP和MELD数据集上的总体性能对比
| 模型 | IEMOCAP (W-F1 / ACC) | MELD (W-F1 / ACC) |
|---|---|---|
| 非图方法 | ||
| DialogueRNN | 68.64 / 68.72 | 65.94 / 65.31 |
| MetaDrop | 69.38 / 69.59 | 66.63 / 66.30 |
| 图方法 | ||
| DialogueGCN | 63.96 / 64.44 | 63.49 / 62.78 |
| MMGCN | 66.79 / 66.99 | 66.63 / 65.13 |
| DER-GCN | 69.40 / 69.70 | 66.10 / 66.80 |
| AR-IIGCN | 70.36 / 70.46 | 64.01 / 64.14 |
| D2GNN | 69.77 / 70.22 | 59.74 / 61.72 |
| HiMul-LGG | 70.22 / 70.12 | 65.18 / 66.21 |
| FrameERC | 70.67 / 70.79 | 66.63 / 67.62 |
| Frame-SCN | 71.00 / 70.98 | 59.10 / 61.92 |
| GECP (ours) | 72.85 / 72.91 | 66.96 / 68.08 |
关键结论:GECP在两个数据集的所有指标(Weighted-F1和Accuracy)上均达到了最优。在IEMOCAP上提升显著(约+1.8%),在MELD上提升幅度较小但依然稳定。
表3:GECP的消融实验结果
| 方法 | IEMOCAP (W-F1 / ACC) | MELD (W-F1 / ACC) |
|---|---|---|
| w/o CA (移除CA单元) | 71.27 / 71.33 | 66.75 / 67.76 |
| w/o Lc (禁用原型损失) | 70.77 / 70.82 | 66.55 / 67.53 |
| w/o LSpk (移除对比损失) | 71.96 / 72.05 | 66.29 / 67.24 |
| GECP (ours) | 72.85 / 72.91 | 66.96 / 68.08 |
关键结论:移除任何一个组件都会导致性能下降,验证了其必要性。其中,移除CA单元造成的性能下降最大,表明共识感知是框架的核心。损失函数Lc和LSpk也贡献了稳定的性能提升。
⚖️ 评分理由
- 学术质量:6.5/7:论文提出了一个动机清晰、设计合理的创新模块(CAL),并通过充分的实验(对比SOTA、消融研究)验证了其有效性。技术路线正确,结果可信。扣分点在于创新属于领域内的渐进式改进,而非开辟全新范式。
- 选题价值:1.5/2:多模态情感识别是活跃且有应用价值的研究方向。论文针对“模态共识”这一具体挑战提出的解决方案具有理论和实际意义。扣分是因为该问题相对垂直,影响力范围有限。
- 开源与复现加成:0.5/1:论文提供了代码链接和关键超参数配置,大大降低了复现门槛,这是显著的加分项。未提供预训练模型和详细的训练日志是主要的扣分原因。