📄 GMS-CAVP: Improving Audio-Video Correspondence with Multi-Scale Constrative and Generative Pretraining
#音视频 #对比学习 #扩散模型 #音频生成 #多尺度模型
✅ 7.5/10 | 前25% | #音频生成 | #扩散模型 | #音视频 #对比学习
学术质量 7.0/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 中
👥 作者与机构
- 第一作者:未说明(论文作者列表为“Shentong Mo1,2,3, Zehua Chen3, Jun Zhu3”,未明确标注第一作者)
- 通讯作者:未说明
- 作者列表:Shentong Mo(卡内基梅隆大学,MBZUAI,清华大学),Zehua Chen(清华大学),Jun Zhu(清华大学)
💡 毒舌点评
亮点在于将多尺度对比学习和多尺度扩散生成统一在一个框架内,为音视频预训练提供了新范式,实验结果在多个指标上刷新了SOTA;短板是论文对于模型具体架构细节(如扩散模型中噪声预测网络的具体设计)、训练硬件和完整超参数列表描述不足,且未提及开源计划,这使得严格的复现存在挑战。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开权重。
- 数据集:使用了公开数据集VGGSound、AudioSet和Panda70M,但未说明是否提供了特定的预处理脚本。
- Demo:未提及在线演示。
- 复现材料:给出了部分训练细节(优化器、学习率、批次大小、训练轮数),并参考了Diff-Foley的扩散设置。但模型架构的具体实现细节、完整的超参数列表和训练日志/检查点未提供。
- 论文中引用的开源项目:引用并基于Diff-Foley [6]的生成器设置;使用Adam优化器。
- 开源计划:论文中未提及开源计划。
📌 核心摘要
本文旨在解决现有对比音视频预训练方法在捕捉细粒度、多层次跨模态对应关系以及直接支持生成任务方面的不足。方法核心是提出GMS-CAVP框架,它统一了多尺度视频-音频对齐(MSA)的对比学习目标与多尺度空间-时间扩散(MSD)的生成预训练目标。与之前仅使用单尺度全局对比学习的方法相比,GMS-CAVP能捕获从细到粗的时空依赖关系,并直接建模模态间的转换映射。主要实验结果表明,在VGGSound等数据集上,GMS-CAVP在视频到音频生成任务(KLD: 1.63, FAD: 0.75, Align Acc: 95.87)和检索任务(如视频到音频R@1: 28.90)上均大幅超越了现有方法。其实际意义是为音视频理解与生成提供了更强大、统一的预训练基础。主要局限性可能包括模型复杂度增加带来的计算开销,以及对扩散模型采样速度的潜在影响(论文未深入讨论)。
关键实验数据对比:
| 方法 | KLD ↓ | FAD ↓ | Align Acc ↑ |
|---|---|---|---|
| SpecVQGAN | 3.78 | 6.63 | 48.79 |
| Im2Wav | 2.54 | 6.32 | 74.31 |
| Diff-Foley | 3.15 | 6.40 | 82.47 |
| FoleyGen | 2.89 | 2.59 | 73.83 |
| V2A-Mapper | 2.78 | 0.99 | 74.37 |
| Seeing & Hearing | 2.62 | 2.63 | 78.95 |
| MaskVAT | 2.65 | 1.51 | 63.87 |
| VAB | 2.58 | 2.69 | 76.83 |
| VATT | 2.25 | 2.35 | 82.81 |
| GMS-CAVP (ours) | 1.63 | 0.75 | 95.87 |
🏗️ 模型架构
GMS-CAVP是一个统一的判别-生成预训练框架,旨在学习鲁棒的音视频对应表示。
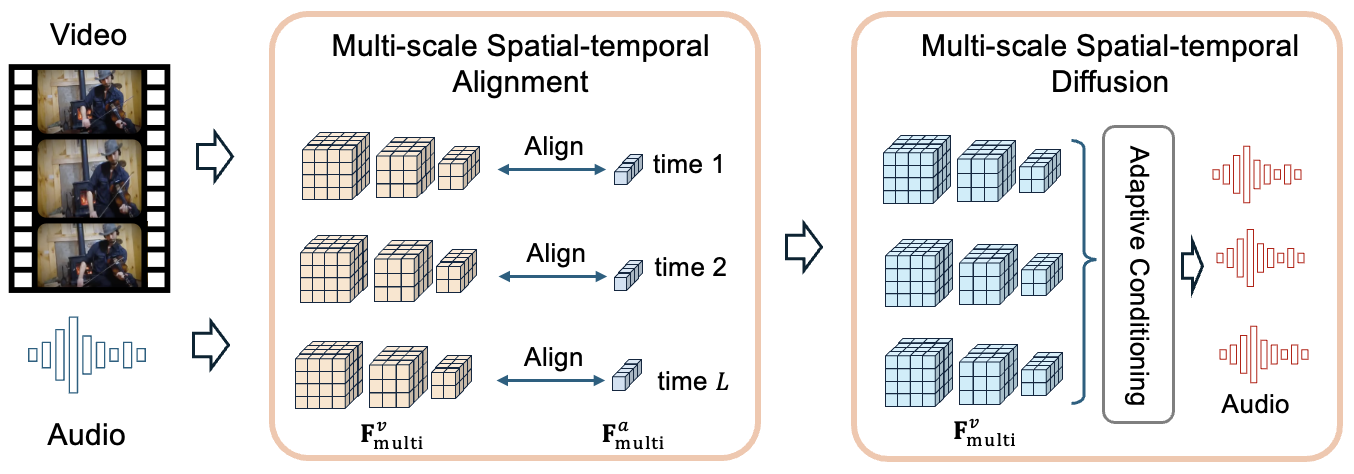
完整输入输出流程与组件:
- 输入:视频帧序列
V和对应的音频梅尔频谱图A。 - 编码器:使用预训练的音频编码器
f_a(·)和视频编码器f_v(·)分别提取特征F_a和F_v。 - 多尺度特征分解:将
F_a和F_v分解为多个分辨率(尺度)的特征集合F_a_multi和F_v_multi(公式2)。这通过时间金字塔池化和多分辨率卷积实现,以捕捉不同粒度的时空信息。 - 多尺度视频-音频对齐 (MSA) 模块:
- 功能:执行多层次的对比学习。
- 内部结构与数据流:在每个尺度
l,计算音频和视频特征的余弦相似度(公式3)。然后,计算所有尺度下的对比损失L_MSA(公式4),该损失是各尺度InfoNCE损失的总和。此外,引入了自适应时间对齐机制(公式5),通过注意力加权强调关键的时序区域,优化最终的对比目标。
- 多尺度空间-时间扩散 (MSD) 模块:
- 功能:执行基于扩散的生成预训练,建模从视频到音频的生成过程。
- 内部结构与数据流:采用层次化扩散模型。生成过程被定义为从噪声逐步去噪以恢复音频表示,且每一步都条件于多尺度的视频特征
F_v_multi(公式6)。训练损失L_MSD(公式7)监督模型预测不同扩散步骤t下的噪声ε,使其学会在视频条件下去除音频表示中的噪声。
- 整体训练:总损失是
L_MSA和L_MSD的组合(论文未明确具体权重)。 - 输出:预训练好的多尺度音视频编码器(用于检索),以及训练好的扩散解码器(用于生成)。
关键设计选择与动机:
- 多尺度分解:动机是解决现有方法使用单一尺度全局表示无法捕捉精细、层次化音视频对应的问题。
- 统一判别-生成目标:动机是解决仅用对比学习预训练的模型在生成任务上表现不佳的问题,通过引入生成目标来弥合模态转换的鸿沟。
- 自适应时间对齐:动机是聚焦于视频中与声音强相关的关键时刻,抑制无关信息干扰。
💡 核心创新点
- 统一的多尺度判别-生成预训练框架:首次将多尺度对比学习和多尺度扩散生成整合到同一个音视频预训练框架中。之前局限:CAVP等方法只使用对比目标,无法直接支持生成任务。该创新作用:使模型在学习强判别性对齐表示的同时,也具备了模态间转换的生成能力,收益:在检索和生成两项任务上都取得性能提升。
- 多尺度视频-音频对齐 (MSA):提出层次化的对比学习策略,在多个空间-时间分辨率上强制执行音视频对齐。之前局限:以往方法(如CAVP)采用单一尺度的全局对齐,忽略细粒度和层次化的跨模态对应。该创新作用:能捕获从动作细节到整体场景变化的多层级语义和时间关联,收益:提升了跨模态对齐的精确度(如Align Acc显著提高)和检索性能。
- 多尺度空间-时间扩散 (MSD):提出以多尺度视频特征为条件的层次化扩散模型,用于音频生成预训练。之前局限:Diff-Foley等扩散生成方法通常基于单级特征进行条件生成。该创新作用:模型可以利用不同尺度的视频信息来逐步、精细地合成音频,增强了生成的保真度和时序同步性,收益:降低了生成音频的分布差距(KLD, FAD下降)并提高了同步性。
🔬 细节详述
- 训练数据:VGGSound(20万片段,10秒), AudioSet(约200万视频), Panda70M(7000万音视频对)。预处理:视频帧调整为224x224;音频为8000Hz采样,10秒片段,使用STFT(50ms窗,25ms hop)生成128x128的梅尔频谱图。
- 损失函数:
L_MSA:各尺度下的InfoNCE对比损失之和。L_MSD:扩散模型的噪声预测均方误差损失(公式7),包含两个时间步的监督。总损失未给出具体组合权重。 - 训练策略:Adam优化器,学习率1e-4,批次大小64,训练200个epoch。扩散生成器设置参考了Diff-Foley [6]。
- 关键超参数:模型具体大小(如编码器维度、扩散网络层数)未说明。多尺度层级数
L未说明。 - 训练硬件:未说明。
- 推理细节:对于生成任务,使用扩散模型进行推理,具体采样步数、调度器等细节参考Diff-Foley。论文中提到了探索扩散采样步数的影响。
- 正则化/稳定训练:未明确提及,可能隐含在扩散训练或优化器选择中。
📊 实验结果
主要Benchmark与数据集:VGGSound(生成、检索), AudioSet(训练/评估?), Panda70M(训练/评估?)。主要评估生成任务和检索任务。
生成任务结果 (VGGSound测试集)
| 方法 | KLD ↓ | FAD ↓ | Align Acc ↑ |
|---|---|---|---|
| SpecVQGAN [1] | 3.78 | 6.63 | 48.79 |
| Im2Wav [2] | 2.54 | 6.32 | 74.31 |
| Diff-Foley [6] | 3.15 | 6.40 | 82.47 |
| FoleyGen [7] | 2.89 | 2.59 | 73.83 |
| V2A-Mapper [21] | 2.78 | 0.99 | 74.37 |
| Seeing & Hearing [8] | 2.62 | 2.63 | 78.95 |
| MaskVAT [11] | 2.65 | 1.51 | 63.87 |
| VAB [10] | 2.58 | 2.69 | 76.83 |
| VATT [12] | 2.25 | 2.35 | 82.81 |
| GMS-CAVP (ours) | 1.63 | 0.75 | 95.87 |
- 结论:GMS-CAVP在所有指标上均显著优于先前方法。与最强基线VATT相比,KLD降低27.6%,FAD降低68.1%,Align Acc提升15.7%。
检索任务结果
| 方法 | Video-to-Audio | Audio-to-Video | ||||
|---|---|---|---|---|---|---|
| R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | |
| CAVP [6] | 9.50 | 25.40 | 35.10 | 11.10 | 27.80 | 36.40 |
| GMS-CAVP (ours) | 28.90 | 43.70 | 57.90 | 30.50 | 45.30 | 58.20 |
- 结论:GMS-CAVP在检索任务上大幅超越基线CAVP,视频到音频R@1提升204%。
消融实验结果
| MSA | MSD | KLD ↓ | FAD ↓ | Align Acc ↑ | R@1 | R@5 | R@10 |
|---|---|---|---|---|---|---|---|
| ✗ | ✗ | 3.15 | 6.40 | 82.47 | 9.50 | 25.40 | 35.10 |
| ✓ | ✗ | 2.06 | 1.37 | 90.76 | 22.30 | 37.80 | 50.60 |
| ✗ | ✓ | 2.17 | 1.58 | 89.85 | 20.80 | 36.30 | 46.70 |
| ✓ | ✓ | 1.63 | 0.75 | 95.87 | 28.90 | 43.70 | 57.90 |
- 结论:单独引入MSA或MSD都能显著提升性能。二者结合时效果最佳,证明了对比学习与生成预训练目标的互补性。MSA对检索的贡献更直接,MSD对生成分布的改善(FAD下降)非常显著。
其他分析:论文提及探索了扩散采样步数、双向训练间隔、空间多尺度以及数据规模(VGGSound+AudioSet+Panda70M组合时KLD达1.35,FAD达0.58)的影响,但未提供具体数值。论文未给出这些细分实验的详细数字表格。
⚖️ 评分理由
- 学术质量:7.0/7:创新性较强,提出了统一的多尺度判别-生成预训练新范式。技术路线清晰,将对比学习与扩散生成有机结合。实验充分,在多个大规模数据集和任务上进行了全面对比与消融,结果可信且提升显著。
- 选题价值:1.5/2:音视频理解与生成是当前多模态AI的前沿方向,具有重要的学术价值和广阔的应用前景(如视频编辑、沉浸式媒体)。与音频/多媒体研究者高度相关。
- 开源与复现加成:-0.5/1:论文未提供代码或模型权重,训练硬件、关键超参数(模型维度、扩散网络结构)信息缺失,显著降低了可复现性。