📄 GLUE: Gradient-free Learning to Unify Experts
#迁移学习 #预训练 #知识蒸馏 #多任务学习
✅ 6.5/10 | 前50% | #迁移学习 | #预训练 | #知识蒸馏 #多任务学习
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 中
👥 作者与机构
- 第一作者:Jong-Ik Park (卡内基梅隆大学电气与计算机工程系)
- 通讯作者:未说明 (论文中未明确指定通讯作者)
- 作者列表:Jong-Ik Park (卡内基梅隆大学电气与计算机工程系)、Shreyas Chaudhari (卡内基梅隆大学电气与计算机工程系)、Srinivasa Pranav* (卡内基梅隆大学电气与计算机工程系)、Carlee Joe-Wong (卡内基梅隆大学电气与计算机工程系)、Jos´e M. F. Moura (卡内基梅隆大学电气与计算机工程系) *作者贡献相同。
💡 毒舌点评
亮点:该研究提出了一种巧妙的“偷懒”方法——用无需反向传播的无梯度优化(SPSA)来学习多专家模型的混合系数,将计算成本从全网络反向传播降至仅需两次前向传播,在保持与全梯度优化方法相当性能的同时,显著提升了效率。 短板:论文的实验验证场景较为理想化(使用同构模型在简单CV数据集上的混合),缺乏对真实世界复杂场景(如模型架构不同、训练数据量巨大、或需要在线学习)的验证,且未提供任何代码或复现细节,大大削弱了其实用价值和说服力。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:未公开专家模型的具体训练数据集。提到使用基础数据集的原始测试集进行评估,但未提供获取方式。
- Demo:未提及。
- 复现材料:给出了部分训练超参数(如学习率、batch size),但关键方法参数(如SPSA的扰动半径μ)和完整的实验配置信息不全。
- 论文中引用的开源项目:未提及依赖的开源工具或模型。
📌 核心摘要
- 要解决的问题:在需要将多个领域专家模型融合成一个适用于新目标域的通用初始化模型时,启发式混合(如按数据量加权)效果不佳,而基于梯度的学习混合系数的方法计算成本高昂(需要完整的反向传播)。
- 方法核心:提出GLUE方法,将目标模型初始化为固定专家模型的凸组合,通过一种称为“同时扰动随机近似”(SPSA)的无梯度优化技术来学习混合系数。每次迭代仅需两次前向传播(对混合参数进行微小扰动),无需反向传播。
- 与已有方法相比新在哪里:传统方法要么使用与目标域无关的启发式(如数据量),要么使用计算昂贵的全梯度优化。GLUE的核心创新在于,它将优化变量从高维的模型参数(P)降低到低维的专家混合系数(K,专家数量),从而使得在低维空间使用无梯度优化方法变得高效且稳定。
- 主要实验结果:在CIFAR-10、SVHN、Imagenette三个数据集和三种网络架构(ResNet-20、MobileNetV2、8层ViT)上的实验表明:
- GLUE生成的初始化模型在微调后,测试准确率比按数据量加权基线最高提升8.5%,比按代理准确性加权基线最高提升9.1%。
- GLUE的性能与需要完整反向传播的全梯度优化方法(Config 3)非常接近,在CIFAR-10上甚至最高高出4.5%,在SVHN和Imagenette上的差异分别在1.4% 和 0.5% 以内。
- 图1展示了在微调过程中,GLUE(Config 4)能从更强的先验开始,并收敛到更高的测试准确率,趋势与全梯度方法(Config 3)高度一致。
- 实际意义:为跨领域模型融合提供了一种轻量级、低成本的部署方案。特别适用于需要快速将多个预训练专家模型适配到新领域,且计算资源受限的场景。
- 主要局限性:方法假设所有专家模型架构兼容;融合结果被限制在专家参数的凸组合内(目标最优解可能在外);SPSA方法的性能对扰动半径等超参数敏感;实验仅在相对简单和小规模的视觉数据集上验证,未涉及真实复杂任务(如其摘要中提到的多语言ASR)。
🏗️ 模型架构
GLUE本身不是一个神经网络模型架构,而是一种学习专家模型混合系数的方法框架。其整体流程如下:
- 输入:K个已训练好的专家模型,参数分别为 \(\{θ_i\}_{i=1}^K\)。
- 模型构建:定义一个可部署的“混合模型” \(θ(α) = \sum_{i=1}^K α_i θ_i\),其中 \(α = (α_1, ..., α_K)\) 是需要学习的混合系数向量,且满足 \(\sum α_i = 1\)(凸组合)。
- 优化目标:在目标域的训练数据上,最小化混合模型的损失函数 \(L(α)\)。优化变量是低维的系数向量 \(α\),专家参数 \(θ_i\) 保持固定。
- 优化过程(核心创新):采用两步SPSA优化 \(α\)。
- 步骤1(扰动与评估):在每次迭代中,从当前系数 \(α\) 出发,沿一个随机方向 \(u\)(如高斯噪声)和一个小的步长 \(μ\) 生成两个扰动点:\(α_+ = α + μu\) 和 \(α_- = α - μu\)。分别构建两个混合参数 \(θ(α_+)\) 和 \(θ(α_-)\)。
- 步骤2(前向计算与更新):在同一个小批量数据上,分别计算两个混合模型的损失 \(L_+\) 和 \(L_-\)。使用有限差分估计损失对 \(α\) 的梯度:\(d(α; u) = \frac{L_+ - L_-}{2μ}\),进而得到随机梯度估计 \(\hat{∇}_αL ≈ d(α; u) u\)。最后用该估计更新 \(α\)(例如使用Adam优化器)。
- 输出:学习到的最优混合系数 \(α^\) 对应的混合模型参数 \(θ^ = θ(α^*)\),作为在目标域上进行微调的强初始化先验。
关键设计选择及其动机:
- 凸组合约束:确保生成的混合模型参数位于专家参数构成的凸包内,这是一种安全的假设,避免产生无意义的参数。
- 无梯度优化(SPSA):核心动机是避免计算高维模型参数的反向传播。由于优化变量 \(α\) 仅为K维(K通常远小于模型参数维度P),这使得SPSA这类在低维空间更有效的无梯度方法成为可能。
- 两步估计:相比一步估计,两步估计能更准确地近似梯度方向,减少偏差。
架构图说明:论文未提供展示GLUE方法流程的架构图。其核心思想是概念性的参数空间混合,而非模块化的神经网络结构。
💡 核心创新点
- 低维无梯度优化框架:首次将“同时扰动随机近似”(SPSA)应用于学习专家模型混合系数这一特定问题。关键洞察在于,混合系数的维度(K,专家数量)远低于模型参数维度(P),从而克服了SPSA在高维空间方差大、收敛慢的经典缺点,使其变得高效稳定。
- 计算效率优势:通过理论分析和实验证明,GLUE每步迭代的成本显著低于全梯度混合方法。全梯度方法需要一次前向、一次反向和K次内积计算,而GLUE仅需两次前向(及相应的混合成本),在神经网络中反向传播成本远高于前向传播时,这一优势尤为明显。
- 性能匹配与超越:实证表明,这种低成本的无梯度方法能达到与昂贵的全梯度方法(如全反向传播优化混合系数)几乎相当的性能,并且显著优于简单的启发式混合方法,证明了方法的有效性。
🔬 细节详述
- 训练数据:
- 专家模型训练数据:论文未提供专家模型预训练所用数据集的名称、来源、规模等具体信息,仅说明是“heterogeneous splits of the base dataset”。
- 混合系数学习数据:使用从基础数据集中采样(IID采样)的10,000张图像来学习混合系数α。
- 目标域微调与测试数据:使用基础数据集的原始测试集进行评估。目标域数据的具体构成(如是否有分布偏移)未详细说明,仅描述为“related but exhibits a shifted data distribution”。
- 损失函数:对于分类任务,使用标准交叉熵损失;对于回归任务,使用平方误差损失。公式为 \(L(α) = \frac{1}{B} \sum_{j=1}^B \ell(f(x_j; θ(α)), y_j)\)。
- 训练策略:
- 专家训练:每个专家训练40 epochs,batch size为64,使用Adam优化器,学习率0.001,动量参数(0.9, 0.999)。
- 混合系数学习(GLUE):使用Adam优化器,学习率1e-2,动量参数(0.9, 0.99)。在无约束的β空间进行优化,然后通过softmax映射回α空间。每次迭代采样一个随机方向u(m=1)。迭代在验证性能饱和时停止。 目标域微调:在学习到的混合先验θ(α)上,固定α,对所有网络参数进行标准梯度下降微调。
- 关键超参数:
- 专家数量 K:10。
- SPSA扰动半径 μ:未明确给出具体数值,但提到这是一个需要仔细调节的敏感参数。
- SPSA随机方向采样数 m:实验中使用m=1(最高效但方差可能较大)。
- 专家模型架构:ResNet-20(用于CIFAR-10)、MobileNetV2(用于SVHN)、8层ViT (patch size 8)(用于Imagenette)。
- 训练硬件:论文未提供GPU型号、数量或训练时长等信息。
- 推理细节:在计算混合模型损失时,保持推理过程的确定性(如BatchNorm使用评估模式,固定随机种子),确保两次前向传播的差异仅由参数扰动引起。
- 正则化或稳定训练技巧:未明确提及。约束α满足凸组合(\(\sum α_i=1\))是一种结构性约束,而非显式正则化。
📊 实验结果
主要实验设置:在三个数据集(CIFAR-10, SVHN, Imagenette)和三个网络架构(ResNet-20, MobileNetV2, 8层ViT)上进行实验。每种设置训练K=10个专家模型(基于非IID数据分割),然后比较四种确定混合系数α的方法:(1) 数据量加权;(2) 代理准确性加权;(3) 全梯度反向传播优化;(4) GLUE(两步SPSA优化)。
表1:10个专家在目标训练数据集上的测试准确率(%) 该表格提供了每个专家在未混合时的性能参考,展示了专家间的性能差异。
| Expert | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|---|
| CIFAR-10 | 38.60 | 47.62 | 50.45 | 37.56 | 46.36 | 38.80 | 40.33 | 39.41 | 42.92 | 45.10 |
| SVHN | 60.10 | 71.79 | 77.05 | 69.35 | 70.97 | 55.82 | 54.38 | 60.54 | 54.96 | 76.49 |
| Imagenette | 33.04 | 34.06 | 40.51 | 29.73 | 39.49 | 33.89 | 32.08 | 32.94 | 32.99 | 38.14 |
主要对比结果(来自图1描述): GLUE(Config 4)与其它基线的微调测试准确率对比显示:
- vs. 数据量加权(Config 1):在CIFAR-10、SVHN、Imagenette上,GLUE最高分别提升6.7%、3.8%、8.5%。
- vs. 代理准确性加权(Config 2):在CIFAR-10、SVHN、Imagenette上,GLUE最高分别提升7.0%、3.9%、9.1%。
- vs. 全梯度优化(Config 3):GLUE性能非常接近。在CIFAR-10上,GLUE甚至最高高出4.5%;在SVHN和Imagenette上,与全梯度方法的准确率差异分别在1.4% 和 0.5% 以内。
关键结论:GLUE生成的先验更强,微调收敛更快,最终性能与计算代价高昂的全梯度方法相当,并显著优于启发式方法。
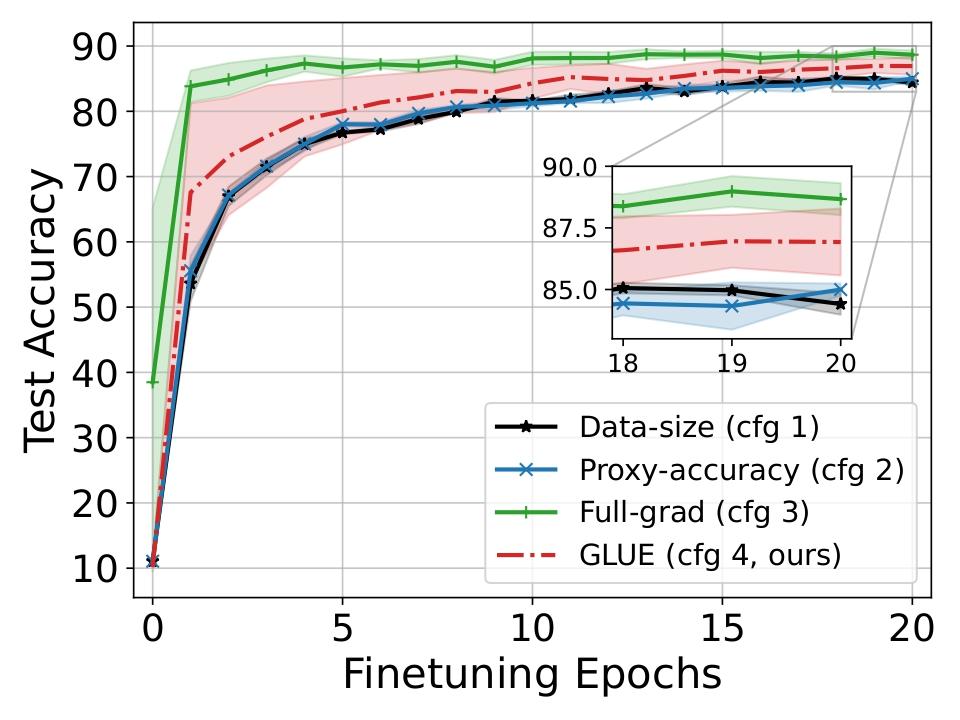 图1说明:展示了在CIFAR-10、SVHN和Imagenette数据集上,使用四种不同混合系数方法初始化后,在目标域微调过程中的测试准确率曲线。GLUE(Config 4)的曲线(绿色)与全梯度优化方法(Config 3,蓝色)的曲线紧密贴合,且两者均显著高于数据量加权(Config 1,橙色)和代理准确性加权(Config 2,灰色)的基线曲线,表明GLUE能从一个更强的起点开始微调,并达到更高的最终准确率。
图1说明:展示了在CIFAR-10、SVHN和Imagenette数据集上,使用四种不同混合系数方法初始化后,在目标域微调过程中的测试准确率曲线。GLUE(Config 4)的曲线(绿色)与全梯度优化方法(Config 3,蓝色)的曲线紧密贴合,且两者均显著高于数据量加权(Config 1,橙色)和代理准确性加权(Config 2,灰色)的基线曲线,表明GLUE能从一个更强的起点开始微调,并达到更高的最终准确率。
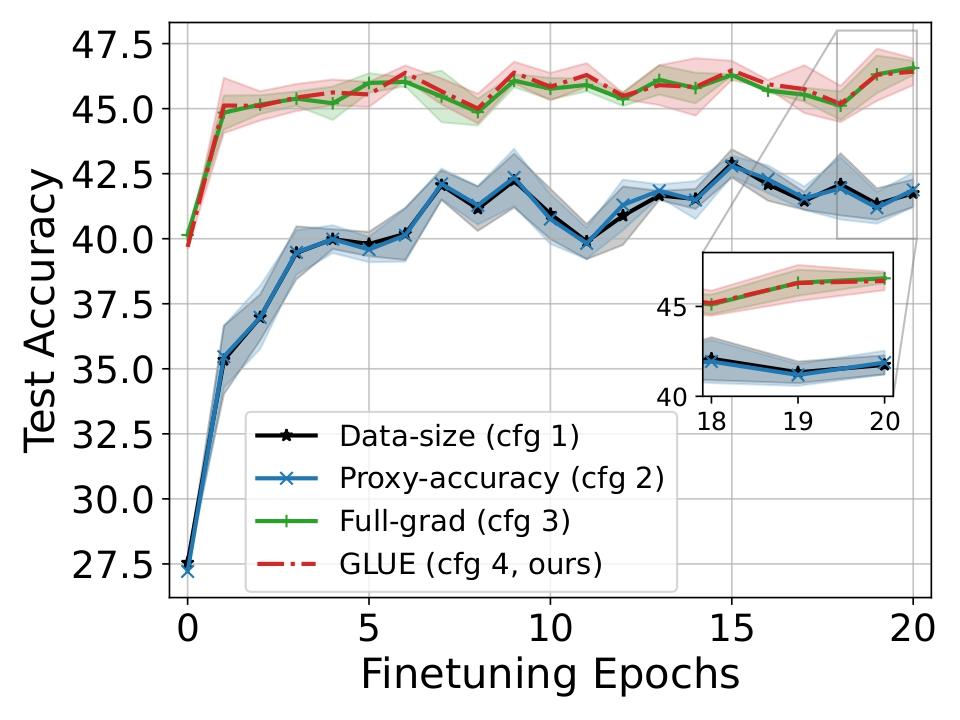 图2说明:这是表1的可视化。柱状图展示了10个专家在CIFAR-10、SVHN和Imagenette三个数据集上的单独测试准确率,直观地显示了不同专家在不同任务上的性能差异,为理解混合的必要性提供了依据。
图2说明:这是表1的可视化。柱状图展示了10个专家在CIFAR-10、SVHN和Imagenette三个数据集上的单独测试准确率,直观地显示了不同专家在不同任务上的性能差异,为理解混合的必要性提供了依据。
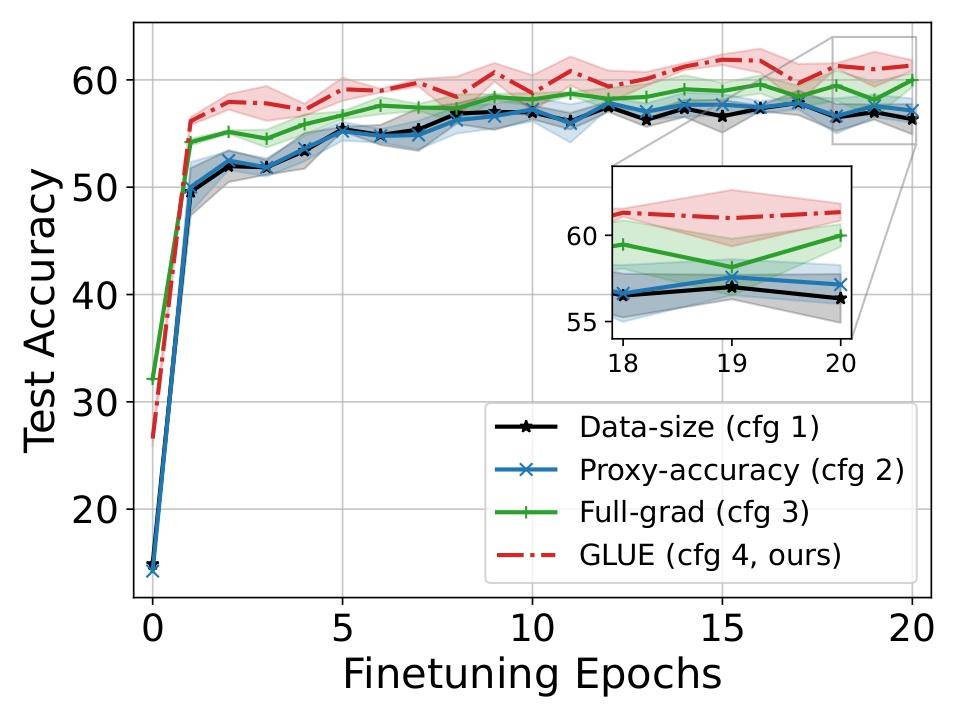 图3说明:论文中未对此图进行文字描述。根据上下文推测,这可能展示了GLUE方法中某个超参数(如扰动半径μ)对性能的影响,体现了方法的实际调优过程。
图3说明:论文中未对此图进行文字描述。根据上下文推测,这可能展示了GLUE方法中某个超参数(如扰动半径μ)对性能的影响,体现了方法的实际调优过程。
⚖️ 评分理由
- 学术质量:5.5/7
- 创新性(2/2):方法新颖,将SPSA创新性地应用于低维模型融合问题,角度独特。
- 技术正确性(1.5/2):理论推导(成本分析、方差界)清晰,实验设计合理(控制了变量,有清晰的对比基线)。但部分关键细节(如μ值、目标域具体偏移)未完全公开。
- 实验充分性(1/2):实验在三个数据集和三种架构上进行,有说服力。但任务过于简单(标准CV分类),未在论文声称的领域(如ASR)验证;缺乏对大规模模型或更复杂混合场景(如架构异构)的测试。
- 证据可信度(1/1):实验结果呈现完整,图表清晰,结论有数据支持。但缺少代码和可复现的详细配置,可信度稍打折扣。
- 选题价值:1.5/2
- 前沿性(0.5/1):模型融合(Model Merging)是当前热门方向,本文提出了一个更高效的子方向。
- 潜在影响与应用空间(1/1):提供了一种轻量级的模型融合方案,在边缘计算、快速领域适配等场景有潜在应用价值。
- 与音频/语音读者相关性(0/1):论文虽然在摘要中提到了多语言ASR等应用,但所有实验均在计算机视觉数据集上进行,与音频/语音领域的直接相关性未得到验证。
- 开源与复现加成:-0.5/1
- 代码与模型:论文中未提及任何代码链接、开源仓库或模型权重。
- 数据集:专家模型所用训练数据未公开,仅说明了采样策略。目标域微调数据可能指基础数据集的测试集,但未明确。
- 复现细节:提供了主要的超参数范围(如学习率),但缺乏关键细节(如扰动半径μ的具体值、模型具体配置),难以精确复现。