📄 GLoRIA: Gated Low-Rank Interpretable Adaptation for Dialectal ASR
#语音识别 #领域适应 #参数高效微调 #可解释性
🔥 8.0/10 | 前25% | #语音识别 | #领域适应 | #参数高效微调 #可解释性
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 中
👥 作者与机构
- 第一作者:Pouya Mehralian (ESAT/PSI, KU Leuven, Belgium)
- 通讯作者:未说明
- 作者列表:Pouya Mehralian (ESAT/PSI, KU Leuven, Belgium)、Melissa Farasyn (∆iaLing, Ghent University, Belgium)、Anne Breitbarth (∆iaLing, Ghent University, Belgium)、Anne-Sophie Ghyselen (GLiMS & MULTPIPLES, Ghent University, Belgium)、Hugo Van hamme (ESAT/PSI, KU Leuven, Belgium)
💡 毒舌点评
这篇论文巧妙地将方言的“地理基因”编码进模型适配的“开关”里,让参数高效的LoRA学会了根据地图位置“量身定制”调整方向,可解释性做得相当漂亮。但其“门控”机制的发挥严重依赖基础模型本身对方言是“中立”的这个假设,如果预训练模型已经对某种方言有偏见,这套非负加法的逻辑可能就玩不转了,且依赖固定元数据(坐标)在流动性强的现代社会可能是个局限。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开的GLoRIA适配权重或预训练CASAD模型权重。
- 数据集:使用了GCND语料库,论文未提供直接获取链接,需联系相关机构或参考文献[19]。
- Demo:未提及。
- 复现材料:提供了详细的模型架构参数、训练配置(学习率、优化器、批次大小等)、正则化权重、特征提取细节等,复现指引较为充分。
- 论文中引用的开源项目:提到了ESPnet [29] 工具包、SpecAugment [28] 数据增强方法。
📌 核心摘要
这篇论文旨在解决方言语音识别(ASR)中因地区差异巨大和标注数据稀缺而导致的性能瓶颈问题。其核心方法是提出GLoRIA,一个参数高效的自适应框架。GLoRIA在预训练ASR编码器的每个前馈层注入低秩矩阵(A和B),并引入一个由地理坐标驱动的门控MLP来预测一个对角矩阵E。最终的权重更新为W’ = W + AEB,即每个秩-1适配方向由对应的门控值(γ_i)独立调制,且该值通过Softplus激活保证非负。
与已有方法相比,GLoRIA的新颖之处在于:1) 它不是简单地使用离散方言标签或坐标拼接,而是通过门控机制动态、连续地调制低秩适配方向,实现了基于地理位置的“平滑”方言插值与外推;2) 它引入了正交性和稀疏性正则化,鼓励适配方向的多样性和选择性,提升了可解释性;3) 它在保持参数高效的同时,在性能上超越了全微调和标准LoRA。
主要实验在GCND荷兰方言语料库上进行,结果表明,使用rank=128的GLoRIA在所有训练方言区的平均词错误率(WER)为34.59%,显著优于方言联合微调(36.45%)、坐标嵌入(37.66%)和标准LoRA(rank=128时为40.36%)。在四个未见方言区,GLoRIA也取得了最佳或次佳的WER,展现了良好的泛化能力,尤其是在外推到训练数据凸包之外的边缘方言时。
其实际意义在于为低资源、多方言场景下的ASR提供了一种高效、可解释且性能优越的自适应方案,同时其方法论可推广至其他需要基于结构化元数据进行模型适配的任务。主要局限性包括:其有效性建立在基础模型对方言相对“中立”的假设上;对地理坐标的依赖可能无法完全覆盖方言形成的全部社会语言学因素;尽管提供了详细的设置,但未开源代码和基座模型权重,限制了即时复现性。
🏗️ 模型架构
GLoRIA的架构核心是对预训练ASR编码器中每个前馈(FF)子层进行可调制的低秩适配,并由一个全局门控网络根据输入元数据动态生成调制权重。
基础模型:采用一个预训练的、基于级联编码器(Cascaded Encoder)的双特征ASR模型。该模型包含:
- ASR编码器:处理原始音频。
- 字幕编码器:用于生成精炼的表征。
- 两个多Transformer解码器,并行地关注上述两个编码器,分别生成逐字稿和字幕转录。
- 本研究主要使用在更大数据集(14k小时)上训练的字幕解码器输出。基础模型为荷兰语专用,拥有约1.8亿参数。
- 在GLoRIA适配前,该模型会先在目标方言数据上进行5个epoch的无元数据微调(方言微调)。
GLoRIA适配模块:
- 注入位置:在预训练模型的每个编码器层的每个FF子层(对于Conformer,包括Macaron FF和标准FF)注入适配模块。
- 低秩更新:对于每个FF层的权重矩阵
W,引入两个可学习矩阵A(d_out × r)和B(r × d_in),其中r(秩)远小于d_in和d_out。 - 门控机制:引入一个对角矩阵
E(r × r),其对角线元素γ由一个门控MLP(gate-mlp)预测。该MLP以录音位置的地理坐标c=(lat, lng)为输入,通过两层网络(隐藏层32,GeLU激活)和Softplus输出层,生成非负的γ向量。 适配公式:最终的权重更新为W' = W + AEB。这等价于W' = W + Σ(γ_i a_i b_i^T),即每个秩-1适配方向a_i b_i^T被其对应的门控值γ_i独立缩放。
数据流与交互:
- 输入:音频特征 + 录音地理坐标。
- 音频经过预训练编码器,但每个FF层的计算都包含了GLoRIA的低秩更新。
A,B矩阵在所有层共享?不,论文明确指出“每个FF子层都有独立的低秩矩阵和gate-mlp”。- 地理坐标仅通过gate-mlp影响
γ,进而调制每个FF层内的低秩更新,而不直接改变音频特征。 - 解码器接收适配后的编码器表征,输出转录结果。
关键设计与动机:
- 非负门控:使用Softplus确保
γ ≥ 0,动机是假设基础模型相对中立,适配组件应累加方言特征。论文也指出,若模型已有偏见,允许负值可能更好。 - 正则化:引入正交性损失(鼓励
A和B的列/行正交)和稀疏性损失(惩罚γ分布的熵),旨在使适配方向多样化且选择性激活,增强可解释性。
- 非负门控:使用Softplus确保
论文中未提供模型整体的架构图,但通过文字和公式清晰地描述了GLoRIA在单个FF层内的工作机制。
💡 核心创新点
- 元数据门控的低秩适配:这是最核心的创新。不同于标准LoRA(固定的低秩更新)或简单的元数据拼接/嵌入,GLoRIA让地理坐标通过一个轻量级门控网络,动态生成一组非负权重,来调制多个低秩适配方向。这实现了基于连续元数据的、细粒度的、可解释的模型行为调制。
- 面向可解释性的正则化设计:通过显式的正交性和稀疏性损失,约束模型学得的适配方向(
A,B的列向量)彼此区分,并让门控网络(γ)为不同位置选择性激活少数方向。这为后续通过NMF等分析工具理解“模型如何根据位置调整自身”奠定了基础。 - 将参数高效适应与强可解释性结合:以往参数高效方法(如LoRA)主要追求效率与性能,可解释性较弱。GLoRIA在保持甚至提升参数效率(更新<10%参数)的同时,其门控机制和正则化使得适配模式具有明确的地理语义,可通过可视化直接分析,架起了高效适应与可解释性之间的桥梁。
🔬 细节详述
- 训练数据:
- 数据集:GCND语料库,包含411小时的自发荷兰方言语音(比利时、荷兰南部、法属佛兰德斯)。
- 预处理:重采样至16kHz,提取80维mel滤波器组特征加3个音高特征(25ms窗,10ms移位),拼接后进行语句归一化。
- 数据增强:训练时使用SpecAugment。
- 数据划分:9个方言区。录音≥50条的区域按80/10/10划分训练/验证/测试;录音<50条的区域不参与训练,仅取其10%数据用于测试。训练方言5个,仅测试方言4个(含过渡方言)。
- 损失函数:
总损失:
L_total = L_ASR + λ_orth L_orth + λ_sp * L_sp。L_ASR:ASR损失,对于字幕解码器为交叉熵损失(未使用CTC)。L_orth:正交性损失,||A^T A - I||_F^2 + ||B B^T - I||_F^2。L_sp:稀疏性损失,对归一化后的γ分布计算负熵,并除以log r进行归一化。- 权重:
λ_orth = 0.8,λ_sp = 5.0。
- 训练策略:
- 优化器:Adam,学习率0.001。
- 调度:WarmupLR,1500步预热。
- 梯度累积步长:128。
- 训练轮数:全微调/LoRA模型100个epoch,GLoRIA模型40个epoch。
- 初始化:新参数使用Xavier uniform初始化;gate-mlp初始化为零。
- 关键超参数:
- GLoRIA rank
r:主要报告128(表1),表2比较了32、64、128。 - 门控MLP:两层,隐藏层大小32,激活函数为GeLU(隐藏层)和Softplus(输出层)。
- 基础ASR模型:编码器为12层Conformer(d_model=512, d_ff=2048, 8头, Swish, 卷积核31),解码器为6层Transformer。
- 参数更新量:对于r=128,GLoRIA更新约10.0%的参数(表2)。
- GLoRIA rank
- 训练硬件:论文中未说明。
- 推理细节:论文中未明确说明解码策略(如beam search size)。
- 正则化技巧:如上所述的
L_orth和L_sp损失;基础模型训练使用了SpecAugment。
📊 实验结果
主要在GCND数据集上评估,指标为词错误率(WER%)。
表1:GLoRIA与多种基线模型的WER对比
| 描述 | 方言区 | 方言特定 (最佳) | 联合模型 | 坐标嵌入 | 修改前馈 | GLoRIA (rank=128) | OWSM V4-1B | Whisper Large-V3 | 预训练模型 | 测试数据量 |
|---|---|---|---|---|---|---|---|---|---|---|
| 见内方言 | Brabants | 30.02 | 28.67 | 28.70 | 27.44 | 27.10 | 78.32 | 71.69 | 56.52 | 7h 47m |
| Frans-Vlaams | 45.13 | 46.01 | 44.84 | 42.67 | 40.84 | 83.65 | 75.11 | 75.38 | 2h 34m | |
| Oost-Vlaams | 32.42 | 32.83 | 33.04 | 31.56 | 30.16 | 80.54 | 68.30 | 66.22 | 5h 03m | |
| Oost-Vlaams>Brabants | 35.89 | 32.65 | 33.21 | 31.98 | 30.28 | 75.34 | 68.04 | 64.51 | 3h 16m | |
| West-Vlaams | 29.53 | 28.61 | 29.17 | 27.36 | 26.70 | 76.25 | 62.91 | 58.95 | 8h 16m | |
| 见外方言 | Limburgs | 47.86 | 48.38 | 52.25 | 50.27 | 49.41 | 76.78 | 68.56 | 61.74 | 2h 44m |
| Limburgs>Brabants | 38.74 | 39.28 | 41.08 | 38.78 | 37.61 | 76.01 | 62.07 | 58.32 | 1h 42m | |
| Vlaams>Zeeuws | 41.96 | 37.60 | 41.55 | 38.52 | 37.17 | 75.43 | 61.37 | 58.69 | 2h 41m | |
| West-Vlaams>Oost-Vlaams | 36.52 | 34.01 | 35.10 | 32.60 | 32.09 | 83.61 | 71.60 | 66.37 | 2h 46m | |
| 平均 | 37.56 | 36.45 | 37.66 | 35.69 | 34.59 | 78.44 | 67.74 | 62.97 | – |
关键结论:GLoRIA在所有见内方言区和大部分见外方言区(3/4)都取得了最低的WER。平均WER比次优的“修改前馈”基线低约1.1个百分点,比标准LoRA(rank=128)低约5.77个百分点(见表2),并大幅领先于大规模通用模型(Whisper, OWSM)。这证明了其在性能上的优越性,尤其是在利用地理信息进行平滑适配方面。
表2:LoRA与GLoRIA在不同秩下的WER对比
| 方言区 | Rank 32 | Rank 64 | Rank 128 | |||
|---|---|---|---|---|---|---|
| LoRA | GLoRIA | LoRA | GLoRIA | LoRA | GLoRIA | |
| Brabants | 33.24 | 28.03 | 32.83 | 27.66 | 32.20 | 27.10 |
| Frans-Vlaams | 55.90 | 43.04 | 54.31 | 42.53 | 50.48 | 40.84 |
| Oost-Vlaams | 39.46 | 32.51 | 37.55 | 32.04 | 36.83 | 30.16 |
| Oost-Vlaams>Brabants | 39.06 | 32.91 | 37.63 | 32.13 | 36.66 | 30.28 |
| West-Vlaams | 35.18 | 27.70 | 34.48 | 27.40 | 32.46 | 26.70 |
| Limburgs | 52.45 | 54.19 | 52.14 | 49.51 | 52.42 | 49.41 |
| Limburgs>Brabants | 42.64 | 39.23 | 42.00 | 38.80 | 41.94 | 37.61 |
| Vlaams>Zeeuws | 42.52 | 38.99 | 42.39 | 38.25 | 41.19 | 37.17 |
| West-Vlaams>Oost-Vlaams | 41.93 | 34.12 | 40.52 | 33.89 | 39.03 | 32.09 |
| 平均 | 42.49 | 36.75 | 41.54 | 35.80 | 40.36 | 34.59 |
| 可训练参数比例 | 2.7% | 2.7% | 5.2% | 5.3% | 9.9% | 10.0% |
关键结论:在相同秩下,GLoRIA在几乎所有方言区都显著优于标准LoRA,平均WER降低约5.7个百分点。这证明了门控机制引入元数据对于捕捉方言变化的关键作用,而非仅���增加参数。
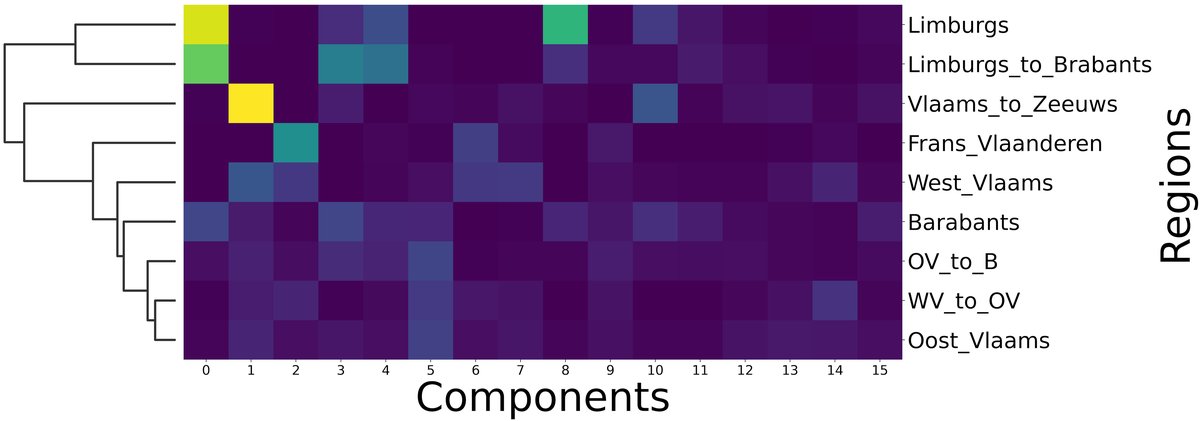
可解释性分析(图1与图2):
- 图1:展示了通过NMF从GLoRIA门控激活中提取的四个典型适配成分在地理空间上的激活强度分布图。每个成分的激活热区与已知的方言区(如Frans-Vlaams, Limburgs, Oost-Vlaams, Antwerp)高度吻合。这直观证明了GLoRIA学到的适配模式具有明确的地理语义。
- 图2:展示了16个NMF成分在9个方言区平均激活值的聚类热图。结果显示,地理和语言学上接近的区域具有相似的激活模式(聚类在一起),且每个区域通常由少数几个成分主导激活。

⚖️ 评分理由
- 学术质量:6.0/7。创新性体现在将元数据、门控机制和低秩适配进行巧妙结合,提出了一个新的适配范式。技术实现上公式推导清晰,损失函数设计合理,实验对比全面(包括不同方法、不同秩、见内见外方言)。主要不足在于对基座模型(CASAD)的公开性、训练细节未做充分说明,且未提供代码,这降低了完全独立复现的信心,扣0.5分;同时,核心创新虽好,但应用场景相对垂直,普适性有待进一步验证,扣0.5分。
- 选题价值:1.5/2。选题针对方言ASR这一实际挑战,价值明确。使用地理元数据解决方言连续变化问题思路新颖,其可解释性对语音处理、社会语言学研究都有参考价值。1.5分表示其问题重要、方法有效,但领域相对专门化。
- 开源与复现加成:0.5/1。论文提供了非常详细的模型配置、训练超参数(学习率、warmup、优化器、正则化权重)和实现框架(ESPnet),使得专业读者可以按照描述进行复现。扣分点在于未提供代码仓库、预训练模型权重或明确的数据获取方式,因此给予中等正向加分。