📄 GLA-GRAD++: An Improved Griffin-Lim Guided Diffusion Model for Speech Synthesis
#语音合成 #扩散模型 #领域适应
✅ 7.5/10 | 前25% | #语音合成 | #扩散模型 | #领域适应
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Teysir Baoueb(LTCI, T´el´ecom Paris, Institut polytechnique de Paris, France)
- 通讯作者:未说明
- 作者列表:Teysir Baoueb(LTCI, T´el´ecom Paris, Institut polytechnique de Paris, France)、Xiaoyu Bie(同上)、Mathieu Fontaine(同上)、Ga¨el Richard(同上)
💡 毒舌点评
这篇论文的亮点在于将经典的信号处理算法(Griffin-Lim)与前沿的生成模型(扩散模型)结合得干净利落,通过一个“简单但关键”的修改(在预测y0项上进行一次性校正)同时解决了速度和鲁棒性两个痛点,在out-of-domain测试集上的提升相当亮眼。短板在于实验对比的基线不够丰富(未与同期的一些快速扩散声码器如FreGrad、SWave等直接对比),且未开源代码和模型权重,对于宣称“零样本”的方法,其实用价值评估需要等待社区验证。
🔗 开源详情
- 代码:论文未提供代码仓库链接。仅提供了演示页面:https://gla-grad-plus-plus.github.io/。
- 模型权重:未提及公开模型权重。
- 数据集:使用的是公开标准数据集(LJSpeech, VCTK),论文未提及额外私有数据集。
- Demo:提供了在线演示页面:https://gla-grad-plus-plus.github.io/。
- 复现材料:给出了核心算法描述和关键实验参数(如GLA迭代次数、梅尔谱参数、扩散步数),但训练超参数(学习率、优化器等)、阶段切换的具体实现代码细节未提供。
- 论文中引用的开源项目:提到了WaveGrad [5]、HiFi-GAN [27]等作为基线或参考,但未明确列出本工作所依赖的开源代码库。
- 开源计划:论文中未明确提及未来开源计划。
📌 核心摘要
本文旨在解决基于扩散模型的声码器在条件梅尔频谱图与训练分布不匹配时性能下降且计算成本高的问题。其核心方法GLA-Grad++通过在扩散反向过程的早期,将神经网络预测的“干净语音”(预测y0)替换为从条件梅尔频谱图中通过一次Griffin-Lim算法(GLA)恢复的音频信号(˜x),来引导生成过程。与先前工作GLA-Grad(在多个扩散步骤中重复应用GLA)相比,本方法仅在扩散开始前应用一次GLA,显著加速了生成。实验表明,GLA-Grad++在感知语音质量(PESQ)和短时客观可懂度(STOI)上持续优于WaveGrad和GLA-Grad基线,尤其在未见过的说话人(VCTK数据集)场景下优势明显。例如,在VCTK上,GLA-Grad++的PESQ得分(3.772)相比WaveGrad(3.453)提升了约9.2%。该工作的实际意义在于为扩散声码器提供了一种无需重新训练、即插即用的增强方案,能有效提升合成语音在跨领域场景下的稳定性和质量。其主要局限性是方法性能(尤其是阶段切换点)对单个音频文件可能存在依赖性,论文建议未来可自适应选择最佳切换点。
🏗️ 模型架构
GLA-Grad++是一个针对扩散声码器(如WaveGrad)的推理阶段增强框架,而非一个独立的端到端模型。其整体架构可分为两个串联的阶段:
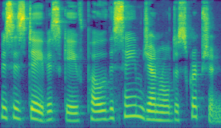 图1:GLA-Grad++ 总体框架图。Stage 1:校正步骤(上部):在开始扩散过程之前,从条件梅尔频谱图出发,首先应用梅尔滤波器组伪逆得到幅度谱,然后通过Griffin-Lim算法(GLA)进行相位恢复,最后通过iSTFT得到一个估计的时域音频信号˜x。Stage 2:“经典”扩散步骤(下部):从随机噪声开始执行标准的扩散反向过程。关键修改在于,在Stage 2的早期扩散步骤(步骤1至n)中,更新公式(公式9)中的第一项(预测y0项)被替换为Stage 1生成的˜x;当扩散过程进行到后续步骤(步骤n+1至T)时,则切换回标准的WaveGrad更新公式(公式5/8)。
图1:GLA-Grad++ 总体框架图。Stage 1:校正步骤(上部):在开始扩散过程之前,从条件梅尔频谱图出发,首先应用梅尔滤波器组伪逆得到幅度谱,然后通过Griffin-Lim算法(GLA)进行相位恢复,最后通过iSTFT得到一个估计的时域音频信号˜x。Stage 2:“经典”扩散步骤(下部):从随机噪声开始执行标准的扩散反向过程。关键修改在于,在Stage 2的早期扩散步骤(步骤1至n)中,更新公式(公式9)中的第一项(预测y0项)被替换为Stage 1生成的˜x;当扩散过程进行到后续步骤(步骤n+1至T)时,则切换回标准的WaveGrad更新公式(公式5/8)。
输入:条件梅尔频谱图 ˜X。 输出:生成的波形 y0。
核心组件:
- 幅度谱估计:使用梅尔滤波器组B的伪逆B+将梅尔频谱图 ˜X 反变换为全频带幅度谱估计 ̂X。
- 相位恢复(GLA):使用快速GLA算法(迭代32次),以随机相位初始化,从估计的幅度谱 ̂X 恢复相位,最终通过iSTFT得到校正信号˜x。
- 扩散去噪器:复用已训练好的WaveGrad模型(或其他基于DDPM的声码器),其网络 ϵθ 预测噪声。
- 条件引导机制:在扩散反向步骤中,将经典的“预测y0”项替换为校正信号˜x,以提供更准确的干净信号估计,从而引导扩散过程朝向与条件频谱图更一致的结果。
数据流与交互:条件梅尔频谱图首先被处理生成校正信号˜x。在扩散反向的前n步,每步的噪声预测 ϵθ(yt, ˜X, √¯αt) 被计算,但最终的波形更新公式使用˜x而非由yt计算出的预测y0。这相当于在扩散早期,用一个来自信号处理方法的、全局一致的“锚点”替代了可能不准确的神经网络预测。n步之后,模型完全交由神经网络自主完成去噪。
💡 核心创新点
- 单一GLA校正:相比于其前身GLA-Grad在扩散早期多个步骤中反复应用GLA(需从当前噪声估计yt初始化),本方法仅在扩散开始前一次性应用GLA,用随机相位初始化。这大幅降低了计算开销(GLA计算量减少),同时保持了引导效果,因为早期扩散步骤中相位信息本身不可靠。
- 对预测y0的替换而非整体迭代yt:在早期扩散步骤中,本方法仅替换更新公式中的“预测y0”项,而保留了指向当前噪声估计yt的“方向项”和随机噪声项。这比直接替换整个迭代yt(如GLA-Grad的做法)在理论上更合理,因为˜x和预测y0具有相同的语义(都是干净语音估计),且保留了扩散过程本身的随机性和方向性。
- 分阶段引导策略:明确提出了将扩散过程分为“校正引导阶段”和“纯扩散阶段”的两段式推理,并通过实验分析了阶段切换点(即第一个阶段包含的步数n)对性能的影响,发现不同的n值对不同指标(PESQ, WARP-Q)和不同数据集有不同影响,为实际应用提供了指导。
🔬 细节详述
- 训练数据:
- LJSpeech:单说话人英语数据集,采样率22050 Hz,约24小时。训练/测试集划分遵循HiFi-GAN协议:12950 clips训练,150 clips测试。
- VCTK v0.92:多说话人英语数据集,110个说话人,约41小时,原始采样率48 kHz,被下采样至24 kHz。使用与[29]相同的10个说话人作为测试集,其余用于训练。
- 损失函数:论文未详细说明GLA-Grad++本身的训练损失。论文指出其使用已训练好的WaveGrad模型,并提及WaveGrad使用L1范数的损失(公式4的变体)。GLA-Grad++本身是一种推理时方法,不涉及新的训练损失。
- 训练策略:未提供GLA-Grad++的独立训练策略。对于基线WaveGrad模型,训练了1M步。优化器、学习率等关键训练超参数未说明。
- 关键超参数:
- 梅尔频谱图参数:nfft=2048,汉明窗长度1200,hop size 300,nmels=128。
- GLA:采用Fast GLA,迭代次数为32次,相位随机初始化。
- 扩散过程:使用WG-6噪声调度(6步扩散),采用DDPM σ(公式8中的σt)。每个阶段(校正阶段和扩散阶段)默认步数为3(即n=3)。
- 训练硬件:论文未提供训练模型所使用的GPU型号和训练时长,仅提到使用了IDRIS的HPC资源进行实验。
- 推理细节:
- 解码策略:两阶段推理,如图1和公式9所示。
- 阶段切换:默认在校正3步后切换。论文实验(5.4节)探索了不同的切换点(从0到6步)。
- 批处理速度:在单卡NVIDIA V100上,处理100个1秒音频文件,GLA-Grad++的推理速度为37.80倍实时(LJSpeech)和35.43倍实时(VCTK)。
- 正则化或稳定训练技巧:未说明。
📊 实验结果
Oracle实验(验证理论上限)
方法 数据集 PESQ (↑) STOI (↑) WARP-Q (↓) WaveGrad LJSpeech 3.598 ± 0.127 0.970 ± 0.005 1.665 ± 0.078 Oracle Spec LJSpeech 3.892 ± 0.113 0.978 ± 0.004 1.684 ± 0.074 Oracle Phase LJSpeech 4.040 ± 0.103 0.987 ± 0.003 1.587 ± 0.082 WaveGrad VCTK 3.453 ± 0.325 0.907 ± 0.055 1.439 ± 0.100 Oracle Spec VCTK 3.866 ± 0.219 0.921 ± 0.056 1.433 ± 0.099 Oracle Phase VCTK 4.041 ± 0.238 0.927 ± 0.057 1.340 ± 0.104 结论:提供真实相位比提供真实幅度谱对生成质量的提升更显著,证实了使用更准确的预测y0(即˜x)的价值。 主要方法对比
方法 数据集 PESQ (↑) STOI (↑) WARP-Q (↓) WaveGrad LJSpeech 3.598 ± 0.127 0.970 ± 0.005 1.665 ± 0.078 GLA-Grad LJSpeech 3.460 ± 0.112 0.963 ± 0.005 1.677 ± 0.076 GLA-Grad++ LJSpeech 3.807 ± 0.115 0.974 ± 0.004 1.694 ± 0.079 WaveGrad VCTK 3.453 ± 0.325 0.907 ± 0.055 1.439 ± 0.100 GLA-Grad VCTK 2.024 ± 0.189 0.858 ± 0.087 1.758 ± 0.163 GLA-Grad++ VCTK 3.772 ± 0.228 0.917 ± 0.057 1.443 ± 0.098 结论:GLA-Grad++在PESQ和STOI上全面优于WaveGrad和GLA-Grad,尤其在VCTK(多说话人,更接近out-of-domain)上提升巨大。WARP-Q指标上结果相当。论文指出GLA-Grad在VCTK上结果与先前文献不同源于训练设置差异。 时间复杂度
方法 LJSpeech (倍实时) VCTK (倍实时) WaveGrad 42.02 39.53 GLA-Grad 32.98 31.25 GLA-Grad++ 37.80 35.43 结论:GLA-Grad++推理速度快于GLA-Grad(因仅应用一次GLA),略慢于原始WaveGrad(增加了GLA计算开销),但整体维持高效推理。 消融实验:Stage 1的结束时间步影响
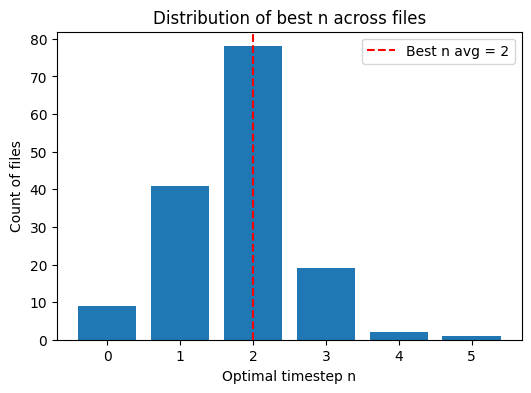 图2:LJSpeech数据集上,针对PESQ指标,每个测试文件的最佳Stage 1结束时间步直方图。
图2:LJSpeech数据集上,针对PESQ指标,每个测试文件的最佳Stage 1结束时间步直方图。
- LJSpeech结果:结束时间步为2时PESQ最高(3.892),为0(即纯GLA)时WARP-Q最优(1.182)。
- VCTK结果:结束时间步为2时PESQ最高(3.830),为0时WARP-Q最优(1.082)。
- 文件级分析(图2):对于PESQ,全局最优步长(3)对约一半文件也是最优的,但存在个体差异。时间步6(即纯WaveGrad)未在任何文件上达到最佳PESQ,表明引导总是有益的。 结论:阶段切换点的选择对性能有影响,存在一个折中区域(约2-3步)能较好地平衡不同指标。
⚖️ 评分理由
- 学术质量:5.5/7:论文动机明确,方法设计有清晰的技术逻辑和创新点(单一GLA、y0替换),实验设计全面(包含Oracle验证、主实验、速度分析、消融研究),数据充分,结论可靠。但其核心贡献是对现有框架的改进,而非开创一个新范式,且实验中未与更多同期快速扩散模型基线对比,深度略有不足。
- 选题价值:1.5/2:解决扩散声码器在实际部署中的关键瓶颈(速度与鲁棒性),尤其是在跨说话人/领域场景下,具有明确的应用价值和市场需求。研究方向处于活跃期,相关性强。
- 开源与复现加成:0.5/1:提供了demo页面,增强了结果的可信度。然而,未公开核心代码、训练好的模型权重及详细训练配置,这限制了方法的直接应用和公平比较,对复现造成了实质性障碍。