📄 Gelina: Unified Speech and Gesture Synthesis Via Interleaved Token Prediction
#语音合成 #手势生成 #自回归模型 #流匹配 #多模态模型
✅ 7.0/10 | 前50% | #语音合成 | #自回归模型 | #手势生成 #流匹配
学术质量 6.5/7 | 选题价值 2.0/2 | 复现加成 -0.5 | 置信度 中
👥 作者与机构
- 第一作者:Téo Guichoux(ISIR, Sorbonne Université;STMS Lab – IRCAM, Sorbonne Université)
- 通讯作者:未说明
- 作者列表:Téo Guichoux(ISIR, Sorbonne Université;STMS Lab – IRCAM, Sorbonne Université), Théodor Lemerle(STMS Lab – IRCAM, Sorbonne Université), Shivam Mehta(KTH皇家理工学院), Jonas Beskow(KTH皇家理工学院), Gustav Eje Henter(KTH皇家理工学院), Laure Soulier(ISIR, Sorbonne Université), Catherine Pelachaud(ISIR, Sorbonne Université;CNRS), Nicolas Obin(STMS Lab – IRCAM, Sorbonne Université)
💡 毒舌点评
这篇论文的亮点在于其“交错token预测”的架构设计直觉上非常优雅,为多模态序列建模提供了一个统一且时序对齐的方案,并在同步性上取得了可观的实验结果。然而,其最大的短板在于“统一”的代价——它在语音生成质量上显著落后于最新的纯语音SOTA(如CosyVoice-2),在手势丰富度(如手指)上也进行了简化,这使其宣称的“统一”和“竞争”显得有些取舍过重,更像是一次有潜力的概念验证而非成熟的系统性方案。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及公开权重。
- 数据集:论文中使用的BEAT2、GigaSpeech、LibriTTS等均为公开数据集,但论文本身未提供新数据集。
- Demo:提供了在线演示链接:https://TGuichoux.github.io/。
- 复现材料:论文给出了详细的训练配置(数据集、学习率、批大小、GPU型号/数量、训练步数),为复现提供了重要信息,但缺少完整的超参数配置文件或代码。
- 论文中引用的开源项目:WavTokenizer [21], Encodec [20], Whisper-large-v3 [29], Matcha-TTS [18], Lina-Speech [6], EMAGE [8], CAMN [9], RAG-Gesture [32]。
- 总结:论文公开了演示和详细的技术细节,但未提供核心的开源代码和模型,因此复现门槛较高。
📌 核心摘要
- 问题:当前生成语音和伴随手势的多模态系统大多采用级联(先语音后手势)的方式,导致两者同步性弱、韵律对齐不足,且不符合人类通信中多模态协同产生的心理语言学原理。
- 方法:提出Gelina,一个统一的自回归框架。该框架将文本映射到交错排列的语音和手势离散token序列中进行联合预测。具体地,它使用预训练的文本-语音数据集进行预训练,然后在配对的语音-手势-文本数据集上微调。手势token随后通过一个条件流匹配解码器还原为连续的运动序列。
- 创新:① 首次提出交错token自回归架构,用于联合建模语音和手势,在单一序列中自然地对齐时间步;② 提出一种利用大规模单模态数据(文本-语音)预训练的策略,以缓解配对多模态数据稀缺的问题;③ 支持灵活的输入/输出模式,包括文本生成语音+手势、基于语音提示生成手势,以及通过序列续写实现语音和手势风格的联合克隆,无需显式的说话人嵌入。
- 结果:在BEAT2数据集上,Gelina克隆模型在手势分布匹配度(FGD-B=0.0839)上优于CAMN和EMAGE基线;在语音自然度(NMOS)和说话人相似度上与同等规模的单模态TTS(Lina-Speech)相当或略优,但落后于强大的CosyVoice-2(WER: 9.2% vs 3.5%)。用户研究(96人)显示,其语音自然度得分显著高于Lina-Speech,手势自然度和同步性得分与专用手势生成模型RAG-Gesture相当,且显著高于EMAGE和CAMN。关键实验数据见下表:
模型 FGD-B ↓ BC ∼ Div. ∼ WER ↓ NMOS ↑ SS (x100) Human 0.0 0.684 4.14 6.5 ±.54 3.72 ±.04 69.1 EMAGE 0.1679 0.766 3.92 - - - RAG 0.1781 0.700 5.13 - - - Gelina Clon. 0.0839 0.738 3.15 9.2 ±.84 3.21 ±.04 61.3 Lina-Speech - - - 10.9 ±.9 2.98 ±.05 60.1 CosyVoice-2 - - - 3.5 ±.5 3.70 ±.04 63.9 - 意义:验证了在统一框架内联合生成语音和手势的可行性,且能获得具有竞争力的同步性和自然度,为具身对话智能体提供了更自然的多模态生成思路。
- 局限:目前仅建模身体姿态,未包含手指和面部表情;语音质量受限于离散化tokenizer(WavTokenizer)的瓶颈;计算效率(RTF 1.47)低于专用单模态模型。
🏗️ 模型架构
Gelina是一个分阶段的多模态生成系统,其核心流程如下:
整体流程: 输入为文本(可选加上用于克隆的语音-手势提示)。文本经BPE分词后,送入自回归(AR)骨干网络。AR骨干网络以自回归的方式预测一个交错排列的语音token序列和手势token序列。预测出的语音token直接送入WavTokenizer的解码器生成语音波形。预测出的手势token则送入一个条件流匹配解码器,结合AR骨干网络的中间嵌入,生成最终的连续手势运动序列(SMPL-X格式)。
主要组件与数据流:
- 分词器(Tokenizers):
- 文本:标准BPE分词器。
- 语音:使用WavTokenizer,将24kHz音频以75Hz的速率转换为离散token(码本大小4096)。
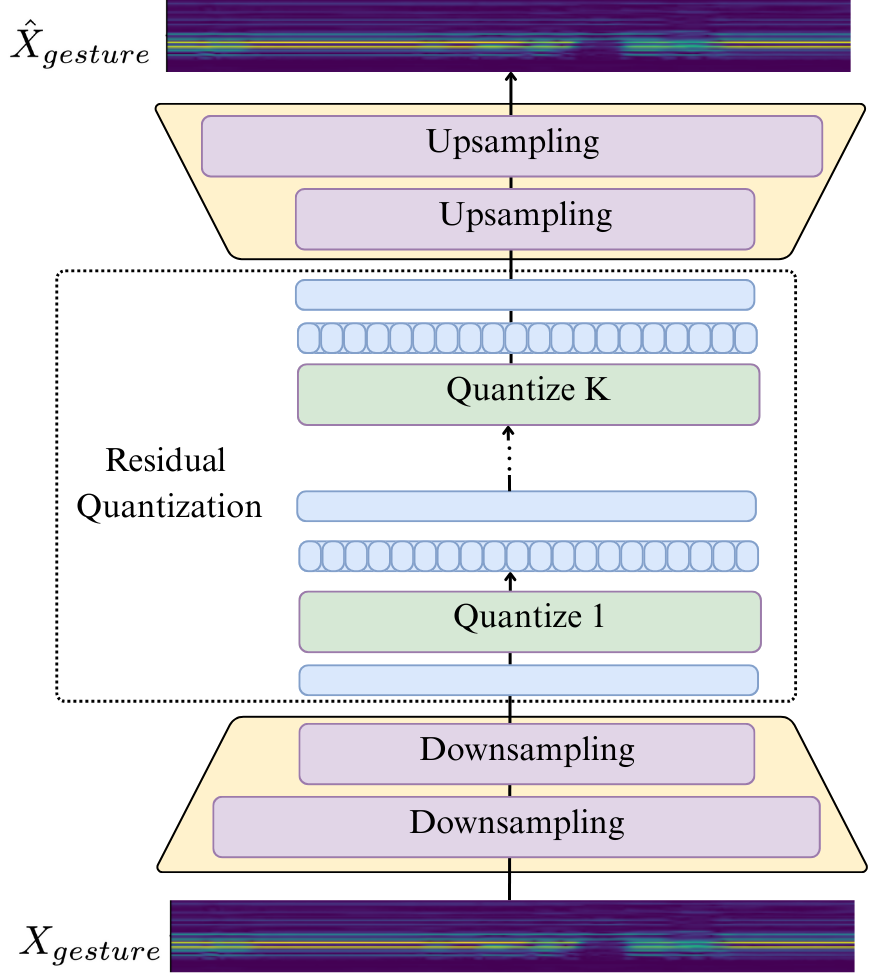
- 手势:训练了一个RVQ-VAE,将20fps的SMPL-X运动序列下采样并量化为5Hz的离散token(6层RVQ,每层码本大小512)。为稳定训练,实际只使用第一层token(码本大小512)。
- 自回归骨干网络(Autoregressive Backbone):
- 基于Lina-Speech架构,是一个编码器-解码器Transformer,采用线性注意力以提高效率。
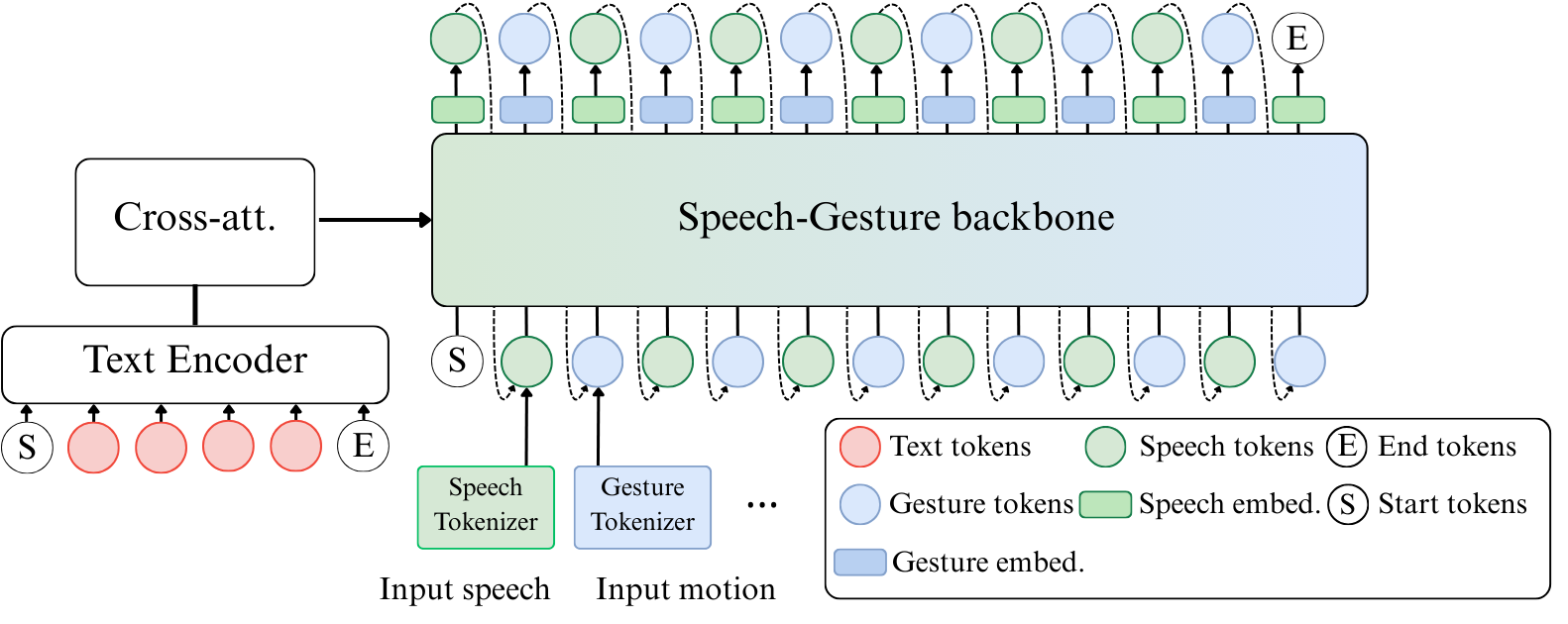
- 关键创新:交错Token预测。在AR序列中,每预测15个语音token后,会预测1个手势token。这对应了语音(75Hz)和手势(5Hz)的编码速率比(15:1)。这种设计强制模型在生成语音的同时,在时间轴上对齐生成手势。
- 模型为语音和手势维护了独立的输入嵌入层和输出投影层。
- AR骨干网络的隐藏层维度为1024,参数量约168M(6层文本编码器,12层因果解码器)。
- 条件流匹配手势解码器(Conditional Flow-Matching Decoder):
- 解决直接使用RVQ-VAE解码器质量不佳的问题,并利用AR骨干网络融合了多模态信息的语义更丰富的嵌入空间。
- 架构是一个基于Matcha-TTS的1D卷积-Transformer U-Net,参数量约11.5M。
- 它接收AR骨干网络的嵌入作为条件
c,学习从噪声手势xt到干净手势x0的向量场。 - 训练损失包含三项:流匹配目标
L_FM、速度一致性损失L_vel(鼓励运动连续性)和关节旋转的测地距离损失L_geo(确保旋转的合理性)。 - 推理时通过100步采样生成手势。
架构图示:
论文图1(pdf-image-page3-idx0)展示了手势分词器(RVQ-VAE)的结构,图pdf-image-page3-idx1展示了交错的自回归骨干网络,图pdf-image-page3-idx2展示了条件流匹配手势解码器。
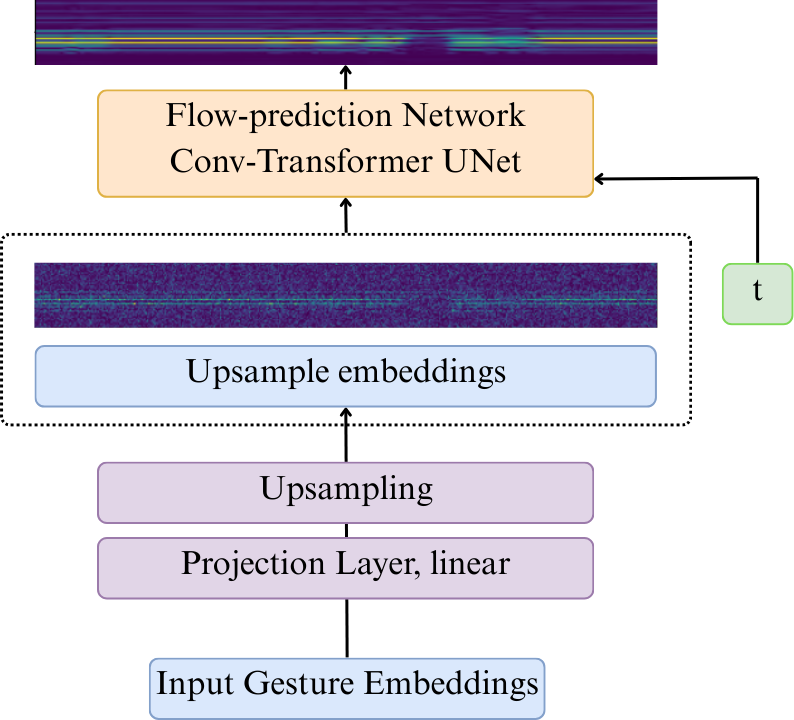 该图详细描述了手势分词器的训练和推理过程,展示了多层残差向量量化的结构。
该图详细描述了手势分词器的训练和推理过程,展示了多层残差向量量化的结构。
 该图核心展示了交错的token序列(蓝-语音,红-手势),以及文本编码器、自回归解码器和跨模态对齐的结构。
该图核心展示了交错的token序列(蓝-语音,红-手势),以及文本编码器、自回归解码器和跨模态对齐的结构。
 该图展示了解码器如何从AR骨干获取条件信息,并通过一个基于Transformer的U-Net从噪声中逐步恢复手势信号。
该图展示了解码器如何从AR骨干获取条件信息,并通过一个基于Transformer的U-Net从噪声中逐步恢复手势信号。
💡 核心创新点
交错Token预测的统一自回归架构:
- 之前局限:以往的语音-手势联合生成模型(如Diff-TTSG, Match-TTSG)多采用级联或并行扩散头设计,模态间耦合较弱,或依赖外部对齐。
- 如何起作用:将语音和手势token在同一个自回归序列中交错排列,模型在预测下一个语音token或手势token时,都能感知到两种模态的历史上下文,从而在序列层面实现了严格的同步对齐。
- 收益:无需外部对齐机制,实现了端到端的同步生成。用户研究证实其生成的语音-手势同步性得分与专用模型RAG-Gesture无显著差异。
利用单模态数据的两阶段预训练策略:
- 之前局限:大规模配对的语音-手势-文本数据稀缺,直接训练多模态模型受限。
- 如何起作用:第一阶段,在纯文本-语音的大规模数据集(GigaSpeech等)上预训练AR骨干网络,此时手势位置填入随机token但不计算损失。这使模型先学会了强大的文本到语音的对齐能力。第二阶段,仅在小规模配对数据(BEAT2)上微调,此时随机手势token被替换为真实token,模型开始学习语音与手势的联合分布。
- 收益:有效利用了丰富的单模态数据,缓解了数据稀缺问题,使模型具备了强大的基础文本到语音能力,并在此基础上学习多模态生成。
基于序列续写的多模态风格克隆:
- 之前局限:许多模型依赖于固定的说话人嵌入来支持多说话人,这限制了其在训练时未见过的新说话人上的泛化,且难以同时克隆语音和手势风格。
- 如何起作用:Gelina支持以“文本 + 一段语音-手势对”作为提示(prompt),通过自回归序列续写的方式,生成与提示在声音和肢体风格上相似的新内容。这是一种隐式的、基于上下文的克隆。
- 收益:无需显式设计说话人嵌入模块,即可实现语音和手势风格的联合克隆,实验表明克隆模式(Gelina Clon.)在多项指标上优于基础模型。
🔬 细节详述
- 训练数据:
- 预训练:GigaSpeech, LibriTTS, MLS-10k,总计约18190小时文本-语音数据。
- 微调/评估:BEAT2数据集,包含对齐的语音、手势和文本。原始转录被Whisper-large-v3重新生成。手势为SMPL-X全身序列(55关节,转为Rot6D+平移+脚接触),实验中移除了手指关节。
- 损失函数:
- AR骨干:标准的下一token预测交叉熵损失(在微调阶段包含语音和手势token)。
流匹配解码器:
L = L_FM + λ_vel L_vel + λ_geo * L_geo。其中λ_vel=0.05,λ_geo=0.8。L_vel约束预测向量场与真实运动速度的一致性;L_geo约束预测旋转与真实旋转在SO(3)流形上的距离。
- AR骨干:标准的下一token预测交叉熵损失(在微调阶段包含语音和手势token)。
流匹配解码器:
- 训练策略:
- 预训练:100k步,学习率 2e-4,批量大小 60k tokens,4xH100 GPU。
- 微调:5k步,学习率 5e-5,批量大小 15k tokens,1xH100 GPU。
- 手势流匹配解码器:300k步,3xH100 GPU。
- 手势分词器(RVQ-VAE):90k步,1xA6000 GPU。
- 关键超参数:AR骨干维度1024,文本编码器6层,解码器12层。语音码本4096,手势码本512(实际只用第一层)。流匹配解码器推理采样步数100。
- 训练硬件:预训练使用4xH100,微调使用1xH100,流匹配解码器训练使用3xH100。
- 推理细节:AR生成采用自回归采样(论文未指定具体解码策略,如温度或beam search)。流匹配解码器采用确定性Euler采样,步数100。运行时分析在A5000上完成,Gelina的RTF为1.47。
- 正则化��稳定训练技巧:为稳定AR训练,丢弃了手势的RVQ残差层(仅用第一层token),依赖流匹配解码器恢复细节。这是一个关键的设计选择。
📊 实验结果
主要对比实验:在BEAT2数据集上,与多个单模态手势生成基线(CAMN, EMAGE, RAG-Gesture)和单模态语音合成基线(Lina-Speech, CosyVoice-2)进行对比。
核心客观指标表格(已在核心摘要中提供,此处重复以确保清晰):
| 模型 | FGD-B ↓ | BC ∼ | Div. ∼ | WER ↓ | NMOS ↑ | SS (x100) |
|---|---|---|---|---|---|---|
| Human | 0.0 | 0.684 | 4.14 | 6.5 ±.54 | 3.72 ±.04 | 69.1 |
| Tokenizers | 0.0118 | 0.667 | 3.91 | 11.03 ±.7 | 3.19 ±.04 | 66.8 |
| CAMN | 0.1097 | 0.551 | 2.96 | - | - | - |
| EMAGE | 0.1679 | 0.766 | 3.92 | - | - | - |
| RAG | 0.1781 | 0.700 | 5.13 | - | - | - |
| Gelina | 0.2310 | 0.744 | 3.20 | 11.3 ±1.0 | 2.96 ±.04 | - |
| Gelina Clon. | 0.0839 | 0.738 | 3.15 | 9.2 ±.84 | 3.21 ±.04 | 61.3 |
| Gelina S2G | 0.1950 | 0.768 | 4.03 | - | - | - |
| Gelina w/o Flow | 0.6107 | 0.824 | 4.28 | 9.2 ±.84 | 3.21 ±.04 | 61.3 |
| Lina-Speech | - | - | - | 10.9 ±.9 | 2.98 ±.05 | 60.1 |
| CosyVoice-2 | - | - | - | 3.5 ±.5 | 3.70 ±.04 | 63.9 |
关键发现:
- 手势生成:Gelina克隆模型(Gelina Clon.)的FGD-B(0.0839)显著优于所有手势基线(CAMN: 0.1097, EMAGE: 0.1679, RAG: 0.1781),表明生成的手势分布最接近真实人类。在节拍一致性(BC)和多样性(Div.)上与基线具有竞争力。
- 语音生成:Gelina克隆模型的WER(9.2%)和NMOS(3.21)略优于同等规模的Lina-Speech(WER 10.9%, NMOS 2.98),但远逊于使用更大模型和数据的CosyVoice-2(WER 3.5%, NMOS 3.70)。
- 消融实验:“Gelina w/o Flow”(直接用RVQ-VAE解码手势)的FGD-B急剧恶化至0.6107,证明了条件流匹配解码器的关键作用。
- 用户研究(图2,
pdf-image-page4-idx3):96名参与者评分显示,在语音自然度上,Gelina Clon.显著高于Lina-Speech(3.21 vs 2.98),与CosyVoice-2(3.70)有差距但更接近;在手势自然度和同步性上,Gelina与RAG-Gesture表现最佳且无显著差异,均显著优于EMAGE和CAMN。
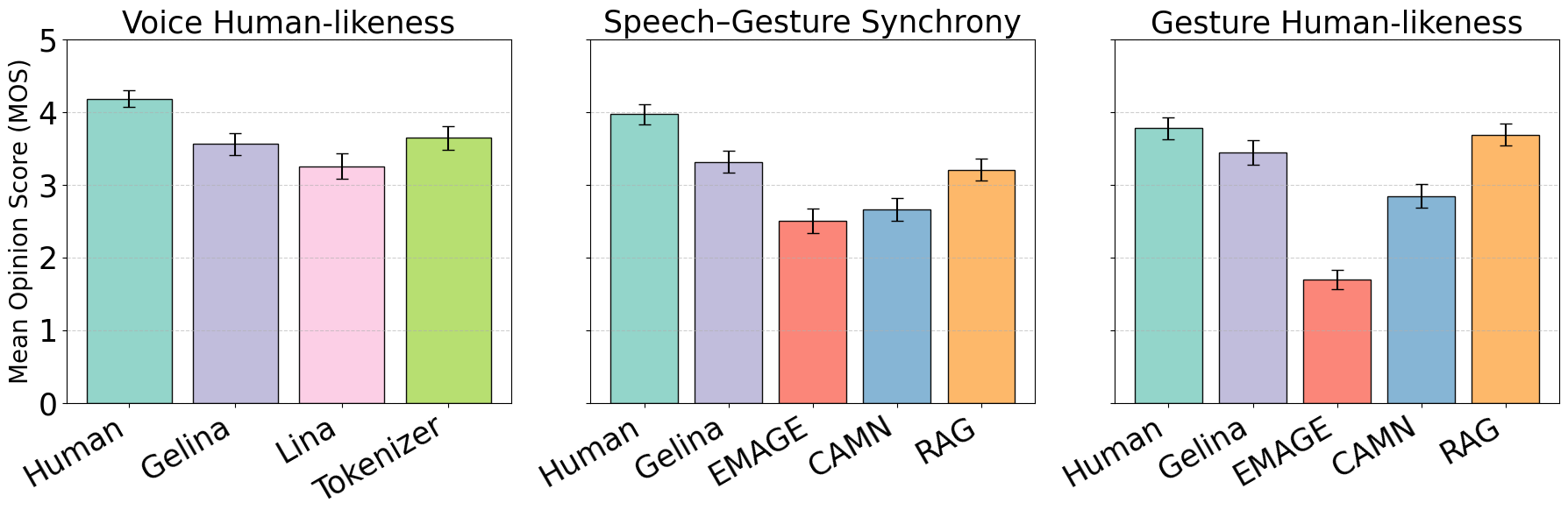 该图展示了用户研究在语音自然度、手势自然度和音视频同步性三个方面的平均分及95%置信区间。Gelina在各项中均表现靠前。
该图展示了用户研究在语音自然度、手势自然度和音视频同步性三个方面的平均分及95%置信区间。Gelina在各项中均表现靠前。
⚖️ 评分理由
- 学术质量:6.0/7:提出了有新意的交错token预测架构和两阶段训练策略,解决了多模态生成中的对齐和数据稀缺问题。实验全面,进行了客观指标和大规模用户研究对比。但技术深度受限于手势建模的简化(无手指)和语音质量未达到SOTA,创新更多是架构层面的组合而非基础性突破。
- 选题价值:1.5/2:研究方向(统一语音-手势生成)具有重要前沿意义,是通往更自然人机交互的关键步骤。应用潜力明确,但相较于通用语音合成,任务领域相对较窄。
- 开源与复现加成:-0.5/1:论文提供了演示页面,描述了关键训练细节,但未提供代码、模型权重或训练脚本,使得完全复现其工作(尤其是预训练阶段)存在较大障碍。