📄 Gdiffuse: Diffusion-Based Speech Enhancement with Noise Model Guidance
#语音增强 #扩散模型 #领域适应 #鲁棒性
✅ 7.0/10 | 前25% | #语音增强 | #扩散模型 | #领域适应 #鲁棒性
学术质量 7.0/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 中
👥 作者与机构
- 第一作者:Efrayim Yanir(特拉维夫大学)
- 通讯作者:未说明
- 作者列表:Efrayim Yanir(特拉维夫大学)、David Burshtein(特拉维夫大学)、Sharon Gannot(巴伊兰大学)
💡 毒舌点评
论文巧妙地将一个庞大的语音生成扩散模型“冻结”起来,仅用一个172参数的噪声模型通过测试时训练进行“遥控”,实现了对新噪声的灵活适应,这个“四两拨千斤”的思路确实新颖。然而,论文声称“噪声统计在训练和推理间保持稳定”是核心假设,但仅用20秒噪声片段训练就断言其统计特性稳定可靠,这个前提在复杂多变的现实声学环境中显得有些理想化,可能成为其实用性的阿喀琉斯之踵。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:论文中未提及公开的预训练权重链接。文中提到使用UnDiff项目预训练的DiffWave,但未给出其具体获取方式。
- 数据集:训练和测试使用了LibriSpeech(公开)和BBC Sound Effects Archive(公开)。但论文未提供其处理后的具体数据划分或下载脚本。
- Demo:论文提供了一个示例网站链接:https://ephiephi.github.io/GDiffuSE-examples.github.io,可能包含音频示例。
- 复现材料:论文描述了噪声模型的具体架构(WaveNet风格CNN,参数细节)、指导调度公式(11)及超参数(γ, λ_max),以及训练轮数的大致范围,提供了一定的复现基础。但优化器学习率、噪声样本的具体处理方式等细节未充分说明。
- 引用的开源项目:提到了UnDiff [15](用于获取预训练DiffWave)和WaveNet [20](噪声模型架构的灵感来源)。
- 开源计划:论文中未提及明确的后续开源计划。
📌 核心摘要
- 问题:传统判别式语音增强模型在匹配条件下表现好,但面对未见过的噪声类型时泛化能力差,易产生伪影。现有的生成式(特别是基于扩散的)语音增强方法虽然性能优越,但往往需要为每种预期噪声专门训练庞大的模型,适应性差且成本高。
- 方法核心:提出GDiffuSE,一个基于去噪扩散概率模型(DDPM)的语音增强框架。其核心是利用一个极轻量(172参数)的噪声模型,在测试时通过少量目标噪声样本进行快速训练。在扩散模型的反向生成过程中,利用该噪声模型的似然函数梯度作为“指导信号”,引导一个预训练的、冻结的语音生成扩散模型(DiffWave)生成干净语音。
- 新意:与现有方法(如直接条件扩散或需重训大模型)不同,GDiffuSE首次将DDPM引导机制与测试时训练相结合,并专门针对语音增强设计了噪声模型指导策略。它解耦了通用语音先验学习和特定噪声适应,使系统能快速适应新噪声。
- 实验:在LibriSpeech干净语音与BBC音效库噪声混合的数据上进行评估。结果表明,在失配噪声条件下(特别是高频噪声),GDiffuSE在PESQ和SI-SDR指标上持续优于基线方法SGMSE(在WSJ0和TIMIT上训练)和CDiffuSE。例如,在5dB SNR下针对高频噪声,GDiffuSE的SI-SDR为11.25±3.21,而sgmseWSJ0为9.43±2.64,CDiffuSE为3.66±3.23。频谱图也显示其抑制噪声更有效。
- 实际意义:提供了一种快速、低成本地将强大语音生成模型适应到新噪声环境的可能方案,降低了先进语音增强技术的部署门槛。
- 主要局限性:核心假设——训练噪声样本与推理时噪声统计一致——在现实中可能不总是成立;实验对比基线相对有限;未充分探讨当噪声统计发生显著变化时模型的失效模式;训练噪声片段(20秒)的充分性有待更全面验证。
🏗️ 模型架构
GDiffuSE系统包含两个主要组件,在训练和推理阶段协同工作,如图1所示。
组件一:预训练的扩散模型(DiffWave,参数θ)
- 功能:作为语音先验的“生成引擎”,在干净语音上训练,学习从高斯噪声逐步去噪生成语音的逆过程。
- 内部结构:论文采用UnDiff项目中预训练的无条件DiffWave模型,具有200个扩散步骤,在VCTK和LJ-Speech数据集上训练。它是一个基于WaveNet的去噪网络εθ(xt, t),用于预测每一步的噪声。
- 状态:在整个GDiffuSE流程中,该模型的参数保持冻结,不更新。
组件二:噪声模型(参数ϕt)
- 功能:学习特定噪声类型的统计模型,在扩散过程中提供指导信号。
- 内部结构:一个极其轻量级的因果卷积神经网络(CNN)。它由4层因果卷积层组成,采用残差连接和权重归一化。每层使用tanh-sigmoid门控机制(WaveNet风格)。网络最终输出高斯分布的均值μt,i和方差σ²t,i。每个扩散步t有独立的噪声模型ϕt。
- 内部结构(细节):内核大小为9,通道数为2,膨胀率设置为[1, 2, 4, 8]。总参数量仅172个。
数据流与交互(推理阶段 - Algorithm 2):
- 初始化:从纯高斯噪声xT ~ N(0, I)开始。
- 迭代去噪(t = T → 1): a. 基础预测:将当前带噪样本xt输入冻结的扩散模型,计算基础均值μθ(xt, t)。 b. 噪声估计:利用观测值y和基础预测,估计当前步的“组合噪声”vt = y - (1/√αt) * μθ(xt, t)。 c. 指导计算:将vt输入当前步的噪声模型ϕt,得到其对数似然函数的梯度∇vt log pϕt(vt)。 d. 引导均值:利用该梯度对基础均值进行校正:μguid_t = μθ(xt, t) + s_t (βt/√αt) (-1/√αt) * ∇vt loss_t(vt)。其中s_t是随时间衰减的指导强度。 e. 采样:从以μguid_t为均值、σ²_tI为方差的高斯分布中采样,得到xt-1。
- 输出:最终迭代得到x0,即增强后的语音估计。
关键设计选择与动机:
- 冻结大模型+训练小模型:动机在于语音的分布(干净语音)是相对通用的先验,而噪声分布多变但通常结构较简单。因此,用一个在大规模干净语音上预训练的大模型捕获通用语音结构,再用一个极小的模型快速学习特定噪声,是高效且合理的。
- 测试时训练噪声模型:动机在于为每种噪声重训大模型不切实际。而仅用少量噪声样本训练一个小模型则快速可行,实现了对新噪声的“即插即用”适应。
- 指导强度调度s_t:动机是在早期(高噪声、低SNR)步骤施加强引导以快速定位到干净语音的大致区域,在后期(高SNR)步骤减弱引导,让大模型自由生成语音细节,避免过度约束导致失真。
💡 核心创新点
- 基于噪声模型的DDPM引导机制:创新性地设计了一种新的引导项,其梯度源于对“组合噪声”vt(包含扩散噪声和声学噪声)的噪声模型的似然估计。这不同于已知算子的重建引导[15]或NMF约束[16],将引导信号与噪声统计直接关联。
- 测试时训练范式应用于语音增强:提出了一个清晰的流程(Algorithm 1 & 2),在给定一个新噪声样本时,仅对轻量噪声模型进行快速训练,无需触碰底层的大型扩散模型。这解决了现有生成式语音增强方法对每种噪声需重训整个模型的核心痛点。
- 利用并指导预训练的语音生成模型(DiffWave):证明了将一个为语音生成任务训练的大型扩散模型,通过外部噪声模型引导,可以有效地适配到语音增强任务中,实现了模型能力的跨任务复用。
🔬 细节详述
- 训练数据:
- 扩散模型预训练:使用VCTK和LJ-Speech数据集,仅包含干净语音。具体规模未说明。
- 噪声模型训练:使用从BBC音效库中提取的、与测试噪声独立但同分布的噪声片段。训练时使用一个20秒的噪声片段(̄w)。通过语音活动检测(VAD)从给定的含噪语音中提取这样的片段。
- 损失函数:
- 噪声模型训练使用负对数似然损失(公式19),即建模为条件高斯分布的最大似然损失。对于步t,损失为:loss_t(vt) = Σ_i [ log(√2π·σt,i) + (vt,i - μt,i)²/(2σ²t,i) ]。
- 训练策略:
- 噪声模型训练:对于每个扩散步t (T→1),独立训练对应的噪声模型ϕt。训练轮数(E)从t=0(原文可能应为t=T?)的70轮递减到t=T(原文可能应为t=1?)的10轮。优化器为ADAM,步长η未具体说明。
- 扩散模型:保持冻结,不训练。
- 关键超参数:
- 指导强度调度参数:γ = 0.7,λ_max根据信噪比(SNR)水平设置为[0.8, 0.72, 0.6, 0.55](分别对应10, 5, 0, -5 dB SNR)。
- 噪声模型CNN:内核大小9,通道数2,膨胀率[1,2,4,8],4层。
- 扩散步骤T:200步。
- 训练硬件:未说明具体型号,仅提到在NVIDIA GeForce GTX TITAN X上进行推理,使用了四块GPU。
- 推理细节:采样过程遵循Algorithm 2,从200步迭代去噪。指导强度s_t按公式(11)随t变化。
- 正则化技巧:噪声模型CNN使用了残差连接和权重归一化。
📊 实验结果
论文在两个实验设置下评估了GDiffuSE与基线方法(SGMSE在WSJ0或TIMIT上训练,以及CDiffuSE)。
表1:BBC音效噪声数据集上的评估(SNR从10dB到-5dB)
| SNR | 方法 | STOI | PESQ | DNSMOS | SI-SDR |
|---|---|---|---|---|---|
| 10 dB | GDiffuSE | 0.91 ± 0.05 | 1.60 ± 0.36 | 2.92 ± 0.24 | 14.80 ± 3.55 |
| sgmseW | 0.94 ± 0.04 | 1.59 ± 0.34 | 3.06 ± 0.27 | 14.23 ± 3.07 | |
| sgmseT | 0.93 ± 0.04 | 1.46 ± 0.27 | 3.04 ± 0.25 | 12.41 ± 1.77 | |
| Input | 0.90 ± 0.06 | 1.20 ± 0.14 | 2.42 ± 0.41 | 10.00 ± 0.02 | |
| 5 dB | GDiffuSE | 0.86 ± 0.08 | 1.40 ± 0.32 | 2.73 ± 0.32 | 10.91 ± 4.47 |
| sgmseW | 0.90 ± 0.06 | 1.34 ± 0.30 | 2.94 ± 0.27 | 10.46 ± 4.03 | |
| sgmseT | 0.88 ± 0.07 | 1.20 ± 0.16 | 2.78 ± 0.27 | 7.80 ± 2.65 | |
| Input | 0.84 ± 0.09 | 1.11 ± 0.09 | 2.03 ± 0.46 | 5.01 ± 0.03 | |
| 0 dB | GDiffuSE | 0.78 ± 0.11 | 1.25 ± 0.27 | 2.65 ± 0.33 | 6.66 ± 5.52 |
| sgmseW | 0.84 ± 0.10 | 1.18 ± 0.17 | 2.79 ± 0.34 | 6.04 ± 4.68 | |
| sgmseT | 0.82 ± 0.10 | 1.11 ± 0.09 | 2.61 ± 0.31 | 3.38 ± 3.53 | |
| Input | 0.77 ± 0.11 | 1.07 ± 0.06 | 2.41 ± 1.05 | 0.02 ± 0.04 | |
| -5 dB | GDiffuSE | 0.69 ± 0.15 | 1.12 ± 0.15 | 2.26 ± 0.61 | 1.34 ± 6.42 |
| sgmseW | 0.76 ± 0.14 | 1.09 ± 0.10 | 2.51 ± 0.39 | 0.77 ± 5.52 | |
| sgmseT | 0.74 ± 0.14 | 1.07 ± 0.06 | 2.35 ± 0.36 | -1.46 ± 4.24 | |
| Input | 0.69 ± 0.13 | 1.09 ± 0.17 | 2.04 ± 1.03 | -4.97 ± 0.07 |
关键结论:在大部分SNR下,GDiffuSE在PESQ(感知语音质量)和SI-SDR(源失真比)指标上优于sgmseW和sgmseT,表明其恢复的语音在感知质量和信号保真度上更好。然而,在STOI(可懂度)和DNSMOS(非侵入式质量)上,SGMSE往往得分更高。这种差异可能表明GDiffuSE更倾向于保留语音细节而非完全平滑噪声。
表2:20个高频强调噪声样本在5dB SNR下的评估
| 方法 | STOI | PESQ | DNSMOS | SI-SDR |
|---|---|---|---|---|
| GDiffuSE | 0.88 ± 0.07 | 1.39 ± 0.24 | 2.87 ± 0.25 | 11.25 ± 3.21 |
| sgmseWSJ0 | 0.91 ± 0.07 | 1.26 ± 0.17 | 2.82 ± 0.25 | 9.43 ± 2.64 |
| sgmseTIMIT | 0.89 ± 0.07 | 1.20 ± 0.14 | 2.84 ± 0.29 | 8.64 ± 2.85 |
| CDiffuSE | 0.80 ± 0.06 | 1.12 ± 0.07 | 2.31 ± 0.46 | 3.66 ± 3.23 |
| Input | 0.85 ± 0.09 | 1.07 ± 0.03 | 1.98 ± 0.47 | 5.00 ± 0.03 |
关键结论:在特定类型(高频)的失配噪声下,GDiffuSE的优势更加明显。其PESQ和SI-SDR显著高于所有基线,包括CDiffuSE。这直接支持了论文关于“快速适应新噪声类型”的核心主张。
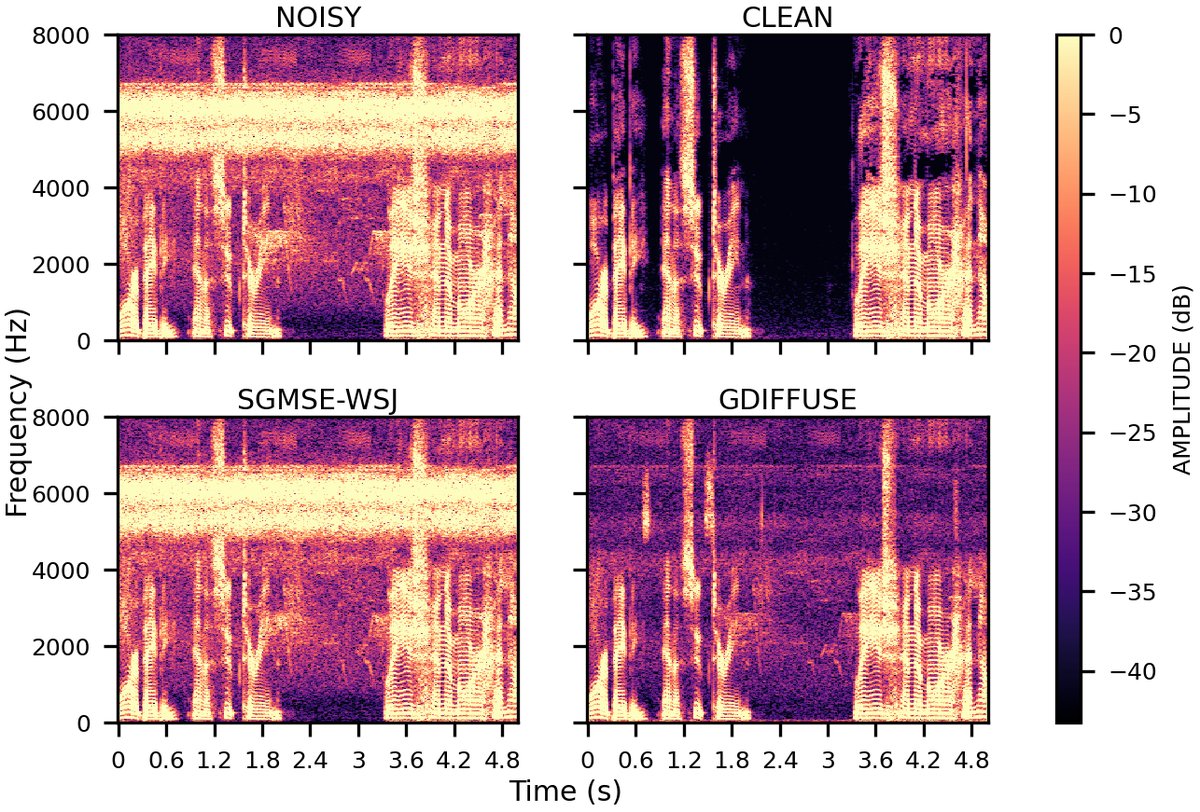
图2:频谱图对比(样本NHU05093027 - 季雨林) (此处无法显示图片,但根据论文描述,该图对比了原始含噪语音、SGMSE增强结果和GDiffuSE增强结果的频谱图。关键结论是:SGMSE难以抑制这种未见过的噪声,而GDiffuSE能有效适应并抑制噪声,保留语音成分。)
⚖️ 评分理由
- 学术质量:6.5/7:论文提出了一个具有原创性和清晰技术路径的框架,将DDPM指导、测试时训练和基础模型复用有机结合。推导正确,实验在设定的失配噪声场景下验证了有效性。扣分点在于实验对比不够全面(未与更多近期工作对比),以及部分关键假设(如短时噪声样本的统计代表性)未经充分验证。
- 选题价值:1.5/2:选题切中当前语音增强领域“如何利用大模型/基础模型并适应环��”的痛点,具有较好的前沿性和应用潜力。方法若成熟,可显著降低实用化成本。
- 开源与复现加成:0.0/1:论文未提供代码、模型权重或详细训练脚本的公开链接。虽然描述了架构和算法,但要完全复现,需自行预训练或获取DiffWave权重,并实现噪声模型的训练和引导流程,存在一定门槛。