📄 Game-Time: Evaluating Temporal Dynamics in Spoken Language Models
#基准测试 #模型评估 #语音大模型 #全双工通信
✅ 7.5/10 | 前25% | #语音对话系统 | #基准测试 | #模型评估 #语音大模型
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Kai-Wei Chang1(麻省理工学院),En-Pei Hu2(台湾大学) (*表示共同第一作者)
- 通讯作者:未说明 (论文中未明确标注通讯作者)
- 作者列表:Kai-Wei Chang (麻省理工学院), En-Pei Hu (台湾大学), Chun-Yi Kuan (台湾大学), Wenze Ren (台湾大学), Wei-Chih Chen (台湾大学), Guan-Ting Lin (台湾大学), Yu Tsao (中央研究院), Shao-Hua Sun (台湾大学), Hung-yi Lee (台湾大学), James Glass (麻省理工学院)
💡 毒舌点评
亮点:选题精准地击中了当前语音对话模型“懂内容,不懂时间”的痛点,并创新性地将儿童语言学习中的“游戏化”概念引入评测框架设计,思路新颖且系统。短板:实验规模(模型数量与评测样本)相对有限,且高度依赖外部工具(如Whisper转录、Gemini作为Judge)进行评估,使得评测流程的自主性与结果的绝对可靠性存在一定折扣。
🔗 开源详情
- 代码:论文中提到“Demos and datasets are available on our project website”,并提供了链接(https://ga642381.github.io/Game-Time)。这很可能包含评估代码和数据。但论文中未明确给出独立的GitHub代码仓库链接。
- 模型权重:未提及。本文是评测基准,不提出新模型。
- 数据集:公开。论文明确声明数据集可在项目网站获取。
- Demo:提供。项目网站包含Demo。
- 复现材料:论文提供了详细的基准构建流程、任务定义表格(表1)和评估方法描述。可能缺少具体的LLM评判prompt模板。
- 论文中引用的开源项目:在数据构建中提到了CosyVoice [39](语音合成)和Google TTS。在评估中使用了Whisper(转录)和Gemini 2.5 Pro [41](作为评判LLM)。
- 总结:论文遵守了评测工作的开源规范,开放了核心数据集和演示,但更完整的复现工具链(如数据生成、评估脚本)的开放情况需查看其项目网站确认。
📌 核心摘要
- 问题:当前对话式语音语言模型(SLM)的评测主要集中在内容生成、风格模仿和轮次转换上,严重缺乏对“时间动态”能力的评估。这种能力包括时间控制、节奏把握和同时说话(全双工),是实现自然、流畅人机语音交互的关键瓶颈。
- 方法核心:本文提出了“Game-Time”评测基准。其灵感来源于儿童通过游戏(如石头剪刀布)学习语言中时间和节奏的过程。该基准包含两大类任务:基础任务(Basic Tasks)测试SLM的基础指令跟随能力;高级任务(Advanced Tasks)在基础任务上增加严格的时间约束(如快/慢速、静音等待、节奏同步、同时发言)。
- 新在何处:与现有仅关注内容、风格或轮次的基准不同,Game-Time首次系统性地、量化地评估SLM的“时间意识”和全双工交互能力。它提出了一个形式化的指令跟随框架,用于生成带有精确时间约束的测试用例,并设计了基于双通道转录和LLM推理的评估方法。
- 主要实验结果:论文评估了多种SLM架构(包括商业API)。结果显示:在基础任务上,最先进的商业模型(如GPT-Realtime)表现良好,但部分学术模型仍存在缺陷。关键结果是,几乎所有模型在引入时间约束后性能都急剧下降。具体而言:模型在“快速/慢速”任务上尚可,但在需要精确“静音等待”或“节奏遵循”的任务上几乎全部失败。全双工同步任务(如同时跟读、石头剪刀布)对所有模型都极具挑战。具体数值见下表:
| 模型 | 全双工方法 | 基础任务平均分(推测) | 高级任务平均分(推测) | 关键观察 |
|---|---|---|---|---|
| SSML-LLM(Oracle) | 非因果补全 | 最高 | 最高 | 理论性能天花板 |
| GPT-realtime | 未说明 | 很高 | 显著下降,但仍可能领先 | 在重复任务上表现突出 |
| Gemini-Live | 未说明 | 高 | 显著下降 | 商业模型表现尚可 |
| Freeze-Omni | 时分复用 | 中高 | 性能大幅下降 | 基础任务尚可,时间任务困难 |
| Unmute | 时分复用 | 中 | 性能大幅下降 | 类似Freeze-Omni |
| Moshi | 双通道 | 中低 | 性能大幅下降 | 基础任务已落后,时间任务更差 |
(注:论文图3展示了详细分数,但未提供具体数值表格,上表根据图表趋势和文字描述总结。)
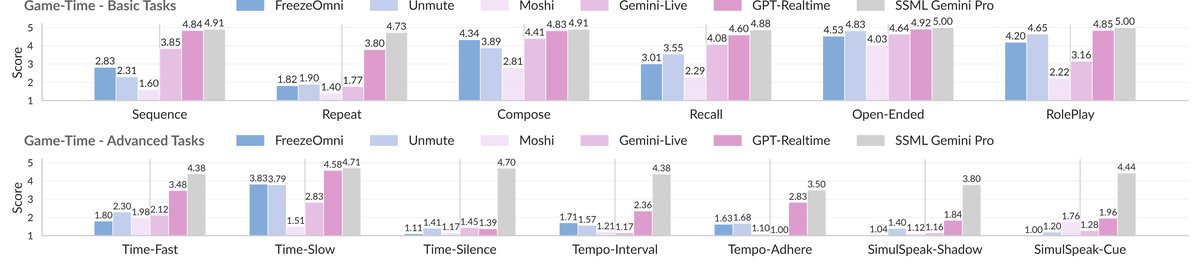 结论:该图清晰展示了所有模型在高级任务(Bottom)上的得分远低于基础任务(Top),且离Oracle系统差距巨大,证实了时间动态是当前SLM的普遍弱点。
结论:该图清晰展示了所有模型在高级任务(Bottom)上的得分远低于基础任务(Top),且离Oracle系统差距巨大,证实了时间动态是当前SLM的普遍弱点。
- 实际意义:该基准为SLM研究提供了一个关键的评测维度,指明了未来模型需要重点突破的方向——时间意识。它推动了从“说什么”到“何时说”的评测范式转变,对开发更自然、更实用的语音交互AI具有重要指导意义。
- 主要局限性:1) 评测的模型数量有限,可能无法覆盖所有最新进展。2) 评估流程依赖ASR转录和LLM判断,其准确性可能影响最终得分。3) 高级任务的设计虽具代表性,但现实对话中的时间动态可能更为复杂和微妙。4) 论文是评测工作,未提出解决时间动态问题的新模型方法。
🏗️ 模型架构
本文的核心贡献是提出了一个评测基准(Benchmark),而非一个具体的神经网络模型架构。因此,其“模型架构”指的是Game-Time评测框架的整体设计。
整体流程:
- 输入:一个带有时间约束的自然语言语音指令(例如:“请在10秒内从1数到10”)。该指令由两部分构成:一个基础任务(t)和一个或多个时间约束(C)。
- 处理主体:待评测的对话式语音语言模型(SLM)。
- 输出:模型生成的语音响应。
- 评估:采用双通道评估方案(见图2)。
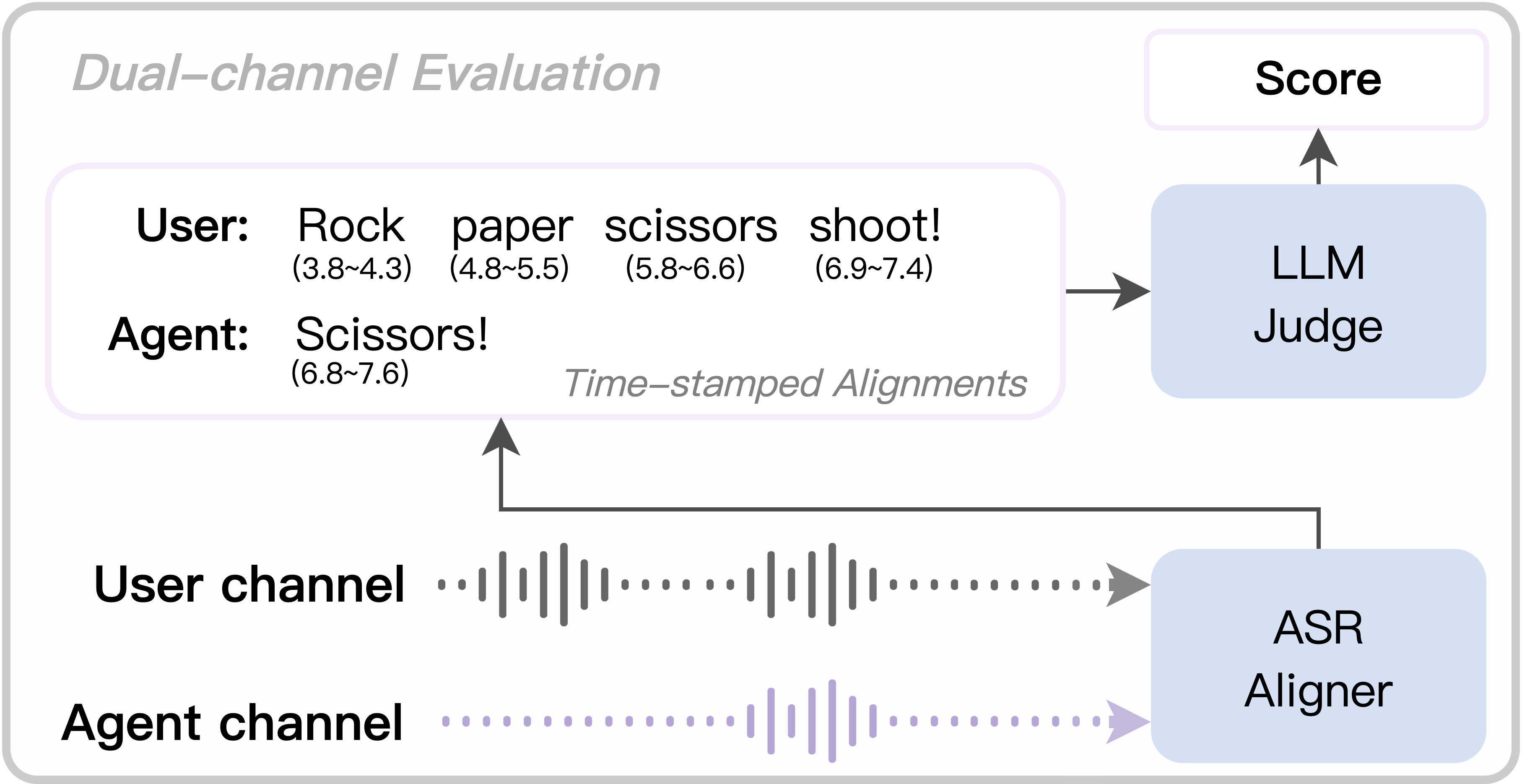
- 使用Whisper模型对用户输入和模型输出的双通道音频进行转录,获得带时间戳的文本。
- 将转录文本输入给一个强大的LLM(如Gemini 2.5 Pro)作为“法官”,根据预设的评分标准(指令跟随、时间满足度等)对模型表现进行打分。
任务体系(核心组件):
- 任务被形式化为指令跟随(IF)问题,每个实例由
(t, C)定义。 - 基础任务族(6类,14个子任务):旨在测试SLM的基本语音交互能力,如序列生成(Sequence)、重复(Repeat)、组合(Compose)、回忆(Recall)、开放式对话(Open-Ended)和角色扮演(Role-Play)。
- 高级任务族(7类,31个子任务):在基础任务上叠加时间约束,分为三类:
- 时间任务(Time):控制总体时长(快/慢)或插入静音。
- 节奏任务(Tempo):遵循指定的词间间隔或模仿用户的说话语速。
- 同步任务(SimulSpeak):要求与用户语音重叠或精确同步(如石头剪刀布的“出拳”时刻)。
- 任务被形式化为指令跟随(IF)问题,每个实例由
数据构建流程:
- 种子指令创建 → 语言多样化(LLM改写) → 语音合成(使用CosyVoice等TTS) → 质量控制(ASR转录比对+人工抽检)。
- 最终生成1475个测试样本(基础700,高级775)。
关键设计选择:
- 形式化:将时间动态评估转化为可量化、可生成的约束满足问题,确保了评测的系统性和可扩展性。
- LLM-as-a-judge:利用LLM的推理能力来评估复杂的、非结构化的语音交互行为(尤其是时间维度),相比纯规则或简单的音频特征比对更为灵活和准确。
- Oracle系统:引入SSML-LLM作为理论性能上界,为评估提供校准基线。
💡 核心创新点
- 提出全新的评测维度——时间动态:这是对话式语音模型评估领域的核心空白。工作将评测重点从“内容质量”转移到“时间质量”,定义了对实现自然全双工对话至关重要的新能力集。
- 设计“游戏化”的任务体系:受儿童语言学习启发,任务设计既包含基础能力检查,又通过渐进式的时间约束(游戏规则)来测试高阶动态交互能力,任务设计直观且具系统性。
- 形式化的指令-约束框架:将评测任务形式化为
(t, C)对,为自动生成大量多样化的测试用例提供了清晰的方法论,使得基准可扩展、可复现。 - 双通道LLM评估方法:提出了一套完整的、利用时间戳转录和LLM推理来评估复杂语音交互行为的评估协议,解决了时间同步等行为难以用传统指标衡量的问题。
🔬 细节详述
- 训练数据:不适用。本文是评测工作,不涉及模型训练。评测数据集(Game-Time Benchmark)包含1475个合成的语音指令样本。
- 损失函数:不适用。无模型训练过程。
- 训练策略:不适用。
- 关键超参数:不适用。论文中未说明任何模型训练超参数。
- 训练硬件:不适用。
- 推理细节:
- 评测对象为现有的SLM,推理细节取决于各模型自身。
- 评估推理:使用Whisper-medium进行语音转文本,使用Gemini 2.5 Pro作为LLM评判者。
- 正则化或稳定训练技巧:不适用。
📊 实验结果
- 主要Benchmark/数据集:论文自建的Game-Time Benchmark(1475个样本)。
- 指标:由LLM-as-a-judge给出的指令跟随得分(0-1或0-100,论文未明确说明具体分制)。人类评估得分用于验证LLM判断的相关性。
- 主要对比与结果:
- 基础任务:Oracle系统(SSML-LLM)性能最佳。商业模型GPT-Realtime和Gemini-Live表现领先,尤其在重复任务上。时间复用模型(Freeze-Omni, Unmute)优于双通道模型(Moshi)。部分现代SLM在基础任务上仍存在失败案例。
- 高级任务:所有模型性能均出现大幅下降。这是最核心的发现。
- 细分结果:
- 模型在“快/慢速”任务上相对较好,说明能调整语速。
- 模型在“静音等待”任务上普遍失败,表明无法理解并执行精确的延迟指令。
- 节奏任务和同步任务对所有模型(包括商业SOTA)都极具挑战性。
- 关键消融实验:论文未进行传统意义上的模型消融,但其“基础任务 vs 高级任务”的对比本身就构成了对“时间约束”这一核心变量的消融分析,清晰展示了时间动态是性能短板。
- 人类评估验证:图4和表3显示,LLM-as-a-judge与人类评估者在高级任务得分上的相关性较高(Spearman’s ρ = 0.677),证明了该评估方法的可靠性。
 图4说明:该图展示了人类评估员对四个模型在部分高级任务上的评分分布。结果显示,模型间性能排序与LLM评估结果趋势一致,且得分普遍偏低,佐证了LLM评估的有效性和模型在时间任务上的困难。
图4说明:该图展示了人类评估员对四个模型在部分高级任务上的评分分布。结果显示,模型间性能排序与LLM评估结果趋势一致,且得分普遍偏低,佐证了LLM评估的有效性和模型在时间任务上的困难。 - 与SOTA差距:即使是最先进的商业模型(如GPT-Realtime),在时间约束任务上也与Oracle系统存在巨大差距,远未达到“解决”时间动态问题的程度。
⚖️ 评分理由
- 学术质量:5.5/7
- 创新性:高。提出了全新的、重要的评测视角和系统化框架。
- 技术正确性:高。任务形式化、数据构建流程、评估方法设计逻辑严密。
- 实验充分性:中。评估了多个代表性模型,包含了细分任务对比和人类评估验证。但模型数量有限,且未对评估方法本身(如不同LLM评判者、转录模型的影响)进行更深入的消融。
- 证据可信度:中高。人类评估与LLM评估的相关性提供了交叉验证,但整体评估流程依赖外部系统。
- 选题价值:1.5/2
- 前沿性:非常高。直击对话式AI走向实用化的核心瓶颈之一。
- 潜在影响:高。为社区指明了关键的研究缺口和评测标准,可能引导大量后续工作。
- 应用空间:高。时间感知对实时助手、医疗语音代理、应急指导等场景至关重要。
- 与读者相关性:高。对从事语音对话、多模态AI、人机交互的研究者有直接参考价值。
- 开源与复现加成:0.5/1
- 提供了项目网站链接,承诺开放数据集和Demo,这是重要的开源贡献。
- 但论文未明确承诺开源评估代码、模型评判的具体prompt、以及合成数据所用的种子指令集等细节,因此复现门槛仍存在。